一、引言
本文主要面向已掌握 RAG 基础概念的读者,因此不再重复阐述 RAG 的基本定义及其核心价值。在阅读这篇最佳实践之前,先回答一个问题:在上千万 tokens 上下文窗口模型出现后,为什么我们仍然需要 RAG?
其实很简单,将所有数据都加载到模型上下文中是否能行得通?我将列出以下问题:
1. 可扩展性:企业知识库以 TB 或 PB 为单位,而不是以 token 为单位,即使有1000万个 tokens 上下文窗口,仍然只能看到可用信息的一小部分。
2. 准确性:实际的上下文窗口与产品发布时宣传的差异巨大,研究 一致表明,早在模型达到官方宣传极限之前,准确性就已经下降到不可用的情况。
3. 延迟:将所有内容加载到模型的上下文中会导致响应时间显著延长。对于面向用户的应用程序来说,用户在得到答案之前就会放弃交互,体验很差。
4. 效率:每次回答一个简单的问题,您都要翻阅整本教科书吗?
在 RAG 中,高效精准的检索其实是非常关键的,混合搜索以及结构化数据支持方面的进步,有助于在知识库中找到正确信息,从而解决上述的问题。同时,RAG 与长上下文、微调、MCP这些概念并不排斥,他们可以通过最佳的协同方式去解决前沿模型的局限性:
RAG 提供对模型知识之外的信息的访问。
微调可以改善信息的处理和应用方式,让大模型更加智能、专业。
更长的上下文允许检索更多信息,以供模型进行推理。
MCP 简化了代理与 RAG 系统(和其他工具)的集成。
最近腾讯云 ES 发布的新特性智能搜索开发,以 AI 搜索增强版内核为底座,进一步优化了对全文与向量混合搜索的能力支持,从原始文档解析、向量化等原子能力,到查询性能、混合排序效率、搜索结果精准度等提供了全方位的支持和优化,让搜索有了更多想象空间。 在此基础上,还可以与混元、DeepSeek 等大语言模型无缝集成,从而帮助企业进一步高效、灵活地构建知识问答等 RAG 应用,在关键环节也可介入调优,整体流程如下:
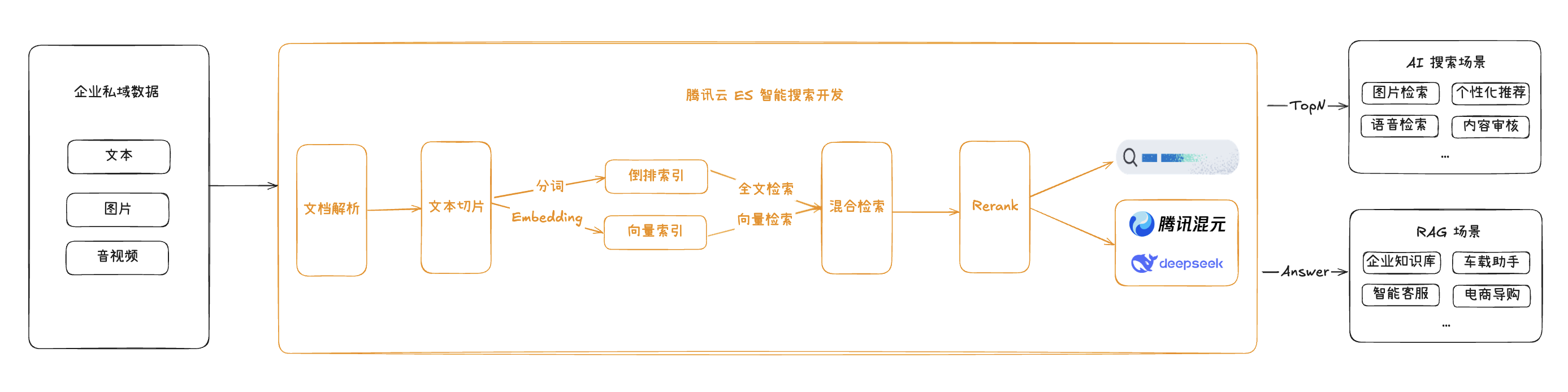
接下来具体看下搭建过程。
二、AI 助手搭建
您只需要将下面的文件运行成功,即可快速构建一个AI 问答应用。
数据写入:(二选一)
如果您有大批量文档或正式生产:运行 data_input.py。
如果您想快速搭 demo 体验:运行 data_input_streamlit.py。
在线问答:search.py。
