操作场景
操作步骤
购买实例
实例:选择 计算型 GN10Xp 或 计算型 GT4。
系统盘:配置容量不小于50GB的云硬盘。您也可在创建实例后使用文件存储,详情参见 在 Linux 客户端上使用 CFS 文件系统。
镜像:建议选择公共镜像,支持自动安装 GPU 驱动。若您选择自定义镜像,则需要自行安装 GPU 驱动。
操作系统请使用 CentOS 8.0、CentOS 7.8、Ubuntu 20.04、Ubuntu 18.04、TencentOS 3.1、TencentOS 2.4。
若您选择公共镜像,则请勾选后台自动安装 GPU 驱动,实例将在系统启动后预装对应版本驱动。如下图所示:
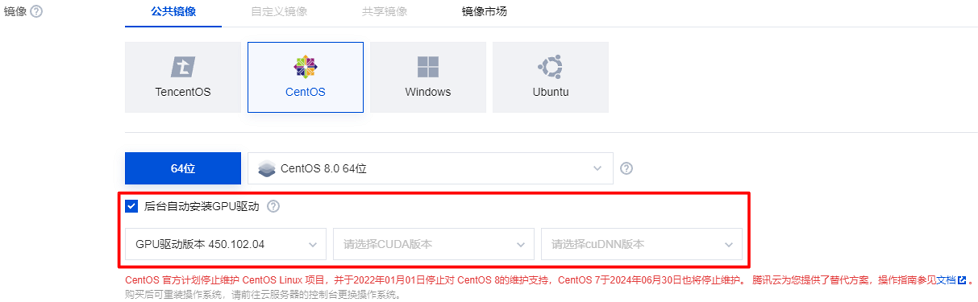
配置实例环境
验证 GPU 驱动
1. 参见 使用标准登录方式登录 Linux 实例,登录实例。
2. 执行以下命令,验证 GPU 驱动是否安装成功。
nvidia-smi
查看输出结果是否为 GPU 状态:
是,代表 GPU 驱动安装成功。
否,请参见 NVIDIA Driver Installation Quickstart Guide 进行安装。
配置 HARP 分布式训练环境
1. 参见 配置 HARP 分布式训练环境,配置所需环境。
2. 配置完成后,执行以下命令进行验证,若配置文件存在,则表示已配置成功。
ls /usr/local/tfabric/tools/config/ztcp*.conf
安装 docker 和 nvidia docker
1. 执行以下命令,安装 docker。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-docker.sh | sudo bash
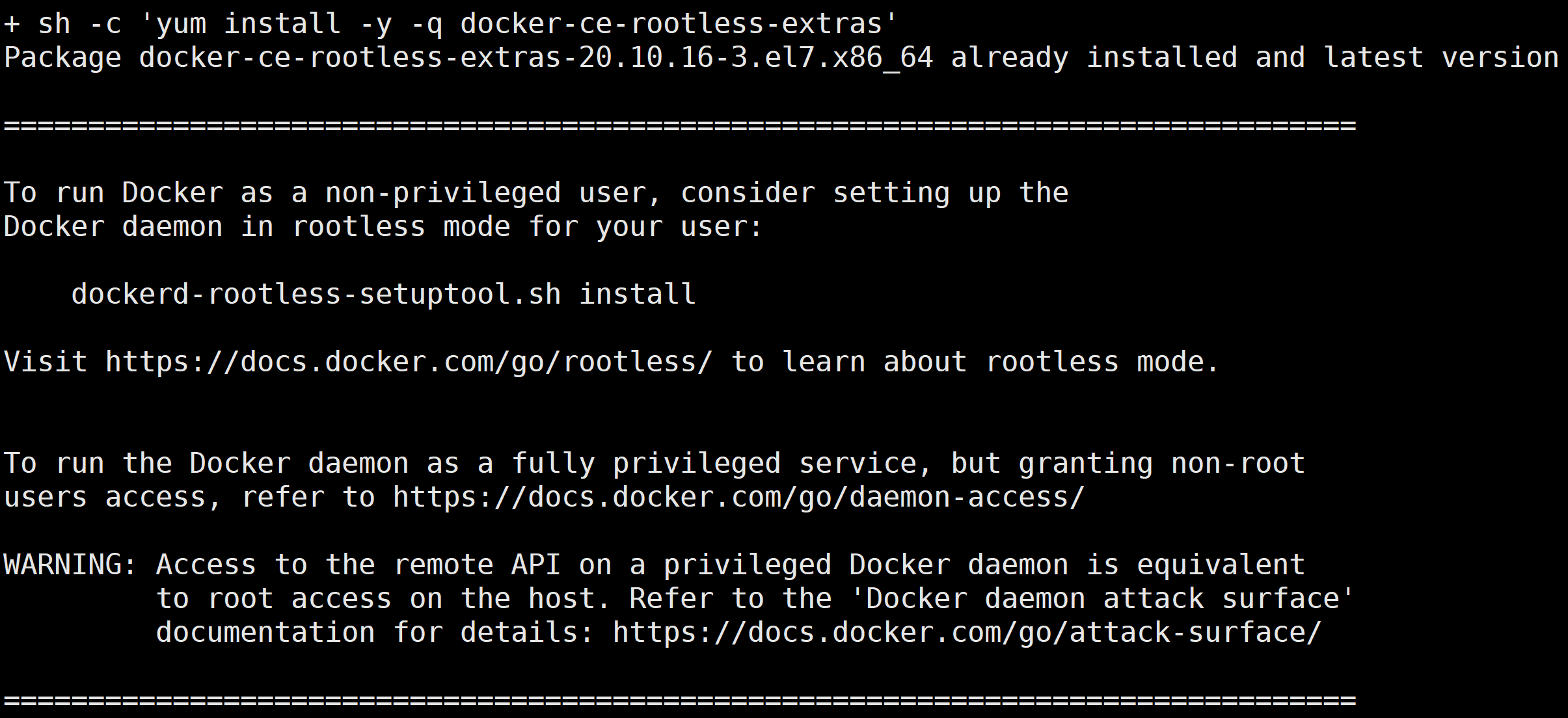
2. 执行以下命令,安装 nvidia-docker2。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
若您无法通过该命令安装,请尝试多次执行命令,或参见 NVIDIA 官方文档 Installation Guide & mdash 进行安装。
