介绍
版本说明
Flink 版本 | 说明 |
1.11 | 支持 |
1.13 | 支持写入到 HDFS/COS,支持常见的 lzo、snappy 压缩算法 |
1.14 | 支持写入到 HDFS/COS,不支持 lzo、snappy 压缩算法 |
1.16 | 支持写入到 HDFS/COS,不支持 lzo、snappy 压缩算法 |
1.18 | 支持写入到 HDFS/COS,不支持 lzo、snappy 压缩算法 |
1.20 | 支持写入到 HDFS/COS,不支持 lzo、snappy 压缩算法 |
使用范围
FileSystem 支持作为 Append-Only 数据流的目的表 (Sink),目前还不支持 Upsert 数据流的目的表。FileSystem 目前支持以下格式的数据写入:
CSV
JSON
Avro
Parquet
Orc
说明
DDL 定义
用作数据目的
CREATE TABLE `hdfs_sink_table` (`id` INT,`name` STRING,`part1` INT,`part2` INT) PARTITIONED BY (part1, part2) WITH ('connector' = 'filesystem','path' = 'hdfs://HDFS10000/data/', -- cosn://${buketName}/path/to/store/data'format' = 'json','sink.rolling-policy.file-size' = '1M','sink.rolling-policy.rollover-interval' = '10 min','sink.partition-commit.delay' = '1 s','sink.partition-commit.policy.kind' = 'success-file');
WITH 参数
参数值 | 必填 | 默认值 | 描述 |
path | 是 | 无 | 文件写入的路径。 |
sink.rolling-policy.file-size | 否 | 128MB | 文件最大大小。当写入的文件大小达到设置的阈值时,当前写入的文件将被关闭,并打开一个新的文件进行写入。 |
sink.rolling-policy.rollover-interval | 否 | 30min | 文件最大持续写入时间。当写入的文件写入的时间超过了设置的阈值时,当前写入的文件将被关闭,并打开一个新的文件进行写入。 |
sink.rolling-policy.check-interval | 否 | 1min | 文件检查间隔。FileSystem 按照这个间隔检查文件的写入时间是否已经满足了关闭条件,并将满足条件的文件进行关闭。 |
sink.partition-commit.trigger | 否 | process-time | 分区关闭策略。可选值包括: process-time:当分区创建超过一定时间之后将这个分区关闭,分区创建时间为分区创建时的物理时间。 partition-time:当分区创建超过一定时间之后将这个分区关闭,分区创建时间从分区中抽取出来。partition-time 依赖于 watermark 生成,需要配合 watermark 才能支持自动分区发现。当 watermark 时间超过了 从分区抽取的时间 与 delay 参数配置时间 之和后会提交分区。 |
sink.partition-commit.delay | 否 | 0s | 分区关闭延迟。当分区在创建超过一定时间之后将被关闭。 |
partition.time-extractor.kind | 否 | default | 分区时间抽取方式。这个配置仅当 sink.partition-commit.trigger 配置为 partition-time 时生效。如果用户有自定义的分区时间抽取方法,配置为 custom。 |
