监控与告警是保证 GPU 服务器高可靠性、高可用性和高性能的重要部分。创建 GPU 服务器时,默认免费开通腾讯云可观测平台。您可以通过 云服务器控制台 查看监控指标,详细说明请参见 云服务器监控指标。NVIDIA GPU 系列实例另外提供了监控 GPU 使用率,显存使用量,功耗以及温度等参数的能力。
GPU 云服务器监控指标告警订阅及处理建议。
1. GPU 云服务器监控指标查看
单台 GPU 云服务器监控指标查看

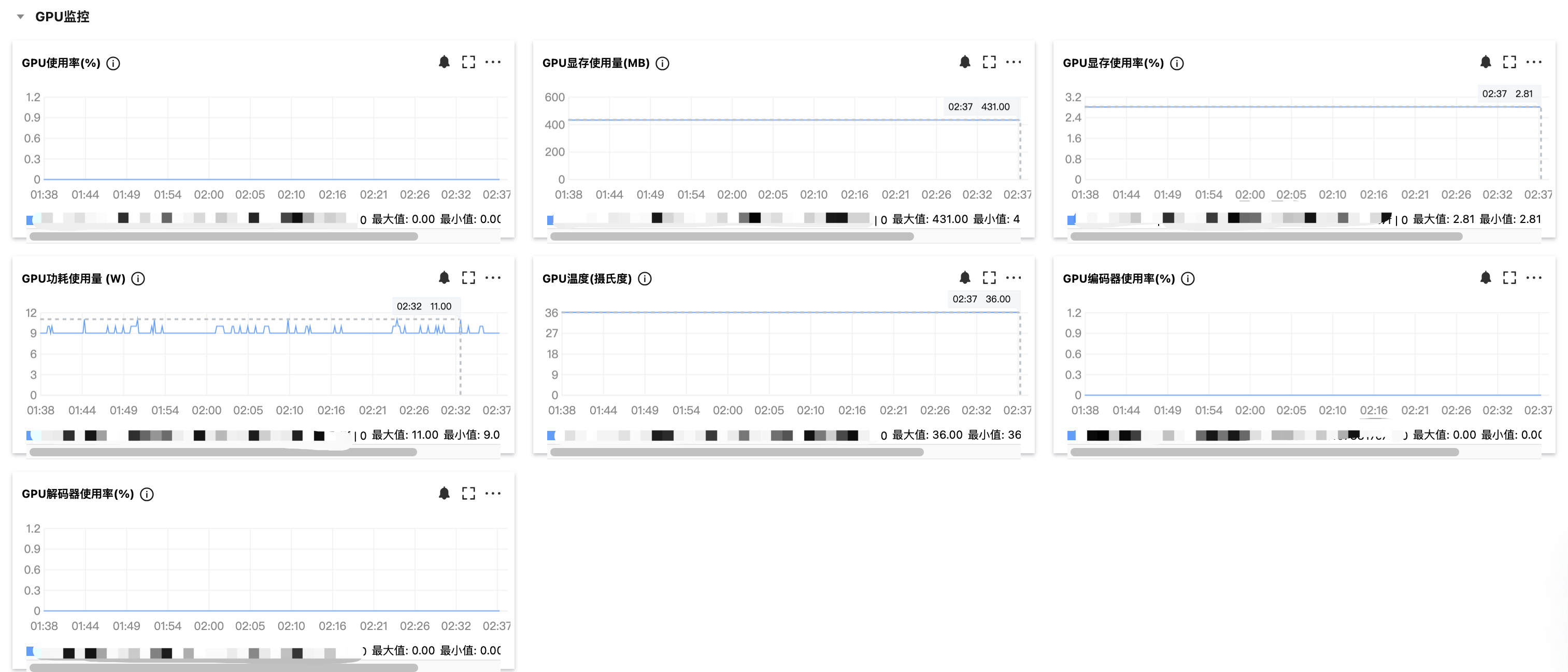
多台 GPU 云服务器监控指标查看
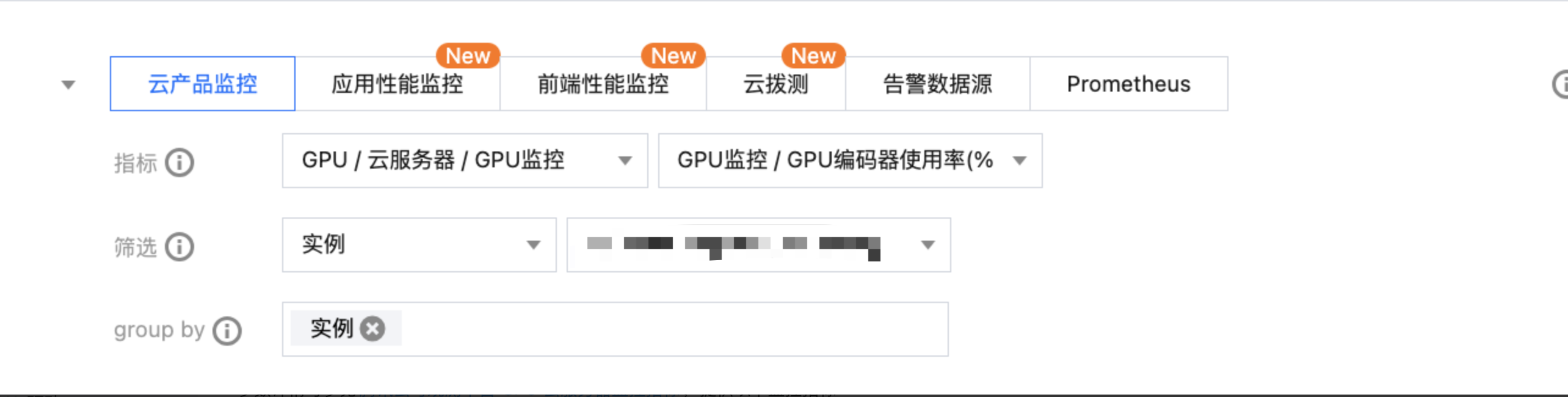
登录 腾讯云可观测平台,左侧导航栏中选择 Dashboard ,进入 Dashboard 列表页。创建 Dashboard 后,在指标处选择 GPU/ 云服务器 /GPU 监控,单击您关注的指标,自定义监控面板进行多实例展示,如下图所示:
2. GPU 云服务器监控指标说明
GPU 云服务器各个监控指标含义如下所示:
指标英文名 | 指标中文名 | 指标说明 | 单位 | 采集方式 | 统计规则 [period, statType] |
GpuMemTotal | GPU 内存总量 | GPU 内存总量 | MB | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
Gpumemusage | GPU 内存使用率 | GPU 内存使用率 | % | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
GpuMemUsed | GPU 内存使用量 | 评估负载对显存占用 | MB | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