本文以 CentOS 为例,安装成功后,返回结果如下图所示:
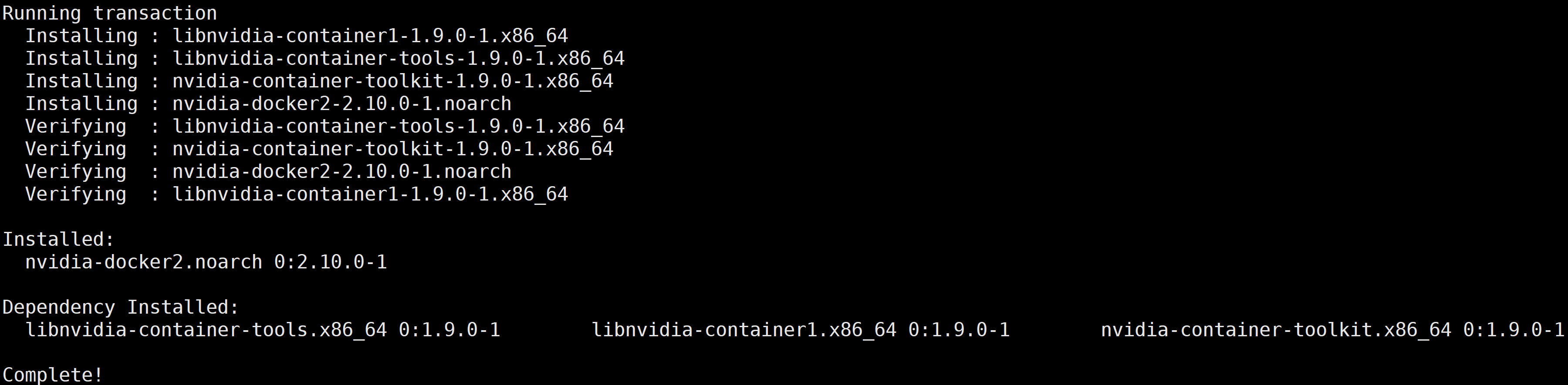
下载 docker 镜像
执行以下命令,下载 docker 镜像。
docker pull ccr.ccs.tencentyun.com/qcloud/taco-train:torch111-cu113-cvm-0.4.3
该镜像包含的软件版本信息如下:
OS:Ubuntu 20.04.4 LTS
python:3.8.10
cuda toolkits:V11.3.109
cudnn library:8.2.0
nccl library:2.9.9
tencent-lightcc :3.1.1
HARP library:v1.3
torch:1.11.0+cu113
其中:
LightCC 是腾讯云提供的基于 Horovod 深度定制优化的通信组件,完全兼容 Horovod API,不需要任何业务适配。
HARP 是腾讯云提供的用户态协议栈,致力于提高 VPC 网络下的分布式训练的通信效率。以动态库的形式提供,官方 NCCL 初始化过程中会自动加载,不需要任何业务适配。
torch 是官方版本1.11.0版本。
启动 docker 镜像
执行以下命令,启动 docker 镜像。
docker run -it --rm --gpus all --privileged --net=host -v /sys:/sys -v /dev/hugepages:/dev/hugepages -v /usr/local/tfabric/tools:/usr/local/tfabric/tools ccr.ccs.tencentyun.com/qcloud/taco-train:torch111-cu113-cvm-0.4.3
注意
/dev/hugepages 和 /usr/local/tfabric/tools 包含了 HARP 运行所需要的大页内存和配置文件。分布式训练 benchmark 测试
说明
单卡
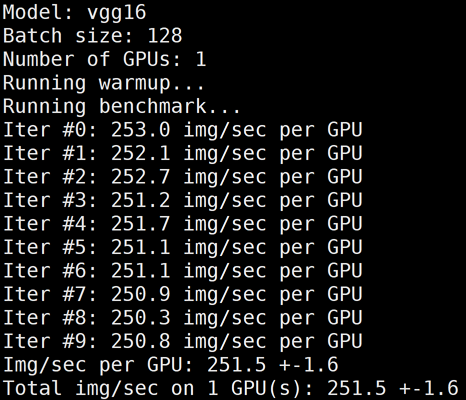
执行以下命令,进行测试。
