本文主要介绍如何部署和使用 TACO DiT 推理加速服务。
获取 TACO DiT custom 依赖包
外部依赖包和 TACO DiT 工具包都放到 custom node 目录下。
配置外部依赖的开源仓库
cd x-flux-comfyuipip install -r requirements.txtcd ComfyUI-TeaCachepip install -r requirements.txtcd ComfyUI-Easy-Usepip install -r requirements.txt
获取并配置 TACO DiT 环境
wget##TACO DiT安装文件##cdxdit-comfyuipipinstall-r requirements.txt
获取并安装 SageAttention
gitclone https://github.com/thu-ml/SageAttention.gitcdSageAttentionexportEXT_PARALLEL=4NVCC_APPEND_FLAGS="--threads 8"MAX_JOBS=32# parallel compiling (Optional)python setup.pyinstall# or pip install -e .
客户部署
根据不同需求场景,您可以创建不同工作流,主要的 custom node 如下:
MagCache
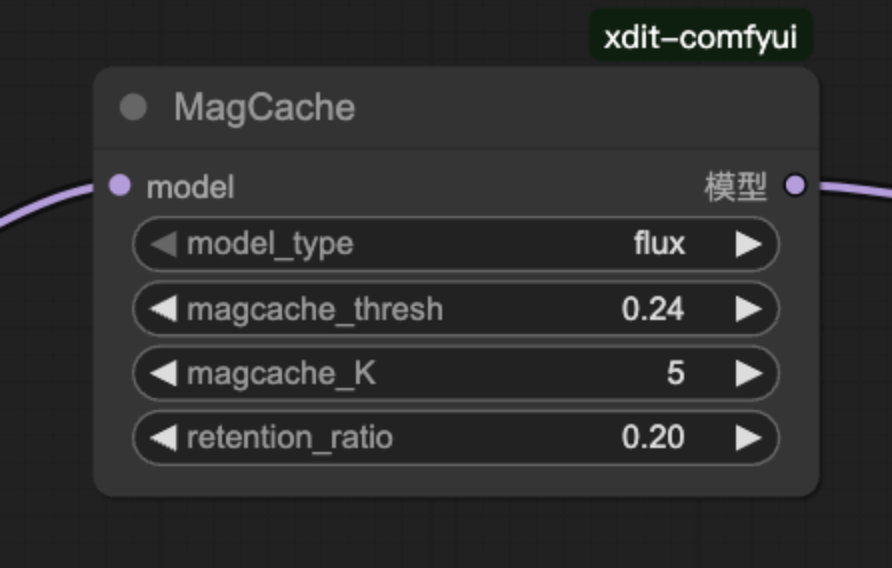
说明:
