背景信息
近几年随着 AI 模型参数的倍增及训练数据的日益增长,用户对模型迭代效率的需求也随之增长,单个 GPU 的算力和显存资源已无法满足大部分业务场景,使用单机多卡或多机多卡训练已成为趋势。单机多卡训练场景的参数同步借助 NVIDIA NVLINK 技术,基本可以获得较高的线性扩展比,但多机多卡训练场景严重依赖多机之间的网络互联技术。网卡厂商提供了高速互联技术 InfiniBand 或 RoCE,虽使多机通信效率大幅提升,但成本也大幅增加。如何在普通甚至低速网络环境下提升分布式系统的训练效率,已成为用户关注的焦点。
TACO Train 简介
目前业内已有一些成熟的分布式训练加速技术,例如多级通信、多流通信、梯度融合、压缩通信等,TACO Train 也引入了类似的加速技术。同时,TACO Train 推出了自定义的用户态协议栈 HARP,有效解决普通网络环境下的多机网络通信问题。
TACO Train 是腾讯云异构计算团队基于 IaaS 资源推出的 AI 训练加速引擎,为用户提供开箱即用的 AI 训练套件。TACO Train 基于腾讯内部丰富的 AI 业务场景,提供自底向上的网络通信、分布式策略及训练框架等多层级的优化,是一套全生态的训练加速方案。
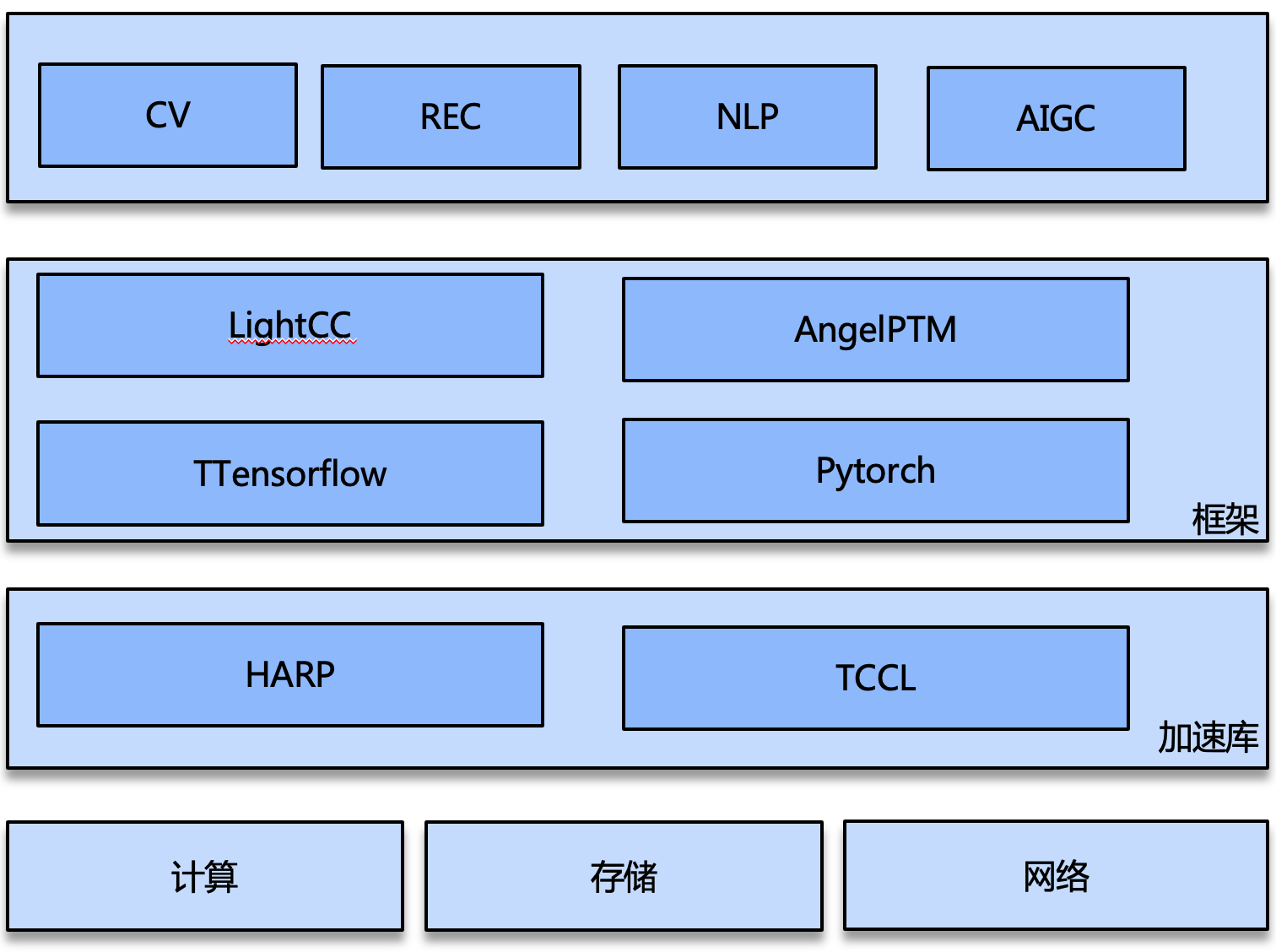
目前 TACO Train 提供了5个训练加速组件:
AngelPTM:大模型预训练框架,支持 GPT/T5/BERT 等大模型。
TCCL:针对腾讯云星脉网络架构的高性能定制加速通信库,为 AI 大模型训练提供更高效的网络通信性能。
HARP:自研用户态网络协议栈,加速普通网络环境的多机通信效率。
LightCC:分布式训练框架,支持 Horovod 或者 pytorch DDP 的分布式训练加速。
Tencent Tensorflow 1.15:基于 Tensorflow 1.15深度优化的训练框架(以下简称 TTF),支持搜索广告推荐场景下海量数据特征的增量训练。
AngelPTM
AngelPTM 是基于 DeepSpeed 和 Megatron 深度定制开发的大模型训练框架,支持 NLP/多模态/AIGC 等多类预训练任务。由于大模型的参数规模巨大,对硬件存储资源提出了挑战,AngelPTM 支持以更少的资源和更快的速度训练大模型,兼容社区方案 API ,支持业务快速接入,
ZeRO Cache 策略:基于 ZeRO 策略把内存作为二级存储 offload 参数、梯度、优化器状态到 CPU 内存(也支持 SSD 作为第三级存储)。ZeRO-Cache 为了最大化利用内存和显存进行模型状态的缓存,引入了显存内存统一存储视角,将存储容量的上界由内存扩容到内存+显存总和。同时将多流异步化做到了高效,在 GPU 计算的同时进行数据 IO 和 NCCL 通信,使用异构流水线均衡设备间的负载,最大化提升整个系统的吞吐。ZeRO-Cache 将 GPU 显存、CPU 内存统一视角管理,击破了异构存储的壁垒,减少了冗余存储和内存碎片,增加了内存的利用率,极大扩充了模型存储可用空间。
自动流水并行:3D 并行是 Megatron 的原始能力,但是 Megatron 的流水并行只支持 block 级别(Transformer Layer),且需要依靠专家经验人工指定 stage 切分以确保 stage 间负载均衡;自动流水并行可以做到 op 级别,且自动 profile op 性能,自动搜索负载均衡的切分方案后执行流水并行训练。