/usr/local/openmpi/bin/mpirun -np 1 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=128
下图为 GN10Xp/V100的单卡 benchmark 结果:
单机多卡
执行以下命令,进行测试。
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=128
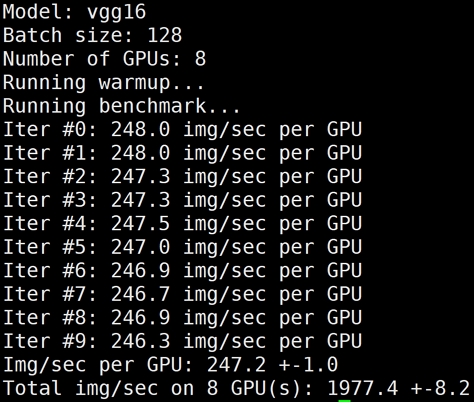
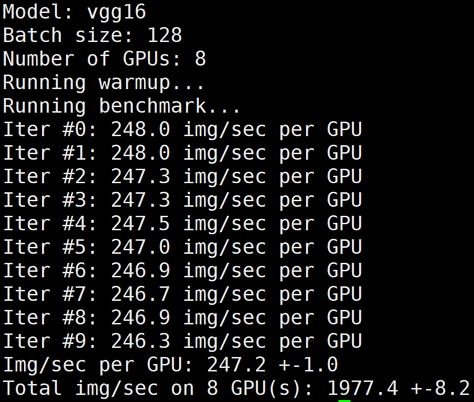
下图为 GN10Xp/V100的单机8卡 benchmark 结果:
多机多卡
1. 参见 购买实例 步骤,购买和配置多台训练机器。
2. 配置多台服务器 docker 间相互免密访问,详情请参见 配置容器 SSH 免密访问。
3. 执行以下命令,使用 TACO Train 进行多机训练加速。
/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x HOROVOD_MPI_THREADS_DISABLE=1 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x LIGHT_INTRA_SIZE=8 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRESHOLD=2097152 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=128
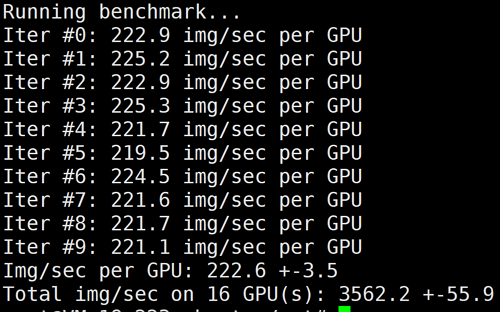
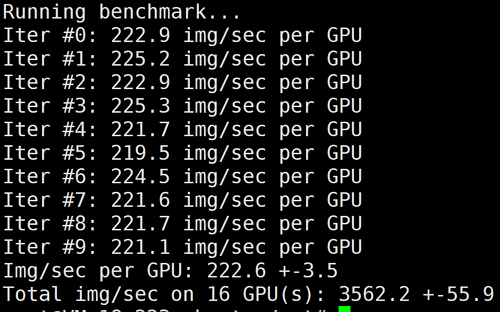
下图为 GN10Xp/V100的2机16卡 benchmark 结果:
LightCC 的环境变量说明如下表:
环境变量 | 默认值 | 说明 |
LIGHT_2D_ALLREDUCE | 0 | 是否使用 2D-Allreduce 算法 |
LIGHT_INTRA_SIZE | 8 | 2D-Allreduce 组内 GPU 数 |