Gpupowdraw | GPU 功耗使用量 | GPU 功耗使用量 | 0 | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
Gpupowlimit | GPU 功耗总量 | GPU 功耗总量 | 0 | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
Gpupowusage | GPU 功耗使用率 | GPU 功耗使用率 | % | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
Gputemp | GPU 温度 | 评估 GPU 散热状态 | 0 | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
Gpuutil | GPU 使用率 | 评估负载所消耗的计算能力,非空闲状态百分比 | % | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
GpuEncUtil | GPU 编码器使用率 | GPU 编码器使用率 | % | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
GpuDecUtil | GPU 解码器使用率 | GPU 解码器使用率 | % | nvml | [10s, avg] [60s, avg] [300s, avg] [3600s, avg] [86400s, avg] |
3. GPU 云服务器监控指标告警配置
腾讯云可观测平台 支持分析更丰富的 GPU 监控指标。您可登录 腾讯云可观测平台,左侧导航栏中选择告警配置,新建告警策略,监控类型选择云产品监控,策略类型选择云服务器 /GPU 监控告警,选择预期告警的 GPU 实例对象,触发条件选择手动配置。
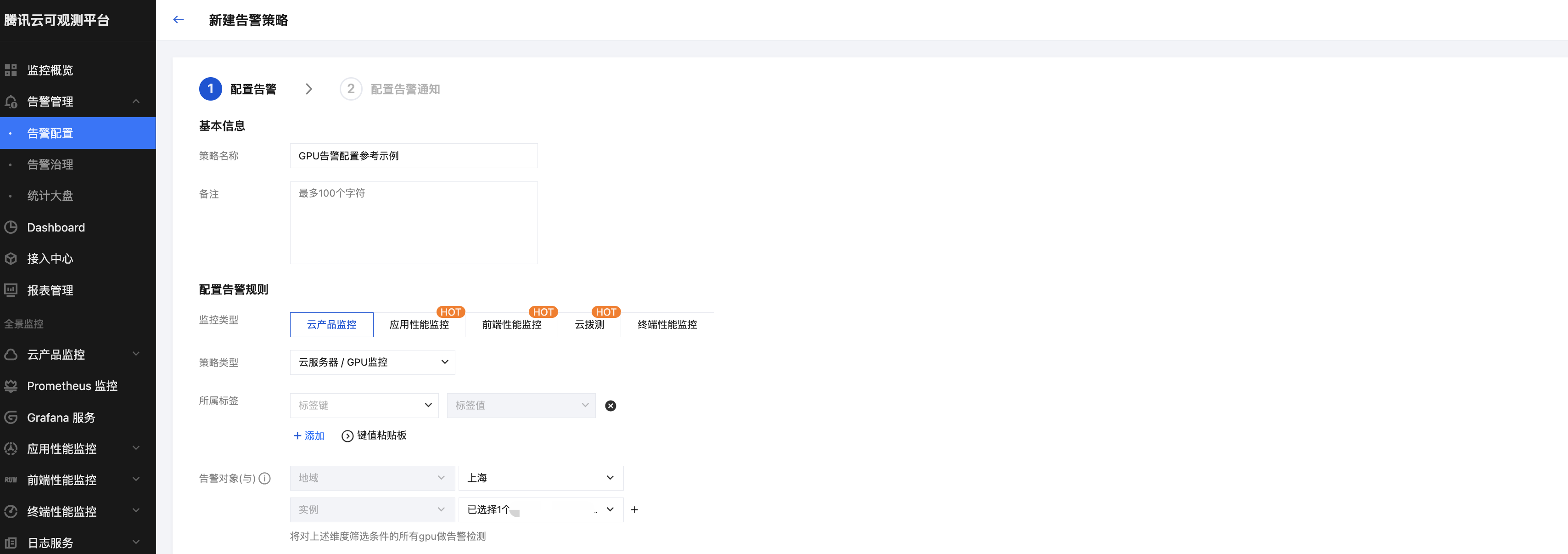
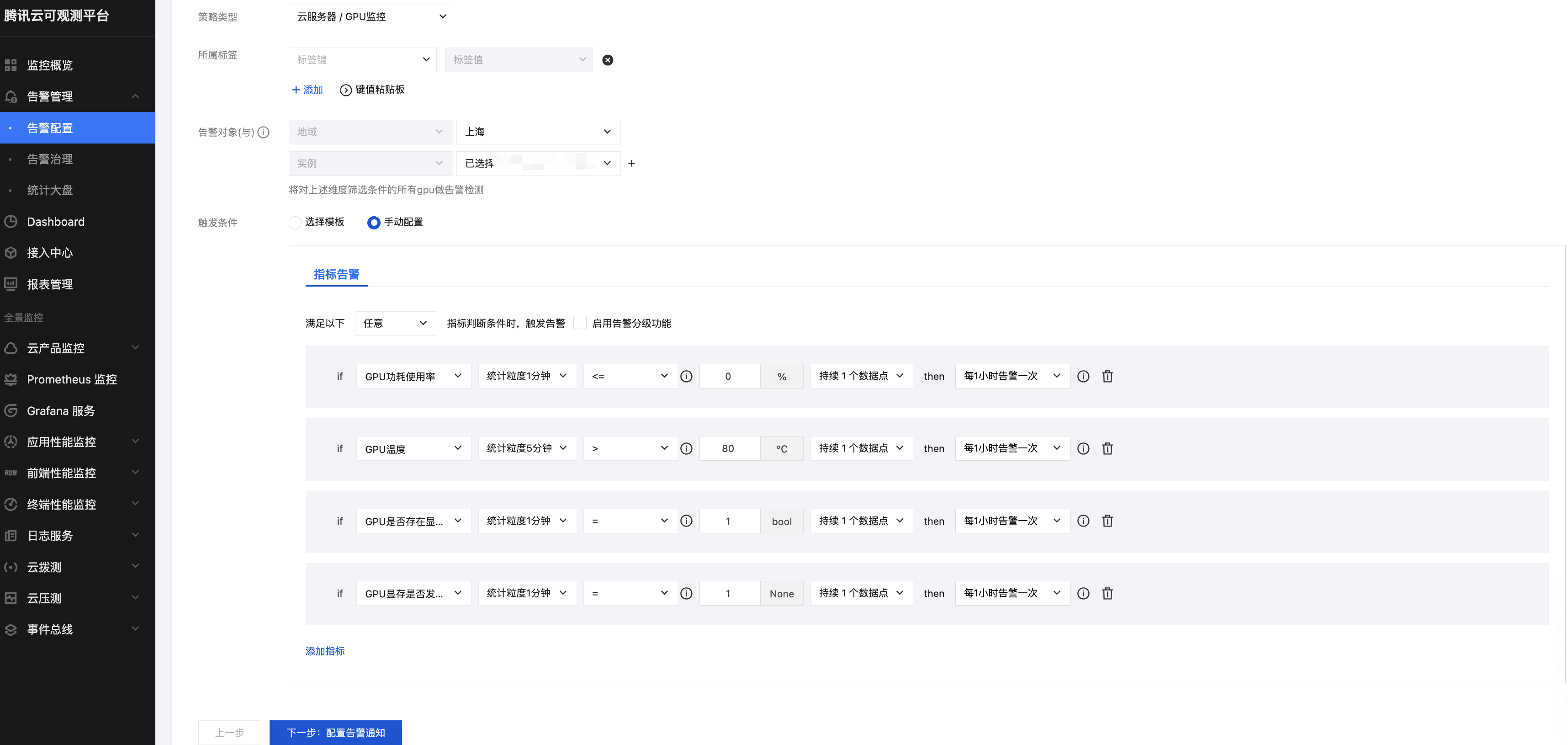
GPU 云服务器监控支持 GPU 内存使用率,GPU 功耗使用率,GPU 使用率,GPU 温度,GPU 是否存在显存页需隔离,GPU 显存是否发生 UCE 等指标告警,可参考下图进行配置告警。
4. GPU 云服务器告警处理建议
指标名称 | 建议告警阈值 | 描述 | 处理建议 |
GPU 功耗使用率 | <=0 | 功耗小于0时可能功率出现Unknown Error 了,会影响 GPU 的正常使用。 | 执行 nvidia-smi 命令查看 GPU 的功率是否有 ERR 或 nvidia-smi -i <target gpu> -q |grep "Power Draw" 是否为 Unknown Error,若存在该现象则尝试重启机器恢复及更新驱动观察。若重启无法恢复 提交工单 联系腾讯云支持。 |
GPU 温度 | 持续5分钟>80 | 当 GPU 温度过高时可能会导致 GPU SlowDown,影响业务性能。 | |
GPU 是否存在显存页需隔离 | =1 | 安培以下架构 GPU 出现了 ECC ERROR,应用进程被 kill,GPU卡处于pending 状态。 | 执行 nvidia-smi -i <target gpu> -q -d PAGE_RETIREMENT 命令查看是否有 GPU 卡处于 pending 状态,重置 GPU 卡或重启实例恢复。若重启无法恢复 提交工单 联系腾讯云支持。 |
GPU 显存是否发生 UCE | =1 | 安培及以上架构 GPU 出现了 ECC ERROR,应用进程被 kill,GPU卡处于pending 状态。 | 执行 nvidia-smi -i <target gpu> -q -d ROW_REMAPPER 命令查看是否有 GPU 卡处于 Pending 状态,重置 GPU 卡或重启实例恢复。若重启无法恢复 提交工单 联系腾讯云支持。 |
