背景介绍
腾讯云高性能应用服务 HAI 是为开发者量身打造的澎湃算力平台。无需复杂配置,便可享受即开即用的 GPU 云服务体验。在 HAI 中,根据应用智能匹配并推选出最适合的 GPU 算力资源,以确保您在数据科学、LLM、AI 作画等高性能应用中获得最佳性价比。
HAI 服务优势
智能选型 :根据应用匹配推选 GPU 算力资源,实现最高性价比。同时,打通必备云服务组件,大幅简化云服务配置流程。
一键部署 :分钟级自动构建 LLM、AI 作画等应用环境。提供多种预装模型环境,包含如 StableDiffusion、ChatGLM2 等热门模型。
可视化界面 :友好的图形界面,AI 调试更为简单。
场景介绍
体验高性能应用服务 HAI 一键部署 ChatGLM2-6B。
启动 Gradio WebUI 进行对话生成。
步骤一:快速部署
1. 登录 高性能应用服务 HAI 控制台。
2. 单击新建,进入高性能应用服务 HAI 购买页面。
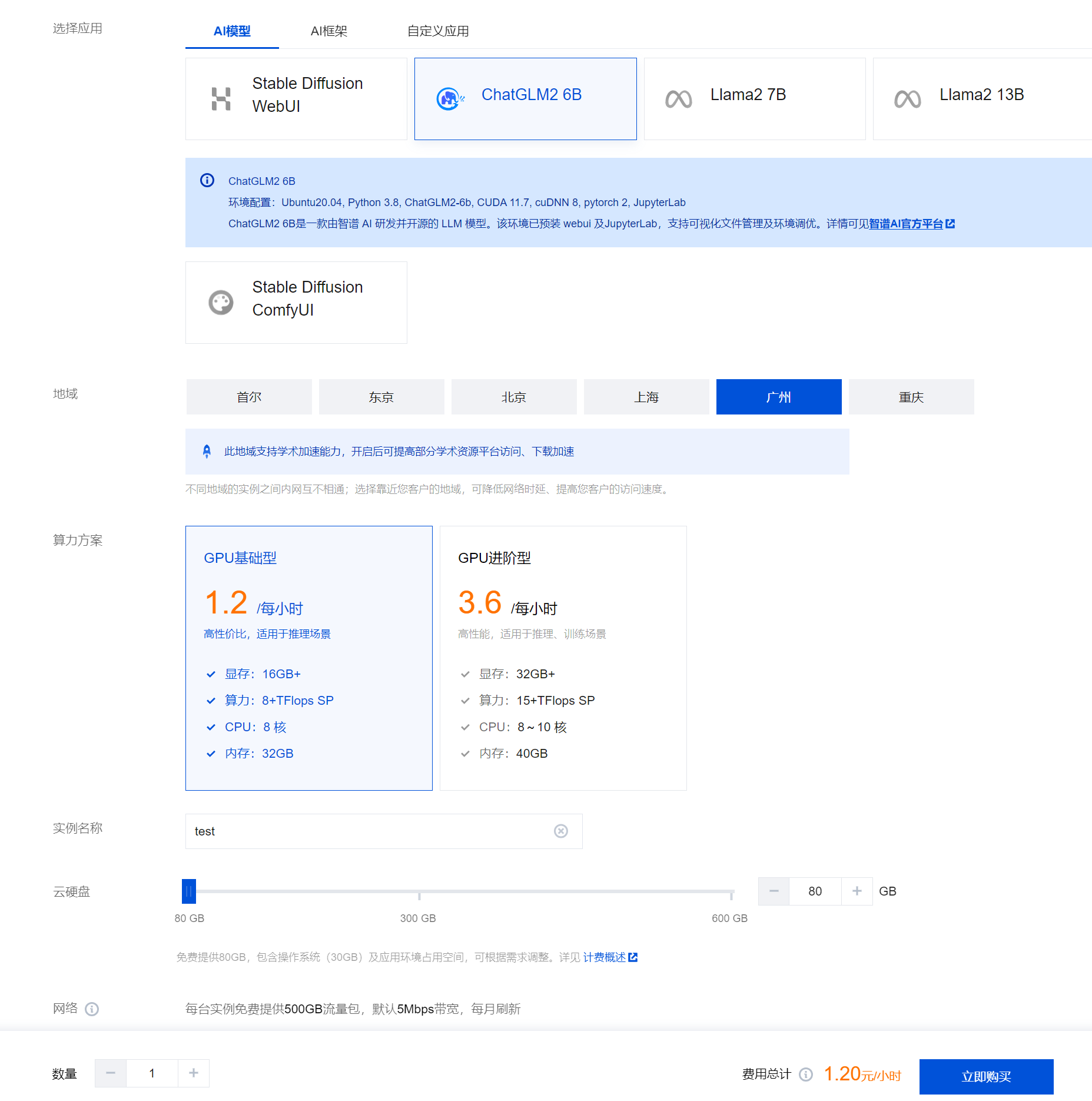
选择应用:目前提供 AI 框架、AI 模型两类应用,请根据实际需求进行选择。