您可修改 model_type 切换不同的模型,如果精度出现下降可以通过降低 magcache_thresh 和 magcache_K 以及增大 retention_ratio 进行优化。
TeaCache
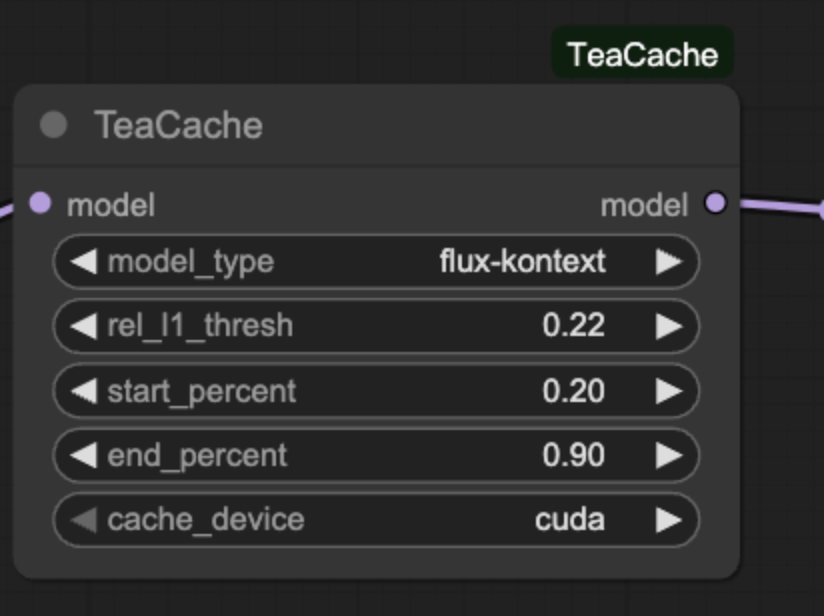
说明:
您可修改 model_type 切换不同的模型,如果精度出现下降可以通过降低 rel_l1_thresh 以及调整 start_percent 和 end_percent 进行优化。
Compile Flux Model
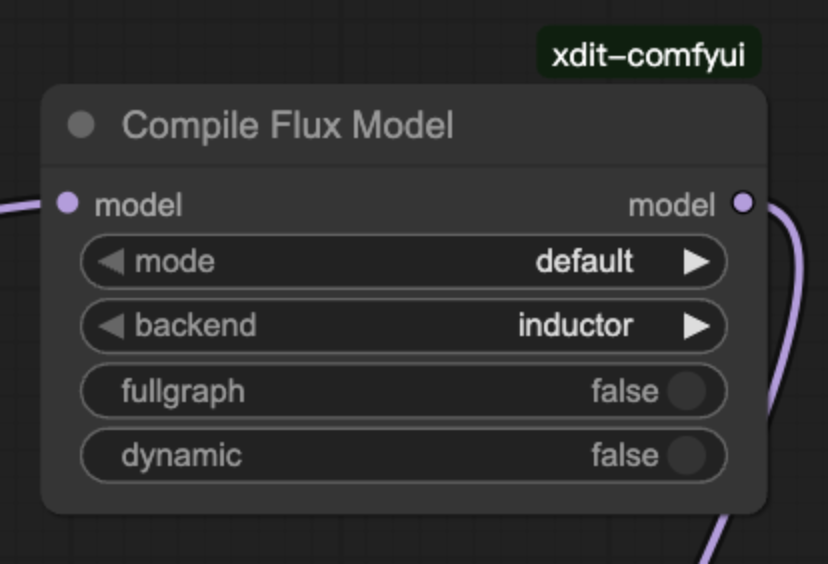
说明:
专为 Flux 模型定制的 Compile Node,第一次执行会对执行流程进行编译,因此会增加第一次的执行时间,但是第二次之后的执行时间会明显下降(当存在 offload 时可能会编译失败,因此存在 offload 时慎用)。
Compile Model
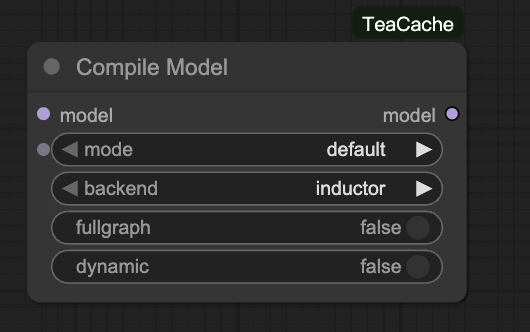
说明:
通用模型的 Compile Node,第一次执行会对执行流程进行编译,因此会增加第一次的执行时间,但是第二次之后的执行时间会明显下降(当存在 offload 时可能会编译失败,因此存在 offload 时慎用)。
ParallelUNETLoader
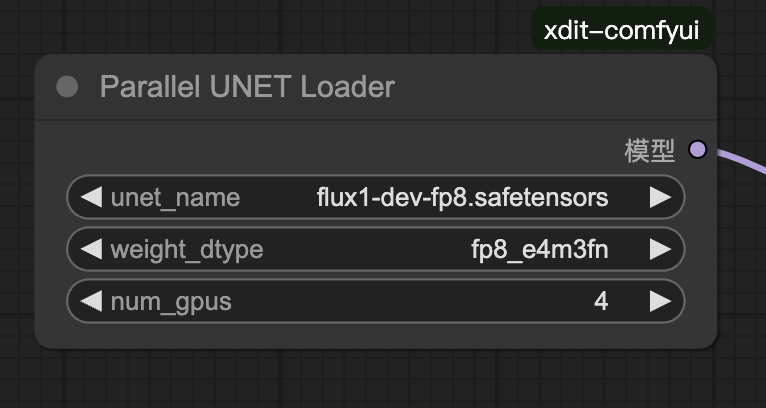
说明:
UNETLoader 的并行版本,通过在启动后设置 num_gpus 可以方便的执行多卡并行(一次 ComfyUI 启动只能支持一种配置,切换卡数需要重启 ComfyUI)。
