功能介绍
若您的业务数据已经存在于作为缓存层的消息队列(例如 Kafka)中了,需要进行清洗格式化(ETL),再存储到下游 Kafka,您可以使用 CKafka 连接器提供的 Kafka to Kafka 插件能力。
该插件支持 Kafka 之间的数据同步,包括 Kafka 实例级别和 Topic 级别数据同步,既支持不同地域实例间的复制迁移功能,也支持不同 CKafka 实例的 Topic 之间互相传递数据、自动同步。同时还提供简单的数据处理能力,如格式化原始数据、解析特定字段、数据格式转换等,将处理后的结构化数据转储到下游 Kafka,构建稳定可靠的数据传输通道,帮助用户提升业务连续服务的能力。
数据同步 | 实例级别数据同步 | Topic 级别数据同步 |
数据源 | 内网连接:腾讯云 CKafka 集群 公网连接:腾讯云 CKafka 集群/自建 Kafka 集群 跨网连接:自建 Kafka 集群/其他云厂商集群 | 腾讯云 CKafka 集群 |
数据目标 | 内网连接:腾讯云 CKafka 集群 公网连接:腾讯云 CKafka 集群/自建 Kafka 集群 | 腾讯云 CKafka 集群 |
操作步骤 | 1. 新建数据源连接 2. 新建数据目标连接 3. 新建数据同步任务 4. 配置数据源 5. 配置数据目标 6. 查看数据同步进度 | 1. 新建数据复制任务 2. 配置数据源 3. 处理数据 4. 配置数据目标 5. 查看数据同步进度 |
使用限制
限制类型 | 限制项 | 限制数量 |
连接维度 | 单个 uin 的连接数量 | 150 |
任务维度 | 单个 uin 的任务数量 | 150 |
| 单个任务的并发数 | min(数据源端的 Topic 总分区数,20) |
数据同步规则说明
CKafka 连接器的 K2K 插件支持在控制台上进行实例之间的元数据,消息数据和消费位点同步,具体的规则说明如下:
数据类型 | 规则说明 |
同步元数据 | 分为初始化同步和定时同步两个环节。 初始化同步:任务启动时,会查看下游是否存在和上游对应的 Topic,如果没有,则会在下游新建 Topic(尽可能和上游的配置一样);如果下游本身就存在对应的 Topic,则不会触发初始化同步。 定时同步:任务启动之后,会周期性(3分钟)地将上游的部分元数据配置同步到下游。 说明: 定时同步暂不支持同步副本数。 