GPU 内存使用率 | 仅保持观察 | - | 评估负载对显存占用。 |
GPU 使用率 | 仅保持观察 | - | 评估负载对 GPU 流处理器占用。 |
高性能计算集群 GPU 型实例 RDMA 监控指标告警订阅及处理建议
高性能计算集群以高性能云服务器为节点,通过 RDMA(Remote Direct Memory Access)互联,提供了高带宽和极低延迟的网络服务,大幅提升网络性能满足大规模高性能计算、人工智能、大数据推荐等应用的并行计算需求。
1. 高性能计算集群 GPU 型实例 RDMA 监控查看
单台 GPU 服务器 RDMA 监控指标查看
1. 在 高性能计算集群 中选择单击集群 ID 或查看详情,可看到集群的 GPU 服务器实例详情。
2. 单击 GPU 实例 列表中的 
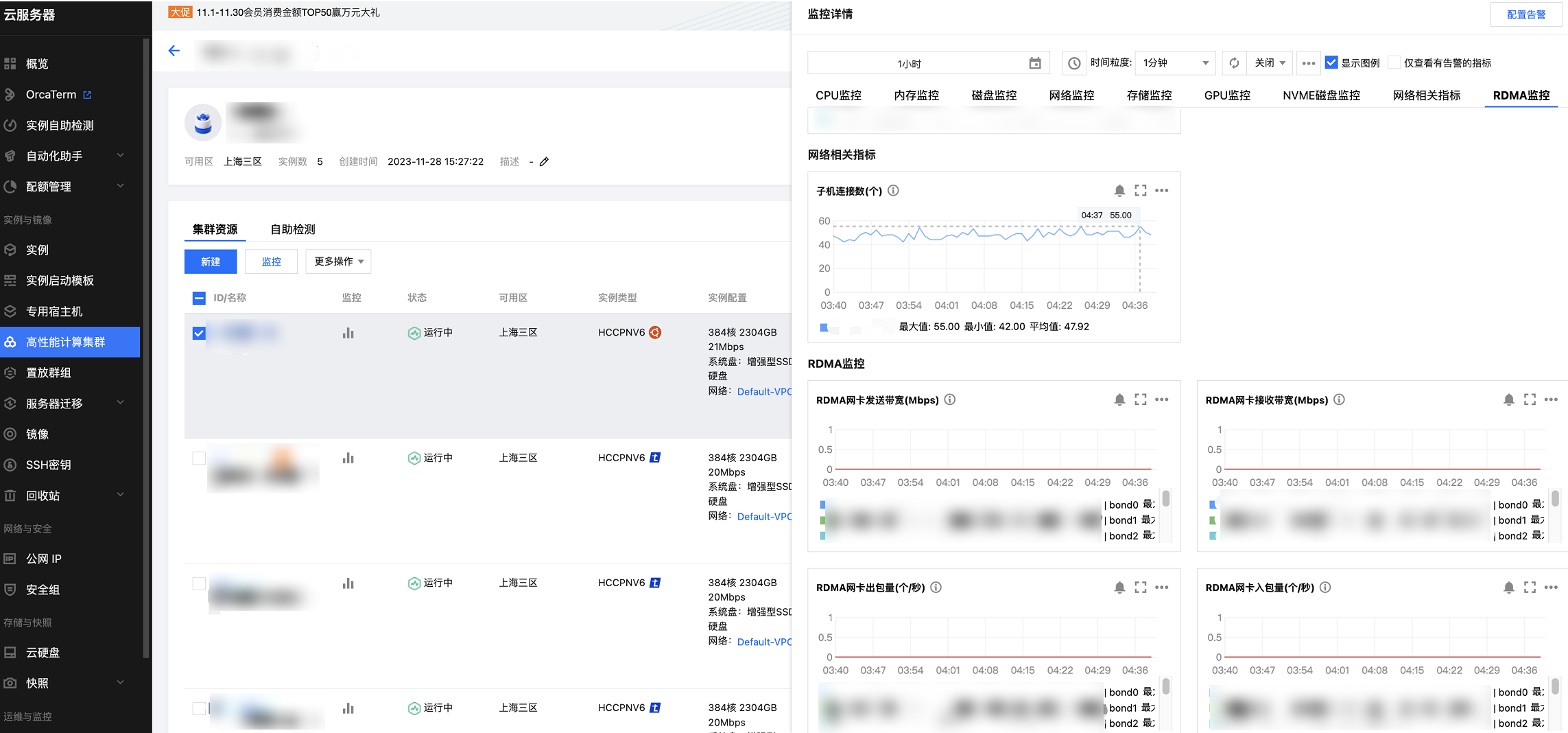
多台 GPU 服务器 RDMA 监控指标查看
多台实例 RDMA 监控可在云产品监控查看统计数据,您可以在云产品监控 -dashboard 中配置您需要的监控指标,操作步骤如下:
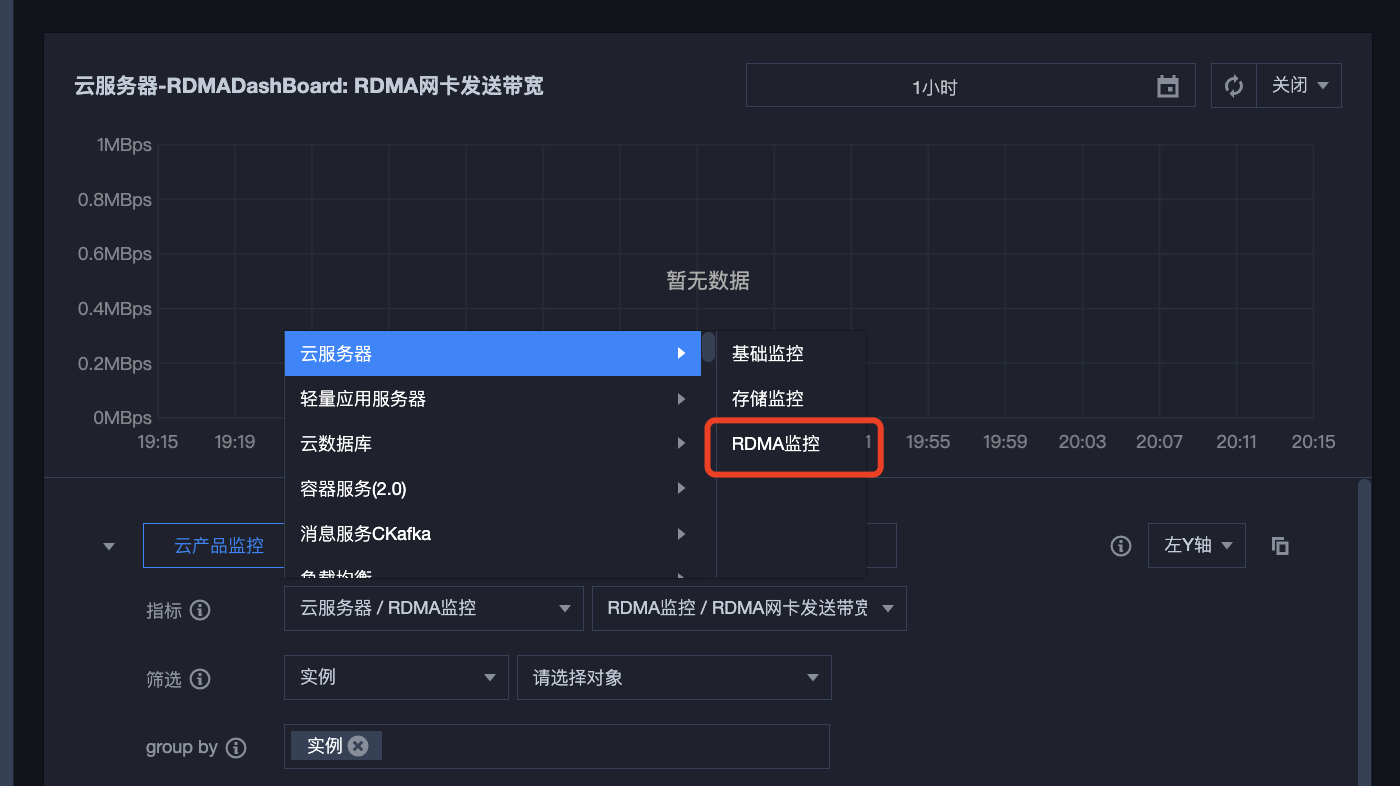
1. 新建 Dashboard,新建图表,指标选择云服务器 -RDMA 监控。
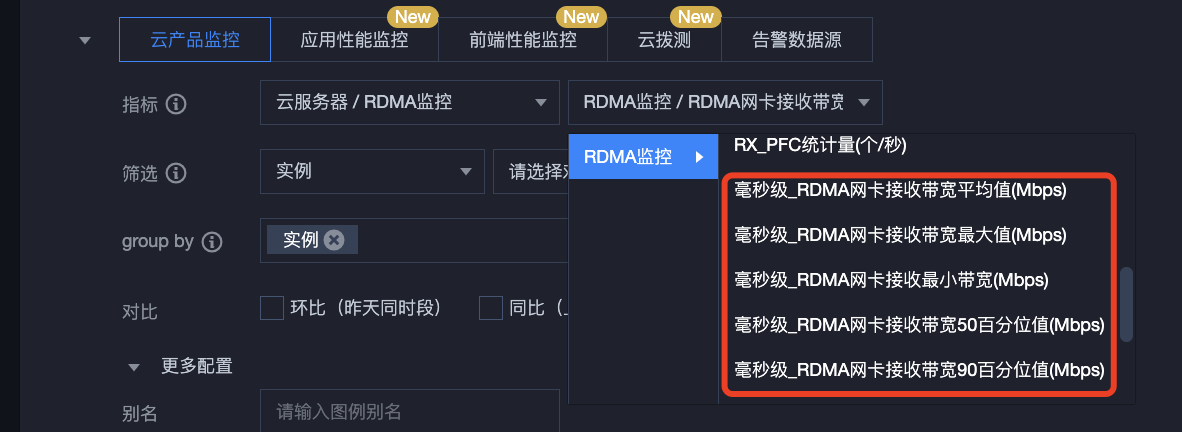
2. 选择您需要监控的 RDMA 毫秒级统计指标。
3. 选择需要监控的高性能计算集群实例 ID。

4. 单击确定即可快速创建 Dashboard。
2. 高性能计算集群 GPU 型实例 RDMA 监控指标说明
