概述
池化调度器是 TKE 提供的高性能调度方案,适用于对调度速度有严格要求的场景,可显著提升调度吞吐能力(在未开启其他扩展调度策略的环境下,调度速度约为 2000 pod/s)。
使用限制
1. 集群 Kubernetes 版本需 >= v1.30。
2. 开启高性能模式后,调度效率将显著提升,但会以一定的精度作为代价。调度结果是兼顾性能与精度的局部最优解,以下调度策略的精确性会受到影响:
PodAntiAffinity(反亲和性):不同分片可能将要求互斥的 Pod 调度到同一拓扑域。详细示例请参见 常见问题 - PodAntiAffinity(反亲和性) 影响。
PodTopologySpreadConstraints(拓扑分布约束):各分片仅感知本分片内 Pod 分布,全局 maxSkew 可能超出预期值。详细示例请参见 常见问题 - PodTopologySpreadConstraints(拓扑分布约束)影响。
不支持超级节点本地副本数策略和包月原生节点的副本数策略。
不支持 Crane-scheduler 场景下的部分 PlacementPolicy 策略:单节点池 Pod 数量限制、单节点池调度比例。
3. 默认调度器在 v1.34 中启用的 DynamicResources 插件,在高性能模式下不启用。
配置高性能模式
开启高性能模式