地域:建议选择靠近目标客户的地域,降低网络延迟、提高您的客户的访问速度。
算力方案:本次算力方案选择进阶型,对话生成效率更高。
实例名称:自定义实例名称,若不填则默认使用实例 ID 替代。
硬盘:默认提供 80GB 免费空间,可根据实际使用需求进行调整。
网络:每台实例每月免费提供 500GB 流量包,默认 10Mbps 带宽,每月刷新。
购买数量:默认1台。
3. 单击立即购买。
4. 核对配置信息后,单击提交订单,并根据页面提示完成支付。
5. 等待创建完成。单击实例任意位置并进入该实例的详情页。
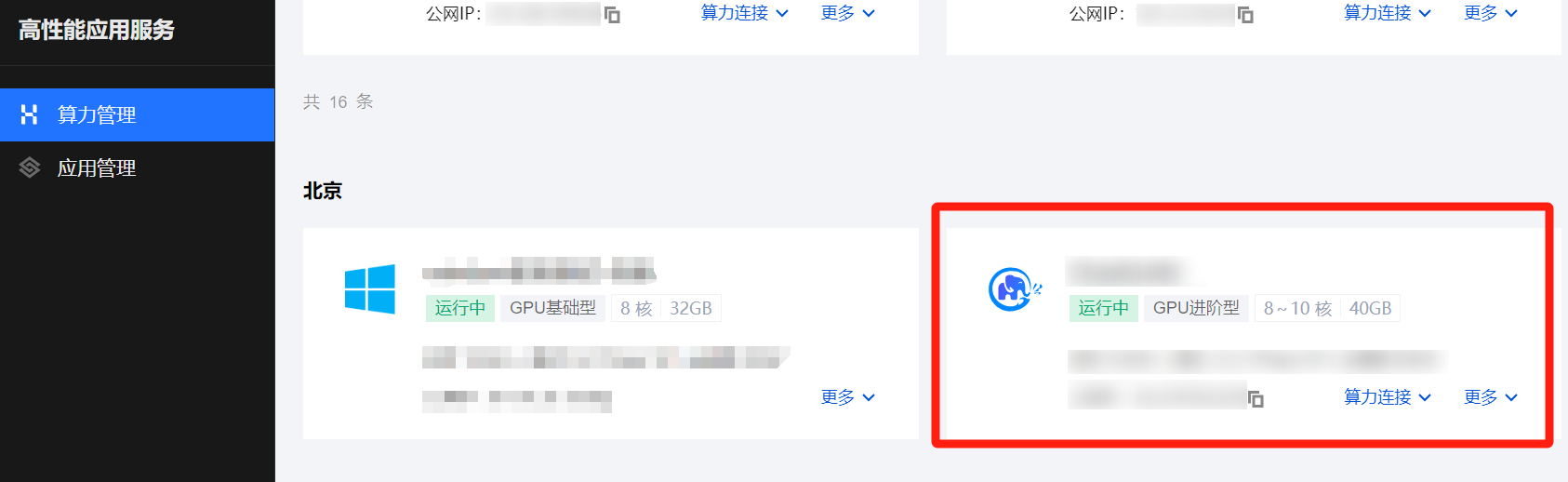
6. 您可以在此页面查看 ChatGLM2-6B 详细的配置信息。
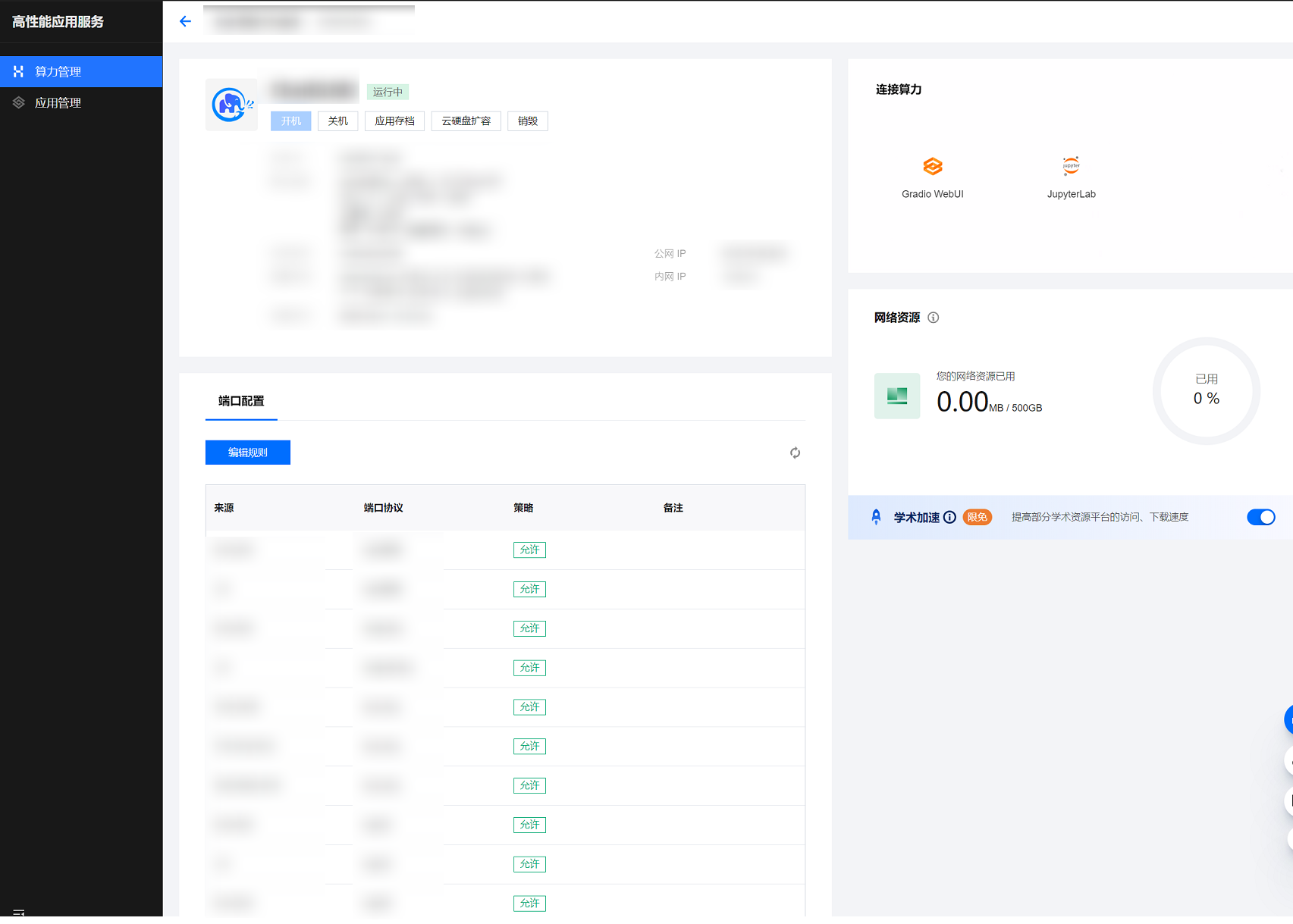
步骤二:启动图形界面
1. 在实例列表中选择算力连接 > Gradio WebUI 并进入该实例的详情页。
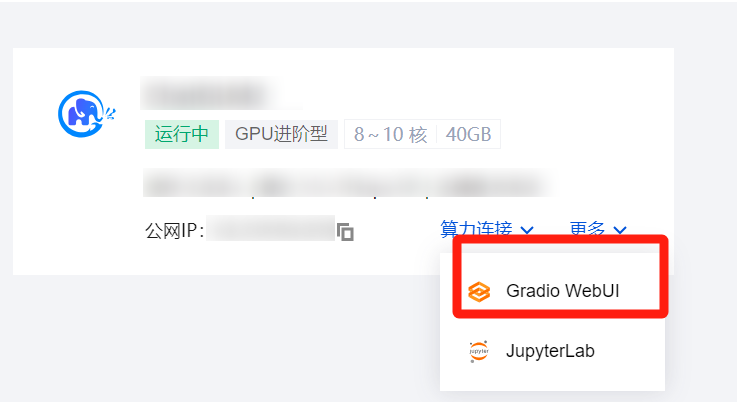
