概述
目前默认策略仅支持云服务器-基础监控、云数据库 MongoDB、云数据库-Mysql-主机监控、云数据库 Redis、云数据库-CynosDB-MySQL、云数据库-CynosDB-PostgreSQL、消息服务 CKafka-实例、Elasticsearch 服务、数据传输服务和弹性 MapReduce、负载均衡 CLB。
当您首次成功购买默认策略支持的云产品,告警管理会为您自动创建默认告警策略。如需了解默认策略支持的指标/告警规则,请参见 默认策略说明。
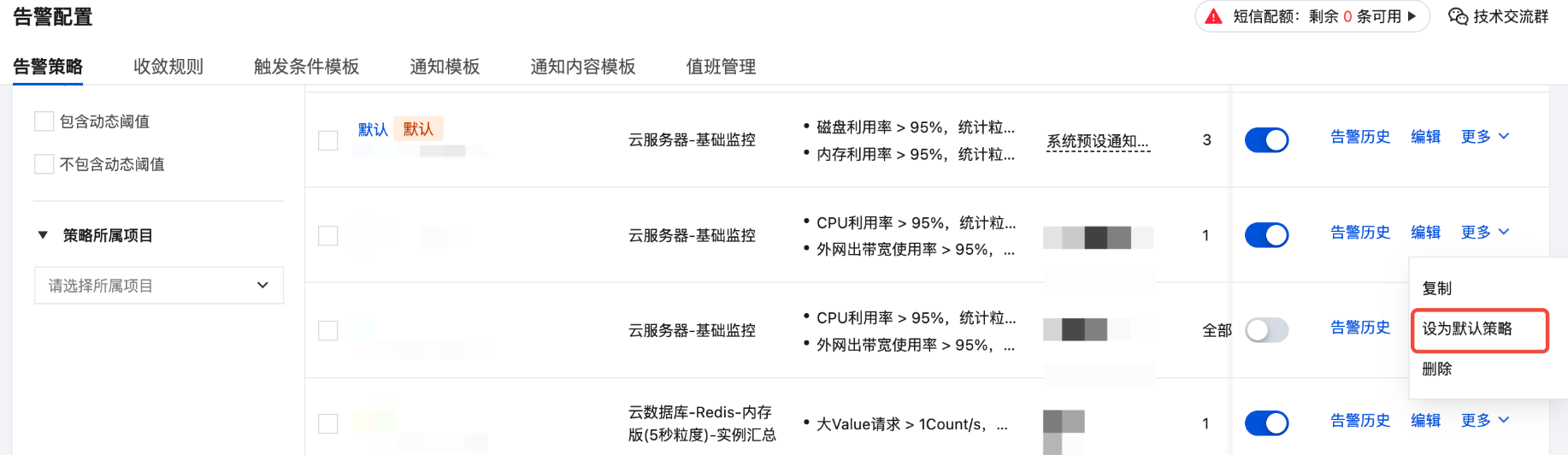
您也可以手动创建告警策略,设为默认告警策略。设置成功后新购买的实例会自动关联默认策略,无需您手动添加。
对于已绑定标签的告警策略,不支持设置默认告警策略。
默认策略说明
产品名称 | 告警类型 | 指标名称 | 告警规则 |
云服务器 | 指标告警 | CPU 利用率 | 统计粒度为1分钟;阈值为>95%;持续监控数据点为5个监控数据点 |
| | 内存利用率 | 统计粒度为1分钟;阈值为>95%;持续监控数据点为5个监控数据点 |
| | 磁盘利用率 | 统计粒度为1分钟;阈值为>95%;持续监控数据点为5个监控数据点 |
| | 外网带宽利用率 | 统计粒度为1分钟;阈值为>95%;持续监控数据点为5个监控数据点 |
云数据库 Mysql-主机监控 | 指标告警 | 磁盘利用率 | 统计粒度为1分钟;阈值为>80%;持续监控数据点为5个监控数据点 |
| | CPU 利用率 | 统计粒度为1分钟;阈值为>80%;持续监控数据点为5个监控数据点 |
云数据库 MongoDB | 指标告警 | 磁盘使用率 | 统计粒度为1分钟;阈值为>80%;持续监控数据点为5个监控数据点 |
| | 连接使用率 | 统计粒度为1分钟;阈值为>80%;持续监控数据点为5个监控数据点 |
云数据库 Redis-CKV 版本/社区版 | 指标告警 | 容量使用率 | 统计粒度为1分钟;阈值为>80%;持续监控数据点为5个监控数据点 |
消息服务 CKafka-实例 | 指标告警 | 磁盘使用百分比 | 统计粒度为1分钟;阈值为>85%;持续监控数据点为5个监控数据点 |
Elasticsearch 服务 | 指标告警 | 平均磁盘使用率 | 统计粒度为1分钟;阈值为>80%;持续监控数据点为5个监控数据点 |
| | 平均 CPU 使用率 | 统计粒度为1分钟;阈值为>90%;持续监控数据点为5个监控数据点 |
| | 平均 JVM 内存使用率 | 统计粒度为1分钟;阈值为>85%;持续监控数据点为5个监控数据点 |
| | 集群健康状态 | 统计粒度为1分钟;阈值为>=1;持续监控数据点为5个监控数据点 |
弹性 MapReduce-主机监控-磁盘 | 指标告警 | 磁盘空间使用率(used_all) | 统计粒度1分钟,阈值为>80%,连续5次满足条件则只告警一次 |
| | inode 使用率 | 统计粒度1分钟,阈值为>50%,连续5次满足条件则只告警一次 |
弹性 MapReduce-主机监控-CPU | 指标告警 | CPU 使用率(idle) | 统计粒度1分钟,阈值为<2%,连续5次满足条件则只告警一次 |
弹性 MapReduce-主机监控-内存 | 指标告警 | 内存使用占比(used_percent) | 统计粒度1分钟,阈值为>95%,连续5次满足条件则只告警一次 |
弹性 MapReduce-HBASE-概览 | 指标告警 | 集群 RS 数量(numDeadRegionServers) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
| | 集群处于 RIT Region 个数(ritCountOverThreshold) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-HBASE-HMaster | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
弹性 MapReduce-HBASE-RegionServer | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
| | Region 个数(regionCount) | 统计粒度1分钟,阈值为>600Count,连续5次满足条件则只告警一次 |
| | 操作队列请求数(compactionQueueLength) | 统计粒度1分钟,阈值为>500Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-HDFS-NameNode | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
| | 缺失块统计(NumberOfMissingBlocks) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-HDFS-DataNode | 指标告警 | XCEIVER 数量(XceiverCount) | 统计粒度1分钟,阈值为>1000Count,连续5次满足条件则只告警一次 |
| | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
弹性 MapReduce-HDFS-概览 | 指标告警 | 磁盘故障 | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
| | 集群数据节点(NumDeadDataNodes) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
| | 集群数据节点(NumStaleDataNodes) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
| | HDFS 存储空间使用率(capacityusedrate) | 统计粒度1分钟,阈值为90%,连续5次满足条件则只告警一次 |
弹性 MapReduce-PRESTO-Presto_Coordinator | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
弹性 MapReduce-PRESTO-Presto_Worker | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
弹性 MapReduce-PRESTO-概览 | 指标告警 | 节点数量(Failed) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-CLICKHOUSE-Server | 指标告警 | partitions 中最大的活跃数据块的数量 | 统计粒度1分钟,阈值为>250Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-HIVE-HiveMetaStore | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
| | DaemonThreadCount | 统计粒度1分钟,阈值为>2000Count,连续5次满足条件则只告警一次 |
| | ThreadCount | 统计粒度1分钟,阈值为>2000Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-HIVE-HiveServer2 | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为:>5s,连续5次满足条件则只告警一次 |
| | DaemonThreadCount | 统计粒度1分钟,阈值为>2000Count,连续5次满足条件则只告警一次 |
| | ThreadCount | 统计粒度1分钟,阈值为>2000Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-YARN-概览 | 指标告警 | 节点个数(NumUnhealthyNMs) | 统计粒度1分钟,阈值为:>0Count,连续5次满足条件则只告警一次 |
| | 节点个数(NumLostNMs) | 统计粒度1分钟,阈值为>0Count,连续5次满足条件则只告警一次 |
弹性 MapReduce-YARN-NodeManager | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
弹性 MapReduce-YARN-ResourceManager | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
弹性 MapReduce-Zookeeper-Zookeeper | 指标告警 | GC 时间(FGCT) | 统计粒度1分钟,阈值为>5s,连续5次满足条件则只告警一次 |
| | ZNODE 个数(zk_znode_count) | 统计粒度1分钟,阈值为>100000Count,连续5次满足条件则只告警一次 |
| | 排队请求数(zk_outstanding_requests) | 统计粒度1分钟,阈值为>50Count,连续5次满足条件则只告警一次 |
负载均衡-公网负载均衡实例 | 指标告警 | 丢弃连接数 | 统计粒度1分钟,阈值为>10个,连续3次满足条件则只告警一次 |
| | 丢弃流入数据包 | 统计粒度1分钟,阈值为>10个,连续3次满足条件则只告警一次 |
| | 丢弃入带宽 | 统计粒度1分钟,阈值为>10MB,连续3次满足条件则只告警一次 |
| | 丢弃出带宽 | 统计粒度1分钟,阈值为>10MB,连续3次满足条件则只告警一次 |
| | 入带宽利用率 | 统计粒度1分钟,阈值为>80%,连续3次满足条件则只告警一次 |
| | 出带宽利用率 | 统计粒度1分钟,阈值为>80%,连续3次满足条件则只告警一次 |