1. 登录 容器服务控制台,选择目标集群。
2. 进入集群详情页,在节点管理中选择 Master&Etcd 页签,单击 kube-scheduler 调度策略右侧的编辑,进入调度器配置编辑页面。
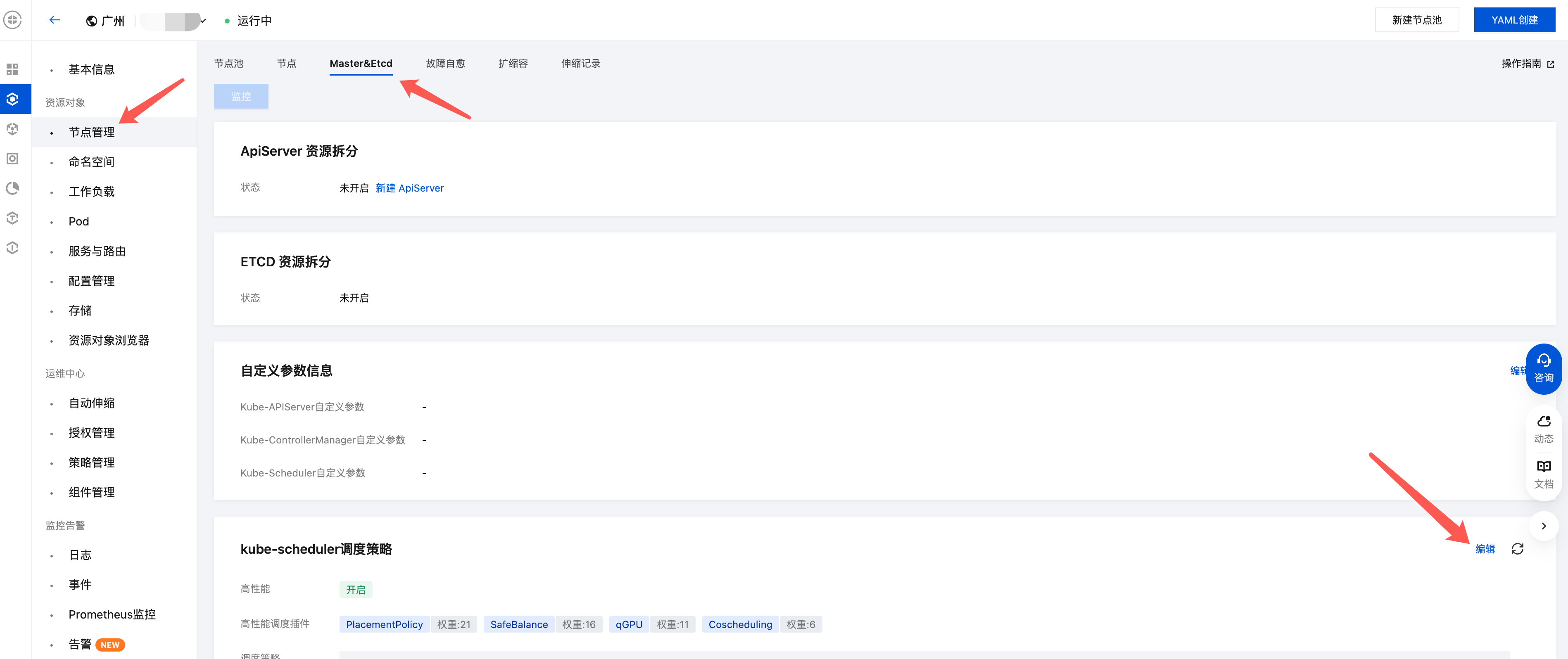
3. 单击开启高性能模式即可。
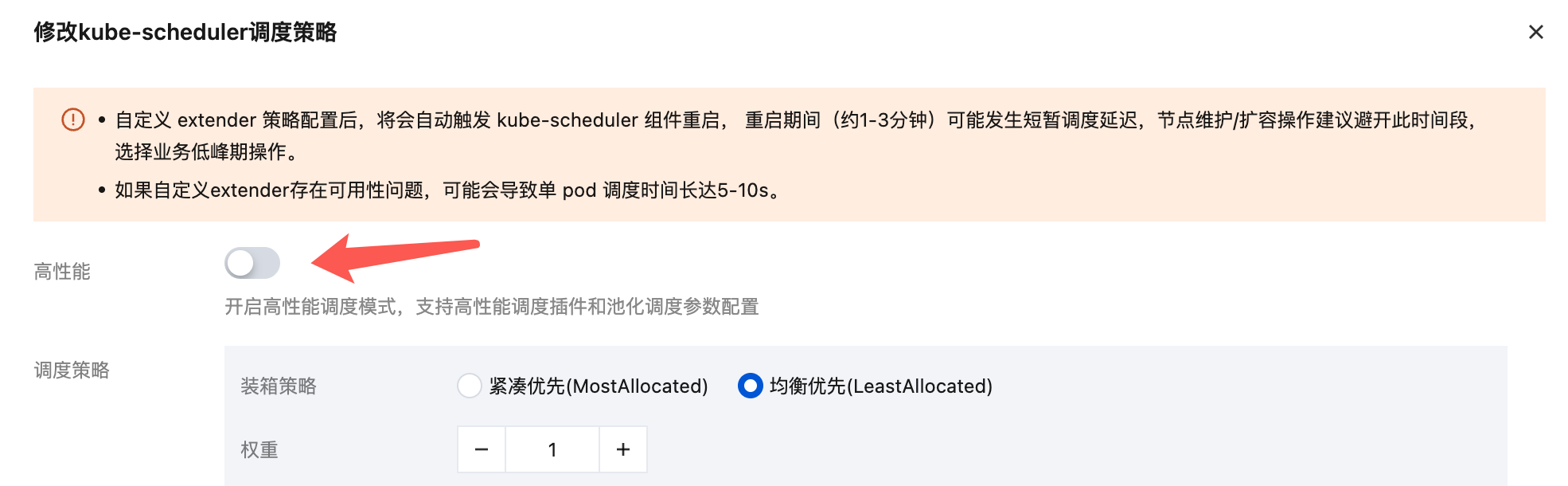
关闭高性能模式
您可在集群详情页关闭高性能模式。关闭后,已集成的调度策略插件(PlacementPolicy、SafeBalance、qGPU、Coscheduling)会被自动关闭,高性能模式相关启动参数也会被自动移除。
说明:
关闭后,如您集群中使用了 Crane、qGPU 相关的调度能力,请重新在组件管理安装对应的 addon 组件。
如果不需要批调度组件,可以在组件管理中卸载 coschedule-sync 组件。
扩展调度策略
高性能模式为全新调度形态,调度策略以插件形式集成到池化调度器。若要扩展调度策略,您需要额外配置插件权重。本节继续介绍:
如何开启批调度能力;
如何将 Crane、qGPU 等策略以插件形式集成到高性能调度器,进一步提升调度性能。详情请参见 扩展其他调度策略。
开启批调度能力
批调度可确保一组关联的 Pod 全部成功调度或全部等待,适用于大数据、AI 训练等场景。启用该特性前,集群需已开启高性能模式。
