操作场景
随着人工智能和自然语言处理技术 LLM(Large Language Model,大型语言模型)的快速发展,智能问答、在线客服、内部知识库等已经成为了许多企业提高效率的关键,LLM 大模型对通用知识领域的回答已表现的非常优秀,但对企业垂直业务领域,如“我想要申请贷款,需要什么条件?”或者“我想要办理信用卡,流程是怎样的?”这类针对特定企业业务的具体问题,当前的大模型可能无法给出准确的、符合企业业务流程的回答。因此,企业需要由向量数据库存储作为内部私域知识作为补充,从而实现专属领域的知识问答,提高智能问答的准确度和专业度。
本文将为您介绍使用 ChatGLM 作为大模型,腾讯云向量数据作为数据存储,搭建企业专属的智能问答系统的操作实践。
原理介绍
本方案中使用的关键组件或服务如下:
LangChain:是一个开源框架,它提供了一套组件和接口,可以简化搭建端到端大模型应用程序的过程。
ChatGLM:是一种基于 LLM 大型语言模型的对话生成系统,功能类似于 ChatGPT,可以用于回答用户的问题、提供信息、进行闲聊等。我们的方案中 ChatGLM 采用本地部署方式,同时采用 API 的方式来调用。
腾讯云向量数据库:用于存储向量数据,并进行向量相似性检索。
具体的实现流程如下:
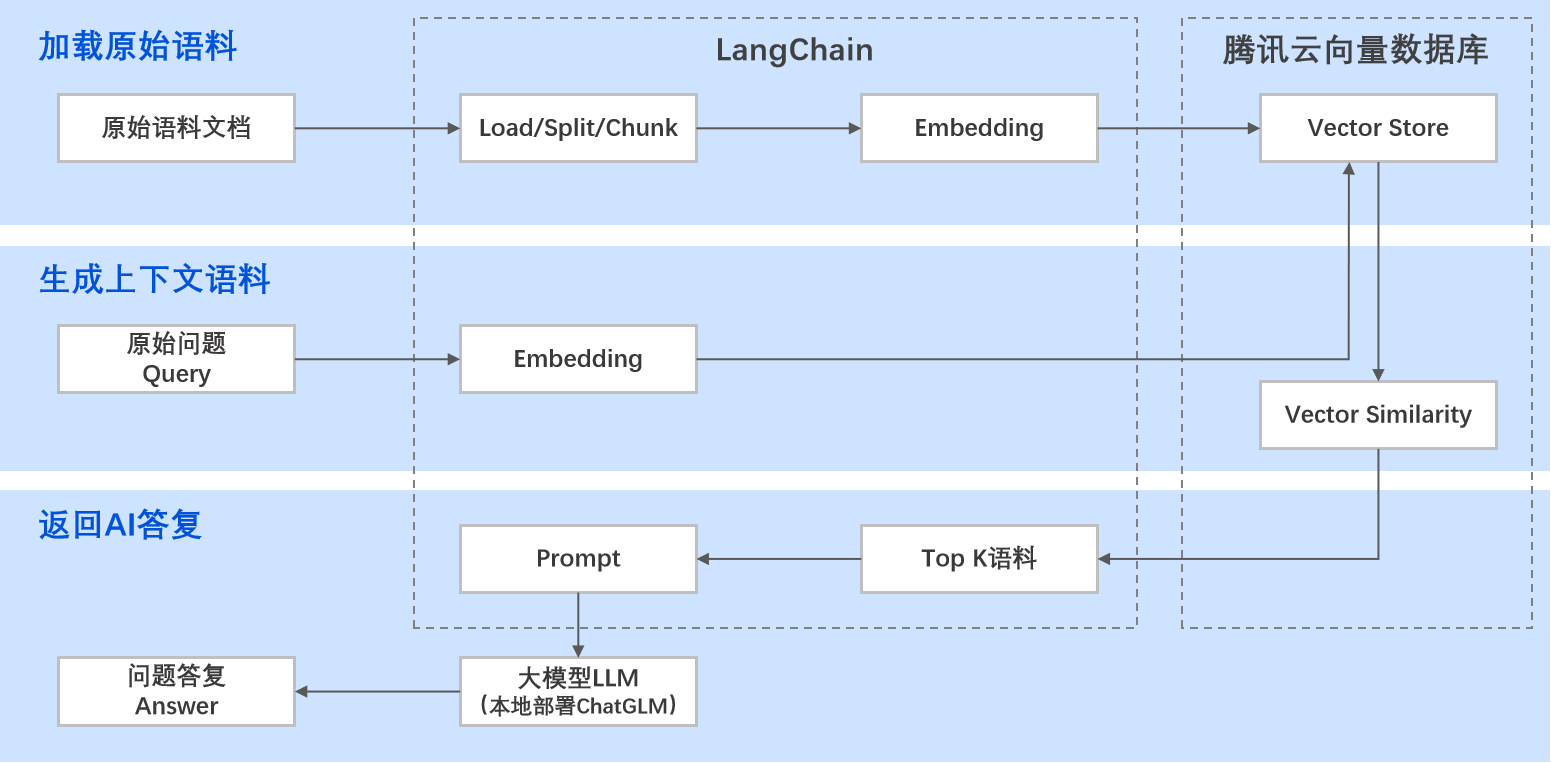
1. 加载原始语料:将原始的语料文档放在指定路径,通过 LangChain 对文档进行加载、分割、语句预处理、向量化,然后发送给向量数据库进行存储。
2. 生成上下文语料:提问请求发起,LangChain 将提问的文本进行向量化,然后发送给向量数据库。向量数据库进行语义检索,即在已存储的语料数据中进行相似性检索,找出与提问的向量数据匹配度最高的 Top K 语料(K 指文本条数的上限,可自行设置),然后把这个匹配出的结果+用户提问的内容,组装成提示词 Prompt。
3. 返回 AI 答复:LLM 根据提示词 Prompt 生成答复文本返回给用户。
操作步骤
步骤1:购买和配置腾讯云向量数据库
1. 使用腾讯云账号登录 向量数据库控制台。
2. 购买一个腾讯云向量数据库实例。
单击新建,进入新建向量数据库实例页面,配置参数后,单击立即申请。
3. (可选)开通外网访问功能。
4. 配置安全组访问功能,使您部署智能问答系统的机器与腾讯云向量数据库可以互通。
在部署智能问答系统的机器上,将腾讯云向量数据库的 IP 及端口添加到访问白名单中。
在腾讯云向量数据库安全组中,将您部署机器的 IP 地址及端口添加到访问白名单中,具体可参见 安全组。
5. 参考连接并写入向量数据中的创建集合步骤,创建 DATABASE 和 COLLECTION,用于存放向量数据。
6. 准备后续步骤中需要配置的相关参数。
获取向量数据库实例的访问地址(VDB_URL)。具体操作,请参见 查看实例信息。
获取向量数据库的 API 访问密钥(VDB_KEY)。具体操作,请参见 密钥管理。
获取向量数据库登录的用户名(VDB_USERNAME)。
获取向量数据库中的 “DATABASE_NAME” 和 “COLLECTION_NAME”。
步骤2:部署 ChatGLM
部署 ChatGLM 需要拉取 ChatGLM 的仓库代码,并下载 ChatGLM 模型文件,模型文件可以从 HuggingFace 下载,因为国内从 Hugging Face 下载 ChatGLM 模型通常速度较慢,如下提供了一个在容器服务(TKE)上快速部署 ChatGLM 的方案,只需20-30分钟。
请参考 使用 TKE 快速部署 ChatGLM 进行部署。因为参考链接中的部署方案提供的是通过 Web UI 的方式访问 ChatGLM,我们在搭建本地知识库时,需要通过 API 方式访问 ChatGLM,所以在新建 Deployment 的步骤中,需要修改如下2点:
1. 容器端口:不需要配置,会按照服务默认的端口进行配置。
2. 运行参数输入:api.py。

ChatGLM 部署完成后,在需要部署知识库的机器上执行如下命令,验证 API 访问是否正常。其中 IP 为 TKE 集群的访问地址,端口默认为8000。
curl -X POST "http://1xx.x.x.1:8000" \\-H 'Content-Type: application/json' \\-d '{"prompt": "你好", "history": []}'
得到的返回值如下。
{"response":"你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。", "history":[["你好","你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。"]], "status":200, "time":"2023-03-23 21:38:40"}
步骤3:部署 LangChain 等相关组件
说明:
步骤3和步骤4可以在您本地的机器上进行部署。如下以 Linux 操作系统为例,我们购买一个云服务器 CVM 作为部署机器。
如果整个智能问答系统仅在一个 VPC 内网使用,购买的 CVM 云服务器与腾讯云向量数据库需要在同一地域同一个 VPC 内;如果智能问答系统需要连接外网,则购买 CVM 云服务器时,地域无限制,但需要开通公网访问功能,同时腾讯云向量数据库也需要开通公网访问功能(与步骤1中的3对应)。
1. 确保机器上已经安装了 Python 和 pip 工具。