LIGHT_HIERARCHICAL_THRESHOLD | 1073741824 | 2D-Allreduce 的阈值,单位是字节,小于等于该阈值的数据才使用 2D-Allreduce |
LIGHT_TOPK_ALLREDUCE | 0 | 是否使用 TOPK 压缩通信 |
LIGHT_TOPK_RATIO | 0.01 | 使用 TOPK 压缩的比例 |
LIGHT_TOPK_THRESHOLD | 1048576 | TOPK 压缩的阈值,单位是字节,大于等于该阈值的数据才使用 TOPK 压缩通信 |
LIGHT_TOPK_FP16 | 0 | 压缩通信的 value 是否转成 FP16 |
4. 执行以下命令,关闭 TACO LightCC 加速进行测试。
# 修改环境变量,使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=128
下图为 GN10Xp/V100的2机16卡,关闭 LightCC 后的 benchmark 结果:
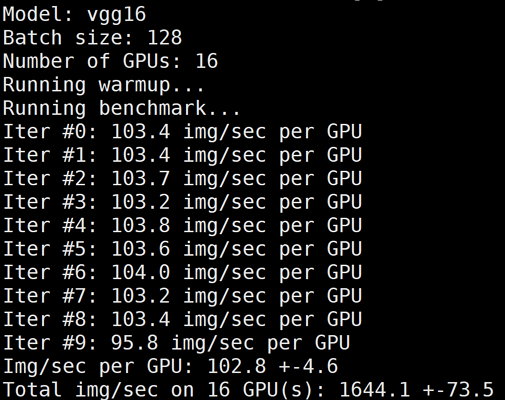
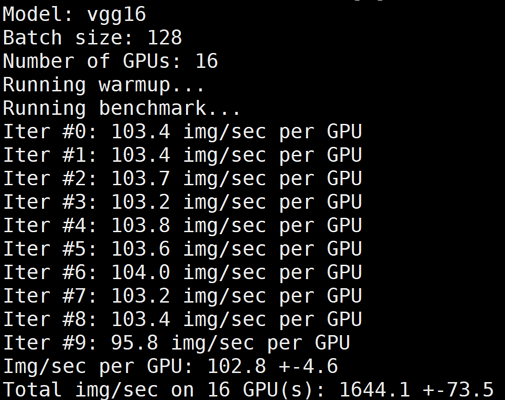
5. 执行以下命令,同时关闭 LightCC 和 HARP 加速进行测试。
# 将HARP加速库rename为bak.libnccl-net.so即可关闭HARP加速。/usr/local/openmpi/bin/mpirun -np 2 -H gpu1:1,gpu2:1 --allow-run-as-root -bind-to none -map-by slot mv /usr/lib/x86_64-linux-gnu/libnccl-net.so /usr/lib/x86_64-linux-gnu/bak.libnccl-net.so# 修改环境变量,使用Horovod进行多机Allreduce /usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=128
下图为 GN10Xp/V100的2机16卡,同时关闭 LightCC 和 HARP 后的 benchmark 结果:
