概述
TKE 弹性推理服务是模型发布为在线服务的核心组件,为开发者屏蔽了底层异构环境的复杂性,并提供了集成高性能引擎、支持多机多卡、PD 分离等高级部署架构的端到端推理能力。本文为您介绍如何使用弹性推理服务部署模型推理服务,并对其进行完整的生命周期管理。
前提条件
在创建推理服务前,请确保您已满足以下条件:
您已经成功开通弹性推理服务平台。
您已经按照 资源管理 的指引,创建了应用集群和资源组,并已导入可用的 CVM 计算节点。
您已拥有腾讯云账号,并具备对相关云资源(如 COS 等)的操作权限。
操作步骤
新建推理服务
新建服务是一个向导式的配置过程,引导您完成从模型选择到资源配置的全部步骤。
1. 登录 容器服务控制台 ,选择左侧导航栏中的弹性推理服务。
2. 在左侧导航栏中,单击推理服务,进入服务列表页面。
3. 单击页面左上角的新建推理服务。
4. 在新建服务页面,依次完成以下基本配置:
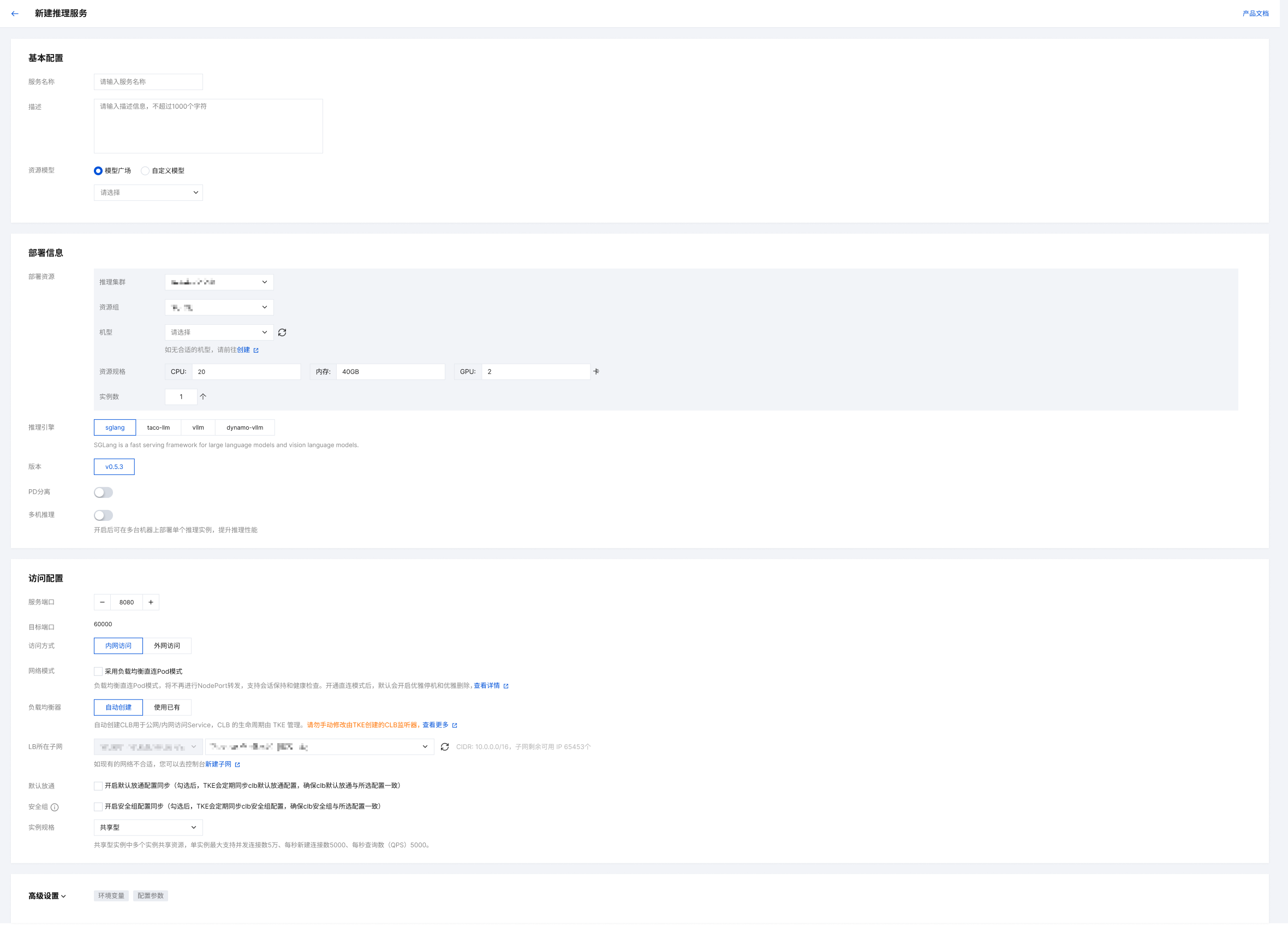
参数名称 | 参数说明 |
服务名称 | 输入一个在您账户下唯一的服务名称,用于标识该推理服务。 |
描述 | 填写服务的描述信息,便于后续识别和管理,此项为选填。 |
资源模型 | |
部署资源 | |
推理引擎 | 根据您的模型和性能需求,选择合适的推理框架,弹性推理服务支持 vLLM、SGLang、TACO-vllm、Dynamo-vllm、 TACO-X。 |
版本 | 选择所使用推理引擎的版本。建议优先选择最新的稳定版本,以获得最佳性能和最新的功能支持。如果您的模型有特定的环境依赖,请选择与之兼容的版本。 |
PD 分离 | 此为针对大语言模型的高级性能优化选项。开启后,系统会将处理提示(Prefill)和生成内容(Decode)的计算任务分配到不同的实例组。适用于访问量大、请求中提示词较长、对响应延迟要求高的业务。 |
多机推理 | 适用于无法由单台机器承载的大模型。开启后,单个服务实例将跨多台机器进行分布式推理,用户可以手动指定一个实例部署的机器数。 |