定时同步分区数时,分区数只能单向增加不能减少,如果下游实例分区已经大于上游,则不会同步分区数。 出于稳定性考虑,目标 Topic 的 retention.ms 和 retention.bytes 这两项元数据的值为-1时(注意:-1为 Kafka 内部定义,代表无限存储)才会同步,其他情况下这两项元数据均不会定时同步。 对于 Topic 级别的配置,出于稳定性考虑,默认情况下,新增的 Topic 只在任务的初始化状态下,元数据会完整同步一次,后续 Topic 配置发生变更则不再同步到下游 原因:用户在不知道存在数据同步任务的情况下,若修改了上游 Topic 配置(如缩短消息时间),此时下游同步该变更,会导致下游在消息未消费情况下,出现大量丢失数据的情况。 同步变更配置的解决方案:如果客户需要变更存量任务中的 Topic 并且同步配置,建议客户手动同步修改上下游的 Topic 配置,避免出现丢数据或稳定性问题。 |
同步消息数据 | 将上游 Kafka 中存储的消息数据同步到下游 Kafka 对应的 Topic 中,如果开启了同步到相同分区,则消息会固定同步到下游对应的相同分区中 |
同步消费位点 | 将上游 Kafka 中存储的消息数据同步到下游 Kafka 对应 Topic 中时,同时同步相关的消费组和消费组对该 Topic 所提交的 Offset 信息,注意该 Offset 是映射后的对应关系。 |
限制条件
说明:
下表中的默认值指元数据未同步情况下,例如上游不存在该配置或者配置非法(非数字、null、空),会使用系统设定的默认值替代。
同步数据类型 | 参数 | 限制条件 | 默认值 |
元数据 | 分区数 | 1. 当需要同步元数据的时候,有两个参数不符合条件会无法同步: 目标 Topic 分区数大于源 Topic 分区数,分区数不能同步。 目标 Topic 与源 Topic 副本数不一致,副本数不能同步。 2. 源实例的 Topic 名称长度超过128位时, 目标创建的 Topic 会取前128位作为该 Topic 的名称。 | / |
| 副本数 | | / |
| retention.ms | | 604800000(7天) |
| cleanup.policy | | delete |
| min.insync.replicas | | 1 |
