实例升配有哪些模式?主要有什么区别?
当系统算法计算到当前独占的资源池不够升配后的资源配额的时候,需要自动化的添加资源到资源池,并对实例的数据进行迁移。故升配存在两种模式:
资源足够时,即时升配提高配额的模式,几分钟内升配完成。
资源不足时,数据迁移的模式,视集群堆积的数据大小而定,可能需要几分钟到几个小时。
当需要数据迁移时,可自定义迁移时间:
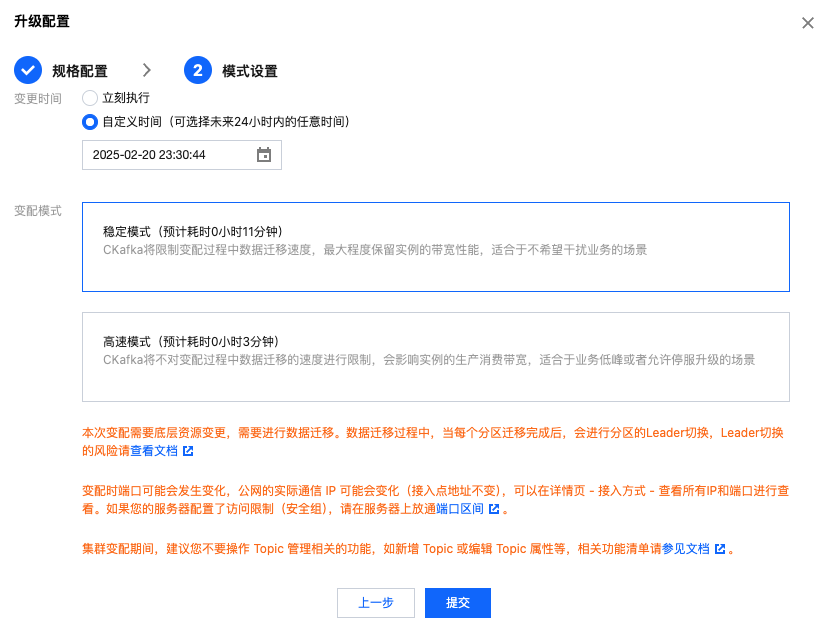
当需要数据迁移时,会有迁移模式和定时迁移两种选项,迁移模式分为如下两种:
稳定模式:CKafka 将限制升配过程中数据迁移速度,最大程度保留实例的带宽属性,适合于不希望干扰业务的场景。
高速模式:CKafka 将不对升配过程中数据迁移的速度进行限制,会影响实例的生产消费带宽,适合于业务低峰或者允许停服的场景。
为什么集群带宽百分比未超过100%,却产生了限流?
从监控界面中,可以看到集群实例的生产或消费带宽百分比未超过100%,但实例最大生产或消费带宽已经超出了所购买集群的带宽,同时集群限流次数不为 0。出现这种现象有以下两种原因:
1. 目前集群所使用的限流机制,针对 Kafka 这样大流量的场景下,采用了较为柔和的延时回包机制。所以在极端情况下,实例最大生产/消费带宽可以超出所购集群的带宽。详情可以参考限流机制说明。
2. 带宽百分比指标,采用较为削峰填谷的方式呈现当前集群的使用比例,我们的计算方式为获取单位时间内的平均值。故而出现上述的问题。
实例最大生产/消费带宽已经超出了所购买集群的带宽,但未产生限流?
实例是否支持数据压缩?
当前 CKafka 支持开源的 snappy 和 lz4 的消息压缩格式。由于 Gzip 压缩对于 CPU 的消耗较高,暂未支持。开启压缩在某些情况下可能会加大服务端的压力,例如生产者的版本较高,消费者的版本协议较低,在消费的时候,会出现向下的协议转换。导致服务端压力升高。所以建议如果需要压测,建议客户关闭消息压缩参数进行测试。
配置开启方法:Producer 的配置文件中参数 compression.type = snappy 或者 lz4,默认为关闭 none。
建议优先选择 Snappy 压缩。开启压缩后,可能会导致服务端 CPU 升高,导致生产消费耗时变高。需谨慎使用。



