本文旨在指导您如何快速部署并使用 DeepSearch,包括开通服务、导入测试数据、深度检索等。
流程解读
DeepSearch 服务的完整使用流程包括:登录控制台开通服务后,获取连接凭据(包括 Endpoint、API Key 和服务 ID),便可通过 HTTP 接口或 Python SDK 进行深度检索体验。
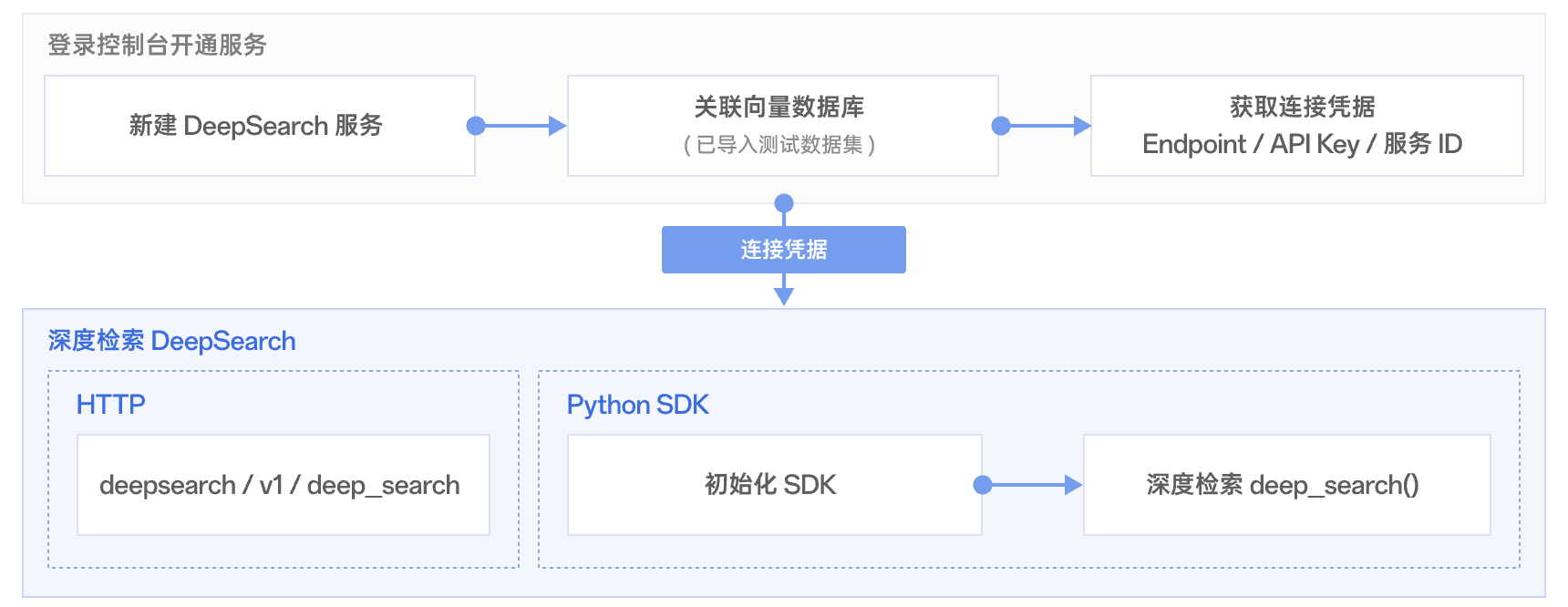
准备工作
已注册腾讯云账号并完成实名认证。
如需注册腾讯云账号:请单击 注册腾讯云账号。
如需完成实名认证:请单击 实名认证。
申请一台与 DeepSearch 服务在同一地域(目前仅开放广州)的云服务器,并确保该服务器与 DeepSearch 网络互通,以获得安全且低延迟的访问体验。
操作步骤
步骤1:开通 DeepSearch 服务
1. 使用腾讯云账号登录 DeepSearch 控制台 页面,配置 DeepSearch 的基本信息,并关联向量数据库实例。若无向量数据库,请根据页面指引,新建向量数据库。具体操作,请参见 新建 DeepSearch。
2. 获取连接凭据:在 DeepSearch 服务列表页面,可看到新建的 DeepSearch 卡片,如下图所示。
DeepSearch ID:将鼠标悬停在 ID 上,单击 ID 可一键复制 DeepSearch ID。
访问地址及密钥:单击卡片,可在服务概览的 API 接入区域获取 DeepSearch 访问地址与访问密钥。
步骤2:准备测试数据
方式1:使用已有库表数据进行深度检索。
说明:
其集合中需要包含检索对应的文本字段,深度检索需要基于原始文本进行匹配、评估。
方式2:使用 Demo 数据进行深度检索。
python batch_upload_files.py \\--vdb_url http://{访问域名}:{端口} \\--vdb_key {访问密钥} \\--user_name root \\--db_name {数据库名称} \\--coll_name {集合名称} \\--data_dir {数据文件夹路径}
方式2:基于已有的向量数据库深度检索,其集合中需要包含检索对应的文本字段,深度检索需要基于原始文本进行匹配、评估。
步骤3:使用 DeepSearch 深度检索
以“怎么配置向量数据库的数据自动删除”为例,通过申请的 CVM 连接并调用 DeepSearch 服务后,依托“Query 拆分→检索→重排序→结果评估”的迭代机制,经过两轮检索优化,最终返回了与用户意图高度匹配的精准答案。
Authorization:配置 DeepSearch 访问密钥。
x-tdai-service-id:配置 DeepSearch ID。