高性能计算集群 GPU 型实例 RDMA 各个监控指标含义如下所示:
指标英文名 | 指标中文名 | 指标说明(非必填) | 单位 | 统计粒度 |
RxHpbwAvg | 毫秒级_RDMA 网卡接收带宽平均值 | 10秒内 RDMA 网卡接收带宽的毫秒级统计粒度平均值 | Mbps | 10s、60s、 300s、 3600s |
RxHpbwMax | 毫秒级_RDMA 网卡接收带宽最大值 | 10秒内 RDMA 网卡接收带宽的毫秒级统计粒度最大值 | Mbps | 10s、60s、 300s、 3600s |
RxHpbwMin | 毫秒级_RDMA 网卡接收带宽最小值 | 10秒内 RDMA 网卡接收带宽的毫秒级统计粒度最小值 | Mbps | 10s、60s、 300s、 3600s |
RxHpbwP50 | 毫秒级_RDMA 网卡接收带宽50百分位值 | 10秒内从小到大 RDMA 网卡接收带宽的毫秒级统计粒度前50百分位数 | Mbps | 10s、60s、 300s、 3600s、 86400s |
RxHpbwP90 | 毫秒级_RDMA 网卡接收带宽90百分位值 | 10秒内从小到大 RDMA 网卡接收带宽的毫秒级统计粒度前90百分位数 | Mbps | 10s、60s、 300s、 3600s |
TxHpbwAvg | 毫秒级_RDMA 网卡发送带宽平均值 | 10秒内 RDMA 网卡发送带宽的毫秒级统计粒度平均值 | Mbps | 10s、60s、 300s、 3600s |
TxHpbwMax | 毫秒级_RDMA 网卡发送带宽最大值 | 10秒内 RDMA 网卡发送带宽的毫秒级统计粒度最大值 | Mbps | 10s、60s、 300s、 3600s |
TxHpbwMin | 毫秒级_RDMA 网卡发送带宽最小值 | 10秒内 RDMA 网卡发送带宽的毫秒级统计粒度最小值 | Mbps | 10s、60s、 300s、 3600s |