# 腾讯云API客户端配置,获取方式见【3.获取API密钥】SECRET_ID = "AKID******" # 替换为您的云API SecretIdSECRET_KEY = "******" # 替换为您的云API SecretKey# es集群相关配置,获取方式见【1.购买集群】【2.获取ES访问地址】# 用户名为 elastic、密码在创建集群时设置。用本地环境测试时,可开启公网访问,实际生产时,建议使用内网访问地址。ES_ENDPOINT = "https://es-******.tencentelasticsearch.com:9200"ES_USERNAME = "elastic" # Elasticsearch集群用户名ES_PASSWORD = "******" # Elasticsearch集群密码INDEX_NAME = "索引名称" # 在写入时要保证索引未被创建过,会默认创建索引并设置mapping,写入数据和在线问答的索引保持一致# 数据入库时,选择COS方式需设置您的COS文件路径# 要处理的文档URL(推荐将文件存放到COS存储,并开启「公有读私有写」权限)document_url = "https://xxx.cos.xxx/sample.doc"
前置条件
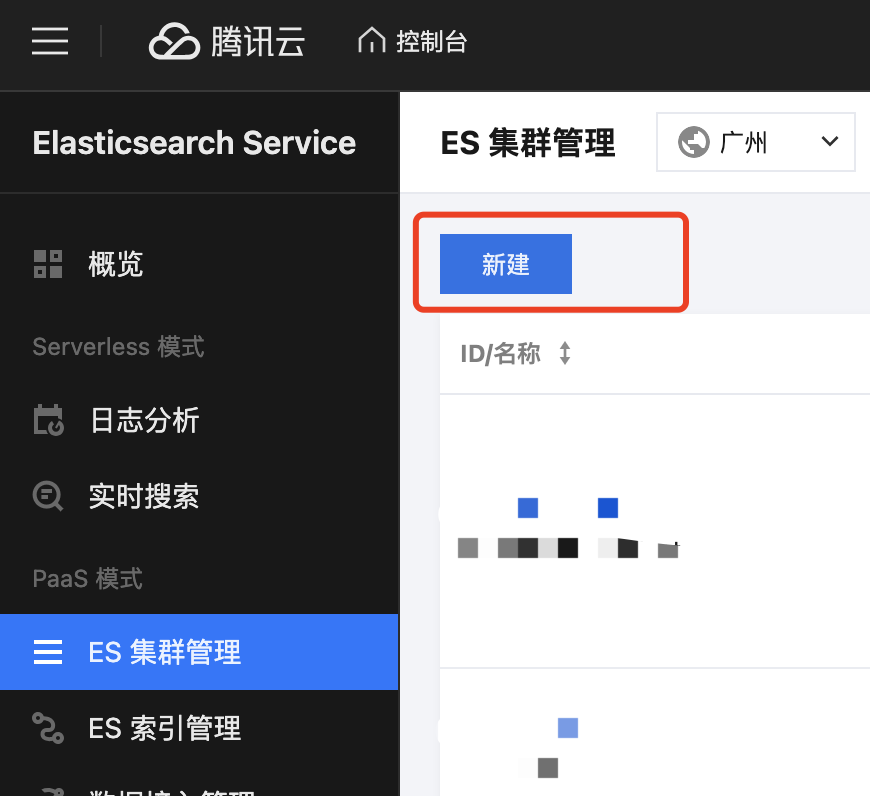
1. 购买 ES 集群
1. 登录腾讯云 ES 控制台,进入 ES 集群管理 页面,单击新建按钮。
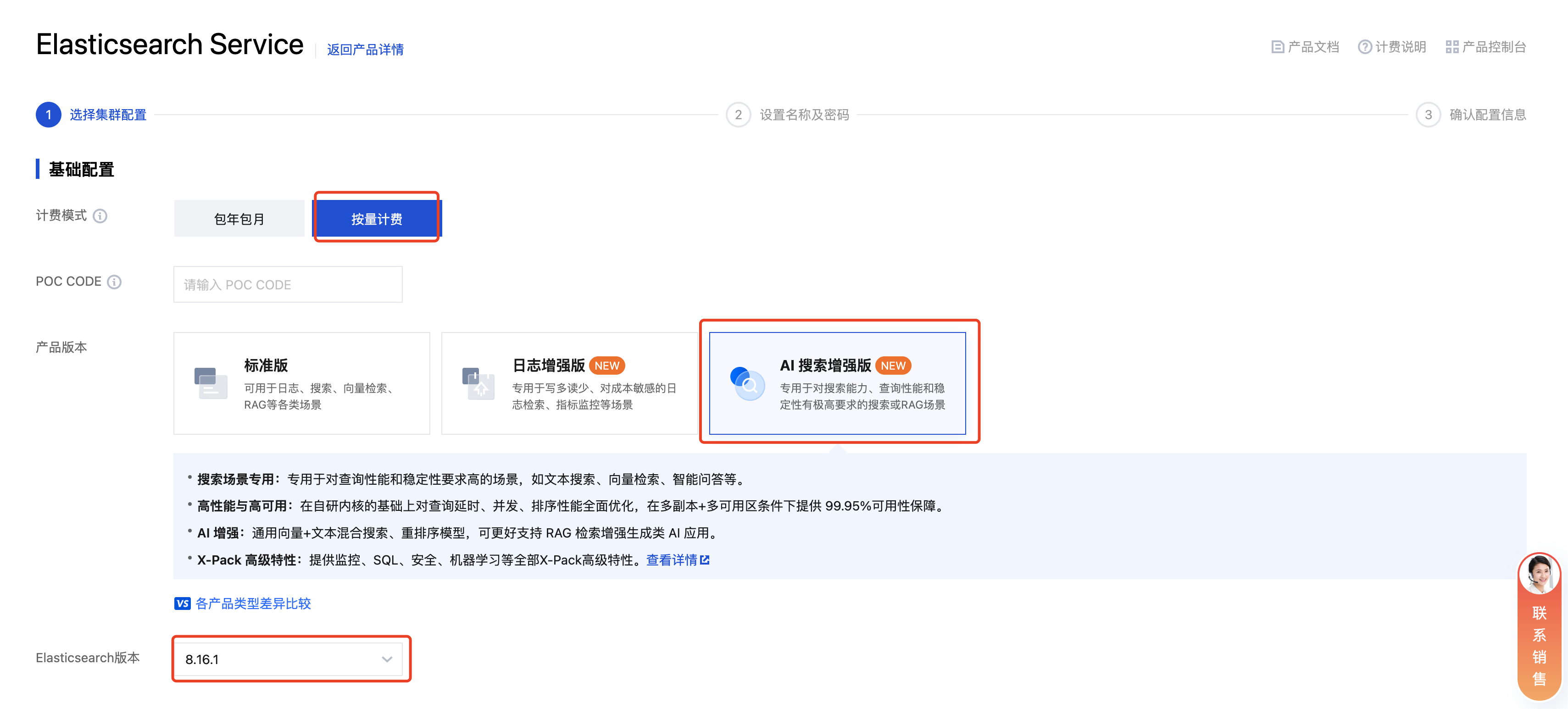
2. 进入新建集群界面,填写以下信息:
用于测试验证计费模式可选按量计费。
产品版本选择 AI 搜索增强版,专用于对搜索能力、查询性能和稳定性有极高要求的搜索和 RAG 场景。
Elasticsearch 版本选择 8.16.1,向量能力主要集中在 8.x 以上版本。
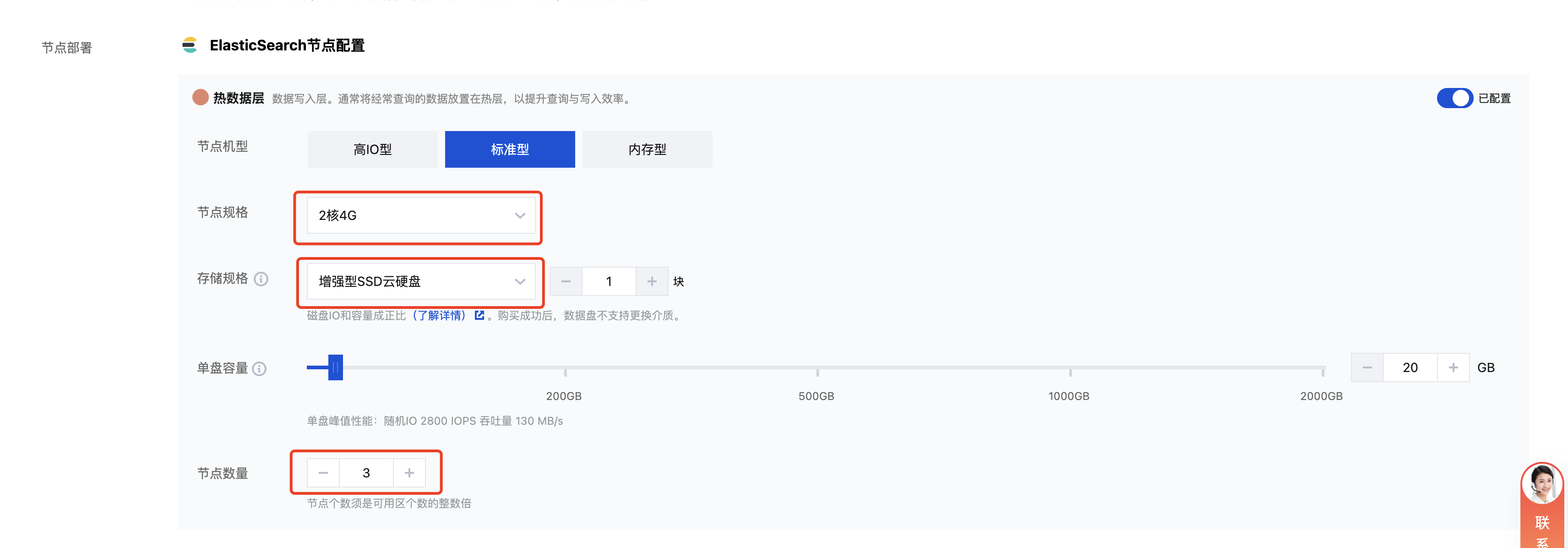
3. ES 节点配置,测试验证可选择为:
节点规格:2核4G。
节点数:默认为 3。
磁盘:为增强型 SSD云硬盘。
磁盘容量:为 20GB。
4. 其余配置选择默认即可,注意保存集群访问密码。
2. 获取 ES 访问地址
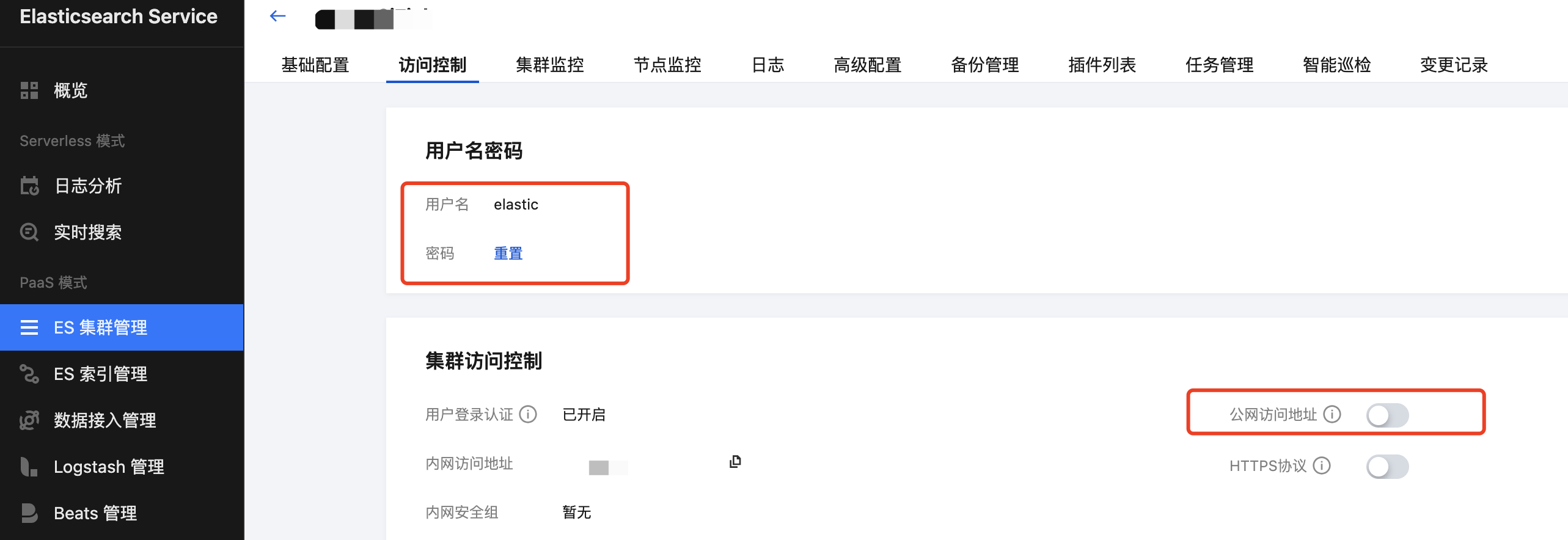
3. 开通服务
现在集群创建好了,在数据入库以及查询时需要用到很多模型服务,腾讯云 ES 智能搜索开发已经集成了文档解析、文本切片、Embedding、Rerank、LLM 服务,只需要在 控制台 开通服务即可,单击立即开通,确认免费开通。