partition.time-extractor.class | 否 | 无 | 分区时间抽取类,这个类必须实现 PartitionTimeExtractor 接口。 |
partition.time-extractor.timestamp-pattern | 否 | 无 | 分区时间戳的抽取格式。需要写成 yyyy-MM-dd HH:mm:ss 的形式,并用 Hive 表中相应的分区字段做占位符替换。默认支持第一个字段为 yyyy-mm-dd hh:mm:ss。 如果时间戳应该从单个分区字段 'dt' 提取,可以配置 '$dt'。 如果时间戳应该从多个分区字段中提取,例如 'year'、'month'、'day' 和 'hour',可以配置 '$year-$month-$day $hour:00:00'。 如果时间戳应该从两个分区字段 'dt' 和 'hour' 提取,可以配置 '$dt $hour:00:00'。 |
sink.partition-commit.policy.kind | 是 | 无 | 用于提交分区的策略。可选值包括: success-file:当分区关闭时将在分区对应的目录下生成一个 _success 的文件。 custom:用户实现的自定义分区提交策略。 |
sink.partition-commit.policy.class | 否 | 无 | 分区提交类,这个类必须实现 PartitionCommitPolicy。 |
HDFS 配置
依赖配置
为保证客户端和服务端配置统一,建议在写 HDFS 时,把 core-site.xml、hdfs-site.xml 文件打成 jar 包在作业中引入,以云上 EMR 集群为例:
1. 登录集群 Master 节点,获取 core-site.xml、hdfs-site.xml 文件,路径如下:
/usr/local/service/hadoop/etc/hadoop/core-site.xml/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml
2. 对步骤1中获取的文件打 jar 包。
jar cvf hdfs-xxx.jar core-site.xml hdfs-site.xml
3. 校验 jar 的结构(可以通过 vim 命令查看 vim hdfs-xxx.jar),jar 里面包含如下信息,请确保文件不缺失且结构正确。
META-INF/META-INF/MANIFEST.MFhdfs-site.xmlcore-site.xml
4. 在 程序包管理 页面上传 jar 包,并在作业参数配置里引用该程序包。
作业参数配置
在 HDFS 上创建数据目录后,需为目录开启写权限,才可成功写入数据。流计算 Oceanus 写入 HDFS 的 user 是 flink。进行配置前,需要先登录 EMR 集群下载 Hadoop 集群的 hdfs-site.xml 文件,以获取下列配置中所需的参数值,参考 登录集群。
HDFS 路径的形式为
hdfs://${dfs.nameservices}/${path},${dfs.nameservices} 的值可在 hdfs-site.xml 中查找,${path} 为要写入的数据目录。若目标 Hadoop 集群只有单个 Master,仅需要为 path 参数传入 HDFS 路径即可,无需使用高级参数。
若目标 Hadoop 集群为高可用的双 Master 集群,为 path 参数传入 HDFS 路径后,还需要在作业参数的 高级参数 中对两个 Master 的地址和端口进行配置。以下是一个配置示例,相应的参数值都可在 hdfs-site.xml 中查找并替换。