| unclean.leader.election.enable | | false |
| segment.ms | | 604800000 |
| retention.bytes | | 默认值取决于 Kafka 配置 |
| max.message.bytes | | 1048588 |
| 消费组 | 若目标实例关闭了自动创建 ConsumerGroup,则消费分组无法进行同步。 | / |
消息数据 | / | 支持消息数据同步到相同分区。 | / |
消费位点 | / | 1. 当需要同步消费位点的时候,如下情况可能导致位点对齐不准: 源端和目标端存在同名 Topic,目标端 Topic 存在其它的消息写入方。 源端和目标端存在同名 Topic,任务重新建立。由于每次任务建立时,数据都会将新建任务启动时读取的最新位置同步至下游,不同步历史数据,历史数据会在这种情况被丢弃。 2. 0.10.2.1 及以下版本实例不支持同步消费位点,若数据同步任务上下游中包含此版本,则不支持创建同步消费位点的任务。 | / |
配置数据同步任务
前提条件
数据源:数据源 Kafka 集群运行状态正常。
数据目标:部署好数据目标 Kafka 集群,集群运行状态正常。
新建 Kafka 数据源和数据目标连接
1. 登录 CKafka 控制台。
2. 在左侧导航栏选择连接器 > 连接列表,选择好地域后单击新建连接。
3. 连接类型选择消息队列Kafka,单击下一步,在设置连接信息页面输入连接名称和描述,用于区分不同的 Kafka 连接。
4. 选择连接 kafka类型。
Kafka 类型 | 说明 |
腾讯云CKafka | 如果客户端和 CKafka 集群部署在同一个私有网络 VPC 内,则网络默认互通。此时可以直接在所属地域和 CKafka 实例的下拉框中选择提前创建好的 CKafka 实例。 |
公网连接 | 如果客户端和 Kafka 集群部署在不同网络环境,可以使用公网实现跨网络生产和消费。公网连接支持自建 Kafka 集群和腾讯云 CKafka 集群。使用公网连接时,建议配置安全策略保障数据传输安全。 Broker地址:输入用户 Kafka 的 Broker 地址。如果有多个 Broker,仅需输入其中 1 个 Broker 的 IP 地址和端口,形式如 127.0.0.1:5664,连接器会打通所有 Broker 的网络。在数据同步期间,必须保证填入的 IP 可用。 ACL 配置:如果连接的源集群开启了 ACL,需要在此处配置相应的访问信息(ACL 用户名和密码)。ACL 配置仅支持静态配置用户(PLAIN 机制),暂不支持动态配置用户(SCRAM 机制)。 |