服务端口与目标端口 | 定义流量访问的端口映射。 服务端口:是负载均衡器(CLB)上暴露给外部访问的端口,例如8080。 目标端口:是运行模型的容器内部实际监听的端口,弹性推理服务限定为60000。 |
访问方式 | 配置服务的网络可访问性。 内网访问:服务只能在同一VPC(私有网络)内被调用,安全性高,适用于集群内部微服务调用场景。 公网访问:平台将自动创建并绑定一个公网CLB,生成一个公网地址,允许从互联网直接访问服务,适用于对外提供API的场景。 |
网络模式 | |
负载均衡器 | 为服务配置流量入口。可选择新建 CLB,由平台自动创建并关联;或选择绑定到账户下已有的 CLB 实例,以复用现有资源和访问入口。 |
LB所在子网 | 为负载均衡器(CLB)实例指定一个部署的子网。请确保所选子网有足够的可用 IP 地址,并规划好网络访问控制(如与后端服务的网络互通性)。 |
默认放通 | 持续同步后端服务器的安全组,以自动放通来自 CLB 的访问流量,确保 CLB 到服务的网络路径始终畅通。 |
安全组 | 持续同步您为 CLB 实例本身绑定的安全组,以确保服务对公网的访问权限始终与您在弹性推理服务中的配置保持一致。 |
实例规格 | 选择实例的性能类型,这将决定其资源隔离级别和网络转发性能。 共享型:实例间共享资源,适用于开发测试或流量较小的业务场景。单实例最大支持并发连接数5万、每秒新建连接数5000、每秒查询数(QPS)5000。 性能容量型:独享转发性能,不受其他实例影响,适用于生产环境或对性能、并发有高要求的业务场景。单实例最大支持并发连接数10,000,000,新建连接数1,000,000,每秒查询数300,000。 |
5. (可选) 您可以展开高级配置,对所选推理框架的参数进行精细化调整,具体参数如下表:
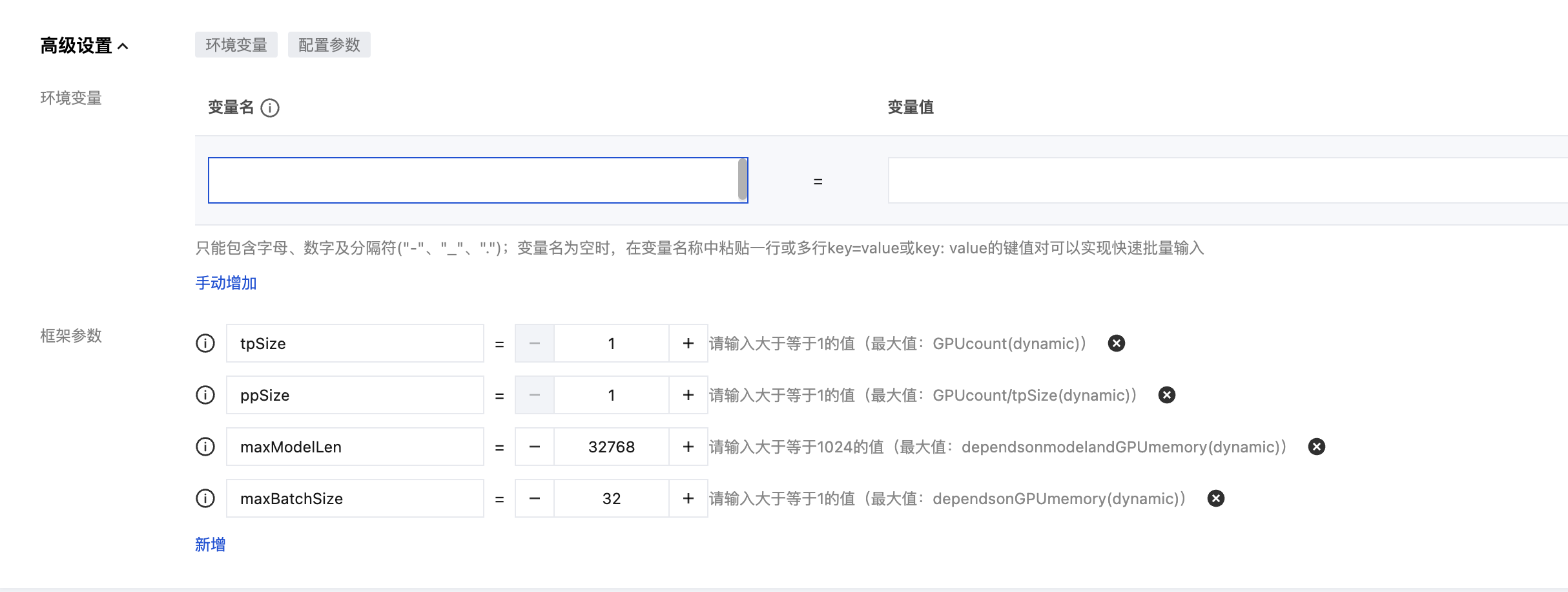
说明:
根据在前面流程中选择的不同的推理引擎,此环节的参数配置会有所不同。