高性能 MoE 组件:基于拓扑感知的 Alltoall 通信加速专家并行,提供高性能定制算子,支持计算通信流水提高迭代效率。
TCCL
TCCL(Tencent Collective Communication Library)是一款针对腾讯云星脉网络架构的高性能定制加速通信库。主要功能是依托星脉网络硬件架构,为 AI 大模型训练提供更高效的网络通信性能,同时具备网络故障快速感知与自愈的智能运维能力。TCCL 基于开源的 NCCL 代码做了扩展优化,完全兼容 NCCL 的功能与使用方法。TCCL 目前支持主要特性包括:
双网口动态聚合优化,发挥 bonding 设备的性能极限。
全局 Hash 路由(Global Hash Routing),负载均衡,避免拥塞。
拓扑亲和性流量调度,最小化流量绕行。
HARP
随着网络硬件技术的发展,网络带宽从 10Gbps 增长到 100Gbps 甚至更高,在数据中心大量部署使用。但目前普遍使用的内核网络协议栈存在着一些必要的开销,使其不能很好地利用高速网络设备。为解决该问题,腾讯云自研了用户态网络协议栈 HARP,可以以 Plug-in 的方式集成到 NCCL 中,无需任何业务改动,加速云上分布式训练性能。在 VPC 的环境下,相比传统的内核协议栈,HARP 提供了以下的能力:
支持全链路内存零拷贝,HARP 协议栈提供特定的 buffer 给应用,使应用的数据经过 HARP 协议栈处理后由网卡直接进行收发,消除内核协议栈中耗时及占用 CPU 较高的多次内存拷贝操作。
支持协议栈多实例隔离,即应用可以在多个 CPU core 上创建特定协议栈实例处理网络报文,每个实例间相互隔离,保证性能线性增长。
数据平面无锁设计,HARP 协议栈内部保证网络 session 的数据仅在创建该 session 的 CPU core 上,使用特定的协议栈实例处理。减少了内核中同步锁的开销,也降低了 CPU 的 Cache Miss 率,大幅提升网络数据的处理性能。
LightCC
LightCC 对社区分布式方案的通信策略进行了深度定制优化,完全兼容 Horovod 或者 PyTorch DDP API,支持业务快速接入。主要包括的优化能力如下:
2D AllReduce 充分利用通信带宽。
高效的梯度融合方式。
TOPK/FP16 压缩通信,降低通信量,提高传输效率。
TTF
TensorFlow 是深度学习领域中应用最广泛的开源框架之一,但在很多业务场景下,开源 TensorFlow 有其特定的限制。为了解决实际业务中遇到的问题,Tencent Tensorflow(以下简称 TTF)提供了以下能力:
相比原始的静态 Embedding,高维稀疏动态 Embedding 帮助用户在不需要重新训练的条件下,动态添加和删除特征,按需使用内存,避免 Hash 冲突,同时保留原始 TF 的 API 设计风格。
混合精度在原有实现的基础上增加了调整精度的策略,根据 loss 的状态自动在全精度和半精度之间切换,避免精度损失。
针对特定业务场景的 XLA,Grappler 图优化,以及自适应编译框架解决冗余编译的问题。
开源 TF 1版本不再提供对 Ampere GPU 的支持,但考虑到较多用户仍在使用 TF 1.15版本的问题,TTF 添加了对 CUDA 11的支持,让用户可以使用 A100来进行模型训练。