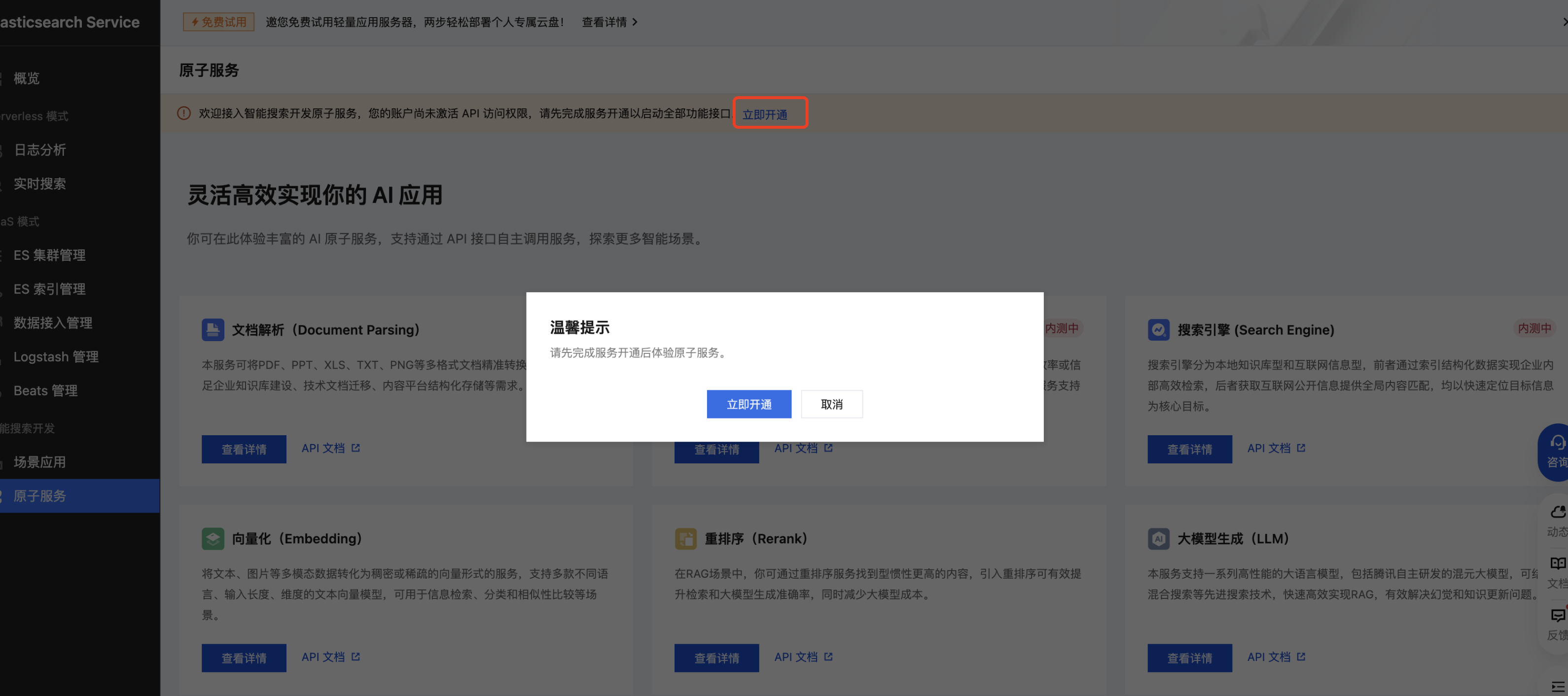
4. 获取 API 密钥

搭建步骤
1. 安装依赖
# Python版本:3.9及以上pip install elasticsearch==8.16.0pip install tencentcloud-sdk-pythonpip install urllib3 certifi# 安装文档处理包pip install python-docx pypdf2 lxmlpip install streamlit #使用COS数据入库时,无需安装
2. 数据入库
这里提供了如下两种方式:
如果有大批量的文档需要进行处理,或者您需要上生产,那建议按 COS 上传 方式入库,这种方式更加稳定和安全。
如果您只是简单体验一下 AI 问答 demo,并通过界面可视化的方式操作,那可以按 本地上传 的方式入库。
方式一:COS上传(可选)
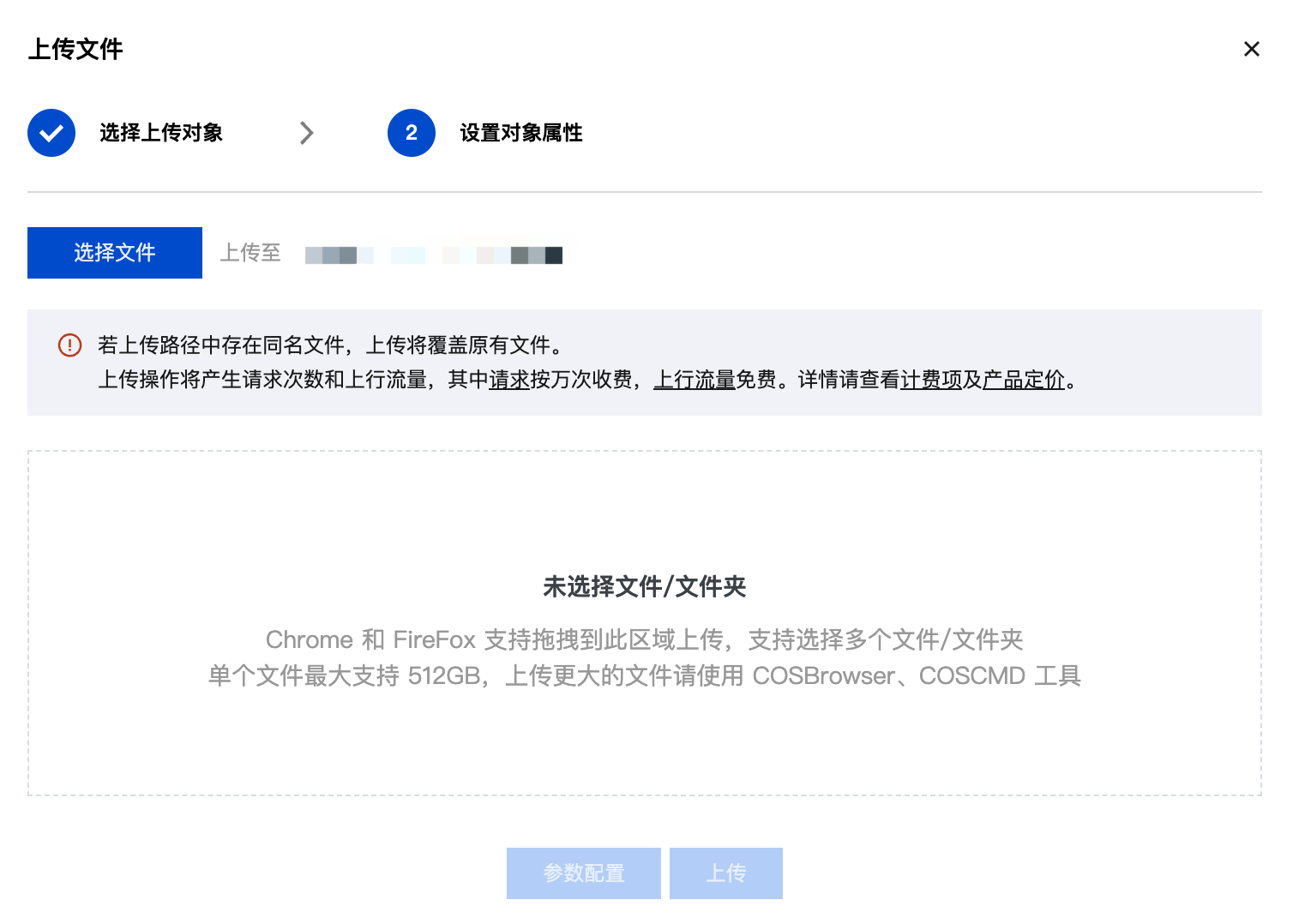
1. 先将需要处理的文档拖入对应 COS 桶,具体操作步骤:进入 对象存储控制台,单击存储桶列表,在对应文件存储桶,单击上传文件,出现以下弹框,拖拽需要上传的文件即可。
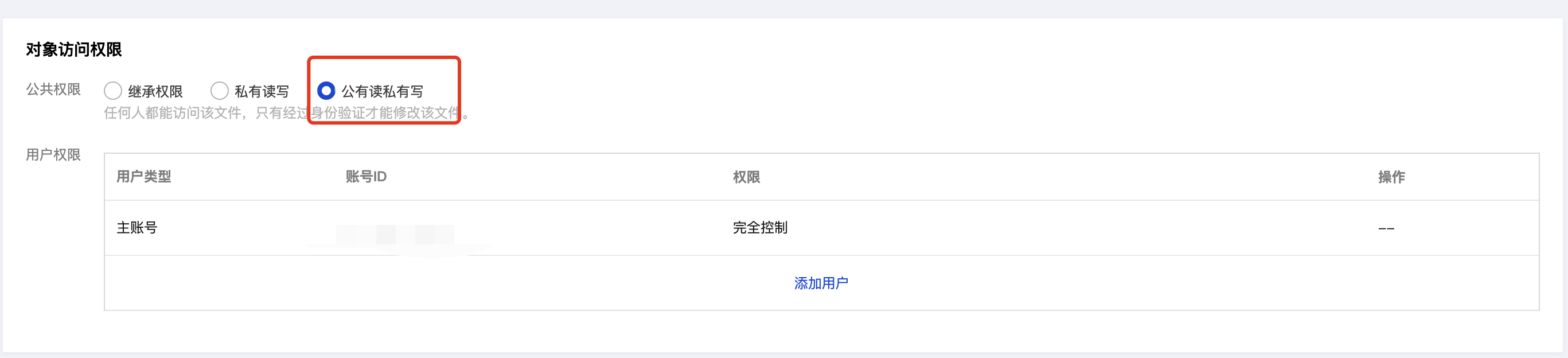
2. 然后设置文档权限,这里需要对文档进行解析切片处理,所以需要开放公有读私有写权限,具体操作:进入对象存储控制台,单击存储桶列表,找到对应文件存储桶,单击文件详情,开启公有读私有写权限。
3. 在 data_input.py 文件中,修改 main 方法中的 document_url 为您上传的 COS 文件地址。
# 要处理的文档URL(推荐将文件存放到COS存储,并开启「公有读私有写」权限。document_url = "https://xxx.cos.xxx/sample.doc"
4. 然后,在终端运行该文件:
python data_input.py
方式二:本地上传(可选)
1. 在终端运行 data_input_streamlit.py 文件,在终端执行如下命令。
streamlit run data_input_streamlit.py
2. 将要上传的文档拖拽进去,或者单击 Browse files 按钮,选择文件上传,效果如下:
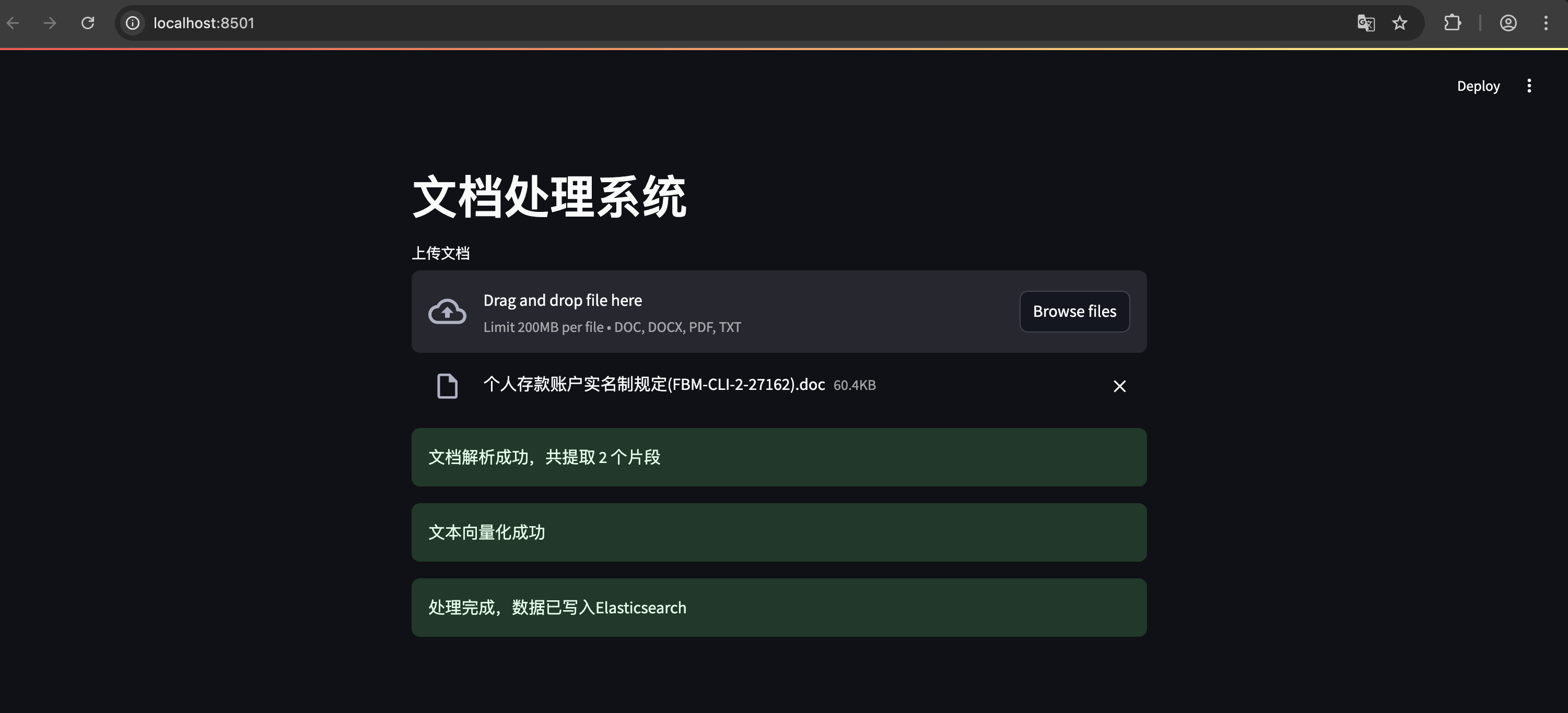
3. 在线问答
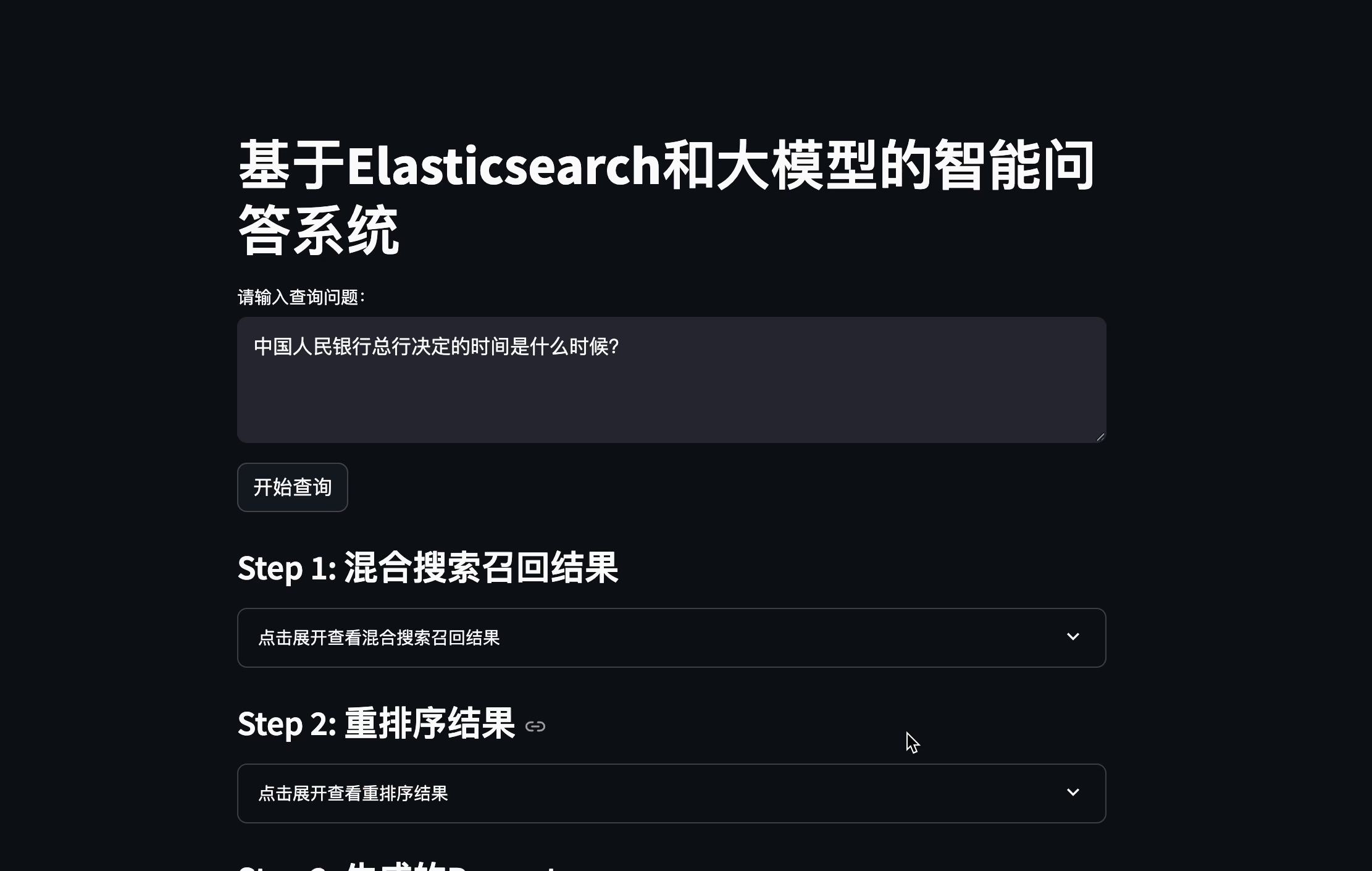