开启批调度
步骤一:安装 coschedule-sync 组件
1. 登录 容器服务控制台,选择目标集群。
2. 进入组件管理页面,选择新建。
3. 在调度分类下找到 coschedule-sync 组件,勾选并单击完成即可安装组件。
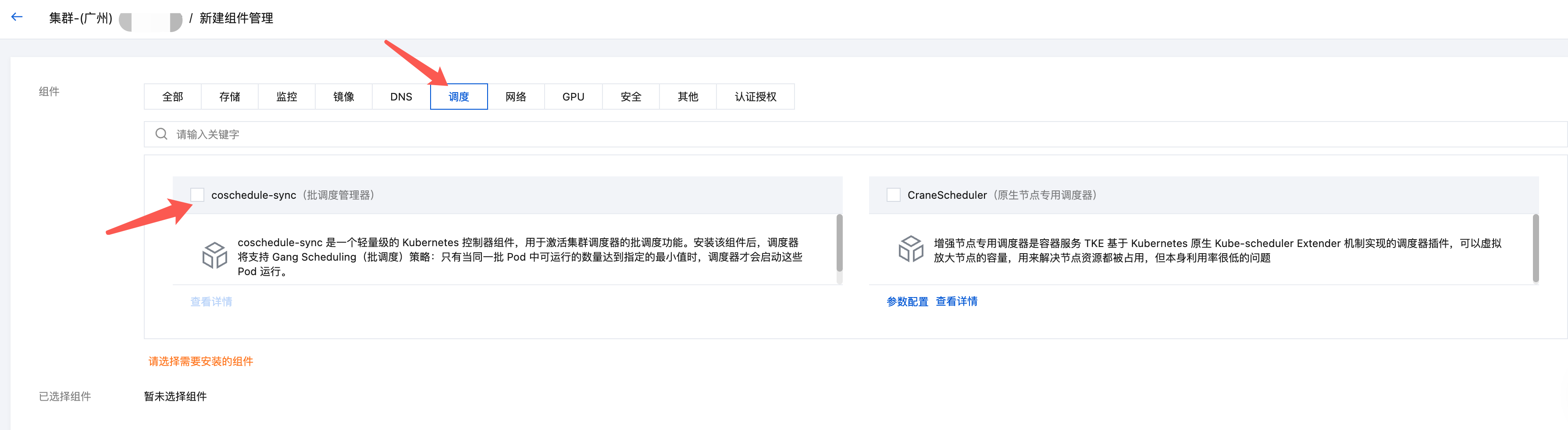
步骤二:开启 Coscheduling 插件
1. 确认上一步中的 coschedule-sync 组件已安装完成。
2. 进入集群详情页,在节点管理中选择 Master&Etcd 页签,单击 kube-scheduler 调度策略右侧的编辑,进入调度器配置编辑页面。
3. 将 Coscheduling 插件权重设置为 1 即开启 Coscheduling 插件。
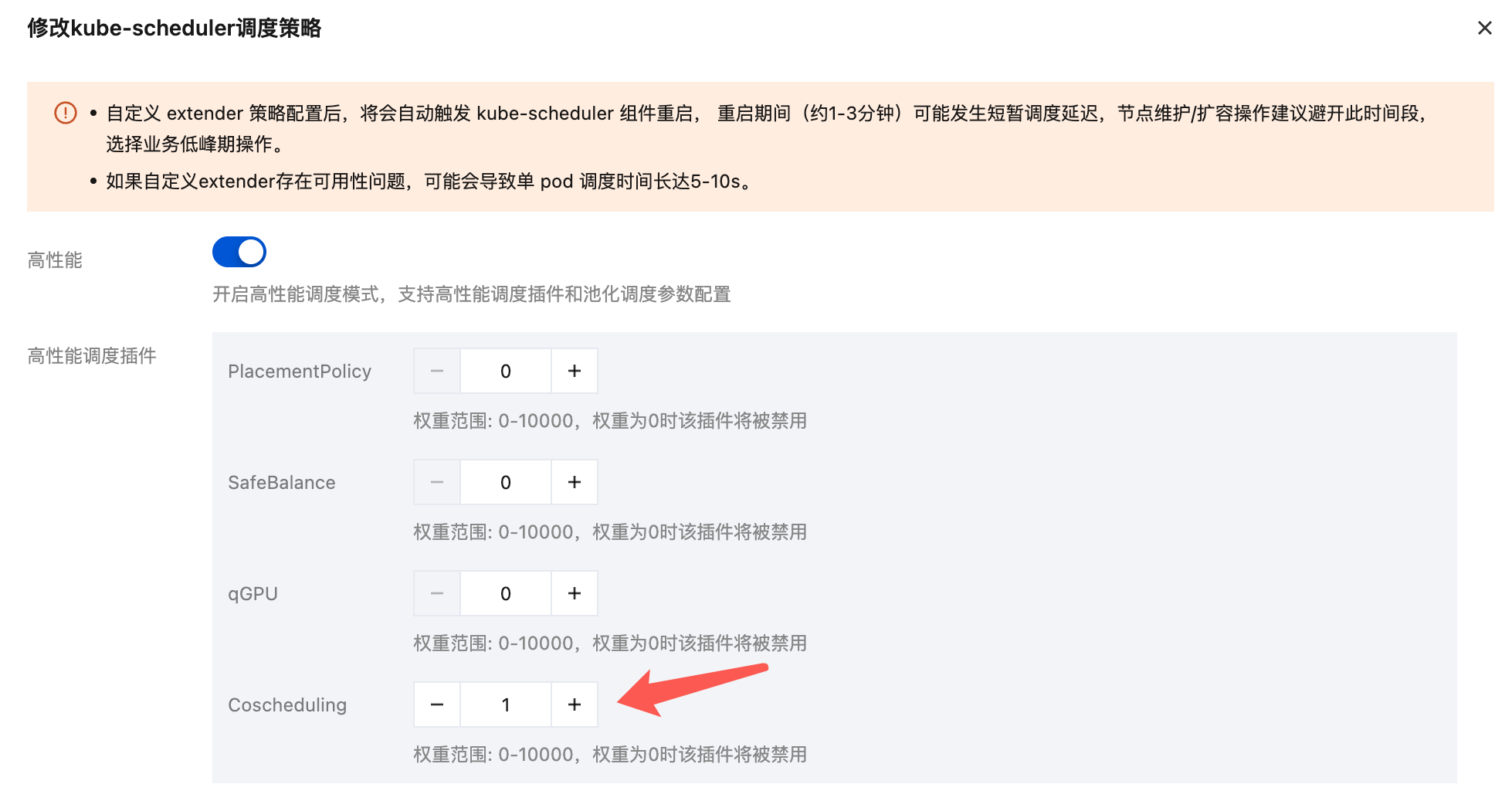
4. 等待调度器重启生效。
关闭批调度
1. 在调度插件管理页面,将 Coscheduling 权重设置为 0 即可关闭 Coscheduling 插件。
2. 等待调度器重启生效。
3. (可选)进入组件管理页面,找到 coschedule-sync 组件,单击删除。
集成其他调度策略插件