# 检查 Python 版本,Python 版本需要满足3.10.x及以上,否则后续步骤可能会有问题。python3 --version# 检查是否安装 pip,版本需要与 python 匹配pip3 --version# 如果没有 pip,请安装 pipcurl https://bootstrap.pypa.io/get-pip.py -o get-pip.pypython3 get-pip.py# 检查 pip 是否安装成功pip3 --version
2. 安装 LangChain、pdf、vectordb 组件。
# 安装 langchainpip3 install langchain# 安装 pdf 模块pip3 install pdfplumberpip3 install pypdfcd# 安装向量数据库模块pip3 install tcvectordb
步骤4:构建智能问答系统
1. 创建一个存放知识库的目录并准备对应文件。
# 知识库目录以 vdbproject 为例# 创建 config 文件目录mkdir -p vdbproject/config# 创建语料存储文件目录mkdir -p vdbproject/data
2. 创建并修改 config.json 配置文件。
# 创建并修改配置文件。执行后按“i”进入编辑模式,参考下面示例中的代码调整,修改完成后按“ESC”返回显示模型。vim vdbproject/config/config.json# 保存并退出:wq
config.json 文件内容示例如下。
{"llm_config": {"URL": "http://1**.**.*.1:8000","TOKEN": "xxxxxx"},"vdb_config": {"VDB_URL": "http://10.**.**.**:80","VDB_USERNAME": "r****","VDB_KEY":"tO**********xxxon**********T","DATABASE_NAME":"LangChainDatabase","COLLECTION_NAME":"LangChainCollection"},"embedding": {"model_id": "bge-base-zh","model_dimension": 768},"query_topk": 4,"prompt_template": "Use the following pieces of information to answer the user's question.\\n If you don't know the answer, just say that you don't know, don't try to make up an answer.\\n Context: {context}\\nQuestion: {question}\\n Only return the helpful answer below and nothing else.\\nHelpful answer:"}
config.json 文件中各参数的说明如下。
配置项 | 参数说明 |
llm_config | 大模型服务调用的信息。 URL:ChatGLM-6B 大模型的调用地址,这里需要填写绝对路径。 TOKEN:ChatGLM-6B 大模型访问密钥,当前不需要配置。 |
vdb_config | VDB 的连接信息,参考“步骤1中的5”获取对应数据并填入。 VDB_URL : VDB 用于外放访问的 URL 地址。 VDB_USERNAME : VDB 登录的用户名。 VDB_KEY : VDB API 访问密钥。 DATABASE_NAME :向量数据库的 DB 名称。 COLLECTION_NAME :向量数据库的 collection 名称。 |
query_topk | 向量数据库进行相似性检索,找出与 query 相似度最高的 Top K 个结果,K 为根据一组向量数据返回语料文本条数的上限。当前定义为4,可以结合大模型允许的字符数上线、大模型微调效果等方面进行设置。 |
prompt_template | 用于向大模型提问的 prompt 模板。 |
3. 准备原始语料文档,放在 vdbproject/data 目录下。
# 将本地的文档“/path/to/local/username.PDF”scp到云服务的“/vdbproject/data"路径下,实际操作中这两个路径需要替换为您的实际路径# 上传单个PDF文档scp -P xxx /path/to/local/filename.pdf username@server_ip:/vdbproject/data# 批量上传多个PDF文档scp -P xxx /path/to/local/*.pdf username@server_ip:/vdbproject/data
4. 创建并修改 main.py。
通过
vim vdbproject/main.py创建并修改 main.py,具体代码示例如下,用户可根据实际情况再调整。说明:
如下代码示例中使用了虚拟的 Embedding,您在使用过程中需要替换为真实的 Embedding 服务参数。