streamlit run search.py
在输入框中提出相关问题,系统会进行混合搜索 > 重排序 > 组装 Prompt > 大模型回答一系列动作,整个流程中间内容可见,最后生成回答内容。效果如下:
三、核心代码解析
1. 数据入库
1.1. 文档解析/切片
常量 MAX_CHUNK_SIZE 即为文本切片单条文本最大字符数,不小于1000,可以根据您的具体业务,确定合适的最大字符数。在 Embedding 过程中,选定的模型 Tokens 限制应大于您设定的最大字符数,否则会出现截断的可能。向量化模型参数请参见 向量化(Embedding)模型列表。
常量 DOCUMENT_CHUNK_MODEL_NAME 即为选择的文档解析切片模型,“doc-tree-chunk”包含了文档解析和切片部分,这里可以直接用。
MAX_CHUNK_SIZE = 2000 # 文本切片单条文本最大字符个数(根据具体选用的Embedding模型tokens设定,最小值不小于1000)DOCUMENT_CHUNK_MODEL_NAME = "doc-tree-chunk"# 调用ChunkDocumentAsync接口创建文档切片任务params = {"Document": {"FileType": file_type,"FileUrl": file_url,"FileName": os.path.basename(urlparse(file_url).path)},"Config": {"MaxChunkSize": MAX_CHUNK_SIZE # 可根据需要调整切片大小},"ModelName": DOCUMENT_CHUNK_MODEL_NAME}response = retry_request(client.call_json, "ChunkDocumentAsync", params)task_id = response['Response']['TaskId']logger.info(f"Created document chunking task with ID: {task_id}")
解压获取到的结果,切片好的数据存放在 xxx.jsonl 文件内,对应 page_content 即为切片数据。
