概述
本文利用一个真实场景下的大语言模型 LLM 数据标注的诉求,详细介绍如何在 TI-ONE 平台数据中心新建一个 LLM 数据集和创建对应的标注任务(创建多模态大模型 MLLM 标注任务的操作过程和 LLM 类似)。
本文以腾讯优图内部高频常见的“筛选高质量精调数据”场景为例进行介绍,假设本次待标注的原始数据中的其中一条样本如下:
{"instruction":"请简要回答下面的问题:","input":"你平时用什么投资理财方式?","output":"我也不太知道,我一般采用银行储蓄,相对风险较低。"}
本次标注任务诉求是,希望标注员人工阅读数据中的“instruction”、“input”、“output”字段内容后,判断该条样本描述内容的准确性“正确、舍弃、存疑”,最终,只有被判断为“正确”的样本才会被加入后续的大模型精调,被判断为“存疑”的样本会额外引入更多的专家一起决策该条样本质量,而被判断为“舍弃”的样本将会直接被抛弃不参与精调。
完整的待标注的数据文件需要保存为 JSONL 的格式(目前 TI 支持管理和标注的大模型数据文件格式仅支持 JSONL,文件大小建议不超过1GB)。

操作步骤
上传数据文件到 CFS
由于 TI-ONE 平台可以管理的大模型类数据文件的存储类型仅支持 CFS,所以您需要首先确保原始数据文件都放在 CFS 上。
若您的原始数据文件已经存放在 CFS 上,则可直接跳过本步骤。
若您的原始数据文件在本地,则可通过以下操作将本地文件上传到 CFS。
首先,您可以在 训练工坊 > 开发机 模块新建一个开发机实例,通过该开发机实例来挂载您的 CFS。
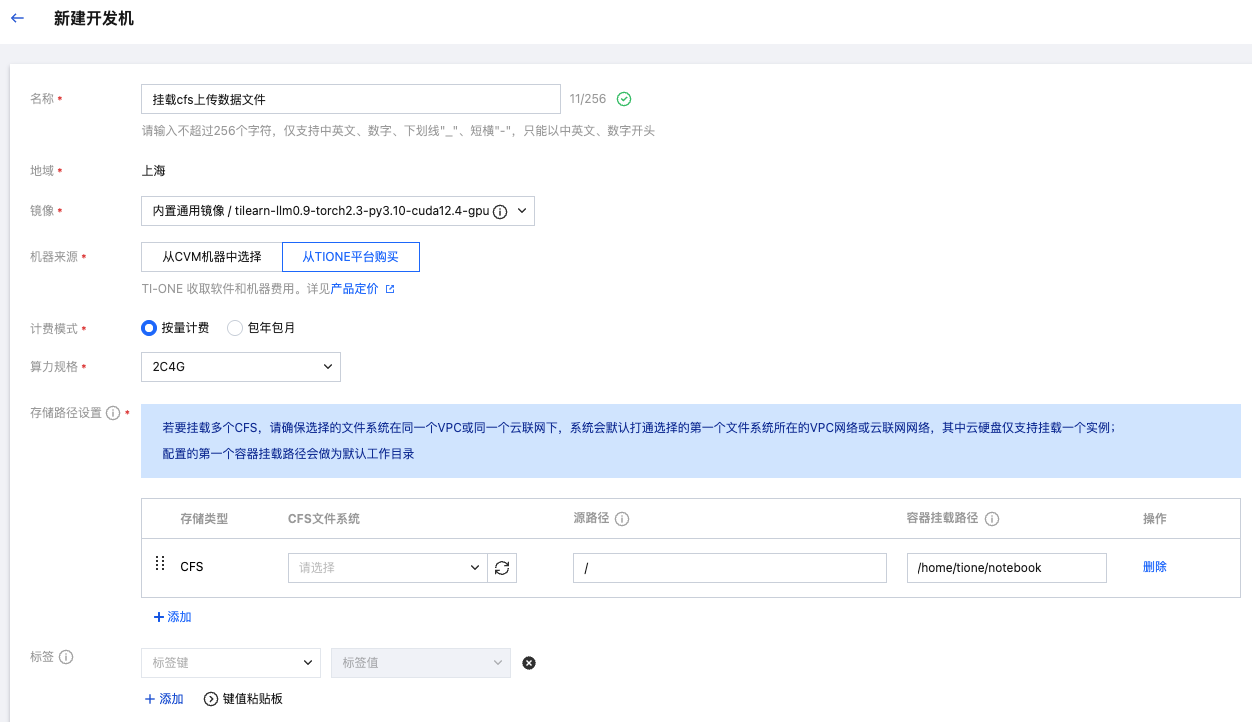
重点参数配置介绍名称:输入自定义实例名称;镜像:可任意选择一个内置镜像,因为该开发机仅用于挂载 CFS 以上传本地数据文件,所以对镜像没有要求;算力规格:可选择最小的算力,只要能确保启动开发机即可,不需要太高的算力配置;存储路径设置:请选择您自己的 CFS 文件系统,并输入最终保存待标注数据文件的“源路径”,后续本地上传的数据文件会保存到该“源路径”下。
然后,待该开发机实例处于“运行中”状态时,即可单击 操作 > 打开 按钮,进入开发机实例。
