当需要对当前页面的组件进行数据筛选,可以使用文本筛选器关联图表来实现。
注意:如文本筛选下拉列表加载缓慢,强烈建议为下拉选项建立单独的维表;例如当前有“城市”筛选器,如果直接用“订单表”作为数据源,则每次访问实际是对订单表的几百万数据做聚合;这时可以在数据层建一个“城市表”,每天更新,则相当于每次查的是100个数据量的表,会快很多。
文本筛选器支持文本输入和文本选择两类交互:
文本输入:无需关联字段,用户输入文本作为筛选条件,常用于类似搜索的交互方式,如查询姓名为“张三”的员工产值信息;
文本选择:需要关联文本字段,用于选择一个下拉项作为筛选条件,常用于分类选择,如查询部门为“销售部”的员工 KPI 完成情况。
通过本文档,您将了解:
设置文本输入类型筛选器
设置选择输入类型筛选器
为筛选器设置缓存
选择输入筛选器的浏览端操作
实践教程
设置“文本输入”类型筛选器
1. 进入编辑器,在组件库 > 交互组件分类中选择 文本筛选器:

2. 选择交互类型为 文本输入:
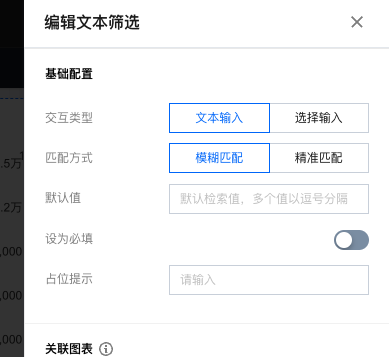
文本输入支持以下设置:
设置项 | 设置说明 |
匹配方式 | 可选模糊匹配和精准匹配,当用户输入 “张三”进行搜索时,区别在于: 模糊匹配:将搜索出“张三”、“张三丰”、“王张三”; 精准匹配:将只能搜索出 “张三”。 |
默认值 | 在页面加载完成后,自动执行默认查询,方便数据初始化 |
设为必填 | 当开启必填,则必须选择默认值,用户至少输入一个值 |
占位提示 | 为了节省位置,可以设置占位字符:  |
3. 设置关联图表:假如我们想在“姓名”输入框中输入“张”搜索所有名字中带“张”的员工(影响图表为“员工投入产出分析”和“部门收入分析”),可以如下操作:
设置“姓名”筛选器的交互类型为“文本输入”
设置匹配方式为“模糊匹配”
关联图表选择“员工投入产出分析”和“部门收入分析”两个组件
选择这两个图表的关联方式为“字段”
设置字段为“姓名”
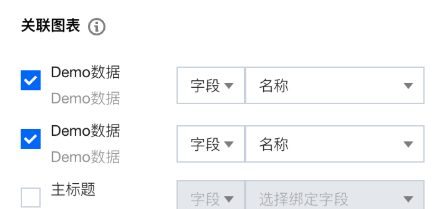
设置“姓名”筛选器的交互类型为“文本输入”;
设置匹配方式为“模糊匹配”;
关联图表选择“员工投入产出分析”和“部门收入分析”两个组件;
选择这两个图表的关联方式为“参数”;
设置关联 sql 参数为“name”(name 为 sql 建表中定义的 sql 参数)。
设置 “选择输入” 类型筛选器
1. 进入编辑器,在组件库 > 交互组件分类 中选择 文本筛选器;
2. 选择交互类型为 选择输入:用户的输入必须是数据库中存在一个维值,因此必须关联数值来源:
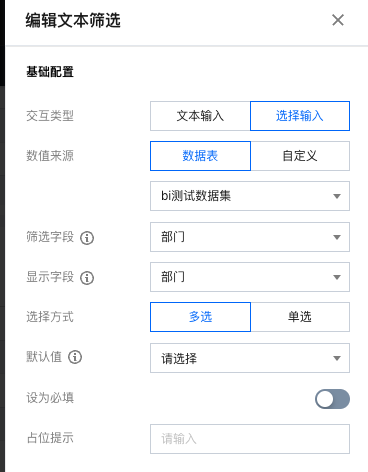
选择输入支持以下设置:
设置项 | 设置说明 |
数值来源 | 下拉选项的值来源,可选来源于数据表或者手工自定义输入; 对于变动比较频繁且值较多的情况,建议使用数据表(如“客户名称”);反之值比较固定且不多的情况,建议使用自定义(如“省份”) |
筛选字段 | 实际执行筛选时的字段 |
显示字段 | 在下拉列表中展现的字段,默认是和筛选字段一致的,如设为不一致,则会显示是一个值(如“深圳”),实际执行一个值(如“0755”),类似于字典表 |
选择方式 | 支持多选和单选 |
默认值 | 可设置默认的筛选器值 |
设为必填 | 当开启必填,则必须选择默认值,用户至少输入一个值 |
占位提示 | 为了节省位置,可以设置占位字符: |
假如我们想在“部门”下拉选择框中一个部门,影响图表为“员工产值分布”和“员工产值及支出”,我们可以如下操作:
设置“部门”筛选器的交互类型为“选择输入”;
设置“数值来源”的数据表为“Demo 数据”,字段为“部门”;
选择方式为“多选”(可以同时选择多个部门);
关联图表选择“员工产值分布”和“员工产值及支出”两个组件;
选择这两个图表的关联方式为“字段”;
设置字段为“部门”。
为筛选器设置缓存
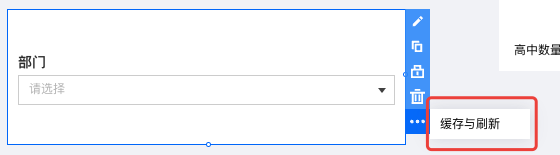
筛选器在数值来源为数据表时,用户可设置缓存,以加快下拉列表的显示。
入口:进入编辑器,在组件的更多操作中,选择 缓存与刷新。
筛选器的浏览端操作
文本下拉筛选器支持以下操作:
支持快速输入:当输入值后下拉还未加载完成时,可以不用等待加载完成,直接确认提交,即可筛选用户输入的值;
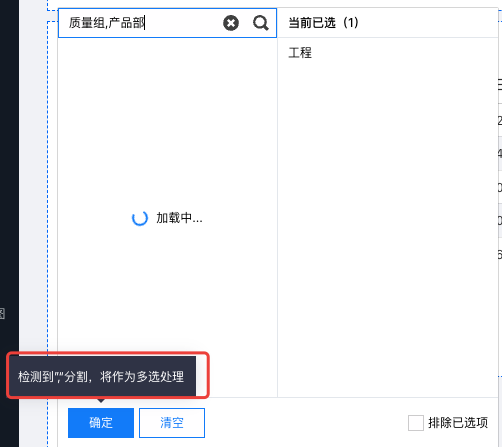
支持批量输入:当输入多个值并以“,”分割时,可批量筛选多个输入值;
实践教程
如何提升列表加载速度?
场景:当连接的数据表数据量较大,则在数据聚合时,耗时会比较长。
处理方式:
使用落静态表的方式,减少聚合时间:
假设订单表有500万条数据,我们想对“渠道商”进行过滤,如果直接对“渠道商”聚合,则每次需要执行500万数据的聚合,耗时比较长;
那我们可以加工一个“城市表”,这个加工表将从订单表中聚合“渠道商”,然后落成静态表(假设有1000个渠道商),下拉数据从静态表中读取,这时候因为不需要聚合,所以相当于只查询1000条数据,速度可大大提升。
使用缓存,减少重复查询:详请参见 缓存与刷新。
使用查询加速,提高性能:详请参见 抽取加速。