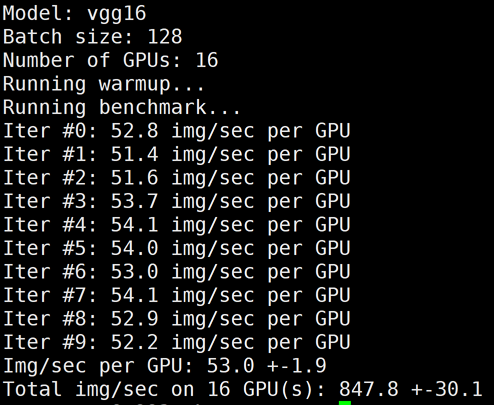
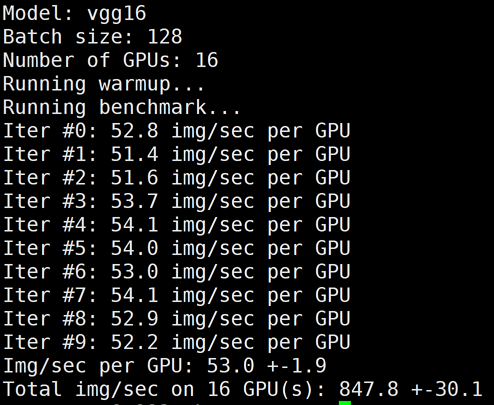
注意:
测试完如需恢复 HARP 加速能力,只需要把所有机器上的 bak.libnccl-net.so 重新命名为 libnccl-net.so 即可。
总结
本文测试数据如下:
机器:GN10Xp(V100 * 8)+ 25G VPC 容器:ccr.ccs.tencentyun.com/qcloud/taco-train:torch111-cu113-cvm-0.4.1 网络模型:VGG16Batch:128 数据:synthetic data | |||||||
机型 |
GPU 卡数
| Horovod+TCP | | Horovod+HARP | | LightCC+HARP | |
| | 性能(img/sec) | 线性加速比 | 性能(img/sec) | 线性加速比 | 性能(img/sec) | 线性加速比 |
GN10Xp/V100 | 1 | 251 | - | 251 | - | 251 | - |
| 8 | 1977 | 98% | 1977 | 98% | 1977 | 98% |
| 16 | 847 | 21% | 1644 | 40% | 3562 | 88% |
说明如下:
对于 GN10Xp,相比开源方案,使用 TACO 分布式训练加速组件之后,16卡V100的线性加速比从93%提升到97%(由于当前网络模型的加速已经很高,软件优化提升的空间有限)。
LightCC 和 HARP 只在多机分布式训练当中才有加速效果,单机8卡场景由于 NVLink 的高速带宽存在,一般不需要额外的加速就能达到比较高的线性加速比。
上述 benchmark 脚本也可以支持除了 VGG16之外的其他模型。ModelName 请参见 Keras Applications。
上述 docker 镜像仅用于 demo,若您具备开发或者部署环境,请提供 OS/python/CUDA/torch 版本信息,并联系腾讯云售后提供特定版本的 TACO 加速组件。