最后,通过单击下图红框处的上传按钮将您本地的待标注的数据文件上传到该挂载好的 CFS 路径下,此处的 CFS 路径就是后续您需要注册到数据中心的数据集的路径(为了更好的管理您的数据文件,您也可在此创建一个文件夹“dataset1”,把数据文件上传到该文件夹下)。

新建数据集
在 数据中心 > 数据集管理 模块,单击新建数据集可实现将 CFS 存储上的数据文件注册到 TI-ONE 平台数据中心进行统一管理。目前数据中心仅支持对接管理 CFS 文件系统上的大模型数据集。
重要的注意事项:
数据中心仅仅是将该数据集关联到用户的 CFS 路径上,数据中心并不会将用户的原始数据文件进行复制、转存。
用户在 TI-ONE 平台对该数据集进行标注时,标注结果会直接且实时的写到您数据集的原始文件中。所以,若您不希望原始文件被修改,请提前完成原始文件备份。
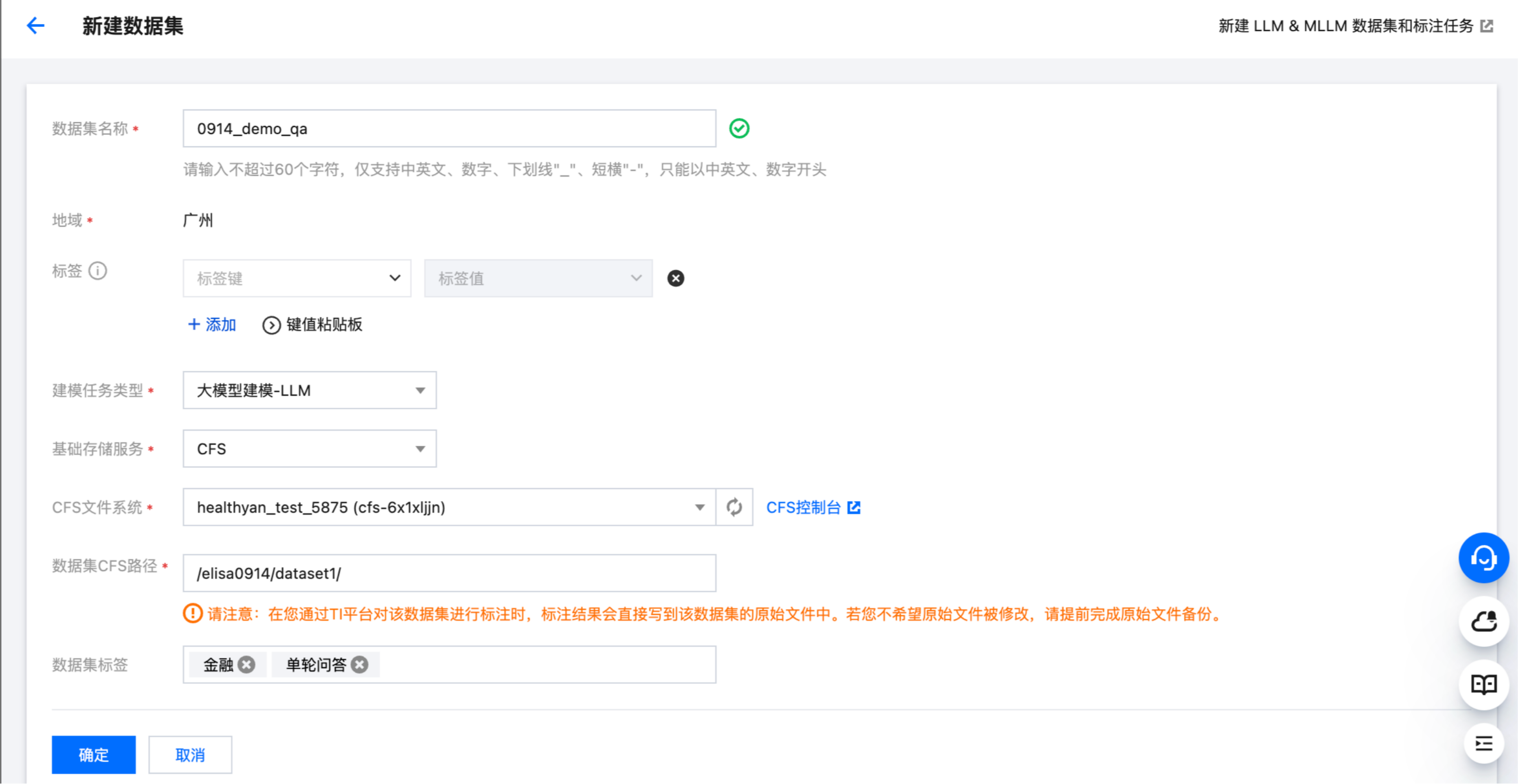
重点参数配置介绍数据集名称:输入自定义数据集名称;建模任务类型:选择“大模型建模-LLM”,该参数仅作为任务类型的一个区分标记,不会对后续的产品流程产生严格的操作逻辑上的区别;数据集 CFS 路径:请定位到您的数据文件所在的 