ParallelLoraLoader
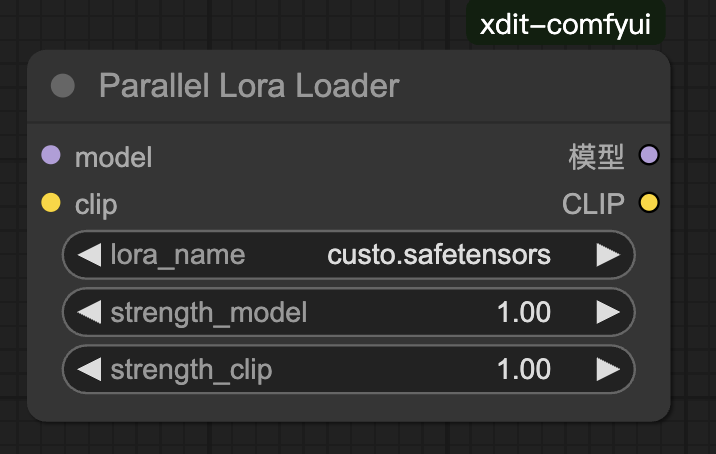
说明:
LoraLoader 的并行版本,与 ParallelUNETLoader 配套使用。
ParallelLoraLoaderModelOnly
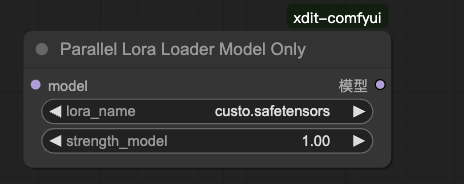
说明:
LoraLoaderModelOnly 的并行版本,与 ParallelUNETLoader 配套使用。
ParallelTeaCache
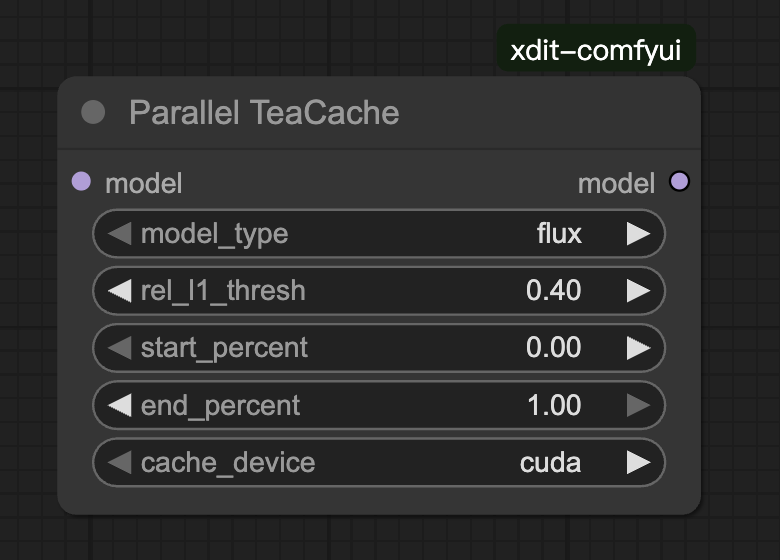
说明:
TeaCache 的并行版本,与 ParallelUNETLoader 配套使用。
ParallelCompileModel
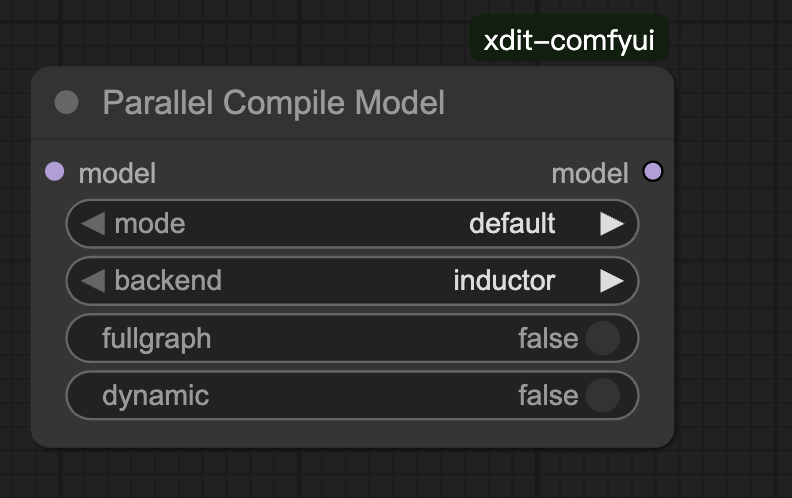
说明:
CompileModel 的并行版本,与 ParallelUNETLoader 配套使用(当存在 offload 时可能会编译失败,因此存在 offload 时慎用)。
验证工作流
单卡执行命令如下:
python3 main.py --fast --port8190--use-sage-attention
为您提供以下样例工作流:
多卡执行命令如下:
python3 main.py --disable-cuda-malloc --fast --port8190