try:with zipfile.ZipFile(io.BytesIO(response.content)) as zip_file:# 检查zip中是否有.jsonl文件jsonl_files = [f for f in zip_file.namelist() if f.endswith('.jsonl')]if not jsonl_files:error_msg = "No .jsonl file found in the zip archive"logger.error(error_msg)raise Exception(error_msg)# 处理每个jsonl文件for file_name in jsonl_files:with zip_file.open(file_name) as f:# 逐行读取jsonl文件for line in f:try:data = json.loads(line.decode('utf-8'))if 'page_content' in data:doc_list.append(data['page_content'])except json.JSONDecodeError as e:logger.warning(f"Failed to parse JSON line: {str(e)}")continue
1.2. 切片 Embedding
如果文本内容过长,分片个数较大时,建议分批次获取 Embedding,建议每次设置最大元素个数在1 - 20之间,可以保证更高的效率。
BATCH_EMBEDDING_SIZE = 20 # 单次向量化入参设置的最大元素个数(建议1-20)document_embedding_list = batch_get_text_embeddings(client=tencent_cloud_client,docs=chunk_list,batch_size=BATCH_EMBEDDING_SIZE, # 根据API限制调整单个批次获取向量化的元素个数max_workers=2 # 根据服务器CPU核心数调整)# 调用GetTextEmbedding进行向量化。模型选择参考:https://cloud.tencent.com/document/product/845/118215EMBEDDING_MODEL_NAME = "bge-base-zh-v1.5"response = retry_request(func=client.call_json,action="GetTextEmbedding",params={"ModelName": EMBEDDING_MODEL_NAME,"Texts": docs})
1.3. 文本&向量数据写入