from langchain.document_loaders import PyPDFLoader # 这里以PDF格式文档为例,实际过程中如果使用其他文档格式,需要进行适配import os, pdfplumber, tempfileimport argparseimport jsonfrom langchain.embeddings.fake import FakeEmbeddingsfrom langchain.text_splitter import CharacterTextSplitterfrom langchain.vectorstores import TencentVectorDBfrom langchain.vectorstores.tencentvectordb import ConnectionParamsfrom langchain.vectorstores.tencentvectordb import IndexParamsfrom langchain.llms import ChatGLMfrom langchain.prompts import PromptTemplatefrom langchain.chains import LLMChainimport timeimport requests# 创建一个 VectorDB 和 LLM 模型的对话class ChatLLMbot:def __init__(self, config,clear_db,no_vector_store) -> None:self.config = configif no_vector_store == False:self.vector_db = self.connect_vectorstore(clear_db)self.llm = self.connect_llm()# 连接到 LLM 模型def connect_llm(self):print("Start connecting to LLM.")endpoint_url = self.config['llm_config']['URL']# 配置 LLM 参数llm = ChatGLM(endpoint_url=endpoint_url,max_token=80000,top_p=0.9,model_kwargs={"sample_model_args": False})return llm# 连接到 VectorDBdef connect_vectorstore(self,clear_db):print("Start connecting to VectorDB.")VDB_URL = self.config['vdb_config']['VDB_URL']VDB_USERNAME = self.config['vdb_config']['VDB_USERNAME']VDB_KEY = self.config['vdb_config']['VDB_KEY']DATABSE_NAME = self.config['vdb_config']['DATABASE_NAME']COLLECTION_NAME = self.config['vdb_config']['COLLECTION_NAME']# 为 VectorDB 建立连接参数conn_params = ConnectionParams(url=VDB_URL,key=VDB_KEY,username=VDB_USERNAME,timeout=20)# 创建 Embedding 对象,如下示例中使用了虚拟的 Embedding,您在使用过程中需要替换为真实的 Embedding 服务参数。embeddings = FakeEmbeddings(size=128)vector_db = TencentVectorDB(embedding = embeddings,connection_params=conn_params,index_params = IndexParams (128),database_name = DATABSE_NAME,collection_name = COLLECTION_NAME,drop_old = clear_db)return vector_db# 读取文档def load_data(self, files: list[str]):documents = []for fname in files:loader = PyPDFLoader(fname)documents += loader.load()# 分割文档text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)documents = text_splitter.split_documents(documents)self.vector_db.add_documents(documents)# 使用 VectorDB+LLM 检索def query(self, query: str, use_vdb: bool = True) -> str:context = ''if use_vdb:answer_from_vdb = self.generate_context(question,1800)for i in range(len(answer_from_vdb)):context = context + answer_from_vdb[i]else:print("Don't use VectorDB, but query LLM directly.")