背景介绍
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需6GB显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约1TB标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持。
在开源的中文大模型中,ChatGLM-6B 是非常不错的选择。最近,来自 LMSYS Org(UC 伯克利主导)的研究人员发起的大语言模型版排位赛中,ChatGLM 虽然只有60亿参数,但依然冲进了前五,只比130亿参数的 Alpaca 落后了23分。基于或使用了 ChatGLM-6B 的开源项目如下:
langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答。
闻达:大型语言模型调用平台,基于 ChatGLM-6B 实现了类 ChatPDF 功能。
chatgpt_academic:支持 ChatGLM-6B 的学术写作与编程工具箱,具有模块化和多线程调用 LLM 的特点,可并行调用多种 LLM。
glm-bot:将 ChatGLM 接入 Koishi 可在各大聊天平台上调用 ChatGLM 话题。
部署步骤
通过控制台创建。
准备集群
1. 开通并创建 TKE 集群,操作步骤详情请参见 创建容器服务集群。
2. 创建节点池,操作步骤详情请参见 创建节点池。由于 ChatGLM-6B 的 GPU 版本最少需要14G显存,因此 Worker 节点选择 V100 GPU 节点,型号为 GN10Xp.2XLARGE40,系统盘空间为100GB。
3. 根据业务部署时对 GPU 的共享需求,可以选择并打开 qGPU 选项。关于 qGPU 的使用方法,请参见 容器服务使用 qGPU。
4. 配置完毕后,确认选项及扩展组件无误,单击创建节点池。
创建应用
使用控制台创建 Deployment
1. 登录 容器服务控制台,选择左侧导航栏中的集群。
2. 单击集群 ID,进入集群的基本信息页面。
3. 选择工作负载,在 Deployment 页面单击新建。
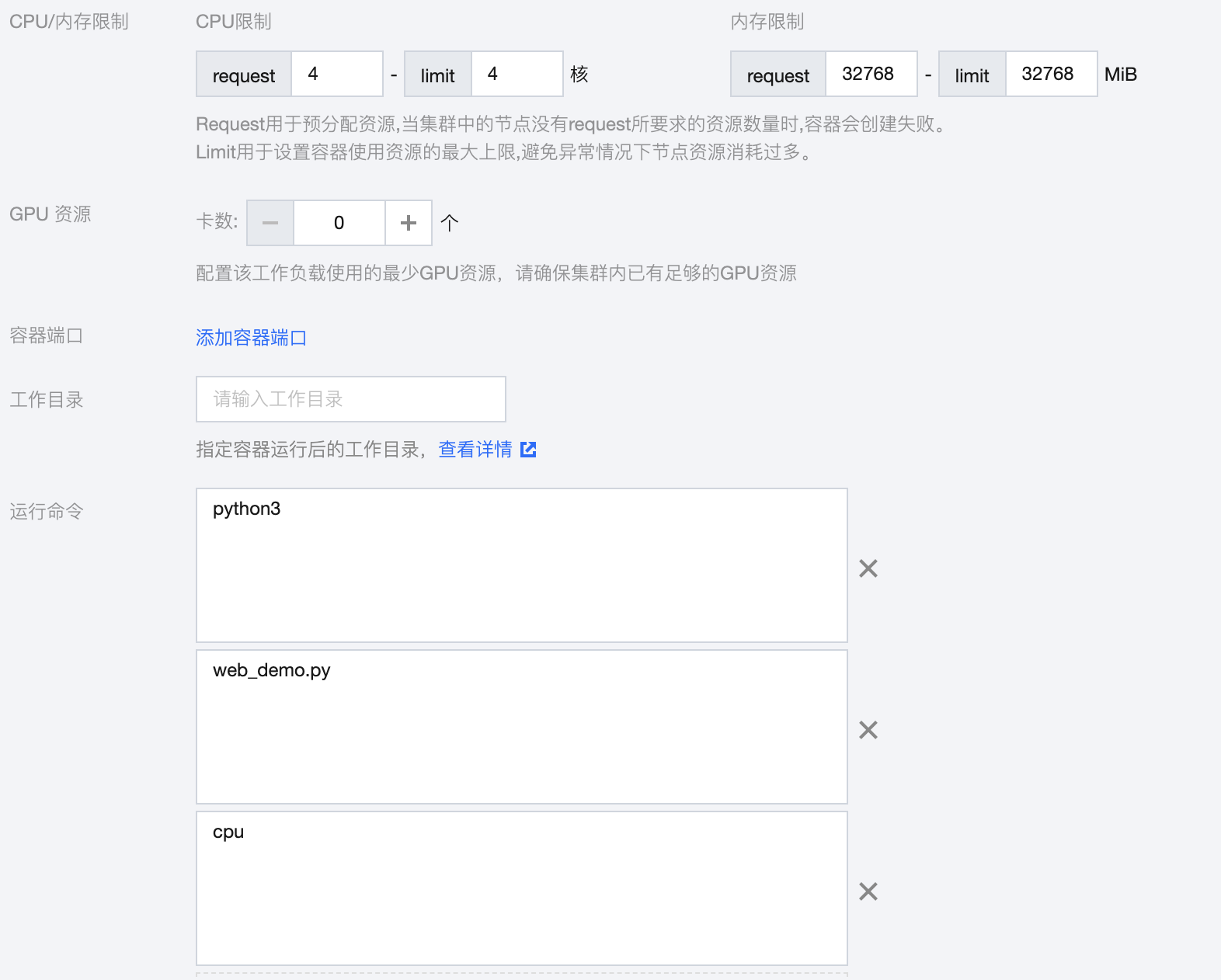
4. 在新建工作负载页面,参考以下信息开始创建 ChatGLM 应用。在实例内容器中设置如下:
名称:填写
chatglm-6b。镜像:填写
ccr.ccs.tencentyun.com/chatglm/chatglm-6b:v1.2。CPU/内存限制:由于 ChatGLM-6B 的资源需要主要是 GPU,因此 CPU 和内存可以按需设置。