跨网连接 | 跨网连接可以实现将不同云厂商 Kafka 数据和元数据同步到腾讯云 CKafka,同时也支持将自建 Kafka 数据和元数据同步到腾讯云 CKafka。 VPC 网络:选择客户自建 Kafka 集群的 VPC ID 或者跨云打通的 VPC ID。 子网:选择客户自建 Kafka 集群的 VPC 子网或者跨云打通的 VPC 子网。 云联网 ID:跨云同步时通常需要经过云联网打通专线。 跨云资源 ID:通常为用户连接器上游的实例 ID,标识跨云同步链路中的唯一资源。新建连接时,将自动探测该资源 ID 下的节点信息,执行网络打通,并关联相关的路由规则。删除该连接时,该资源 ID 下自动打通的路由规则将会删除。 Broker地址:输入用户 Kafka 的 Broker 地址。如果有多个 Broker,仅需输入其中 1 个 Broker 的 IP 地址和端口,形式如 127.x.x.1:5664,连接器会打通所有 Broker 的网络。在数据同步期间,必须保证填入的 IP 可用。 ACL 配置:如果连接的源集群开启了 ACL,需要在此处配置相应的访问信息(ACL 用户名和密码)。ACL 配置仅支持静态配置用户(PLAIN 机制),暂不支持动态配置用户(SCRAM 机制)。 |
5. 单击下一步,开始进行连接校验,校验成功后,连接创建完成,在连接列表可以看到创建好的连接。
注意:
1. 跨网连接功能目前仅支持单向数据同步,可将数据从其他云平台同步至腾讯云 CKafka,暂不支持反向同步。
2. 由于各云厂商对 Kafka 集群的访问权限控制策略不同,系统在建立连接时会自动进行权限验证,仅当权限检查通过后才能成功创建连接,否则会提示失败。
3. 当前仅支持 IP:Port 格式的 Broker 地址,用户需提供 Broker 地址信息,CKafka 将在连接建立时自动完成各节点的网络连通配置。
4. 考虑到早期 Kafka 版本功能限制,系统暂不支持 0.10.2 及以下版本的 Kafka 实例作为源端或目标端。
6. 参考同样的步骤继续创建好数据目标 Kafka 连接。
新建数据同步任务