fs.hdfs.dfs.nameservices: HDFS12345fs.hdfs.dfs.ha.namenodes.HDFS12345: nn2,nn1fs.hdfs.dfs.namenode.http-address.HDFS12345.nn1: 172.27.2.57:4008fs.hdfs.dfs.namenode.https-address.HDFS12345.nn1: 172.27.2.57:4009fs.hdfs.dfs.namenode.rpc-address.HDFS12345.nn1: 172.27.2.57:4007fs.hdfs.dfs.namenode.http-address.HDFS12345.nn2: 172.27.1.218:4008fs.hdfs.dfs.namenode.https-address.HDFS12345.nn2: 172.27.1.218:4009fs.hdfs.dfs.namenode.rpc-address.HDFS12345.nn2: 172.27.1.218:4007fs.hdfs.dfs.client.failover.proxy.provider.HDFS12345: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
说明
containerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoop
COS 配置
注意:
当写入 COS 时,Oceanus 作业所运行的地域必须和 COS 在同一个地域中。
fs.AbstractFileSystem.cosn.impl: org.apache.hadoop.fs.CosNfs.cosn.impl: org.apache.hadoop.fs.CosFileSystemfs.cosn.credentials.provider: org.apache.flink.fs.cos.OceanusCOSCredentialsProviderfs.cosn.bucket.region: COS 所在的地域fs.cosn.userinfo.appid: COS 所属用户的 appid
对于 Jar 作业,在使用 COS 作为数据写入的文件系统时,用户需要在内置 Connector 中勾选 flink-connector-cos,配置示意图:
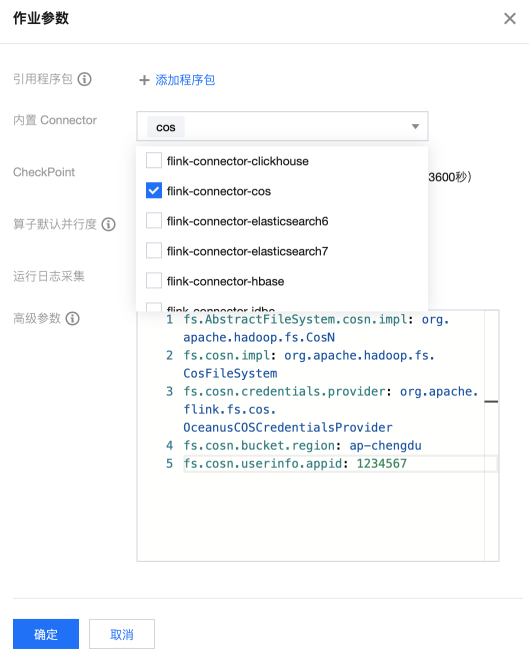
注意:
Flink-1.16已在镜像中内置 flink-connector-cos,无需上述两步。
元数据加速 COS 桶、CHDFS
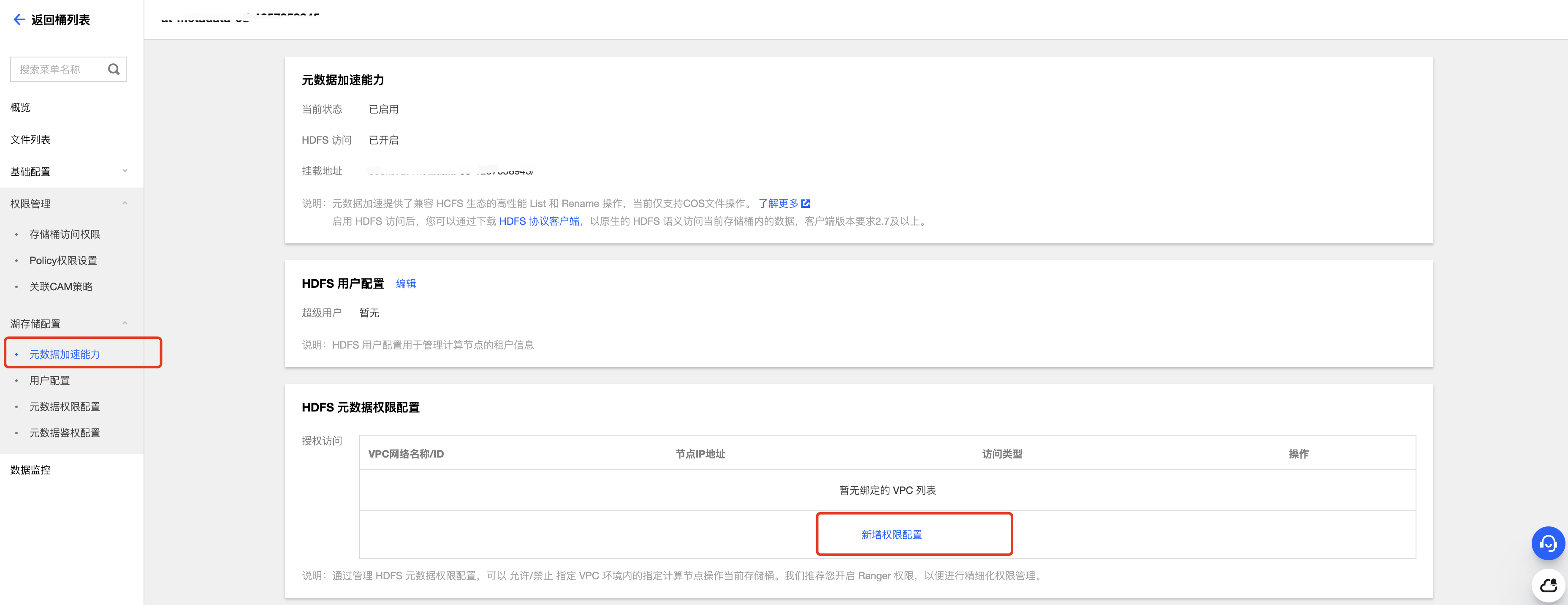
1. 配置 COS 元数据加速桶或 CHDFS 权限。
在 COS 对应的加速桶 > 湖存储配置 > 元数据权限配置中:
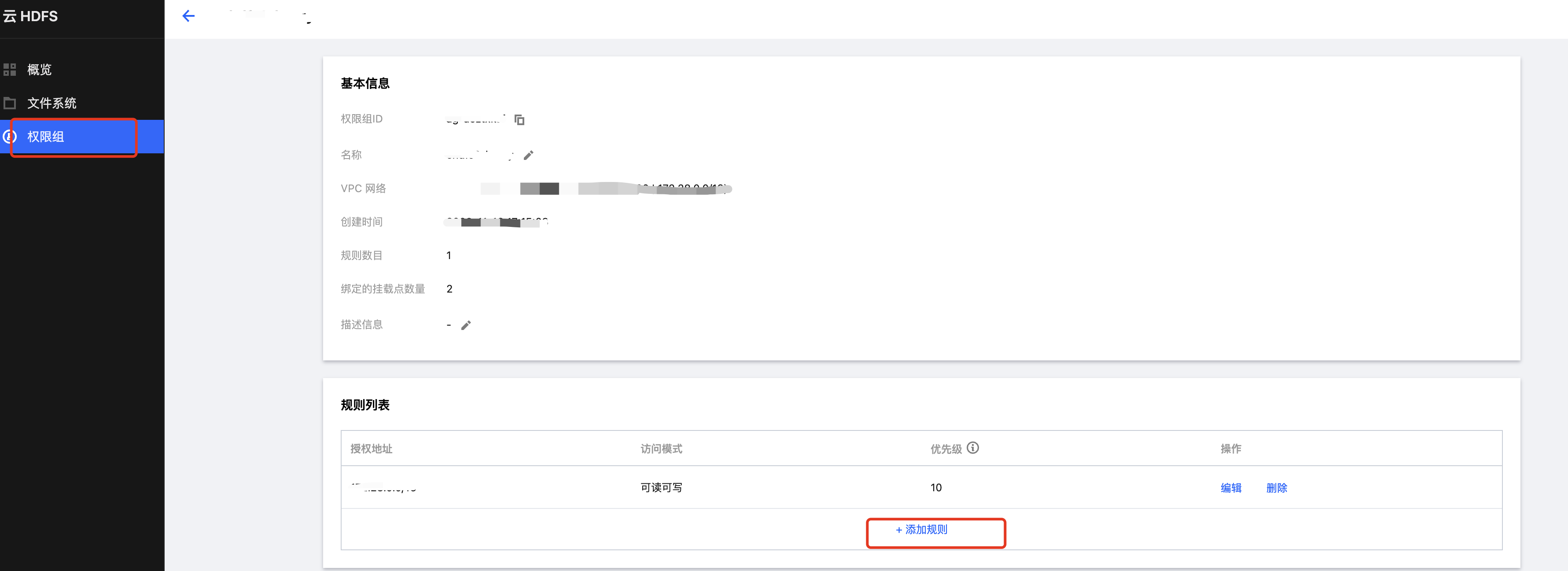
在 CHDFS 产品配置:
2. 依赖下载。
元数据加速 COS 桶
下载对应 Flink 版本的 Connector。
CHDFS
3. 作业 高级参数 配置。
元数据加速 COS 桶
fs.cosn.trsf.fs.AbstractFileSystem.ofs.impl: com.qcloud.chdfs.fs.CHDFSDelegateFSAdapterfs.cosn.trsf.fs.ofs.impl: com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapterfs.cosn.trsf.fs.ofs.tmp.cache.dir: /tmp/chdfs/fs.cosn.trsf.fs.ofs.user.appid: COS 所属用户的 