TxHpbwP50 | 毫秒级_RDMA 网卡发送带宽50百分位 | 10秒内从小到大 RDMA 网卡发送带宽毫秒级统计粒度前50百分位数 | Mbps | 10s、60s、 300s、 3600s |
TxHpbwP90 | 毫秒级_RDMA 网卡发送带宽90百分位 | 10秒内从小到大 RDMA 网卡发送带宽毫秒级统计粒度前90百分位数 | Mbps | 10s、60s、 300s、 3600s |
3. 高性能计算集群 GPU 型实例 RDMA 监控指标告警配置
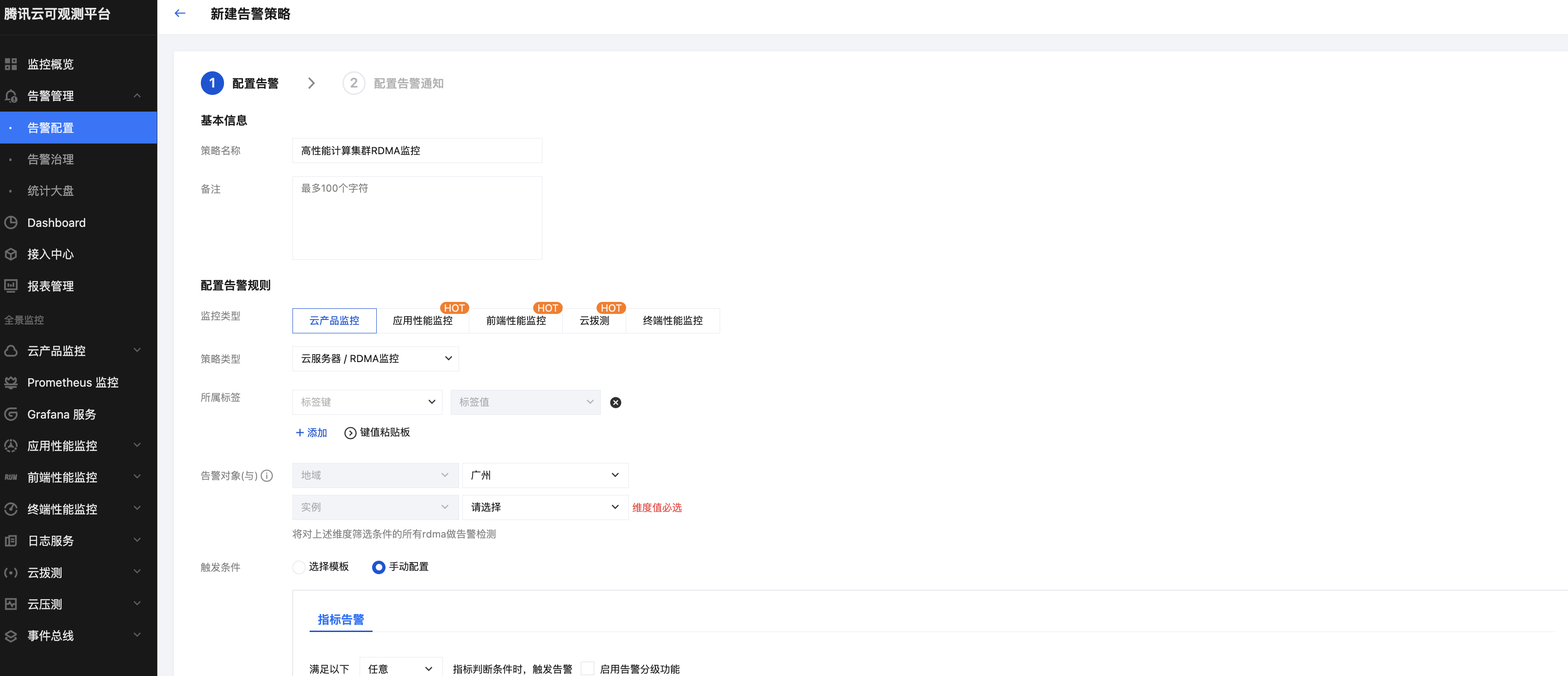
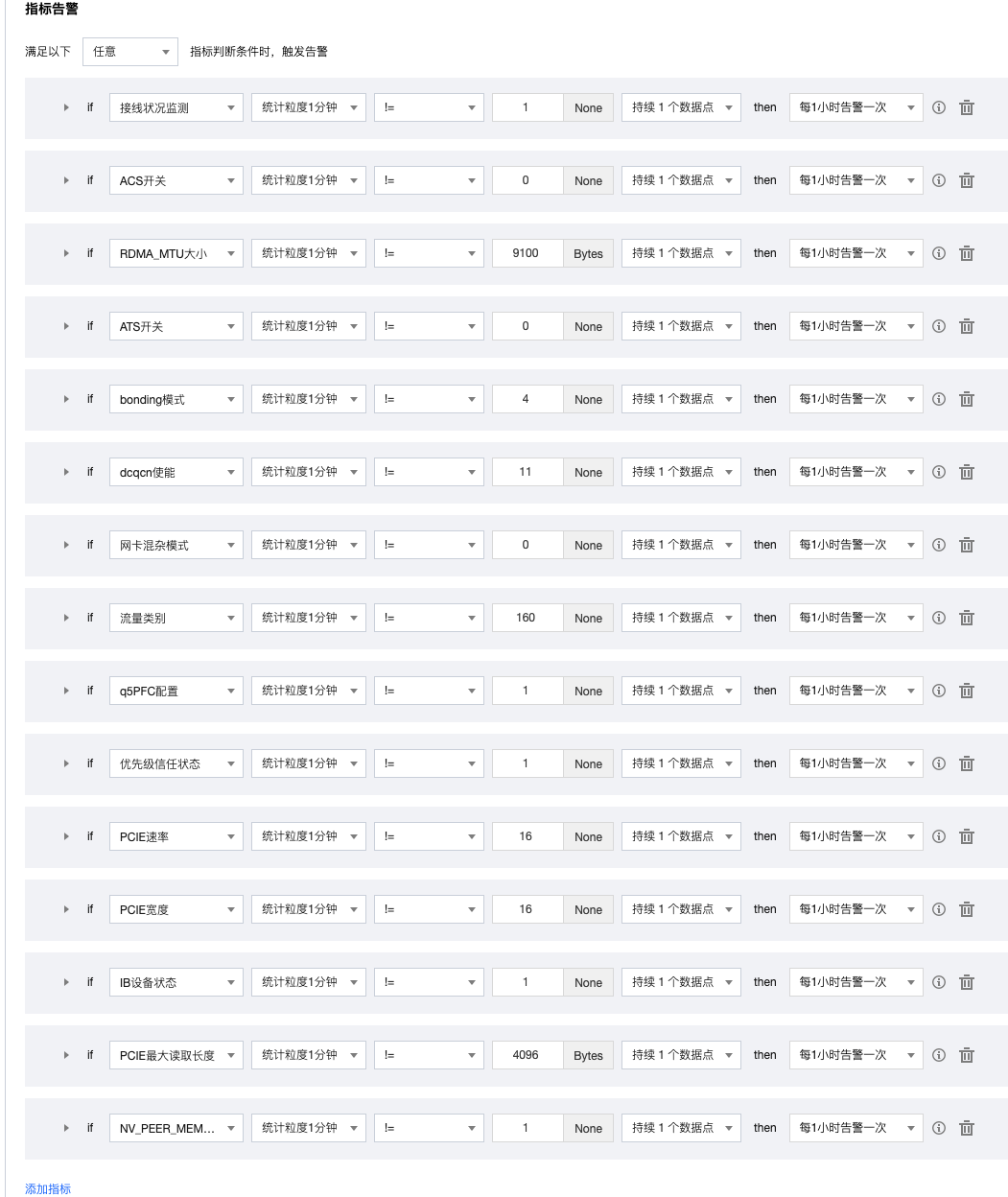
指标告警参考如下配置:
2. 告警通知可参见 新建通知模板 配置,支持多渠道通知。
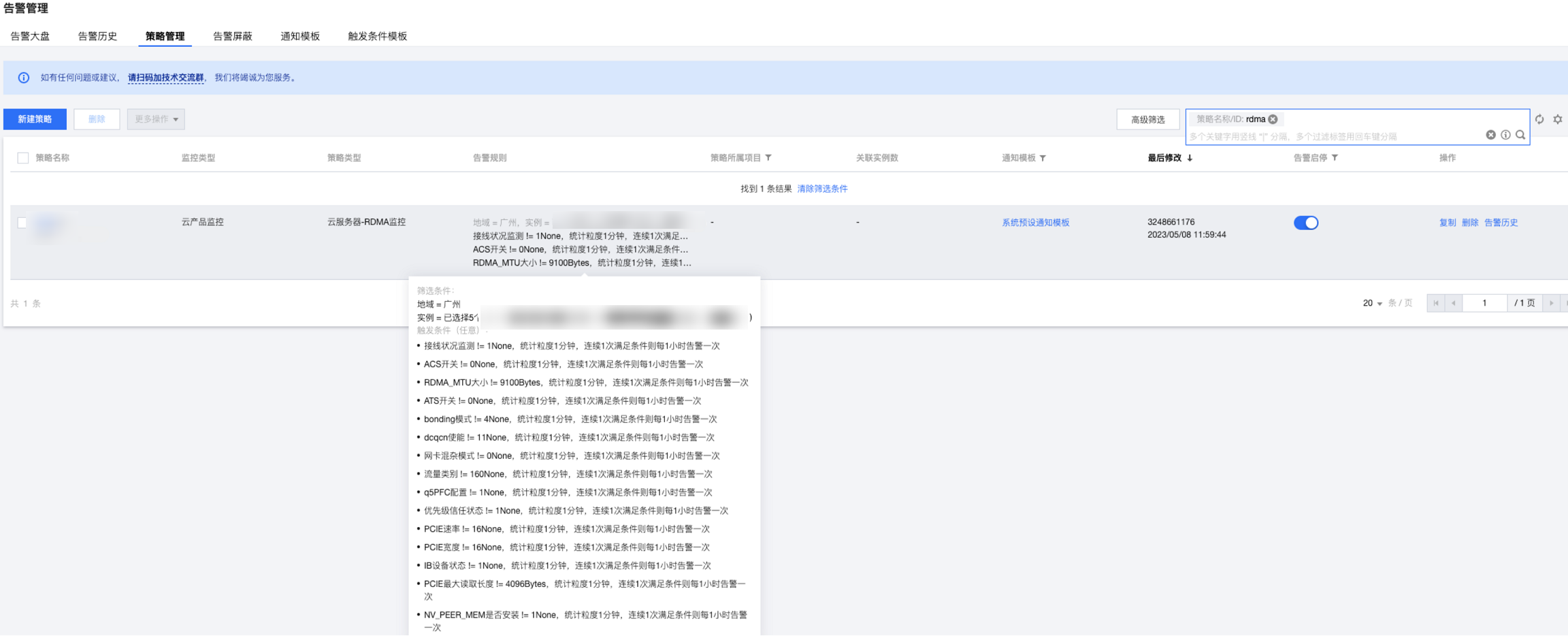
配置完成后策略查看截图如下:
告警示例截图如下:

4. 高性能计算集群 GPU 型实例 RDMA 告警处理建议
监测指标 | 指标名 | 错误描述 | 正确配置值 | 处理策略 | 客户更正方式 | 设备 |
接线状况监测 | link_detected | 链路 down | 1(1代表端口 up) | 客户尝试软件恢复,如无法恢复,授权运维维修 | ifconfig $ethname up | eth |
ACS 开关 | acs | ACS 开关配置错误 | 0(0代表关闭 ACS) | 客户改正配置(需要重启机器) | bash /etc/acsctl_online.sh disable_acsctl | eth |
RDMA_MTU 大小 | active_mtu | RDMA 卡的 MTU配置错误(影响性能) | 9100 | 客户更正配置即可 | ifconfig $ethname mtu 9100 | bond |