1. 在左侧导航栏单击连接器 > 任务列表,选择好地域后,单击新建任务。
2. 填写任务名称,任务类型选择数据流出,数据目标类型选择 消息队列(Kafka)。
3. 单击下一步,进入数据源配置页面。
配置数据源
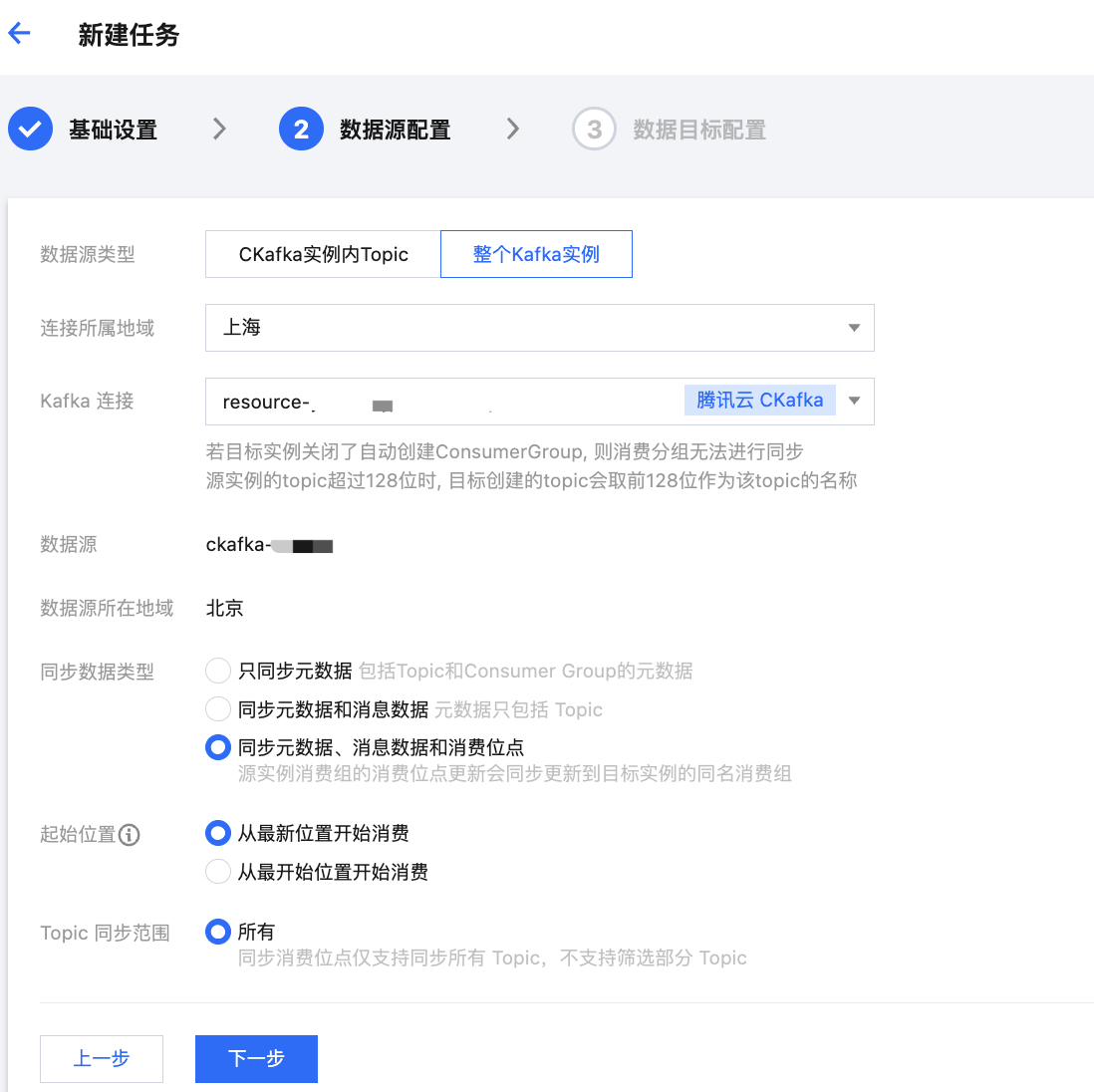
1. 在数据源配置页面设置好数据源信息。
参数 | 说明 |
任务名称 | 输入任务名称,用于区分不同的数据同步任务,任务名称需符合命名规则:只能包含字母、数字、下划线、“-”、“.”。 |
数据源类型 | 选择整个Kafka实例。 |
连接所属地域 | 在下拉框中选择提前配置好的数据源连接所在的地域。 |
Kafka 连接 | 在下拉框中选择提前配置好的数据源连接。 |
同步数据类型 | 只同步元数据:同步源实例内 Topic 和 Consumer Group 的元数据。 同步元数据和消息数据:同步源实例内 Topic 和 Consumer Group 的元数据,以及 Topic 内的消息数据。 同步元数据、消息数据和消费位点:同步源实例内 Topic 和 Consumer Group 的元数据、 Topic 内的消息数据、以及源实例消费组的消费位点。源实例消费组的消费位点更新会同步更新到目标实例的同名消费组。 |
起始位置 | 若选择了同步元数据和消息数据或者同步元数据、消息数据和消费位点,需要配置 Topic offset(偏移量),用于设置转储时对历史消息的处理策略。支持两种方式: 从最新位置开始消费:即最大偏移量,从当前最新的数据开始消费(跳过历史消息)。 从最开始位置开始消费:即最小偏移量,从最早的数据开始消费(同步全部历史消息)。 |
Topic同步范围 | 若选择了同步元数据和消息数据或者同步元数据、消息数据和消费位点,需要配置同步数据的 Topic 范围。 同步元数据和消息数据:支持选择所有 Topic 或者指定部分 Topic。若选择部分 Topic,需通过正则表达式匹配 Topic,表达式验证通过后可以单击进入下一步。 注意: 当使用正则表达式同步部分 Topic 时,不会同步对应 Topic 的消费组。 同步元数据、消息数据和消费位点:只支持选择全部 Topic。 |
2. 信息确认无误后,单击下一步,配置数据目标信息。
配置数据目标
1. 在数据目标配置页面,选择好数据目标的连接。