2. 使用高性能应用服务 HAI 部署的 ChatGLM2-6B 体验简单的对话。
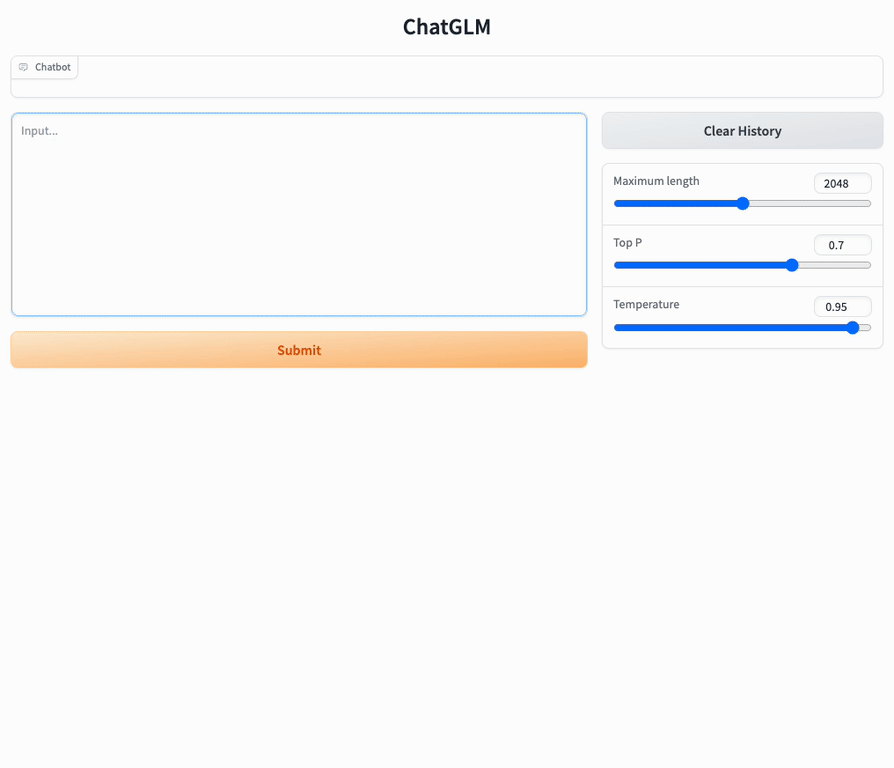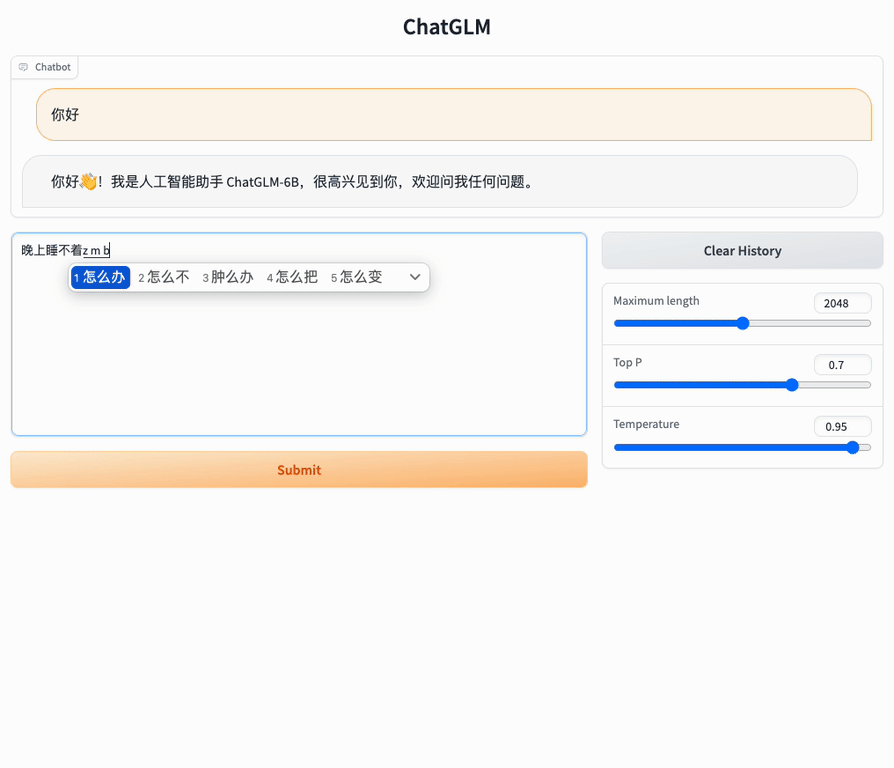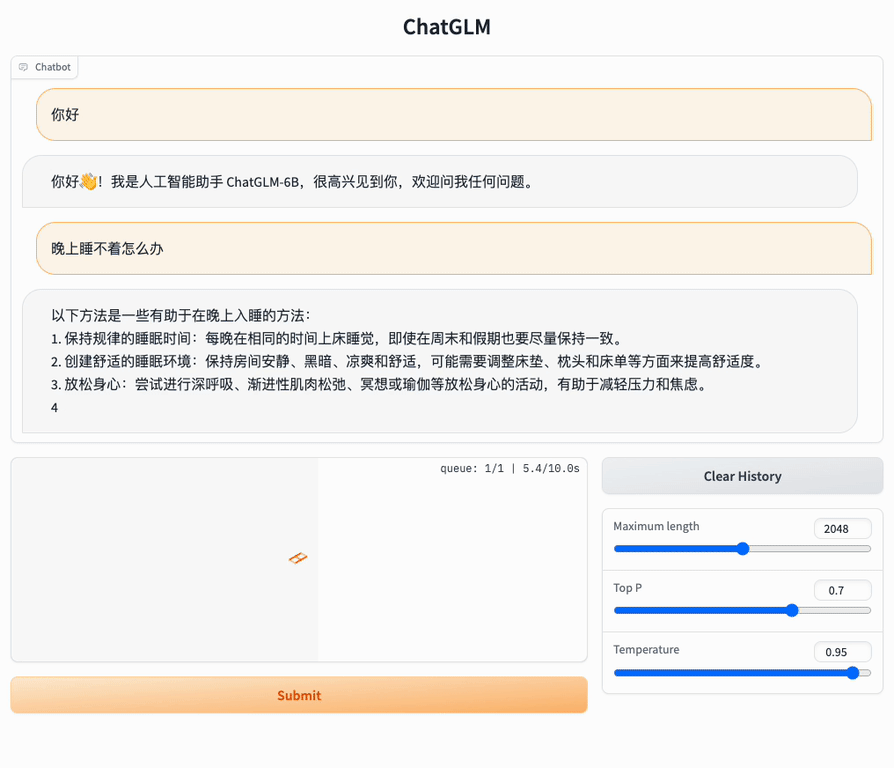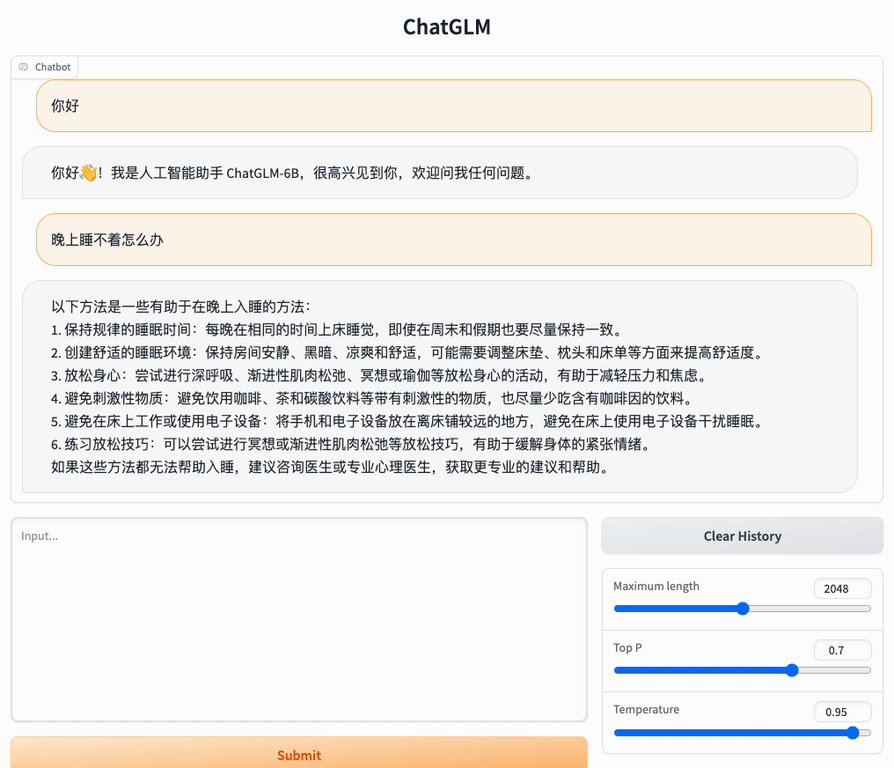
参数说明
Maximum length 参数
通常用于限制输入序列的最大长度。
因为 ChatGLM2-6B 是2048长度推理的,一般这个保持默认就行,太大可能会导致性能下降。
Temperature 参数
用于控制模型输出的结果的随机性。
设置为0,对每个 prompt 都生成固定的输出。
较低的值,输出更集中,更有确定性。
较高的值,输出更随机,更有创意。
Top-p 参数
用于控制模型生成文本的概率分布。
较小的 Top-p 值会导致模型更加倾向于选择高频词汇。
而较大的 Top-p 值则会使模型更加注重选择低频词汇。
合适的 Top-p 值能够平衡生成文本的准确性和多样性。