curl -i -k -X POST \\-H 'Content-Type: application/json' \\-H 'Authorization: Bearer *****************************************' \\-H "x-tdai-service-id: tdai-dps-9f3w****" \\https://deepsearch.tdai.tencentyun.com/deepsearch/v1/deep_search \\-d '{"database": "dps_test_db","collection": "dps_test_coll","search": {"query": "怎么配置向量数据库的数据自动删除","query_preprocessing": {"method": "sub_query_split"},"retrieval_config": {"mode": "dense","limit": 3,"retrieval_params": {"ef": 200}},"rerank": {"rerank_model": "bge-reranker-large"},"evaluate_config": {"max_iterations": 3},"limit": 3,"return_execution_details": true}}'
基于测试数据集,深度检索的结果如下所示。
{"id": "1409808654987071492","score": 0.98535156,"text": "## 适用场景\\n\\n某些业务场景下,业务数据的增长很快,并且业务数据的热度随着时间推移会有明显的降低,可以使用 TTL 将热度降低的数据在特定的过期时间时自动清理。例如:在电子商务平台中,用户搜索和浏览行为产生的向量数据,如点击流和用户偏好向量,通常具有很高的时效性。这些数据在短期内对于个性化推荐至关重要,但随着时间的推移,其相关性会迅速降低。在向量数据库集合中,设置TTL,便会自动删除过时的用户行为数据,确保推荐系统能够基于最新的用户互动提供实时、相关的推荐,从而提升用户体验和业务效率。\\n\\n"},{"id": "1409808654987071491","score": 0.46704102,"text": "## 功能介绍\\n\\nTTL(Time to Live,生存周期)功能,指数据项从创建或更新后开始,到自动被系统删除的时间期限。在创建数据库集合时,通过为文档设置TTL,数据库能够自动清理过期的数据,从而优化存储空间的使用,保持数据的时效性,并确保查询结果的准确性,特别是在数据具有时效性要求的场景中,如实时推荐系统等。\\n\\n"},{"id": "1409808654987071496","score": 0.27807617,"text": " .withTtlConfig(TTLConfig.newBuilder().WithEnable(true).WithTimeField(\\"expired_at\\").build())\\n .build();\\n Collection collection = db.createCollection(collectionParam);\\n ```\\n2. 插入向量数据时,指定 TTL 字段 expired_at 过期时间。\\n \\n\\n > **说明:**\\n > \\n\\n > 数据库插入数据,过期时间允许有1个小时的误差。\\n > \\n\\n ``` java\\n"}