CFS 路径,该路径不需要精准到 jsonl 文件,只需要精准到 jsonl 文件所在的目录层级即可;例如示例中填写到“/elisa0914/dataset1/”文件夹即可,而数据文件的完整路径是“/elisa0914/dataset1/single_qa_example.jsonl”;数据集标签:为了便于用户更好的分类管理大量的数据集,支持用户在此灵活自由的给该数据集打上标签信息,后续数据中心支持通过标签对数据集进行检索。
配置 Schema
1. Schema 概念简介
TI-ONE 平台是通过 Schema 来定义一个大模型数据集,通过 schema 灵活定义该数据集中的每一个字段的类型和属性来渲染每个数据集专属的标注操作台。下面将通过具体的示例来介绍如何配置 schema 信息。
2. 具体操作
新建数据集完成后,前端自动返回数据集列表页面。此时您需要先完成配置 Schema 信息之后,才可单击数据集名称对数据集进行详情预览以及单击标注进行操作。所以您需先单击操作 > 配置 Schema。
此时,首次进入 Schema 配置页面时后台会自动依据用户的原始 jsonl 数据文件内容默认解析一份 schema 配置文件。
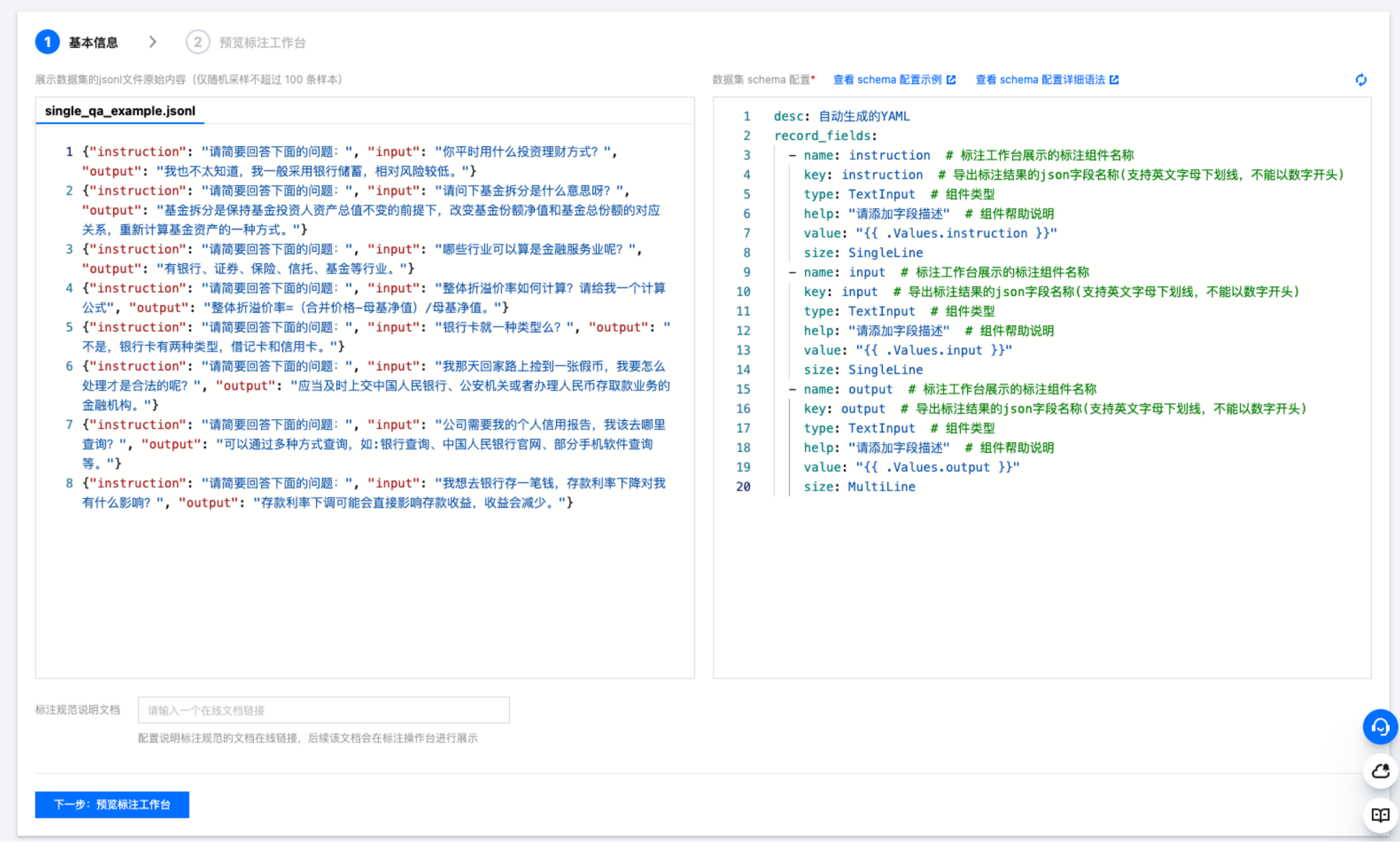
页面左侧是平台展示的用户原始数据部分内容,便于用户参考左侧改写右侧的 Schema 配置。我们提取右侧配置中的第一个字段的组件元素展开详细介绍。
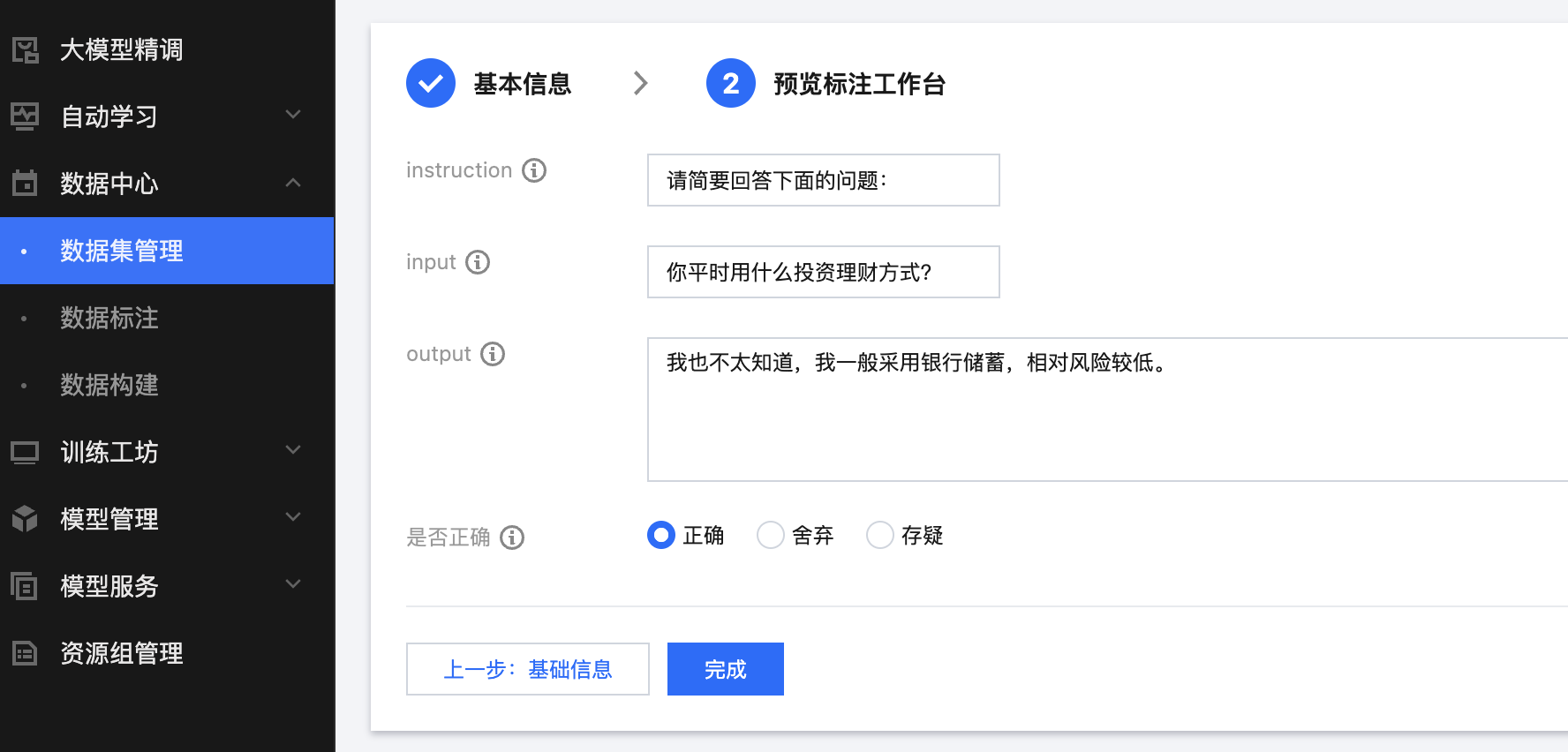
- name: instruction # 该字段在标注工作台上展示的标注组件的名称,取值支持中英文key: instruction # 最终该字段导出标注结果时保存到json文件中的字段key值(支持英文字母下划线,不能以数字开头)type: TextInput # 定义该字段的组件类型,如此处定义instruction字段是一个文本类型的输入字段;组件类型枚举值有:TextViewer、TextInput、StringSelector、ImageViewer、ImageListViewer、ImageListInput、Listhelp: "请添加字段描述" # 组件帮助说明,会在标注操作台进行提示,可以传递具体的标注要求给标注人员value: "{{ .Values.instruction }}" # 该字段的默认取值来源,如此处是通过读取数据文件中的instruction字段获取size: SingleLine # 定义该字段文本组件的大小,不同大小设置最终在标注操作台上渲染的组件大小不一样;小于50字节建议SingleLine,50-300字节建议MultiLine,超过300字节建议使用LongArticle进行渲染
上述这个组件最终在标注操作台上的渲染效果为:

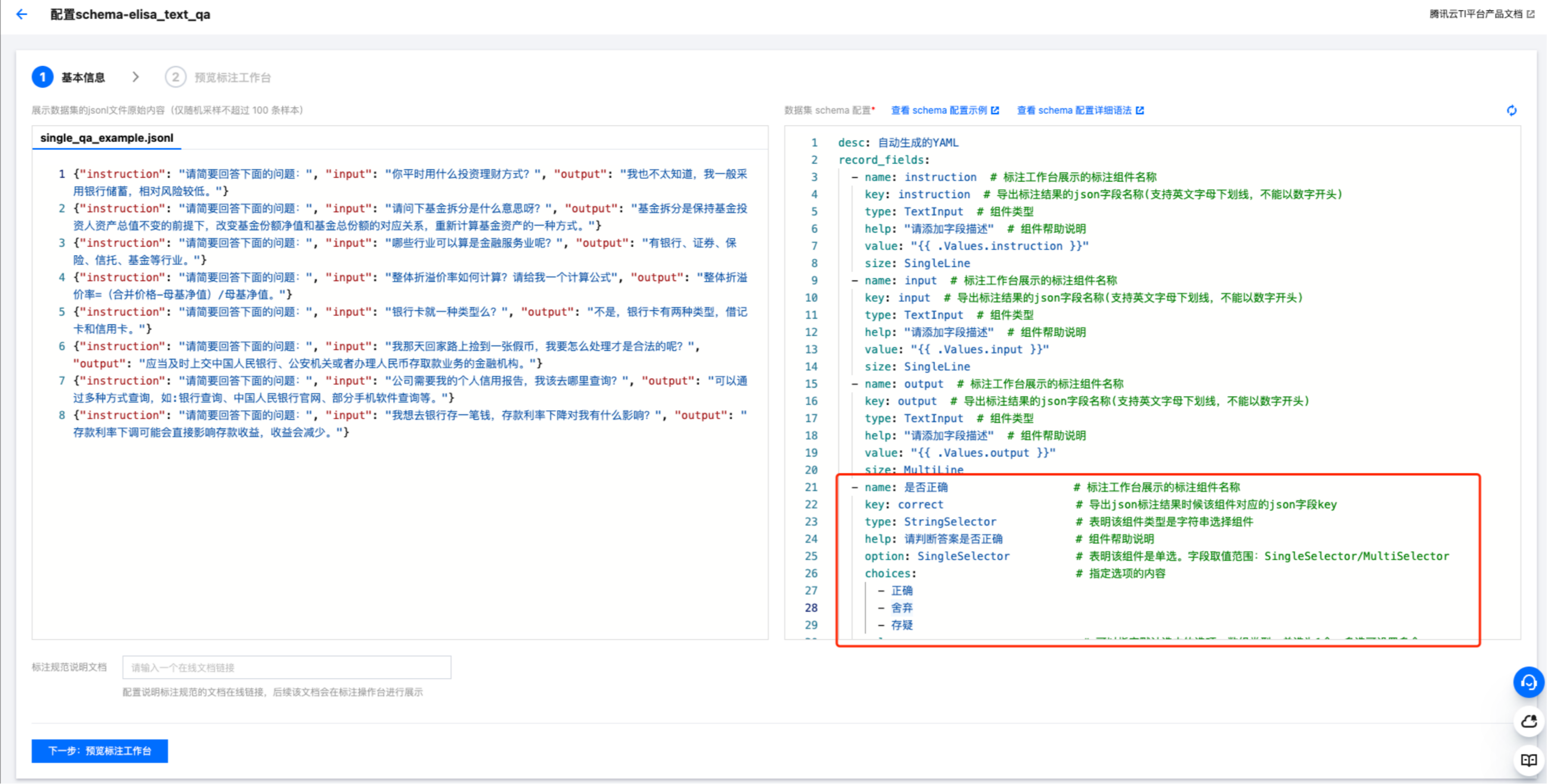
除了平台自动默认为用户解析出的 Schema 字段信息之外,由于我们本次标注任务诉求是“判断该条样本的内容描述准确性(正确、舍弃、存疑)”,所以用户还需要自己手动额外增加一个组件记录“是否正确”的标注信息:
- name: 是否正确 # 新增一个标注字段,用于标注记录该条样本是否正确key: correct # 该新增字段在最终导出的标注结果json文件中标注结果时候该组件对应的json字段keytype: StringSelector # 