ATS 开关 | ats_enabled | ATS 开关配置错误 | 0(0代表关闭 ATS) | 客户改正配置(需要重启机器) | // 关闭 ATS for i in `lspci -d 15b3: | awk '{print $1}'`; do echo $i; mlxconfig -d $i -y s ATS_ENABLED=0; done // 重启之后确认状态 for i in `lspci -d 15b3: | awk '{print $1}'`; do echo $i; mlxconfig -d $i q | grep ATS_ENABLED; done | eth |
bonding 模式 | bonding_mode | bonding 模式配置错误 | 4(4代表双发模式) | 客户更正配置即可 | cd /usr/local/qcloud/rdma/; sh set_bonding.sh; sh dscp.sh | bond |
dcqcn 使能 | dcqcn_enable | dcqcn 未使能 | 11(两个1分别代表 rp和 np 的状态) | 客户更正配置即可 | echo 1 > /sys/class/net/$ethname/ecn/roce_rp/enable/5 echo 1 > /sys/class/net/$ethname/ecn/roce_np/enable/5 | eth |
网卡混杂模式 | eth_promisc | 网卡误配为混杂模式 | 0(0代表非混杂模式) | 客户更正配置即可 | ifconfig $ethname -promisc | eth |
流量类别 | traffic_class | 流量类别配置错误 | 160 | 客户更正配置即可 | echo 160 > /sys/class/infiniband/$RDMA_name/tc/1/traffic_class | bond |