# 返回查询结果给 LLM 模型answer = self.query_to_llm(context, query)return answer# 根据提问匹配上下文def generate_context(self, query: str,max_context_length: int) -> str:print("Start querying VectorDB with query: " + query)# 使用向量数据库做相似性检索docs = self.vector_db.similarity_search(question, k=self.config['query_topk'])# 限制发给大模型的上下文文本总长度current_context_length = 0ret = []for doc in docs:if len(doc.page_content) + \\current_context_length > max_context_length:continuecurrent_context_length += len(doc.page_content)ret.append(doc.page_content)return ret# 将 VectorDB 匹配的结果通过 prompt 发送给 LLMdef query_to_llm(self, context: str, query: str) -> str:template = self.config['prompt_template']prompt = PromptTemplate(template=template, input_variables=["context", "question"])print("Start querying LLM with prompt.")start_time = time.time()llm_chain = LLMChain(prompt=prompt, llm=self.llm)# 使用 LLM 模型进行预测answer = llm_chain.predict(context=context,question=question)end_time = time.time()print("Get response from LLM success. Cost Time: {:.2f}s".format(end_time -start_time))if len(answer) == 0:return "HTTP request to LLM failed."return answer# 命令行参数解析if __name__ == '__main__':parser = argparse.ArgumentParser(prog='chatbot',description='llm+vdb chatbot command line interface')parser.add_argument('-l', '--load', action='store_true',help='generate embeddings and update the vector database.')parser.add_argument('-c', '--clear', action='store_true',help='clear all data in vector store')parser.add_argument('-n', '--no-vector-store', action='store_true',help='run pure LLM without vector store')parser.add_argument('--config', help='input configuration json file',default='./config/config.json')args = parser.parse_args()# 检查是否配置 JSON 文件并加载对应配置if args.config:if os.path.exists(args.config):with open(args.config) as f:config = json.load(f)#print(config)bot = ChatLLMbot(config,args.clear,args.no_vector_store)if args.load :DIR_PATH = os.path.dirname(os.path.realpath(__file__))files = [os.path.join(DIR_PATH, 'data', x)for x in os.listdir(os.path.join(DIR_PATH, 'data'))]print(f'Start loading files: {files}')bot.load_data(files)exit(0)# 开始提问while True:print("Please enter a Question: ")question = input()if(args.no_vector_store):answer = bot.query(question,False)print('LLM answer:\\n ' + answer)else:answer = bot.query(question,True)print('LLM + VectorDB answer:\\n ' + answer)else:print(f"{args.config} is not existed.")else :print("The config json file must be set.")