2. 单击提交,完成任务创建,在任务列表页面可以看到创建好的数据同步任务。任务创建成功后,会自动根据任务设置开始数据同步,实时复制数据。

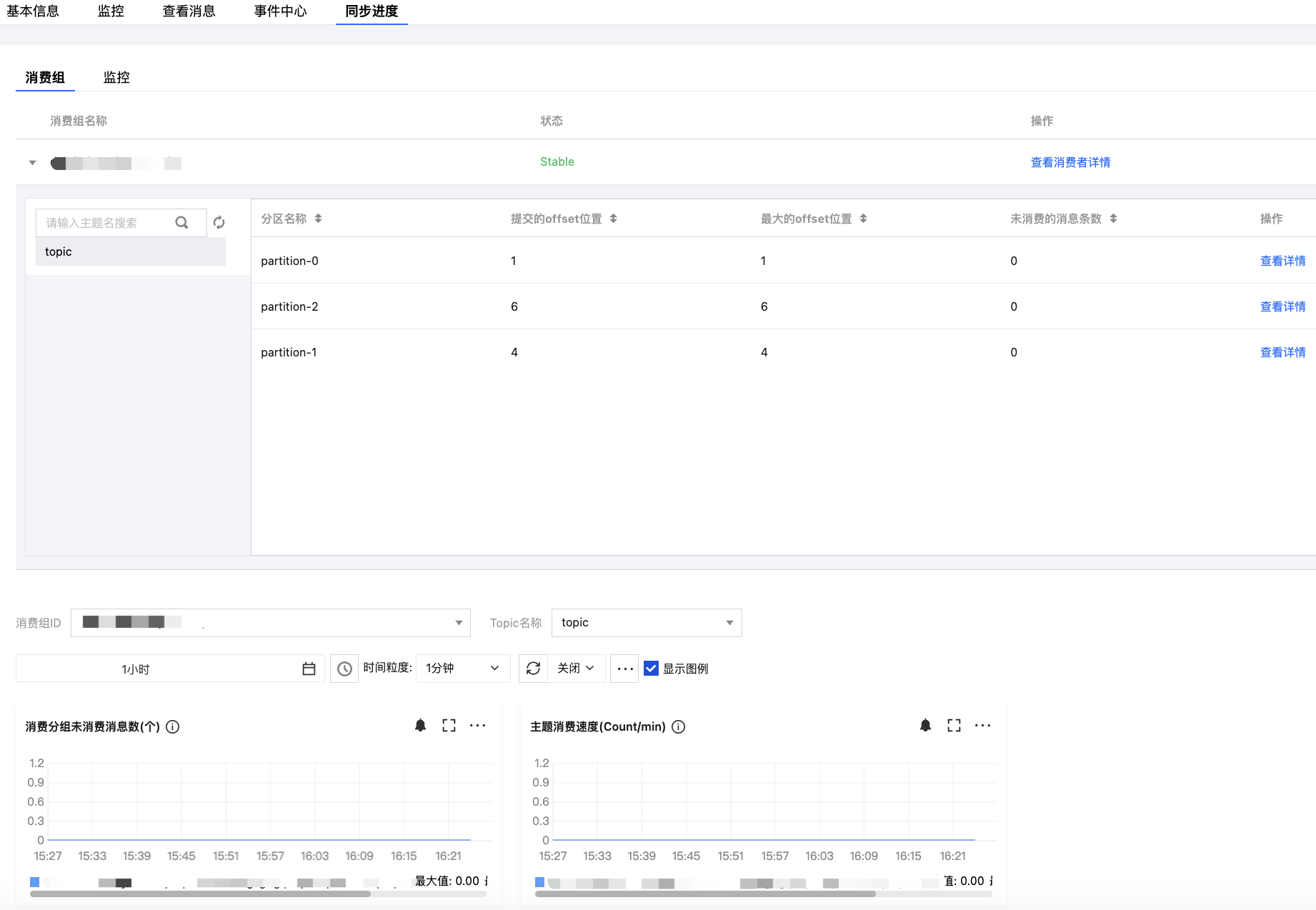
查看数据同步进度
1. 在任务列表页面,单击创建好的任务的“ID”,进入任务的基本信息页面。
2. 在页面顶部选择同步进度页签,可以查看数据同步的进度和详情。
前提条件
已创建腾讯云 CKafka 实例和 Topic,且集群状态为“健康”。
数据源和数据目标 Topic 处于相同的地域。
新建数据复制任务
1. 登录 CKafka 控制台。
2. 在左侧导航栏单击连接器 > 连接列表,选择好地域后,单击新建连接。
3. 地域选择数据目标所在的地域,填写好任务名称,任务类型选择数据流出,数据目标类型选择 消息队列(Kafka),单击下一步。
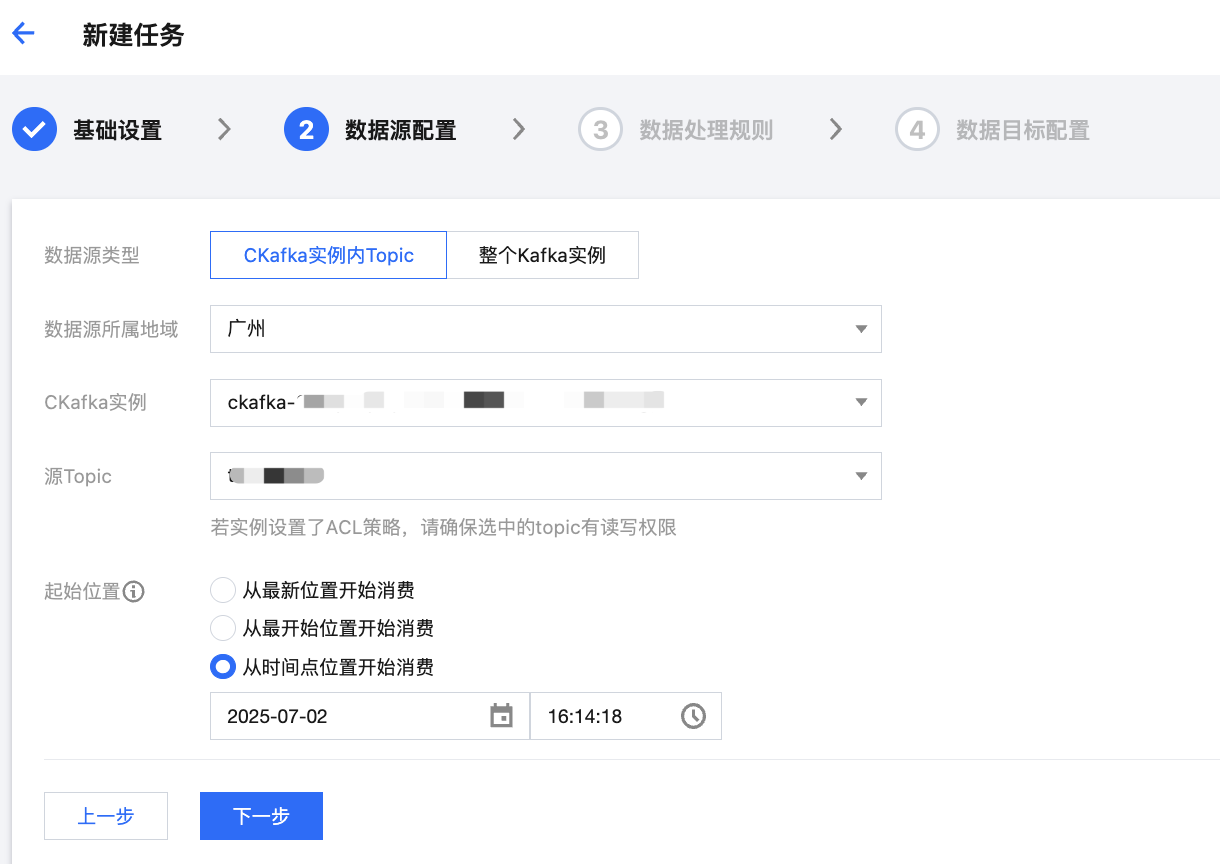
4. 在“数据源配置”页面,配置数据源信息。
参数 | 说明 |
任务名称 | 输入任务名称,用于区分不同的数据同步任务,任务名称需符合命名规则:只能包含字母、数字、下划线、“-”、“.”。 |
数据源类型 | 选择 CKafka实例内Topic。 |
连接所属地域 | 在下拉列表中,选择数据源实例所属的地域。 |
CKafka实例 | 在下拉列表中,选择已准备好的数据源 CKafka 实例。 |
源 Topic | 在下拉列表中,选择已准备好的数据源 Topic。 若数据源实例设置了 ACL 策略,请确保具备选中的数据源 Topic 的读写权限。 |
起始位置 | 配置 Topic offset(偏移量),用于设置转储时对历史消息的处理策略。支持如下三种方式: 从最新位置开始消费:即最大偏移量,从当前最新的数据开始消费(跳过历史消息)。 从最开始位置开始消费:即最小偏移量,从最早的数据开始消费(处理全部历史消息)。 从时间点位置开始消费:从用户自定义的时间点开始消费。 |
5. 设置上述信息后,单击下一步,进入“数据处理规则”页面。
配置数据处理规则
1. 在“数据处理规则”页面,在源数据处单击预览Topic消息,将会选取源 Topic 中的第一条消息进行解析。
说明
目前解析消息需要满足以下条件:消息为 JSON 字符串结构,且源数据必须为单层 JSON 格式,嵌套 JSON 格式可使用数据处理进行简单的消息格式转换。