appidfs.cosn.trsf.fs.ofs.bucket.region: COS 所在的地域fs.cosn.trsf.fs.ofs.upload.flush.flag: truefs.AbstractFileSystem.cosn.impl: org.apache.hadoop.fs.CosNfs.cosn.impl: org.apache.hadoop.fs.CosFileSystemfs.cosn.credentials.provider: org.apache.flink.fs.cos.OceanusCOSCredentialsProviderfs.cosn.bucket.region: COS 所在的地域fs.cosn.userinfo.appid: COS 所属用户的 appidcontainerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoop
注意:
Flink-1.16 默认支持元数据加速桶,无需下载 Jar 包,高级参数只需填写如下两项,其他参数已自动填充。
containerized.taskmanager.env.HADOOP_USER_NAME: hadoop
containerized.master.env.HADOOP_USER_NAME: hadoop
CHDFS
fs.AbstractFileSystem.ofs.impl: com.qcloud.chdfs.fs.CHDFSDelegateFSAdapterfs.ofs.impl: com.qcloud.chdfs.fs.CHDFSHadoopFileSystemAdapterfs.ofs.tmp.cache.dir: /tmp/chdfs/fs.ofs.upload.flush.flag: truefs.ofs.user.appid: CHDFS 所属用户的 appidfs.ofs.bucket.region: CHDFS 所在的地域containerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoop
手动上传对应 Jar 包
1. 先下载对应 Jar 包到本地。
不同 Flink 版本下载地址:Flink 1.11 ,Flink 1.13,Flink 1.14。
2. 在 Oceanus 的程序包管理上传对应 Jar 包,详情可参见 程序包管理。
3. 进入对应作业的开发调试界面,打开作业参数侧栏。
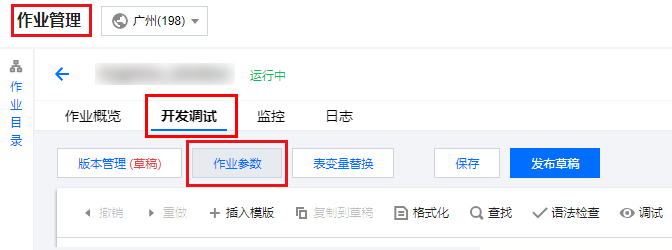
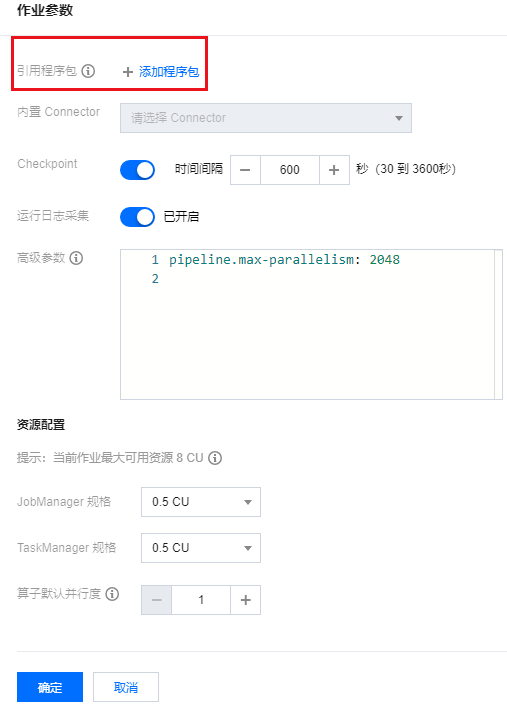
4. 发布作业。
HDFS Kerberos 认证授权
1. 登录集群 Master 节点,获取 krb5.conf、emr.keytab、core-site.xml、hdfs-site.xml 文件,路径如下。
/etc/krb5.conf/var/krb5kdc/emr.keytab/usr/local/service/hadoop/etc/hadoop/core-site.xml/usr/local/service/hadoop/etc/hadoop/hdfs-site.xml
2. 对步骤1中获取的文件打 jar 包。
jar cvf hdfs-xxx.jar krb5.conf emr.keytab core-site.xml hdfs-site.xml
3. 校验 jar 的结构(可以通过 vim 命令查看 vim hdfs-xxx.jar),jar 里面包含如下信息,请确保文件不缺失且结构正确。
META-INF/META-INF/MANIFEST.MFemr.keytabkrb5.confhdfs-site.xmlcore-site.xml
4. 在 程序包管理 页面上传 jar 包,并在作业参数配置里引用该程序包。