5. 加载 data 路径下的文件。
# 进入 vdboroject 路径下cd vdboroject# 加载数据python main.py -l# 清理历史数据。如果需要重新加载文档,请先清理历史数据,然后再执行加载数据命令python main.py -l -c
6. 运行 main.py。
python main.py
7. 运行 main.py 后会提示“Please enter a Question: ”,然后输入问题。
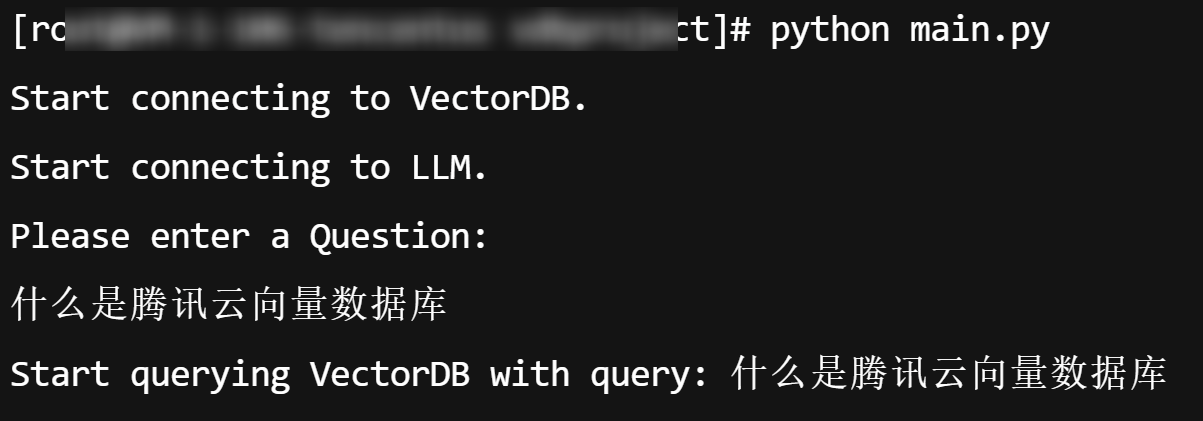
如果输入中文问题后提示“'utf-8' codec can't decode……”,则不兼容字符集,请尝试如下处理。
