介绍
Apache Paimon 是一种流批统一的数据湖存储格式,创新地结合了湖格式和 LSM 结构,将实时流式更新引入湖架构。
使用范围
支持类型 | Source 和 Sink |
运行模式 | 流、批 |
API 种类 | SQL |
写入模式 | append / upsert |
版本说明
Flink 版本 | 是否支持 | Paimon 社区版本 |
1.13 | 不支持 | - |
1.14 | 不支持 | - |
1.16 | 支持 | 0.9 |
创建 Paimon Catalog
目前 Oceanus 上的 Paimon Catalog 支持 2 种 metastore:
Filesystem:默认类型,将元数据和表文件都存储在文件系统中。
Hive:额外将元数据存储在 Hive Metastore 中,用户可以直接从 Hive 访问表。
FileSystem Metastore
以下 SQL 创建一个名为 my_catalog 的 Paimon Catalog,元数据和表文件存储在 hdfs://HDFS14979/usr/hive/warehouse 下。
CREATE CATALOG my_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs://HDFS14979/usr/hive/warehouse');
说明:
Hive Metastore
以下 SQL 注册并使用一个名为 my_hive 的 Paimon Catalog。
CREATE CATALOG my_hive WITH ('type' = 'paimon','metastore' = 'hive',-- 'uri' = 'thrift://<hive-metastore-host-name>:<port>', -- 默认使用 HiveConf 中的 ‘hive.metastore.uris’-- 'warehouse' = 'hdfs://HDFS14979/usr/hive/warehouse', -- 默认使用 HiveConf 中的 ‘hive.metastore.warehouse.dir’);
说明:
创建 Paimon 表
在使用 Paimon Catalog 后,可以创建和删除表。在 Paimon Catalog 中创建的表由 Catalog 管理,删除表时其文件也会被删除。
DDL 定义
-- 创建主键表CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED) WITH ('bucket' = '10',-- 其他 with 参数);-- 创建分区表CREATE TABLE my_table (user_id BIGINT,item_id BIGINT,behavior STRING,dt STRING,hh STRING,PRIMARY KEY (dt, hh, user_id) NOT ENFORCED) PARTITIONED BY (dt, hh) WITH ('bucket' = '10',-- 其他 with 参数);
WITH 参数
参数 | 数据类型 | 是否必填 | 默认值 | 描述 |
bucket | Integer | 否 | -1 | Paimon 表的分桶数。可选取值如下: -1:动态分桶模式 大于 0:固定分桶模式 |
bucket-key | String | 否 | 无 | 指定用于数据分桶的列。数据根据分桶键 (bucket-key) 的哈希值分配到每个桶。如果指定多个字段,用逗号分隔。如未指定,将使用主键。如果没有主键,则使用整行 |