2. 若需要对源数据进行清洗处理,请开启对源数据进行数据处理按钮,并执行步骤3;若无需清洗数据,只需要完成数据同步,则可以跳过后续步骤,直接进入下个环节配置数据目标。
3. (可选)数据处理规则配置支持从本地导入模板,若已有提前准备好的规则模板,直接导入即可;若无则继续执行步骤4配置数据处理规则,后续配置完数据处理规则后,您也可以将其导出存储为模板,在其他任务中复制使用。
4. 在“原始数据”选择数据来源,支持从源topic拉取或者自定义,此处以从从源topic拉取为例。

5. 在“解析模式”选择对应的数据解析模式并确认,可以看到数据解析结果。此处以 JSON 模式为例,单击左侧的解析结果可以在右侧生成结构化预览。
解析模式 | 说明 |
JSON | 解析标准 JSON 格式的数据,支持嵌套字段,输出格式为键值对。 |
分隔符 | 按指定分隔符解析非结构化文本,分隔符支持 空格、制表符、,、;、|、:、自定义。 |
正则提取 | 说明: 当输入的正则表达式中含有类似 (?<name>expr) 或者 (?P<name>expr) 捕获组时,会将正则表达式视为模式串进行匹配,当消息成功匹配模式串时将解析捕获组内容;否则,会将整个输入的正则表达式视为捕获组,并提取消息中所有匹配的内容。 |
JSON对象数组- 单行输出 | 数组内每个对象的格式一致,解析时仅解析第一个对象,输出结果为单条的 JSON,是 map 类型。 |
JSON对象数组- 多行输出 | 数组内每个对象的格式一致,解析时仅解析第一个对象,输出结果为数组类型。 |
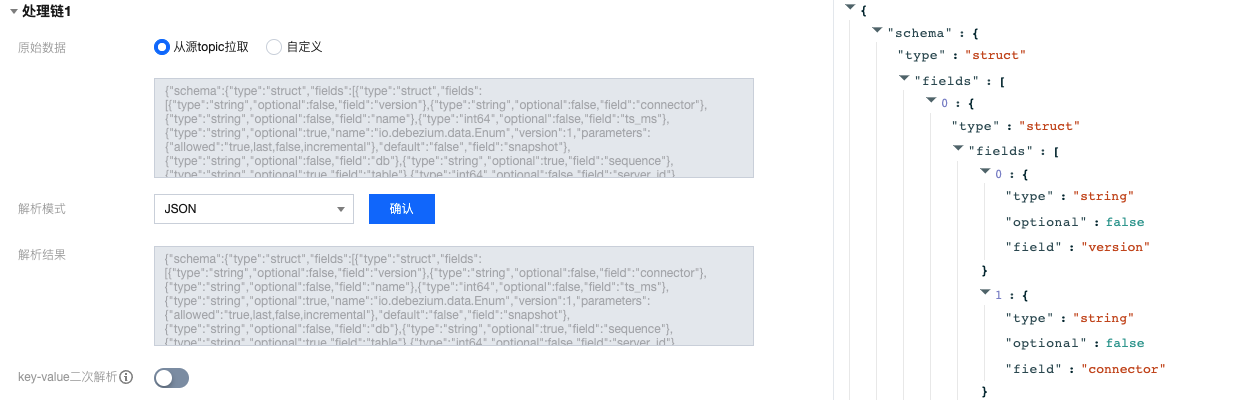
6. 若开启 key-value二次解析,将对 value 里的数据再次进行 key-value 解析。
7. 在“数据处理”区域设置数据处理规则,此处可对字段进行编辑、删减,调整时间戳格式,并新增当前系统时间字段等等。单击处理value 可以添加处理链对处理后的单条数据进行再次处理。
操作 | 说明 |
映射 | 可以选择已有的 KEY,最终输出的 VALUE 值由指定的 KEY 映射而来。 |
JSONPATH | |
系统预设-当前时间 | 可以选择系统预设的 VALUE ,目前支持 DATE(时间戳)。 |
自定义 | 可以输入自定义 VALUE。 |