q5 PFC 配置 | q5_pfc_enabled | PFC 未使能,存在QOS ERROR | 1(1代表 PFC 使能) | 客户更正配置即可 | mlnx_qos -i $ethname -f 0,0,0,0,0,1,0,0 | eth |
优先级信任状态 | prio_trust_state | 优先级信任状态配置错误 | 1(1代表 dscp) | 客户更正配置即可 | mlnx_qos -i $ethname --trust=dscp | eth |
pcie 速率 | max_link_speed | PCIE GEN 配置错误 | 16 | 客户更正配置即可 | eth | |
pcie 宽度 | max_link_width | PCIE width 配置错误 | 16 | 客户更正配置即可 | eth | |
IB 设备状态 | link_state | bond 口下两个 eth口全部 down | 1(1代表 bond 口up) | 客户尝试软件恢复,如无法恢复,授权运维维修 | ifconfig $ethname up | bond |
MRSS PCIE 最大读取长度 | mrss | MRSS 配置错误 | 4096 | 客户更正配置即可 | lspci -D -nn | grep 15b3 |awk -F' ' '{print $1}' |xargs -I {} setpci -s {} 68.w=5936 | eth |
NV_MEM_PEER 是否安装 | nv_peer_mem_state | nvidia_peermem 模块未加载 | 1(1代表模块已加载) | 客户加载模块即可 | modprobe nvidia_peermem | 整机 |