# 定义索引映射mappings = {"mappings": {"properties": {"content_embedding": {"type": "dense_vector","dims": EMBEDDING_MODEL_DIMS,"index": True,"similarity": "cosine", # 指定相似度计算方式为余弦相似度"index_options": {"type": "int8_hnsw", # 使用int8量化的HNSW(Hierarchical Navigable Small World)算法进行索引"m": 16, # HNSW参数,表示每个节点在图中连接的邻居数,影响索引的构建和搜索性能"ef_construction": 100 # HNSW参数,表示构建索引时考虑的候选列表大小,影响索引质量和构建时间}},"content": {"type": "text","index": True}}}}
通过 Bulk API 批量写入数据。原始文档信息和向量化之后的数据均进行存储,方便 ES 混合搜索,提高召回率。
原始文档写入 content 字段,向量写入 content_embedding 字段。
actions = [{"_index": index_name,"_id": str(doc["index"]),"_source": {"content": doc["content"], # 原始文本内容"content_embedding": doc["content_embedding"] # 向量}}for doc in embeddings]
2. 在线问答
对应 search.py 文件,主要讲述用户的一个 Query 语句进来后,经过向量化,从 ES 中进行混合检索召回 TopK,然后经过 Rerank 再精排过滤后,结合 Prompt 工程喂给大模型进行总结回答,具体如下:
2.1. Query 向量化
对 Query 语句进行向量化,具体调用方式本质上是与切片向量化一致,不再赘述。
2.2. 文本&向量混合检索
指定向量字段,对 Query 向量进行向量相似度检索,获取前 k 条向量数据,同时进行全文检索,在最后将两者进行融合排序。
关于文本与向量的权重可以通过"weights"设置,可根据具体业务数据调试,取效果最优的权重即可。
通用场景参考如下:
电商搜索:提升关键词权重(权重比 3:1 或更大)
内容推荐:增强语义相关性(权重比 1:2 或更大)
知识库检索:平衡语义与关键词(权重比 1:1 微调)