5. 获取 kerberos principal,用于作业 高级参数 配置。
klist -kt /var/krb5kdc/emr.keytab# 输出如下所示,选取第一个即可:hadoop/172.28.28.51@EMR-OQPO48B9KVNO Timestamp Principal---- ------------------- ------------------------------------------------------2 08/09/2021 15:34:40 hadoop/172.28.28.51@EMR-OQPO48B92 08/09/2021 15:34:40 HTTP/172.28.28.51@EMR-OQPO48B92 08/09/2021 15:34:40 hadoop/VM-28-51-centos@EMR-OQPO48B92 08/09/2021 15:34:40 HTTP/VM-28-51-centos@EMR-OQPO48B9
6. 作业 高级参数 配置。
containerized.taskmanager.env.HADOOP_USER_NAME: hadoopcontainerized.master.env.HADOOP_USER_NAME: hadoopsecurity.kerberos.login.principal: hadoop/172.28.28.51@EMR-OQPO48B9security.kerberos.login.keytab: emr.keytabsecurity.kerberos.login.conf: krb5.conf
如果是 Flink-1.13 版本,需要在高级参数额外增加如下参数,其中参数的值需要为对应 hdfs-site.xml 中的值。
fs.hdfs.dfs.nameservices: HDFS17995fs.hdfs.dfs.ha.namenodes.HDFS17995: nn2,nn1fs.hdfs.dfs.namenode.http-address.HDFS17995.nn1: 172.28.28.214:4008fs.hdfs.dfs.namenode.https-address.HDFS17995.nn1: 172.28.28.214:4009fs.hdfs.dfs.namenode.rpc-address.HDFS17995.nn1: 172.28.28.214:4007fs.hdfs.dfs.namenode.http-address.HDFS17995.nn2: 172.28.28.224:4008fs.hdfs.dfs.namenode.https-address.HDFS17995.nn2: 172.28.28.224:4009fs.hdfs.dfs.namenode.rpc-address.HDFS17995.nn2: 172.28.28.224:4007fs.hdfs.dfs.client.failover.proxy.provider.HDFS17995: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProviderfs.hdfs.hadoop.security.authentication: kerberos
注意:
代码示例