参数名称 | 参数说明 |
环境变量 | 类型:string 说明:以 key=value 的形式为服务容器注入自定义环境变量。 |
最大并发处理数 (maxBatchSize) | 类型:int 说明:推理引擎在单个 batch 中能并行处理的最大请求数量。此值影响服务的并发能力和吞吐量,需根据显存大小进行权衡。 |
最大上下文长度 (maxModelLen) | 类型:int 说明:定义模型能处理的最大序列长度。此值受限于模型的预训练设置和 GPU 显存大小,设置过高可能导致显存溢出。 |
张量并行数 (tpSize) | 类型:int 说明:将模型的权重沿特定维度切分到多个 GPU 上,以减少单个 GPU 的显存占用。是解决大模型单卡无法加载问题的常用方法。 |
流水线并行数 (ppSize) | 类型:int 说明:将模型的不同 Layers 分布到不同的 GPU 上,数据在 GPU 间以流水线方式处理。适用于超大规模模型的训练和推理。 约束:通常与 tp_size 结合使用,tp_size * pp_size 等于您为单个副本分配的总卡数。 |
数据并行数 (dataParallelSize) | 类型:int 说明:将相同的模型副本部署在多个 GPU 上,并将输入数据 batch 切分后并行处理。主要用于提升吞吐量。 |
显存利用率(gpuMemoryUtilization) | 类型:float 说明:设置推理服务可以使用的单张 GPU 显存的比例上限。这个参数用于为 KV Cache 预留空间。KV Cache 的大小是动态的,取决于批次大小和序列长度。 示例 :gpuMemoryUtilization为 0.85 意味着服务会预先分配 85% 的显存用于加载模型权重和计算,剩余的 15% 留作他用或作为安全缓冲。这有助于防止因 KV Cache 增长而导致的显存溢出。 |
单批次最大Token数(maxNumBatchedTokens) | 类型:int 说明:定义了推理引擎在一个批次中能够处理的所有序列的 Token 总数的上限。 |