changelog-producer | Enum | 否 | none | changelog 生成机制,可选取值如下: none:不生成 changelog input:将输入数据流双写至 changelog 文件中,作为 changelog full-compaction:每次 full compaction 时生成 changelog lookup:通过 lookup 的方式生成 changelog |
merge-engine | Enum | 否 | deduplicate | 相同 primary key 数据的合并机制,可选取值如下: deduplicate:去重并保留最后一行 partial-update:部分更新非空字段 aggregation:聚合具有相同主键的字段 first-row: 去重并保留第一行 |
snapshot.num-retained.max | Integer | 否 | 2147483647 | 最多保留几个最新 Snapshot 不过期,应大于等于 snapshot.num-retained.min |
snapshot.num-retained.min | Integer | 否 | 10 | 最少保留几个最新 Snapshot 不过期,应大于等于 1 |
snapshot.time-retained | Duration | 否 | 1h | Snapshot 产生多久以后会过期 |
Paimon Source 示例
-- 创建 logger sinkCREATE TABLE logger_sink (id BIGINT,name STRING) WITH ('connector' = 'logger','print-identifier' = 'DebugData');-- 创建 paimon catalogCREATE CATALOG paimon_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs://HDFS14979/usr/hive/warehouse');-- 从 paimon 读取数据写入 logger sinkINSERT INTO logger_sinkSELECT * FROM paimon_catalog.test_db.user_info;
Paimon Sink 示例
-- 创建 datagen sourceCREATE TABLE datagen_source (id BIGINT,name STRING) WITH ('connector' = 'datagen','rows-per-second' = '10');-- 创建 paimon catalogCREATE CATALOG paimon_catalog WITH ('type' = 'paimon','warehouse' = 'hdfs://HDFS14979/usr/hive/warehouse');-- 创建 paimon 库和表(存在则不创建)CREATE DATABASE IF NOT EXISTS paimon_catalog.test_db;CREATE TABLE IF NOT EXISTS paimon_catalog.test_db.user_info (id BIGINT,name STRING,PRIMARY KEY (id) NOT ENFORCED) WITH ('bucket' = '2');-- datagen 生成数据写入 paimon 表INSERT INTO paimon_catalog.test_db.user_infoSELECT * FROM datagen_source;
上下游配置
COS 配置
使用 COS 存储时无需做额外配置,warehouse 填写为对应的 cosn 路径即可。
元数据加速 COS 桶配置
1. 创建存储桶时开启元数据加速。
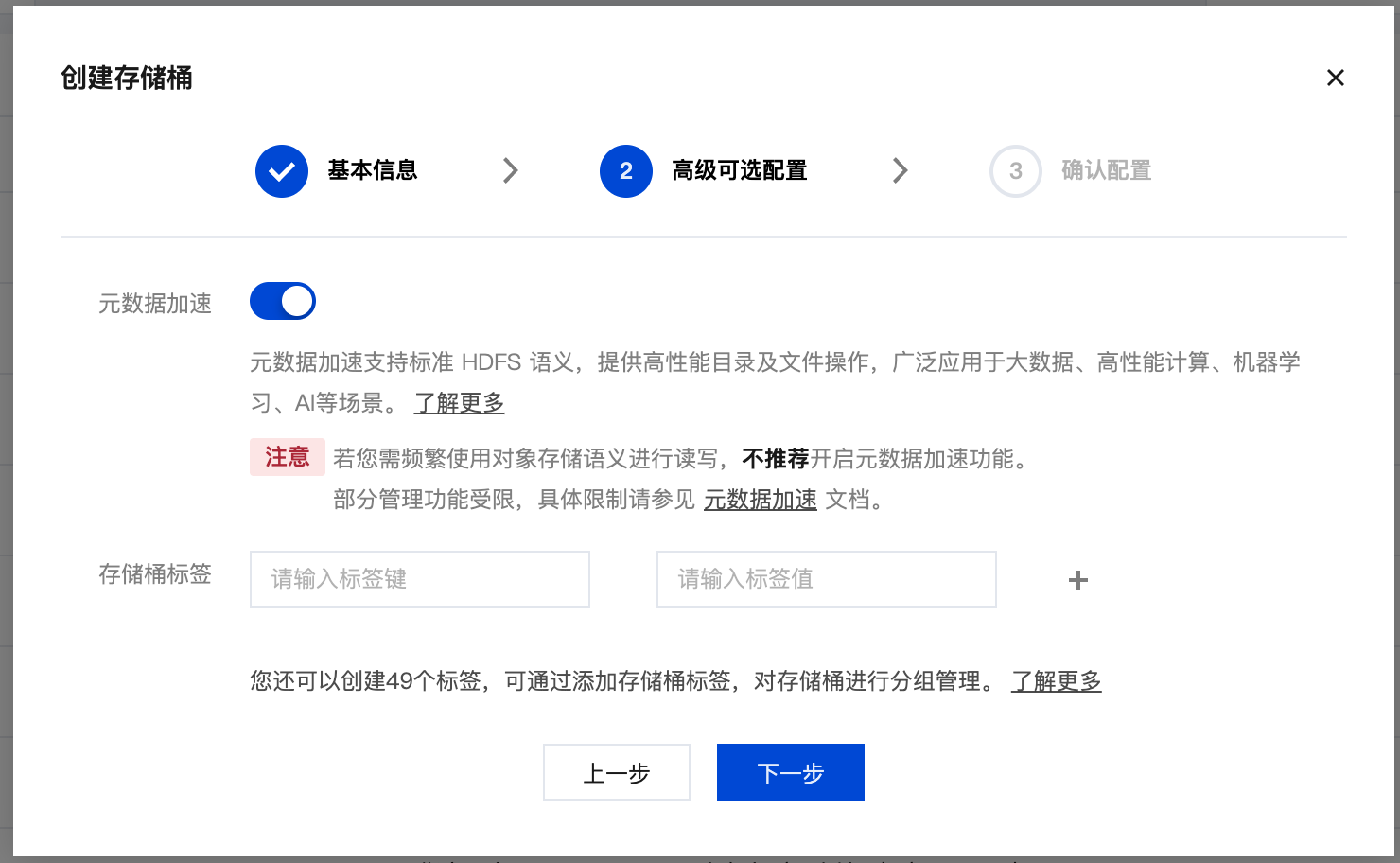