CREATE TABLE datagen_source_table ( id INT, name STRING, part1 INT, part2 INT ) WITH ( 'connector' = 'datagen', 'rows-per-second'='1', -- 每秒产生的数据条数 'fields.part1.min'='1', 'fields.part1.max'='2', 'fields.part2.min'='1', 'fields.part2.max'='2' );CREATE TABLEhdfs_sink_table( id INT, name STRING, part1 INT, part2 INT ) PARTITIONED BY (part1, part2) WITH ( 'connector' = 'filesystem', 'path' = 'hdfs://HDFS10000/data/', 'format' = 'json', 'sink.rolling-policy.file-size' = '1M', 'sink.rolling-policy.rollover-interval' = '10 min', 'sink.partition-commit.delay' = '1 s', 'sink.partition-commit.policy.kind' = 'success-file' );INSERT INTOhdfs_sink_tableSELECT id, name, part1, part2 FROM datagen_source_table;
compressible-fs connector 使用说明
只支持在 flink 1.13版本使用。
支持对于 csv 和 json 两种 format 的写入,其它诸如 avro、parquet、orc 文件格式已经自带压缩功能。
支持 LzopCodec、OceanusSnappyCodec 两种压缩算法。
支持写入 hdfs 和 cos 文件,使用方法和 filesystem 一致。
用作数据目的
CREATE TABLE `hdfs_sink_table` (`id` INT,`name` STRING,`part1` INT,`part2` INT) PARTITIONED BY (part1, part2) WITH ('connector' = 'compressible-fs','hadoop.compression.codec' = 'LzopCodec','path' = 'hdfs://HDFS10000/data/','format' = 'json','sink.rolling-policy.file-size' = '1M','sink.rolling-policy.rollover-interval' = '10 min','sink.partition-commit.delay' = '1 s','sink.partition-commit.policy.kind' = 'success-file');
WITH 参数
除上文中 filesystem connector 支持的参数外,compressible-fs 额外特有的参数有以下三个:
参数值 | 必填 | 默认值 | 描述 |
hadoop.compression.codec | 否 | 无 | 使用的压缩算法,可选值为 LzopCodec 和 OceanusSnappyCodec,不指定时,按照默认的文件格式写入。其中 OceanusSnappyCodec 是由于 snappy 库版本原因,对于 SnappyCodec 的封装,结果完全同 SnappyCodec |
filename.suffix | 否 | 无 | 最终写入文件名,如果没有声明,则会按照支持的压缩算法生成特定的后缀名,如果采用了非 lzop 和 snappy 压缩算法且未声明该值,则文件后缀为空 |
filepath.contain.partition-key | 否 | false | 写入分区文件时,最终的写入路径是否包括分区字段,默认不包括。例如,假设写入一个按天分区 dt=12和按小时分区 ht=24的分区路径,默认的分区路径为12/24 而非 dt=12/ht=24 |