开启高性能模式后,您可以将原本以 Extender 方式运行的 Crane、qGPU 等调度策略,以插件(Plugin)形式集成到池化调度器中,进一步提升调度性能。可集成的插件包括:
插件名称 | 说明 | 权重推荐 |
PlacementPolicy | Crane 调度能力,用于自定义节点池的调度优先级 | 10000 |
SafeBalance | Crane 基于负载感知的调度能力 | 20 |
qGPU | GPU 共享调度 | 10 |
Coscheduling | Gang 调度能力 | 1 |
说明:
以上策略适用的节点类型不会因为开启高性能模式后发生变化。
开启插件
使用 Crane 的调度能力,即在高性能调度插件开启 PlacementPolicy 和 SafeBalance 插件,需要关闭 crane-scheduler Extender。
如果要用 qGPU 的调度能力,即在高性能调度插件开启 qGPU 插件,需要关闭 qgpu-scheduler Extender。
步骤二:开启插件
1. 进入集群详情页,在节点管理中选择 Master&Etcd 页签,单击 kube-scheduler 调度策略右侧的编辑,进入调度器配置编辑页面。
2. 在高性能调度插件选择需要开启的插件,配置对应的权重即可开启,权重推荐值如下图。
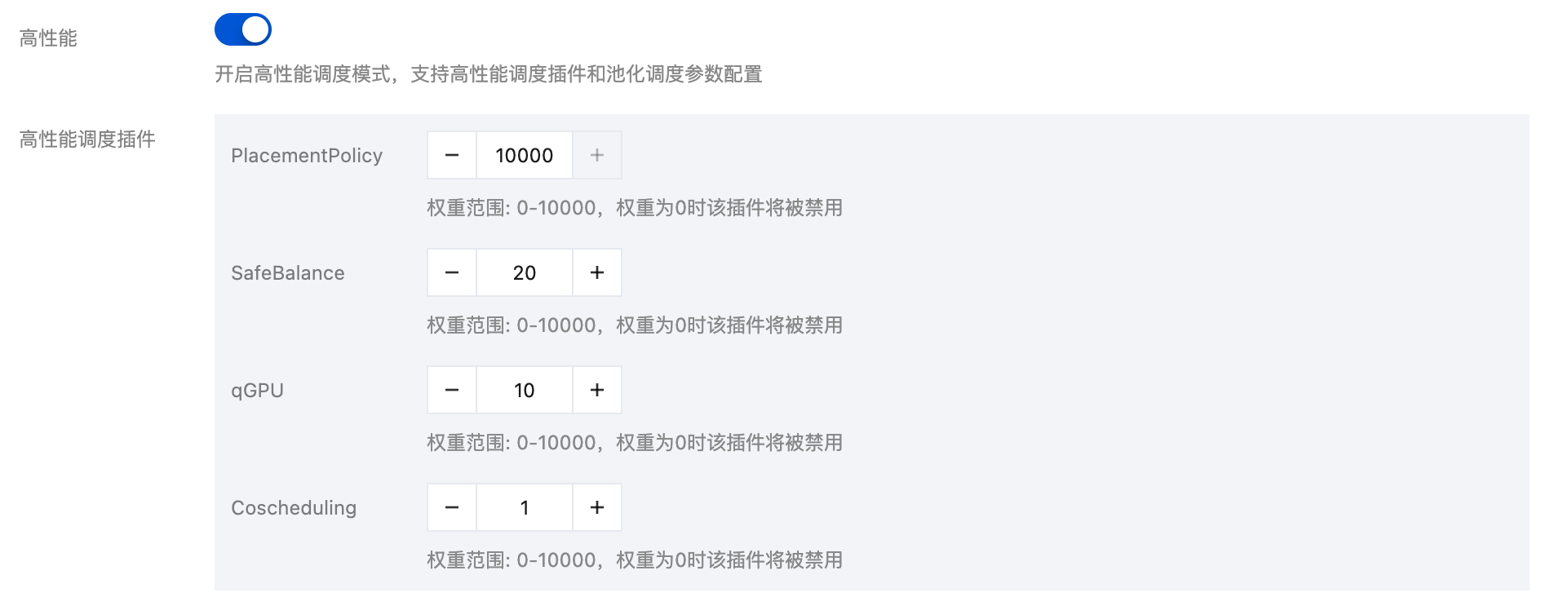