2. 在 元数据加速能力 标签配置 HDFS 元数据权限,增加对应 VPC 权限
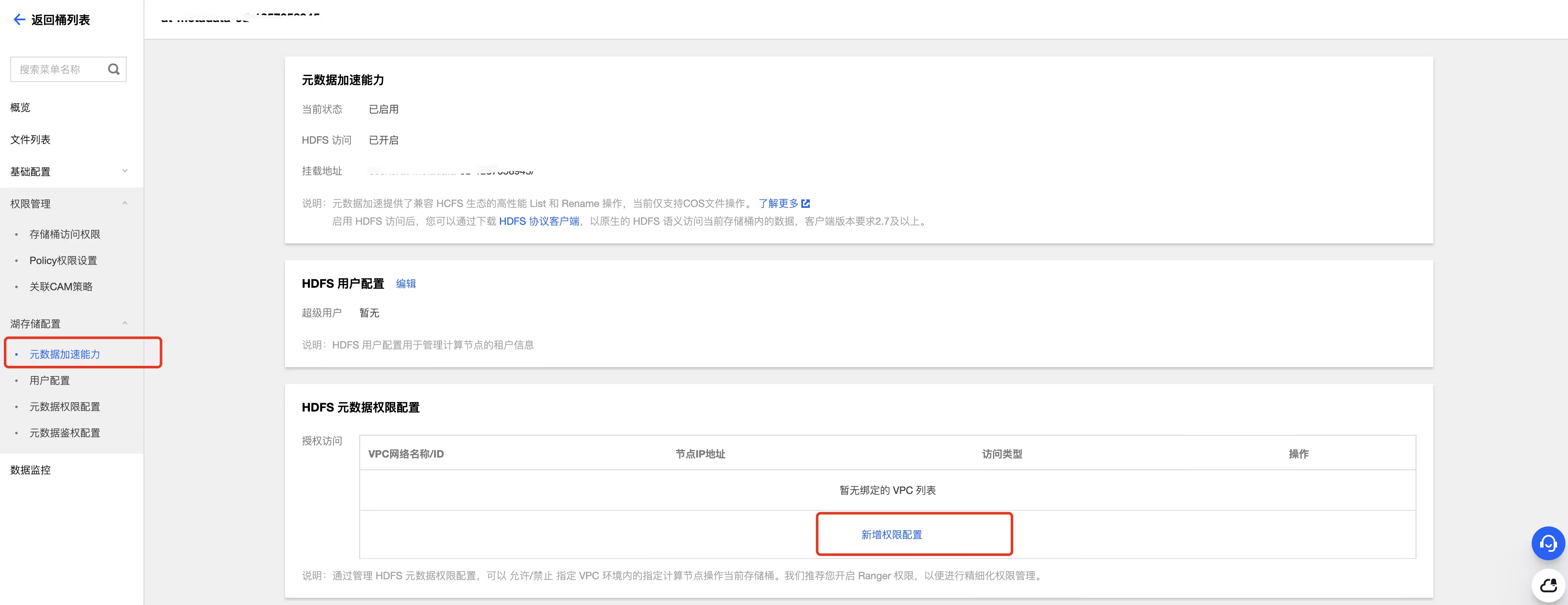
3. 在作业高级参数中增加如下高级参数:
containerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoop
HDFS 配置
获取 HDFS 连接:配置 jar
使用 HDFS 存储时需要使用包含 HDFS 配置信息的 jar 包来连接到 HDFS 集群。具体获取连接配置 jar 及其使用的步骤如下:
1. ssh 登录到对应 HDFS 集群节点。
2. 获取 hdfs-site.xml,EMR 集群中的配置文件在如下位置。
/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml
3. 对获取到的配置文件 打 jar 包。
jar -cvf hdfs-xxx.jar hdfs-site.xml
4. 校验 jar 的结构(可以通过 vi 命令查看 ),jar 里面包含如下信息,请确保文件不缺失且结构正确。
vi hdfs-xxx.jar
META-INF/META-INF/MANIFEST.MFhdfs-site.xml
在任务中使用配置 jar
引用程序包中选择 HDFS 连接配置 jar 包(该 jar 包为在 获取 HDFS 连接配置 jar 包 中得到的 hdfs-xxx.jar,必须在依赖管理上传后才使用)。
配置写入 HDFS 的用户
说明:
containerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoop
Hive 配置
获取 Hive 连接配置 jar
使用 Hive Metastore 时需要使用包含 Hive 及 HDFS 配置信息的 jar 包来连接到 Hive 集群。具体获取连接配置 jar 及其使用的步骤如下:
1. ssh 登录到对应 Hive 集群节点。
2. 获取 hive-site.xml 和 hdfs-site.xml,EMR 集群中的配置文件在如下位置。
/usr/local/service/hive/conf/hive-site.xml/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml
3. 修改 hive-site.xml 文件。
在hive-site增加如下配置,ip的值取配置文件里 hive.server2.thrift.bind.host 的 value<property><name>hive.metastore.uris</name><value>thrift://ip:7004</value></property>
4. 获取 hivemetastore-site.xml 和 hiveserver2-site.xml,点击文件名下载。
5. 对获取到的配置文件 打 jar 包。
jar -cvf hive-xxx.jar hive-site.xml hdfs-site.xml hivemetastore-site.xml hiveserver2-site.xml
6. 校验 jar 的结构(可以通过 vi 命令查看
vi hive-xxx.jar),jar 里面包含如下信息,请确保文件不缺失且结构正确。META-INF/META-INF/MANIFEST.MFhive-site.xmlhdfs-site.xmlhivemetastore-site.xmlhiveserver2-site.xml
在任务中使用配置 jar
引用程序包中选择 Hive 连接配置 jar 包(该 jar 包为在 获取 Hive 连接配置 jar 包 中得到的 hive-xxx.jar,必须在依赖管理上传后才使用)。
Kerberos 认证授权