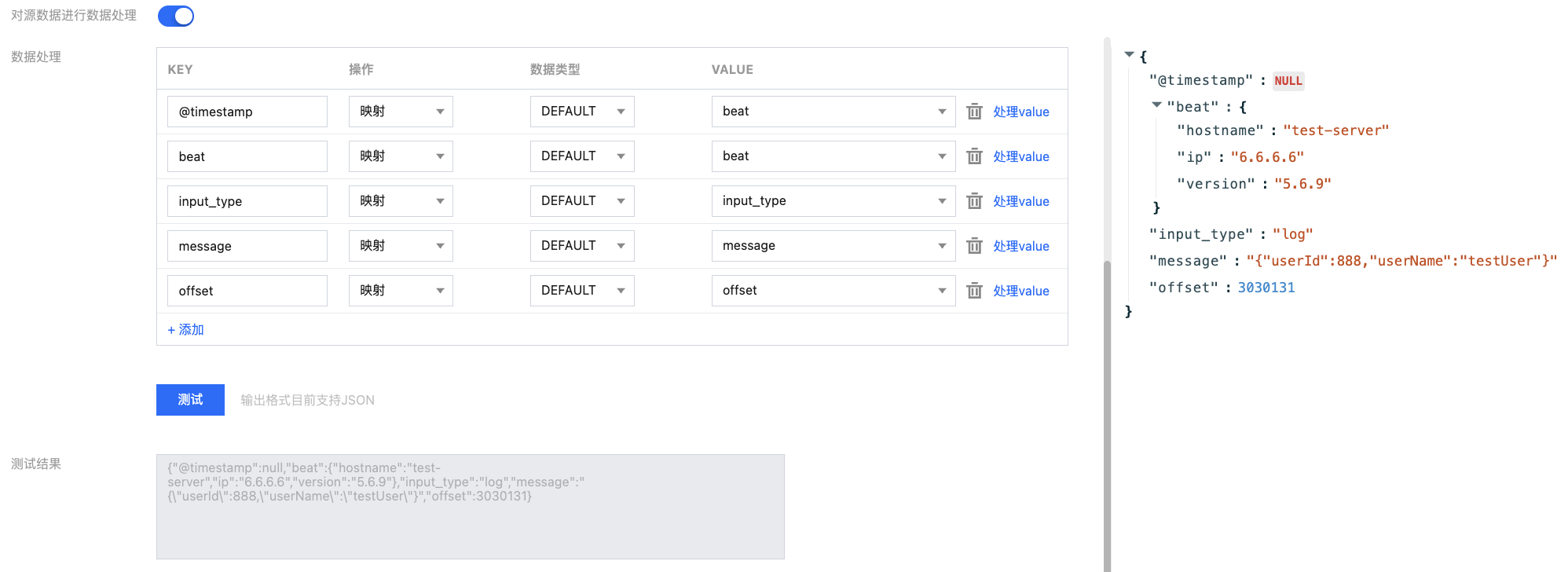
8. 单击测试,查看数据处理的测试结果。此时可根据实际业务需求添加处理链可对上面数据处理结果再次进行处理。
9. 在“过滤器”选择是否开启过滤器,若开启则可以仅输出符合过滤器规则的数据。过滤器的匹配模式支持前缀匹配、后缀匹配、包含匹配(contains)、除外匹配(except)、数值匹配和 IP匹配。详情参见 过滤器规则说明。
10. 在“保留 Topic 源数据”选择是否开启保留 Topic 源数据。
11. 在“输出格式”设置数据输出内容,默认为 JSON,支持 ROW 格式,若选择 ROW 格式需要选择输出行内容。
输出行内容 | 说明 |
VALUE | 只输出上方测试结果中的 VALUE 值,用分隔符隔开。VALUE 间分隔符默认为“无”选项。 |
KEY&VALUE | 输出上方测试结果中的 KEY 和 VALUE,KEY 和 VALUE 间分隔符和 VALUE 间分隔符均不能为“无”。 |
12. 在“失败消息处理”设置投递失败的消息处理规则,支持丢弃、保留和投递到死信队列三种方式。
处理方式 | 说明 |
丢弃 | 适合用于生产环境,任务运行失败时将会忽略当前失败消息。建议使用 "保留" 模式测试无误后,再将任务编辑成 "丢弃" 模式用于生产。 |
保留 | 适合用于测试环境,任务运行失败时将会终止任务不会重试,并且在事件中心中记录失败原因。 |
投递到死信队列 | 需指定死信队列 Topic,适合用于严格生产环境,任务运行失败时会将失败消息及元数据和失败原因投递到指定的 CKafka Topic 中。 |
13. 数据规则配置完成后,可以直接在顶部单击导出为模板,在后续的数据任务中复制使用,减少重复配置的操作成本。
14. 单击下一步,配置数据目标。
配置数据目标
1. 在数据配置目标页面,选择好数据流转的目标 Topic,并设置好消息复制倍数,若消息复制倍数设置为N,则源端写一条消息,目标端写N条消息。
2. 单击提交,完成任务创建,在任务列表页面可以看到创建好的数据同步任务。任务创建成功后,会自动根据任务设置开始数据同步,实时复制数据。

查看数据同步进度
1. 在任务列表页面,单击创建好的任务的“ID”,进入任务的基本信息页面。
2. 在页面顶部选择同步进度页签,可以查看数据同步的进度和详情。