3. 等待调度器重启生效。
修改插件权重
1. 进入集群详情页,在节点管理中选择 Master&Etcd 页签,单击 kube-scheduler 调度策略右侧的编辑,进入调度器配置编辑页面。
2. 在高性能调度插件选择需要调整的插件,配置对应的权重即可,其中将权重配置为 0 即可关闭。
3. 等待调度器重启生效。
删除 Extender
将调度策略以插件形式集成到池化调度器后,需删除冗余的 Extender,提升调度速度。
注意:
该操作仅在开启高性能模式下适用。
支持的 Extender
名称 | 说明 |
qgpu-scheduler | qGPU 调度扩展,包含 qGPU 插件。 |
crane-scheduler | Crane 调度扩展,包含 PlacementPolicy 和 SafeBalance 两个插件。 |
操作步骤
1. 进入集群详情页,在节点管理中选择 Master&Etcd 页签,单击 kube-scheduler 调度策略右侧的编辑,进入调度器配置编辑页面。
2. 在高级设置中找到系统 extender,在 Extender 列表中找到目标 Extender,点击「删除」。
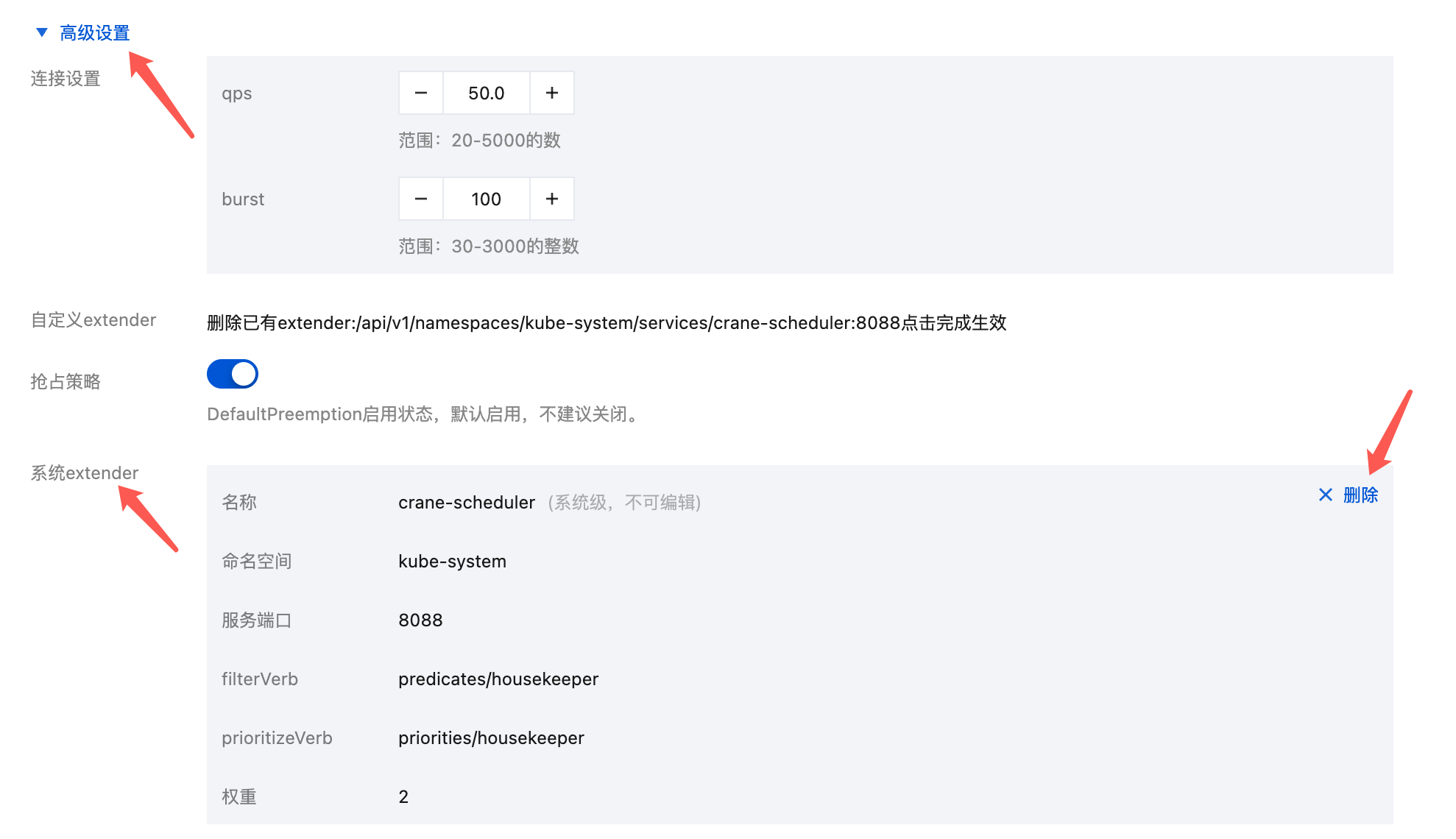
3. 等待调度器重启生效。
注意:
当关闭高性能模式时,如需重新使用 Crane 和 qGPU 能力,请重新安装对应的 addon 组件。
调度器启动参数配置
前置条件:已开启高性能模式。
支持的参数
参数 | 取值范围 | 说明 |
pooling-sharding-count | 2~100 | 分片数量,默认为 10 |
pooling-key-labels | 自定义字符串 | 表示使用哪些 label 平衡各分片的节点数量 |
操作步骤
1. 进入集群详情页,在节点管理中选择 Master&Etcd 页签,单击 kube-scheduler 调度策略右侧的编辑,进入调度器配置编辑页面。
2. 在高级设置中找到池化调度启动参数。
3. 在启动参数区域修改对应的参数值。
4. 等待调度器重启生效。
说明:
关闭高性能模式时,这些参数会被自动移除。
常见问题
1. PodAntiAffinity(反亲和性) 影响
核心逻辑:确保同一服务的 Pod 绝不出现在同一个拓扑域(如 Zone)。
1. 场景设定:
分片 A:管理 Zone-1 的部分节点。
分片 B:管理 Zone-1 的另一部分节点。
调度需求:部署 2 个副本,要求
topologyKey: zone 反亲和(即:一个 Zone 只能有一个 Pod)。2. 失效过程:
分片 A 收到 Pod-1 请求,检查发现自己管辖的 Zone-1 节点上没有该 Pod,于是将其部署在 Zone-1。