最大并发处理数(maxNumSeqs) | taco 专属参数,意义同 maxBatchSize。 |
流水线并行数(pipelineParallelSize) | taco 专属参数,意义同 ppSize。 |
张量并行数(tensorParallelSize) | taco 专属参数,意义同 tpSize。 |
6. 确认无误后,单击确定,平台将开始部署您的推理服务。
查看服务状态与详情
服务创建后,您将在推理服务列表页看到新创建的服务及其状态。
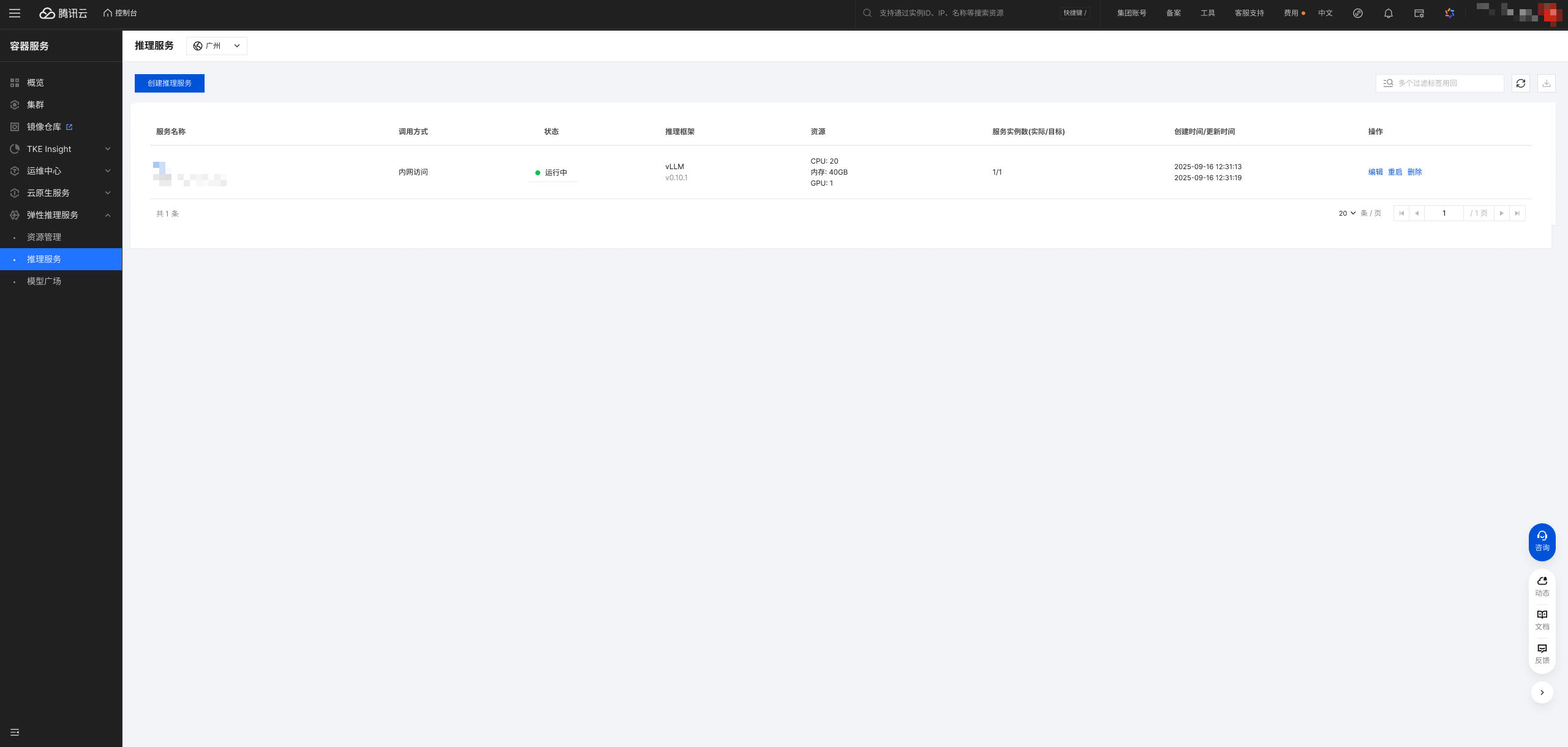
可查看内容:推理服务名、调用方式、运行状态、推理引擎/框架、资源、实例数、创建/更新时间。
运行状态说明:
等待中:服务正在部署过程中,如拉取镜像、加载模型等。
运行中:服务已成功启动并通过健康检查,可以正常接收请求。
异常:服务实例出现错误,无法正常运行。
单击服务名称,即可进入服务详情页面。在此页面,您可以查看:
基本信息:服务的完整配置。
实例列表:服务下所有实例的运行状态、所在节点IP等。
访问方式:服务的内网和公网访问地址及调用示例。
监控:服务的核心性能指标图表,如首字延迟 (TTFT)、字间延迟 (TPOT) 和端到端 (E2E) 请求延迟等。
日志:查看服务实例的实时日志。
YAML:查看该服务在底层 Kubernetes 中的资源定义文件。
管理服务生命周期
在推理服务列表页或详情页,您可以对服务进行以下管理操作:
更新服务:单击编辑,您可以修改服务的资源规格、实例数、弹性配置、高级参数等。
说明:
推理服务的推理框架、部署架构等基础配置在创建后不可变更。
重启服务:单击重启,平台将重新部署服务的所有实例。
删除服务:单击删除,平台将执行优雅下线,并在终止服务前处理完所有进行中的请求,然后释放相关资源。

相关文档
关于如何创建应用集群和资源组,并导入可用的 CVM 计算节点,请参见 资源管理。
关于内置的模型列表,请参见 模型广场。