# 打开 python 解释器python# 在 Python 解释器中输入如下代码import syssys.stdin.reconfigure(encoding='utf-8')# Ctrl + D 退出解释器
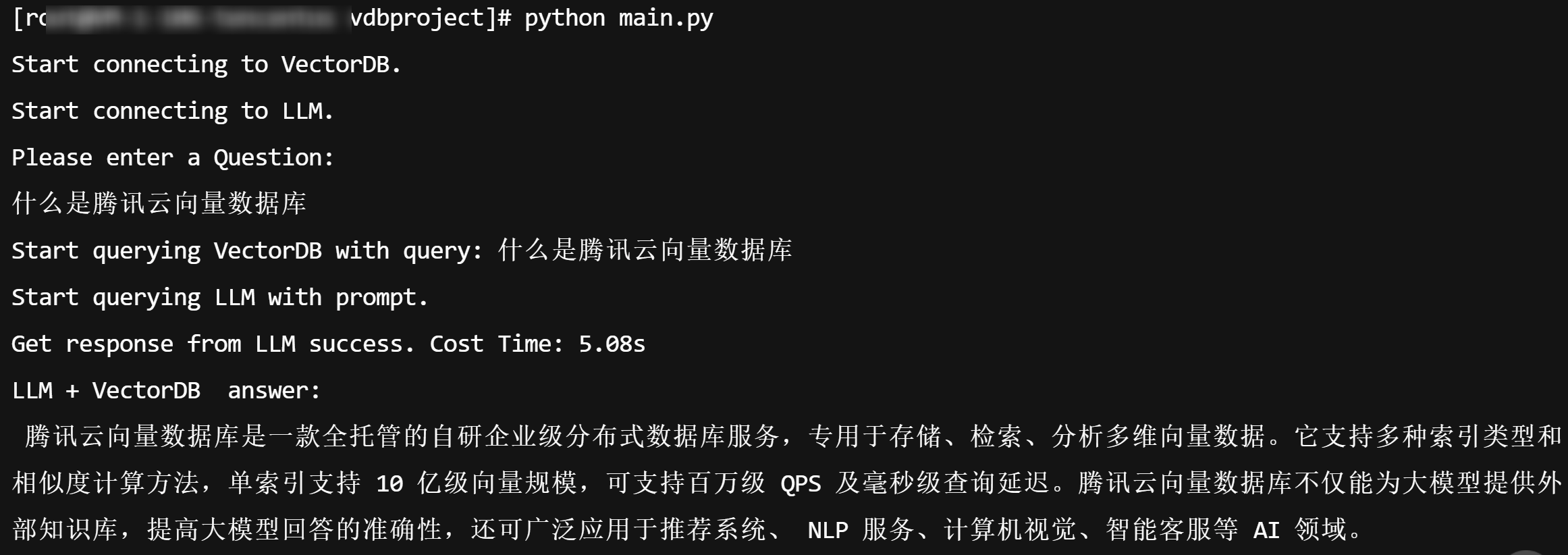
步骤5:使用效果对比
不使用向量数据库,仅查询 LLM 结果示例(执行
python main.py -n)。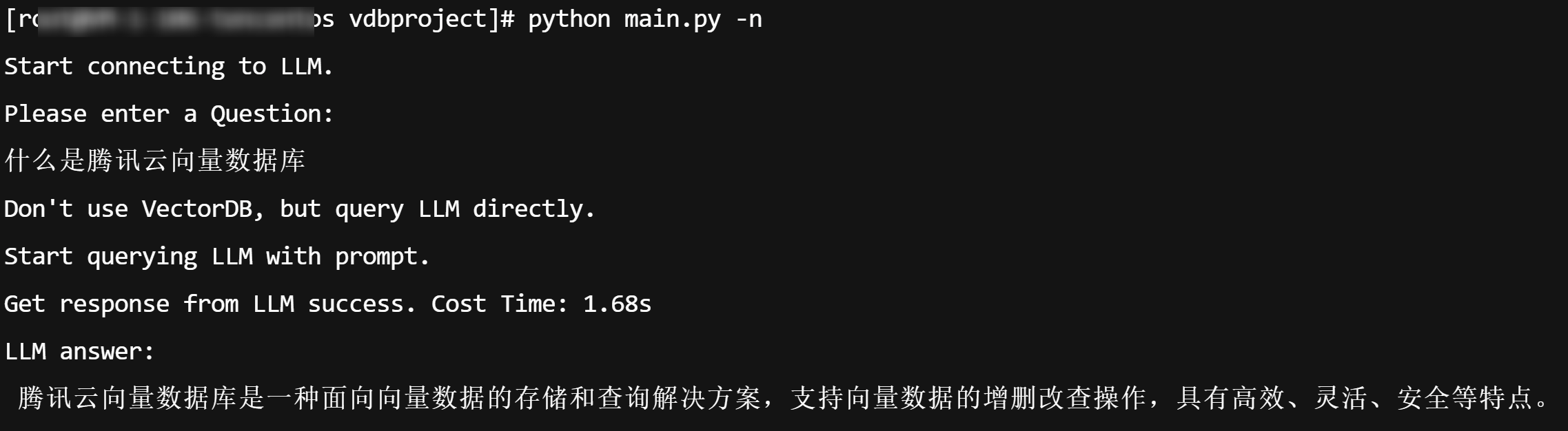
使用向量数据库做上下文语料提示,查询 LLM 结果示例(执行
python main.py)。说明:
由于我们的代码示例中使用了虚拟的 Embedding,所以可能会出现多次查询的结果差异较大,精准度不高。您在实际使用过程中替换为真实的 Embedding 后,结果会根据语料库进行精准匹配。