分片 B 同时收到 Pod-2 请求,由于并行调度逻辑,它不知道分片 A 已经在 Zone-1 部署了 Pod,它检查自己管辖的 Zone-1 节点也是空的。
3. 结果: 最终两个 Pod 都落在了 Zone-1,直接违反了“跨 Zone 隔离”的初衷。
2. PodTopologySpreadConstraints(拓扑分布约束)影响
核心逻辑:严格控制不同拓扑域(例如 Zone)之间 Pod 数量的差值(Skew)。
1. 场景设定:
策略要求:
maxSkew: 1(不同 Zone 间的数量差不能超过 1)。物理分布:集群包含 Zone 1 和 Zone 2。
2. 分片视角(局部决策):
分片 A(管辖节点子集):
Zone 1 已有:1 个 Pod
Zone 2 已有:2 个 Pod
差值:1 (符合要求)
分片 B(管辖节点子集):
Zone 1 已有:0 个 Pod
Zone 2 已有:1 个 Pod
差值:1 (符合要求)
3. 全局结果:
将各分片数据汇总后:
Zone 1 总计:1 (分片 A) + 0 (分片 B) = 1
Zone 2 总计:2 (分片 A) + 1 (分片 B) = 3
全局差值:2
结果: 全局 maxSkew 达到了 2,违反了
maxSkew: 1 的限制,导致分布不均。