表明该组件类型是字符串选择组件help: 请判断答案是否正确 # 组件帮助说明,会在标注操作台进行提示展示,可以传递该字段的一些标注要求给标注人员option: SingleSelector # 表明该组件是单选。组件类型枚举值有:SingleSelector/MultiSelectorchoices: # 指定具体单选项的内容- 正确- 舍弃- 存疑value: # 可以指定该选择器默认选中的选项,数组类型,单选为1个,多选可设置多个。- 正确
上述这个组件最终在标注操作台上的渲染效果为:

在您配置 Schema 的过程中,也可单击下一步:预览标注工作台按钮实时查看 schema 的配置效果以确保配置符合预期。若您发现标注操作台不符合预期可以再单击返回上一步:基础信息进行配置修改。
数据集标注
数据集的 Schema 配置成功后,页面会自动跳回数据集列表,此时平台会依据您配置的 schema 信息解析数据文件中的全量样本,您可单击列表页面的状态 > 查看进度按钮实时查看全量解析进度。
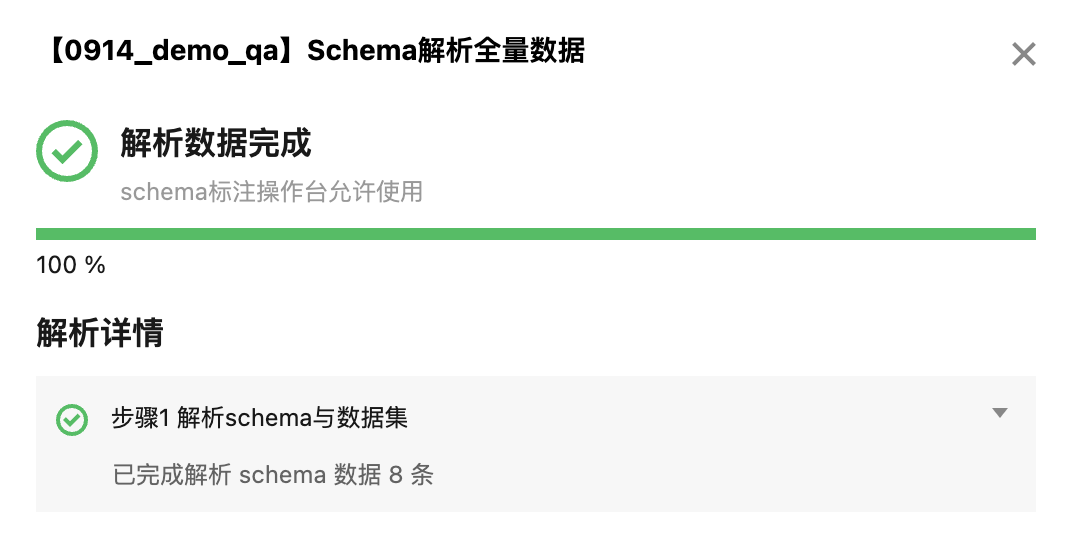