# 使用8.16集群的混合搜索语法(并行召回:返回 query 和 knn 召回结果的并集)mix_query = {"retriever": {"rank_fusion": {"retrievers": [{"standard": {"query": {"match": {"content": query}}}},{"knn": {"field": "content_embedding","query_vector": [...], # 向量字段"k": 5,"num_candidates": 10}}],"weights": [2, 1],"rank_constant": 20}}}
2.3. 召回结果重排序
调用 Rerank 模型进行重排序。
Rerank 模型请参见 Rerank 模型列表。
TopN 即为排序返回的 top 文档数量。
如果没有指定,则返回全部候选 doc。
如果指定的 TopN 值大于输入的候选 doc 数量,返回全部 doc。
RERANK_MODEL_NAME = "bge-reranker-large"json_object = {"ModelName": RERANK_MODEL_NAME,"Query": query,"ReturnDocuments": True,"Documents": docs,"TopN":5 # 排序返回的top文档数量, 如果没有指定则返回全部候选doc,如果指定的TopN值大于输入的候选doc数量,返回全部doc}
2.4. 组装 Prompt
设置自己的 Prompt 模板,注意预留 user_query 和 documents_str 占位符,分别代表问题与检索到最相关的切片上下文。
PROMPT_TEMPLATE = """# 任务说明您是一位专业的AI助手,需要基于提供的参考文档准确回答用户问题。请严格遵循以下要求:# 用户问题{user_query}# 参考文档(已按相关性排序){documents_str}# 回答要求- 简明扼要的核心答案(1-2句话)- 详细解释或分点说明(3-5点,视问题复杂度而定)- 可选的补充信息或建议(如适用)- 对于事实性问题:提供准确数据或事实- 对于观点性问题:呈现不同角度的分析- 对于操作性问题:给出步骤清晰的指导- 对于比较性问题:进行客观对比分析"根据现有资料,我暂时无法提供令人满意的答案。建议您补充更多相关信息或重新提问。"# 特别注意1.保持回答专业、准确且流畅2.如文档中有数据或研究结果,请优先引用3.根据问题复杂度控制回答长度在200-400字之间4.对于专业术语,必要时提供简单解释5.避免使用"根据文档"等冗余表述,直接整合信息到回答中"""
2.5. 调用 DeepSeek 回答
调用 deepseek-v3 大模型进行总结回答,当然您可以切换不同 hunyuan 以及 deepseek 大模型进行体验。如果期望返回值是流式响应时,则设置 Stream 为 True。
# 设置deepseek-v3模型(这里可以设置为您想要的模型,参考:https://cloud.tencent.com/document/api/845/117810)LLM_MODEL_NAME = "deepseek-v3"# 调用大模型回答,content即为build_llm_prompt返回组装后的promptdef generate_llm_response(content: str) -> Dict[str, Any]:"""调用大模型生成回答Args:content: 要发送给大模型的prompt内容Returns:大模型的响应结果Raises:Exception: 如果调用大模型过程中出现错误"""if not content.strip():raise ValueError("空内容无法生成回答")json_object = {"Messages": [{"Role": "user", "Content": content}],"ModelName": LLM_MODEL_NAME,"Stream": False # 可以设置成True,流式输出}try:response = tencent_cloud_client.call_json("ChatCompletions", json_object)return responseexcept Exception as e:logger.error(f"大模型调用失败: {e}")raise
四、总结
腾讯云 ES 凭借其在传统 PB 级日志和海量搜索场景中积累的丰富经验,通过深度重构底层系统,成功地将多年的性能优化、索引构建和运营管理经验应用于 RAG 领域,并积极探索向量召回与传统搜索技术的融合之道,旨在充分发挥两者的优势,为用户提供更加精准、高效的搜索体验。未来,腾讯云 ES 将持续深耕智能检索领域,在成本、性能、稳定性等方面持续提升,帮助客户降本增效的同时实现业务价值持续增长。
其实,用 ES Inference API 构建 RAG 应用会更加便捷,相关能力马上推出,欢迎关注下一篇实践文章。