1. 登录集群 Master 节点,获取 krb5.conf、emr.keytab、core-site.xml、hdfs-site.xml、hive-site.xml 文件,路径如下:
/etc/krb5.conf/var/krb5kdc/emr.keytab/usr/local/service/hadoop/etc/hadoop/core-site.xml/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml/usr/local/service/hive/conf/hive-site.xml
2. 修改 hive-site.xml 文件。在 hive-site.xml 中增加如下配置,IP 的值取配置文件中
hive.server2.thrift.bind.host 的 value。<property><name>hive.metastore.uris</name><value>thrift://ip:7004</value></property>
3. 获取 hivemetastore-site.xml 和 hiveserver2-site.xml,点击文件名下载。
4. 对获取的配置文件打 jar 包。
jar cvf hive-xxx.jar krb5.conf emr.keytab core-site.xml hdfs-site.xml hive-site.xml hivemetastore-site.xml hiveserver2-site.xml
5. 校验 jar 的结构(可以通过 vim 命令查看 vim hdfs-xxx.jar),jar 里面包含如下信息,请确保文件不缺失且结构正确。
META-INF/META-INF/MANIFEST.MFemr.keytabkrb5.confhdfs-site.xmlcore-site.xmlhive-site.xmlhivemetastore-site.xmlhiveserver2-site.xml
6. 在 程序包管理 页面上传 jar 包,并在作业参数配置里引用该程序包。
7. 获取 kerberos principal,用于 作业高级参数 配置。
klist -kt /var/krb5kdc/emr.keytab# 输出如下所示,选取第一个即可:hadoop/172.28.28.51@EMR-OQPO48B9KVNO Timestamp Principal---- ------------------- ------------------------------------------------------2 08/09/2021 15:34:40 hadoop/172.28.28.51@EMR-OQPO48B92 08/09/2021 15:34:40 HTTP/172.28.28.51@EMR-OQPO48B92 08/09/2021 15:34:40 hadoop/VM-28-51-centos@EMR-OQPO48B92 08/09/2021 15:34:40 HTTP/VM-28-51-centos@EMR-OQPO48B9
8. 作业高级参数 配置。
containerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoopsecurity.kerberos.login.principal: hadoop/172.28.28.51@EMR-OQPO48B9security.kerberos.login.keytab: emr.keytabsecurity.kerberos.login.conf: krb5.conf
说明:
security.kerberos.login.keytab 和 security.kerberos.login.conf 的值为对应的文件名。