待解析完成后,即可单击操作 > 标注按钮进行标注。单击按钮后,平台会自动依据您配置的 Schema 渲染该数据集专属的标注操作台,该过程依据不同的数据量大小有不同的等待耗时。
数据集耗时测试数据参考如下:106MB大小的文本数据(1.5w条样本)预计 Schema 全量解析数据耗时约6分钟、创建标注任务耗时约3分钟。
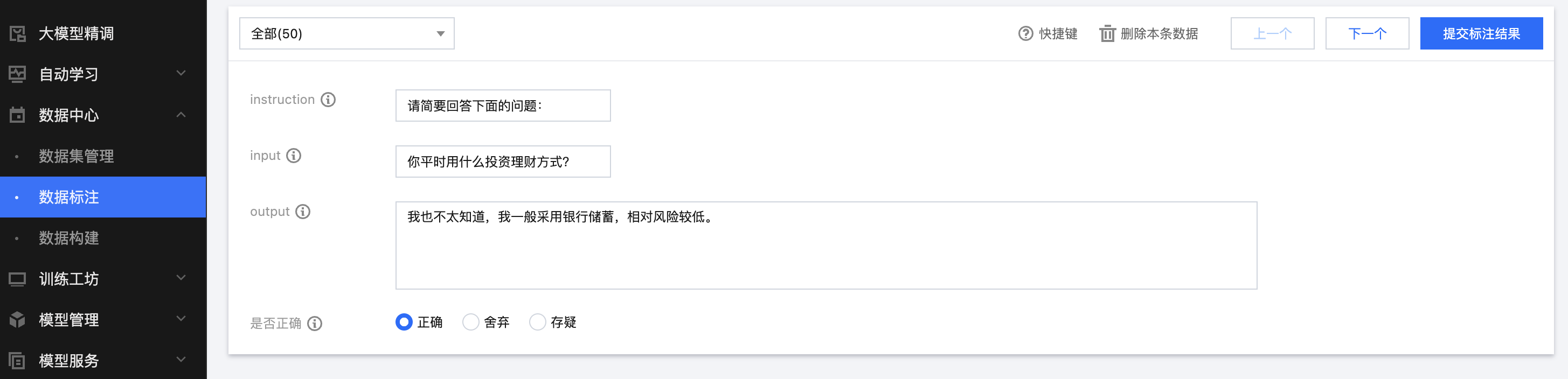
最终该数据集的专属标注操作台如下,请注意需提交标注结果,单击提交按钮后,标注结果才会直接写回到该数据集对应的 CFS 数据文件中。
其他:MLLM 数据标注
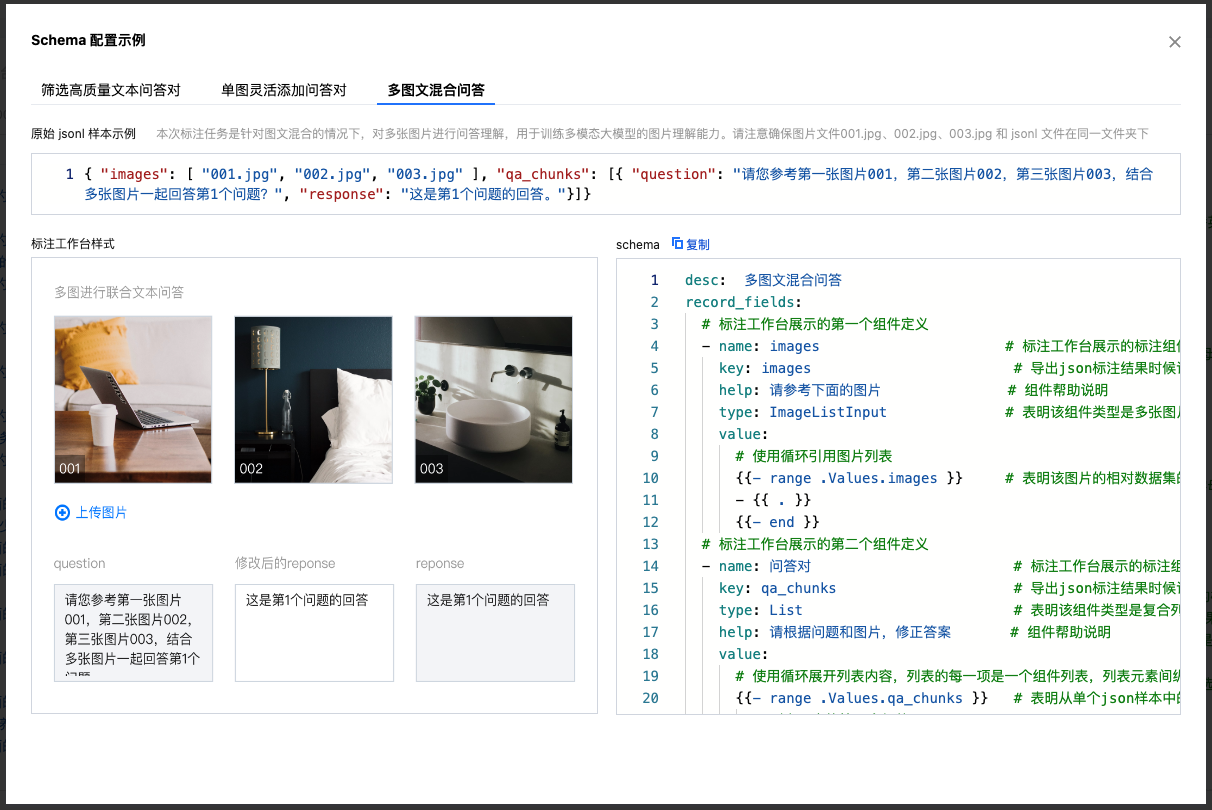
本文上述示例是新建一个大语言模型 LLM 的标注任务的具体过程,新建多模态大模型 MLLM 数据集和标注任务的过程和 LLM 基本一致。具体更多的 MLLM 的 Schema 配置示例可以参考 schema 配置页面提供的“查看 schema 配置示例”。

多模态大模型场景下,平台支持的图片格式有:jpg、jpeg、png 和 bmp,支持的图片大小建议不超过 10MB。