GPU 资源:设置为1个,GPU 类型选择 Nvidia。
容器端口:端口填写7860。
运行命令
:分别添加 python3和 web_demo.py。如下图所示: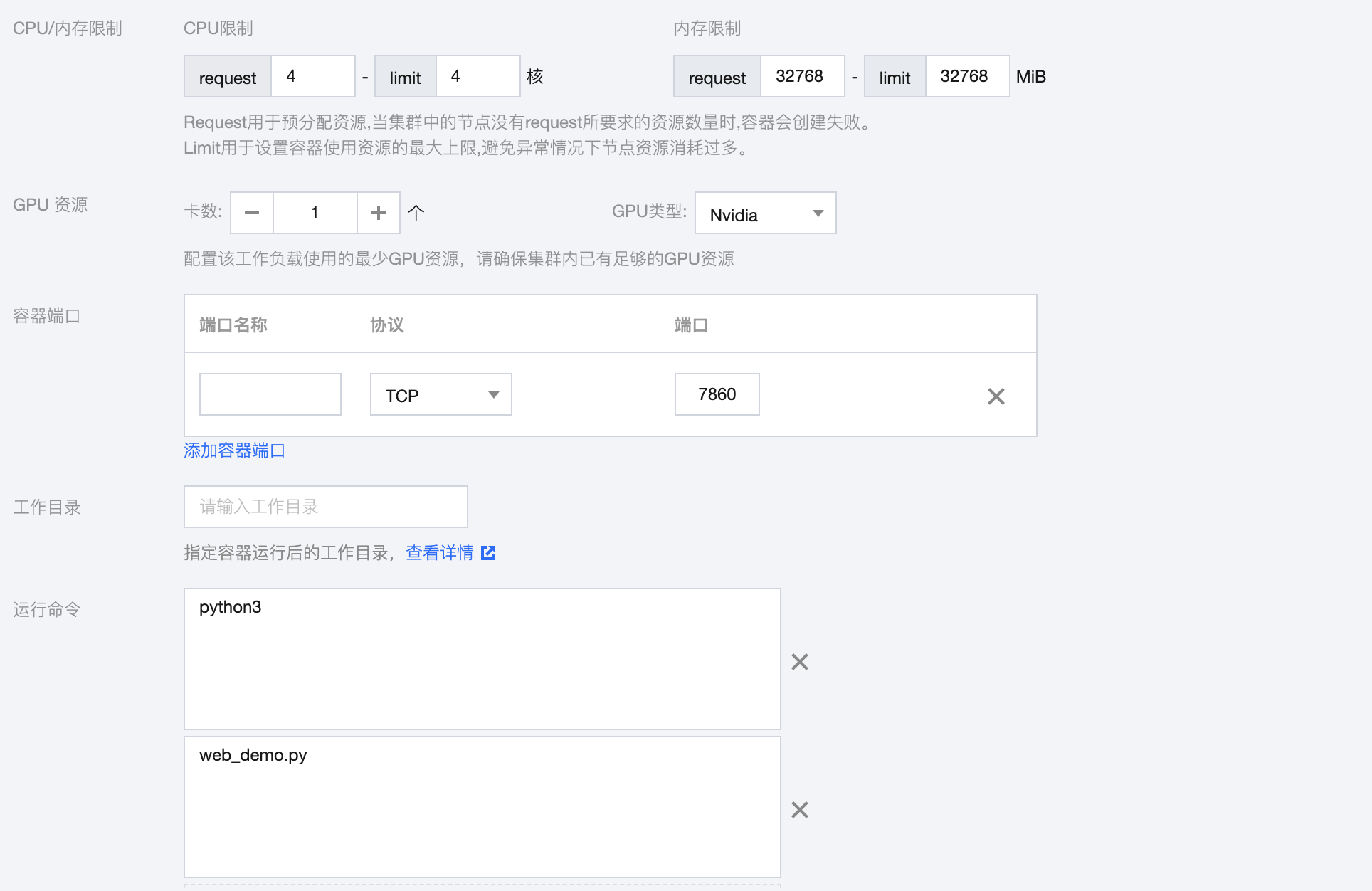
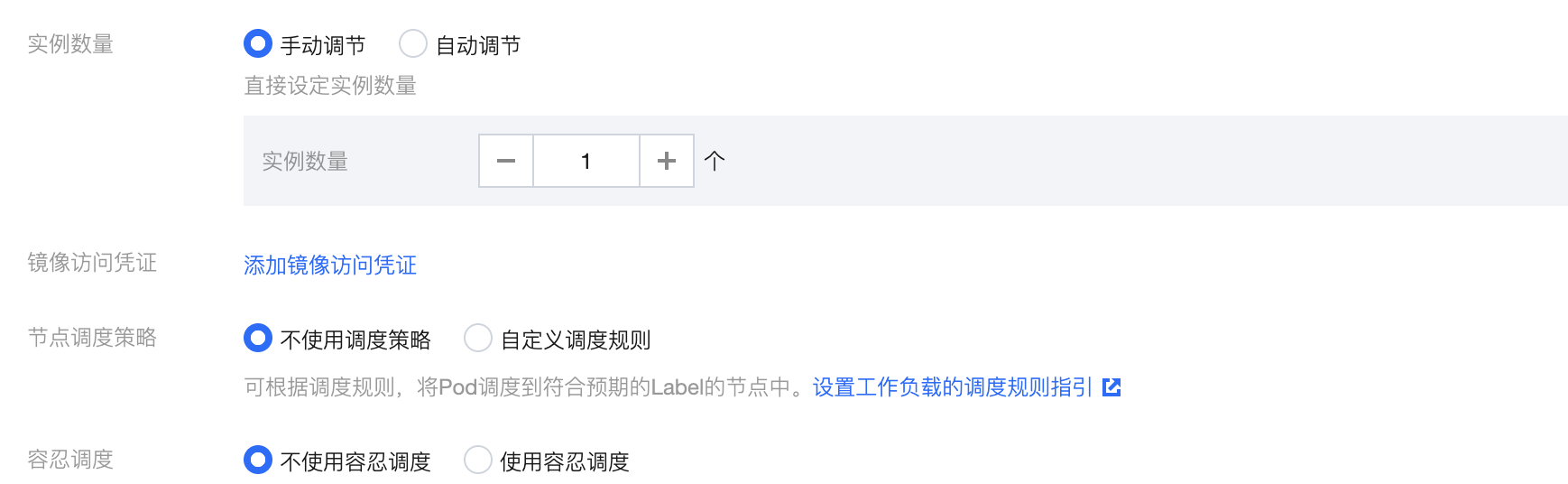
5. 在基本信息中,实例数量选择手动调节,并设置为1个。如下图所示:
6. 为了让外部可访问,在访问设置中,您可参考以下信息进行设置。
服务访问方式:选择公网 LB 访问。
端口映射:将容器端口和服务端口都填写为7860。
7. 设置完成后,单击创建 Deployment,等待 Pod Ready。需注意,由于镜像大小为25GB,因此需要等待一段时间才能完成部署,大致需要等待半小时左右。
8. 选择服务与路由,在 Service 页面获取项目的公网 IP。
在浏览器中输入 http://
IP:7860,即可访问。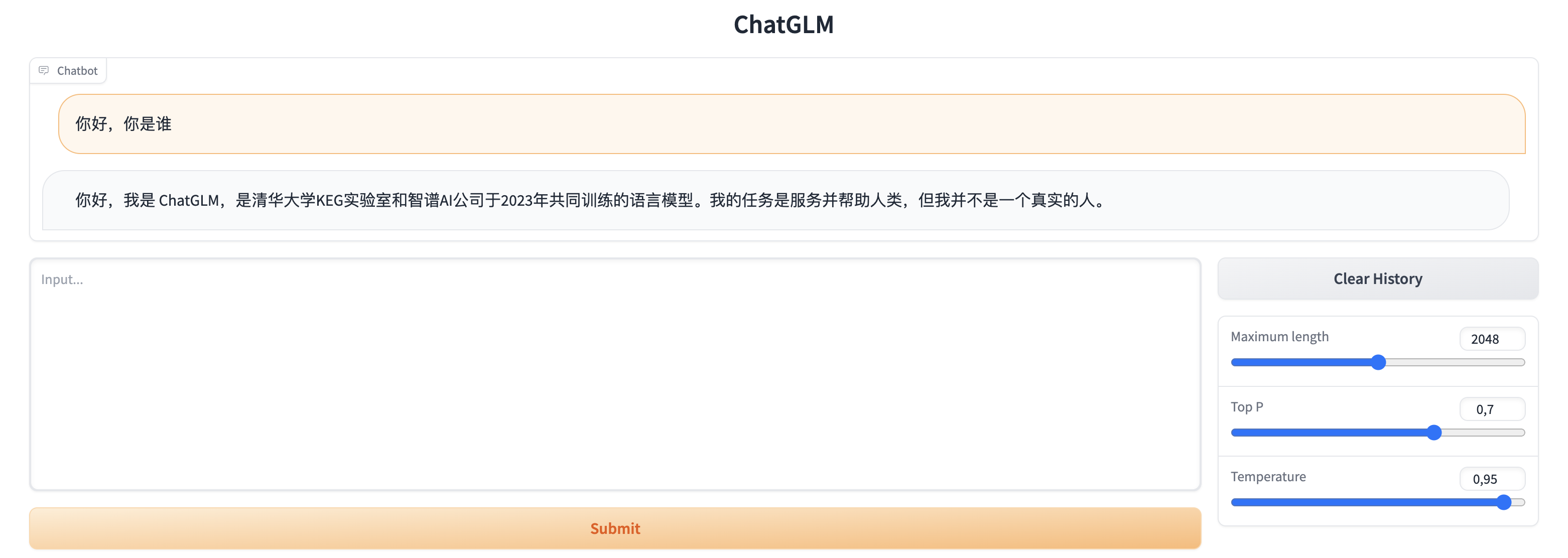
使用 YAML 创建 Deployment
您也可以使用以下 YAML 配置直接创建 Deployment:
apiVersion: apps/v1kind: Deploymentmetadata:name: chatglm-6bspec:replicas: 1selector:matchLabels:app: chatglm-6btemplate:metadata:labels:app: chatglm-6bspec:containers:- name: chatglm-6bimage: ccr.ccs.tencentyun.com/chatglm/chatglm-6b:v1.2command:- python3- web_demo.pyports:- containerPort: 7860resources:limits:nvidia.com/gpu: "1"---apiVersion: v1kind: Servicemetadata:name: chatglm-6b-svcspec:type: ClusterIPports:- port: 7860targetPort: 7860selector:app: chatglm-6b
创建 CPU 版本应用
如果没有 GPU 硬件,ChatGLM-6B 也可以在 CPU 上进行推理,但推理速度会更慢。资源需要大概32GB内存,相比创建 GPU 版本应用,您需要注意以下两点:
1. 内存资源需要32GB。
2. 将 运行命令 改为
python3 web_demo.py cpu。如下图所示: