总览
使用 MMLU 等开源数据集对大模型做基准测试,是较常使用的评价大模型的方法。大模型在发布时,往往也会公布在主流开源数据集上的基准测试结果以证实自身的效果。但该方法存在以下局限性:
1. 刷榜风险:因为开源数据集是公开的,模型可以在训练过程中「见过」这些数据,从而特意针对评测数据集优化,得到更高的分数。这种优化并不能代表模型在实际场景中的表现,仅仅是「刷榜」行为。
2. 缺乏实际场景的测试:开源数据集往往是经过挑选或有特定风格的,无法完全涵盖真实应用中的复杂性和多样性。实际场景中的数据往往更具噪音、更不确定,这些因素无法通过标准的开源数据集评估。
3. 数据集陈旧问题:一些开源数据集较为老旧,可能不适合评估最新大模型的效果。大模型在语料和能力方面的提升,使得传统数据集无法有效区分模型的好坏。
使用 TI-ONE 平台 的 主观评测 功能,您可以基于自己构造的、基于实际场景的定制问答数据集,评测及对比Hunyuan-Large和其他模型在该数据集上的表现,从而真实地评价 Hunyuan-Large 在您关心的领域中展现的能力及优势。
下文将逐步详细介绍如何使用 TI-ONE 平台基于您的定制问答数据集对比评测 Hunyuan-Large 和其他模型效果。
前置要求
文件存储
腾讯云大模型训推平台 TI-ONE
Hunyuan-Large 模型评测需要使用 GPU 机器,推荐机型为 HCCPNV6 机型,请纳管此机型到 TI-ONE 的资源组中。对 Hunyuan-large 模型做评测的最少资源为:HCCPNV6 机型 1 台。
实践教程
一、构造定制数据集
.csv 格式的数据集由两列构成,第一列名为 prompt ,第二列名为 answer。在第一列中,请给出想向大模型提出的问题;在第二列中,请给出您所设想的回答。您可参考示例数据集:test.csv。请使用 Sublime Text 等文本编辑器编辑并保存 .csv 数据集文件,务必不要使用 Excel,否则文件中会生成非标准的UTF-8 BOM 使 主观评测 功能无法读取数据集文件。
我们准备了下表中的数据以构造定制数据集:
prompt | answer |
什么是机器学习? | 机器学习是一种通过数据训练算法,使其在未来能够做出预测或决策的技术。 |
如何提高英语口语水平? | 提高英语口语的方法包括多听、多说、模仿母语者的表达方式,练习日常对话并接受反馈。 |
Spring Boot 有哪些主要特性? | Spring Boot 的主要特性包括简化配置、内嵌服务器支持、自动化配置和丰富的扩展性。 |
如何优化 SQL 查询性能? | 可以通过索引、避免全表扫描、优化 JOIN 操作、减少子查询等方式优化 SQL 查询性能。 |
什么是自然语言处理? | 自然语言处理(NLP)是研究如何通过计算机处理和理解人类语言的学科,涉及语音识别、文本分析等应用。 |
如何设计一个 RESTful API? | 设计 RESTful API 的步骤包括确定资源、使用 HTTP 方法(GET、POST 等)、保持 URI 简洁、使用状态码等。 |
如何提升编程逻辑思维能力? | 提升编程逻辑思维的方法包括多做算法题、多阅读优秀代码、锻炼分解问题的能力,尝试多种思维方式。 |
将上表中的数据在本地保存为 myDataset.csv 文件。
二、将定制数据集上传到 CFS 文件存储
下面将通过平台的 Notebook 功能将定制数据集上传到 CFS 文件存储。进入 TI-ONE 平台 控制台,单击左侧导航栏中的训练工坊 > Notebook,跳转到 Notebook 模块主页。在 Notebook 主页中单击新建按钮,进入下图所示的 新建 Notebook 页面:
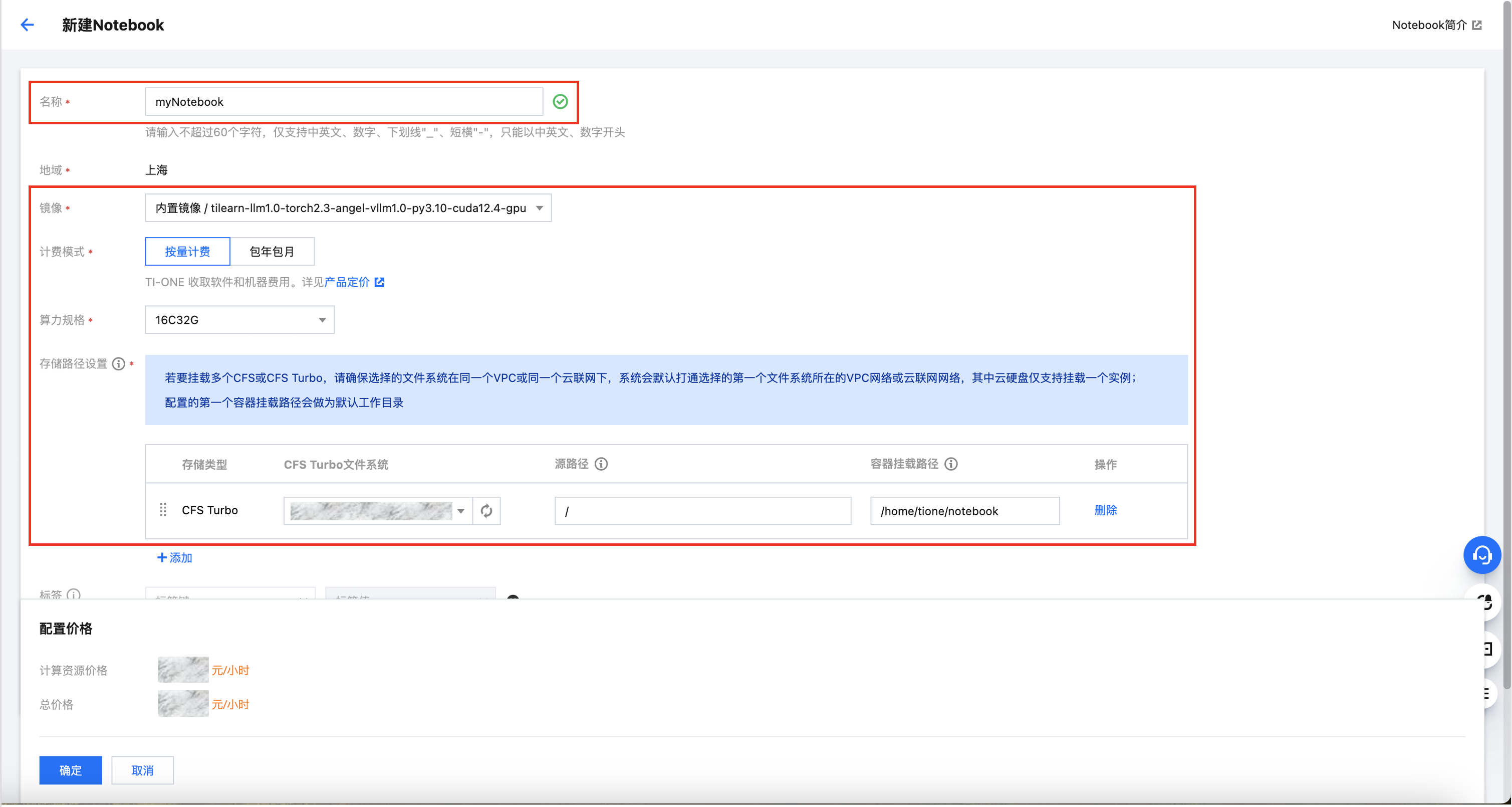
在新建 Notebook页面,需要填写以下上图所示的字段以完成创建:
1. 名称:请输入您指定的 Notebook 名称。本文中取值为 “myNotebook”。
2. 镜像:请选择“内置镜像-tilearn-llm1.0-torch2.3-angel-vllm1.0-py3.10-cuda12.4-gpu”。
3. 计费模式:请选择“按量计费”。
4. 算力规格:请选择“16C32G”。
5. 存储路径设置:先单击添加按钮,选择CFS文件系统或CFS Turbo文件系统。接下来选择一个您指定的 CFS 实例。其他字段使用默认值,无需改动。
填好后,单击确定。此时会跳转回 Notebook 主页,等待刚刚创建的 Notebook 启动。当 创建的 Notebook 的状态变为“运行中”后,单击“操作”列的打开按钮,跳转进入 JupyterLab。
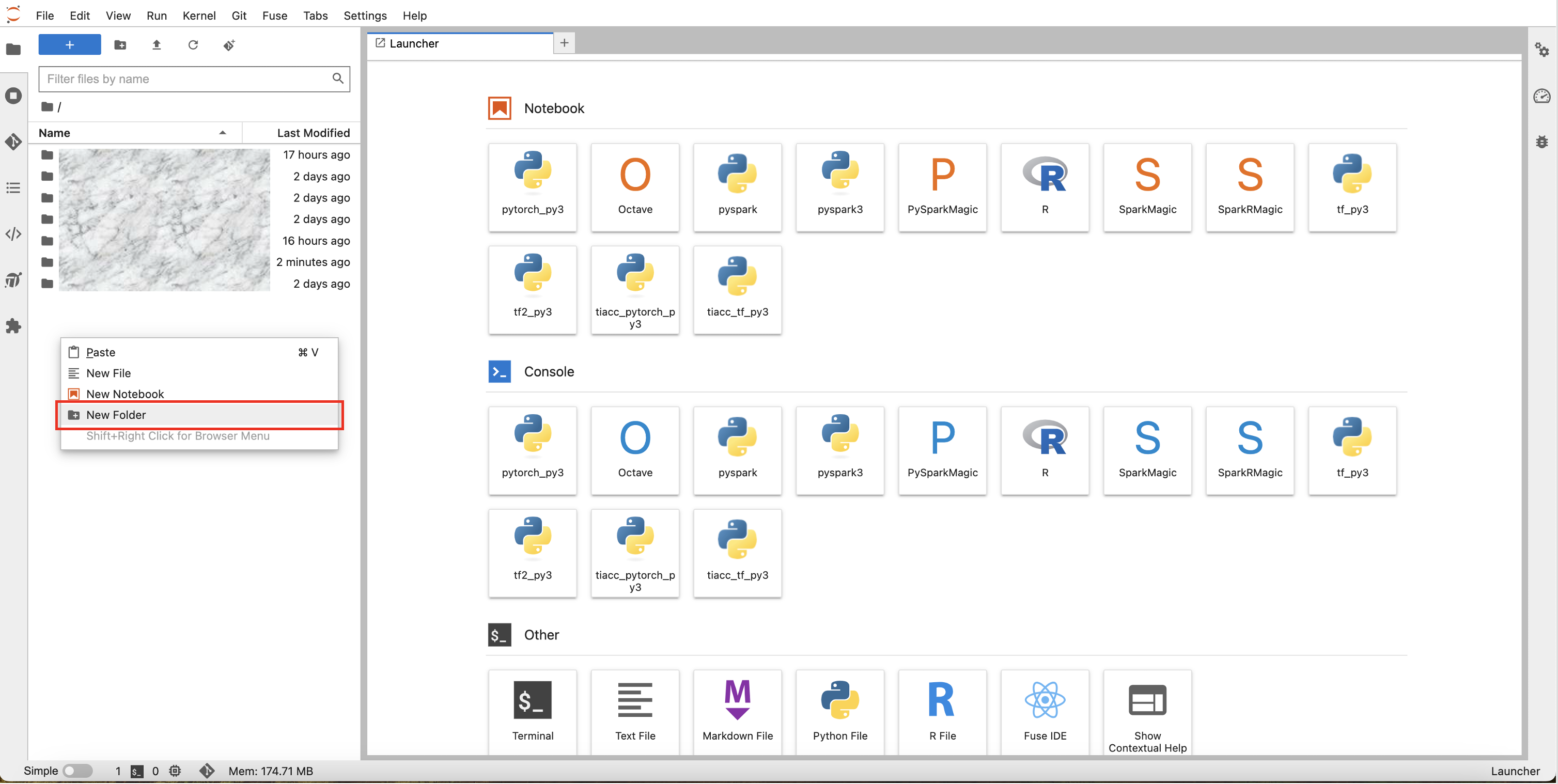
右键单击左侧文件列表中的空白处,在弹出的菜单中,单击如下图红框中New Folder选项以新建文件夹,新文件夹的命名,本文中取值为 “myWorkspace”。
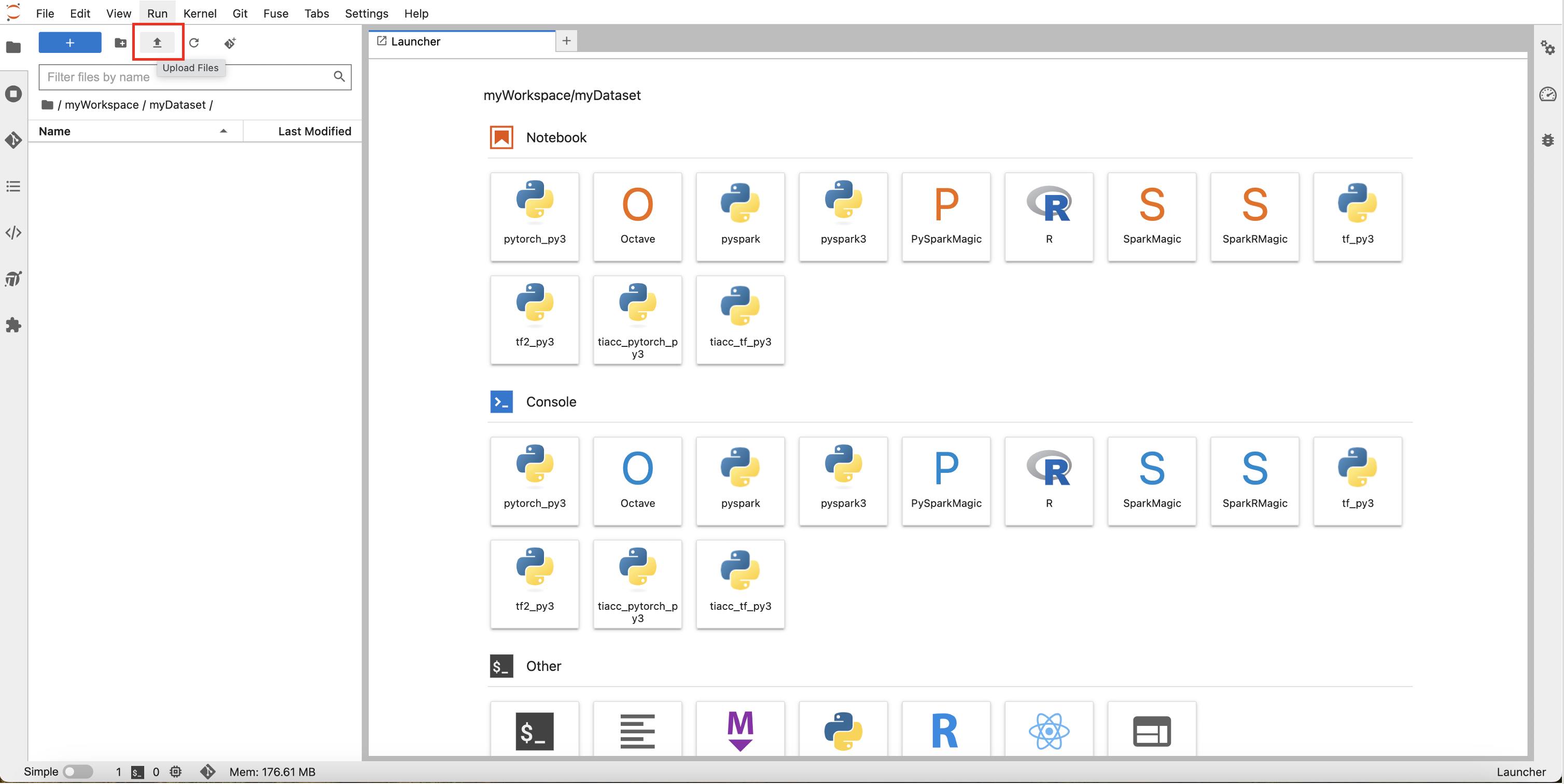
双击myWorkspace图标,进入刚刚新建的文件夹。在新文件夹下创建子文件夹“myDataset”,双击进入“myDataset”,单击下图中红框位置的按钮,唤起本地文件上传对话框,将第 1 节中保存的 myDataset.csv 上传到该文件夹下。
上传成功,在文件夹下显示出 myDataset.csv:
如果您需要在 主观评测 中评测平台尚未内置的大模型,您可以将您从平台外站点(如 HuggingFace 等)获取的模型文件夹压缩为 .zip 文件,并按照本节描述的方式上传到“myWorkspace”文件夹,上传成功后通过在 Terminal 中执行 unzip 命令解压为文件夹以供使用。
上传并解压成功,在“myWorkspace”文件夹下显示出对应模型文件夹(本文中为 “Qwen2.5-0.5B-Instruct”):
三、使用 主观评测 功能对比 Hunyuan-Large 和其他模型
单击平台左侧导航栏中的模型服务 > 模型评测,跳转到 模型评测 模块主页。在 模型评测 主页上方 Tab 选项卡中选择“主观评测”,进入主观评测 Tab 后,单击顶部的新建任务按钮,进入下图所示的 新建主观评测任务 页面:
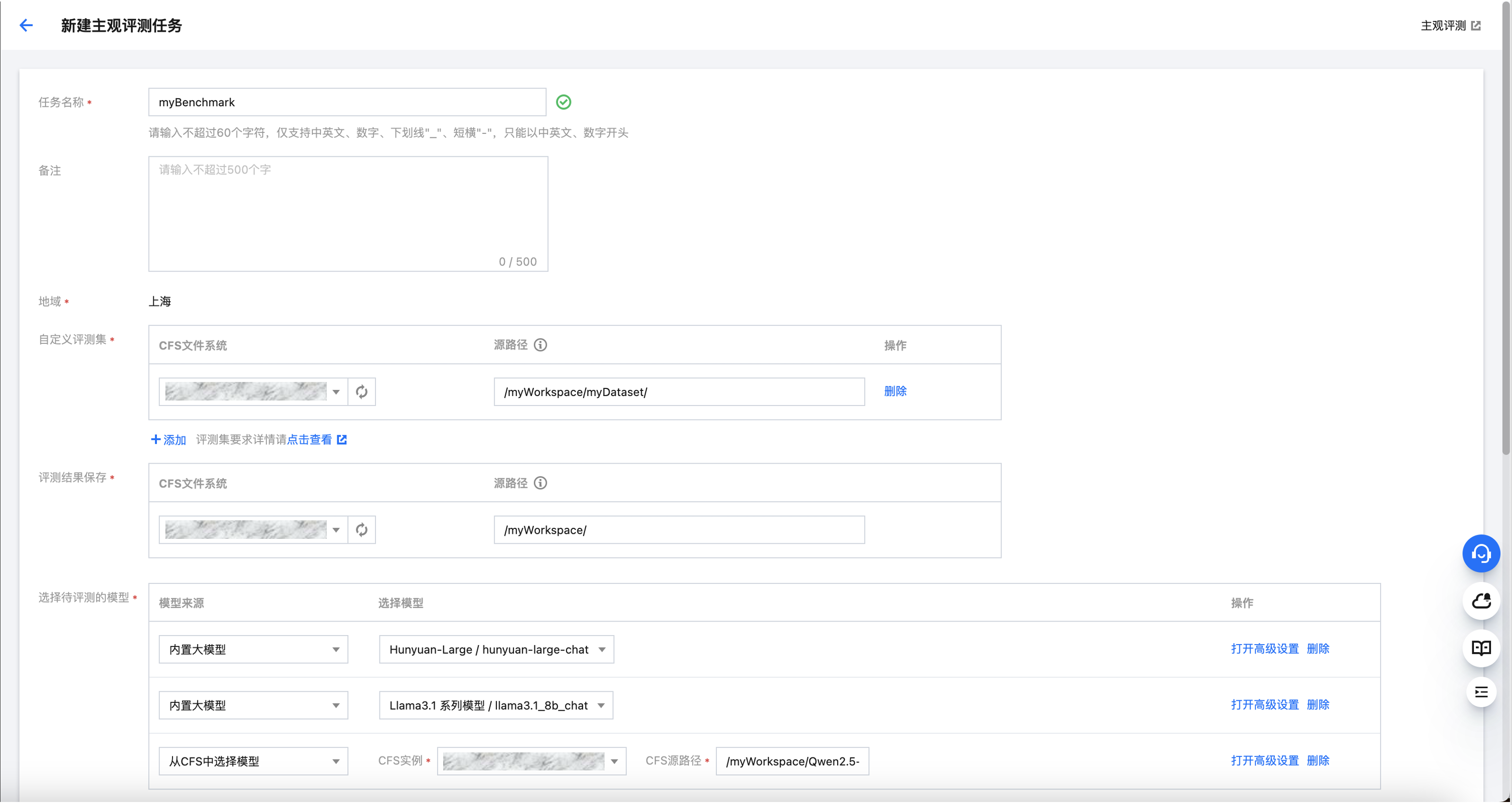
在新建主观评测任务页面,需要填写以下上图所示的字段以完成创建:
1. 任务名称:请输入您指定的任务名称。本文中取值为 “myBenchmark”。
2. 自定义评测集:先单击添加按钮,接下来选择第 2 节中您指定的存放定制数据集和大模型的 CFS 实例。源路径中输入“/myWorkspace/myDataset/”。
3. 评测结果保存:选择第 2 节中您指定的 CFS 实例。源路径中输入“/myWorkspace/”。
4. 选择待评测的模型:先单击添加按钮,模型来源选择“内置大模型”,并在右侧选择框中选择 Hunyuan-Large / hunyuan-large-chat。

如您想和平台内置大模型对比效果:单击添加按钮,模型来源选择“内置大模型”,并在右侧选择框中选择您要对比的大模型。
如您想和第 2 节中上传的大模型对比效果:单击添加按钮,模型来源选择“从 CFS 中选择模型”,并在右侧选择框中选择第 2 节中您指定的 CFS 实例,在文本框中输入模型文件夹的路径。
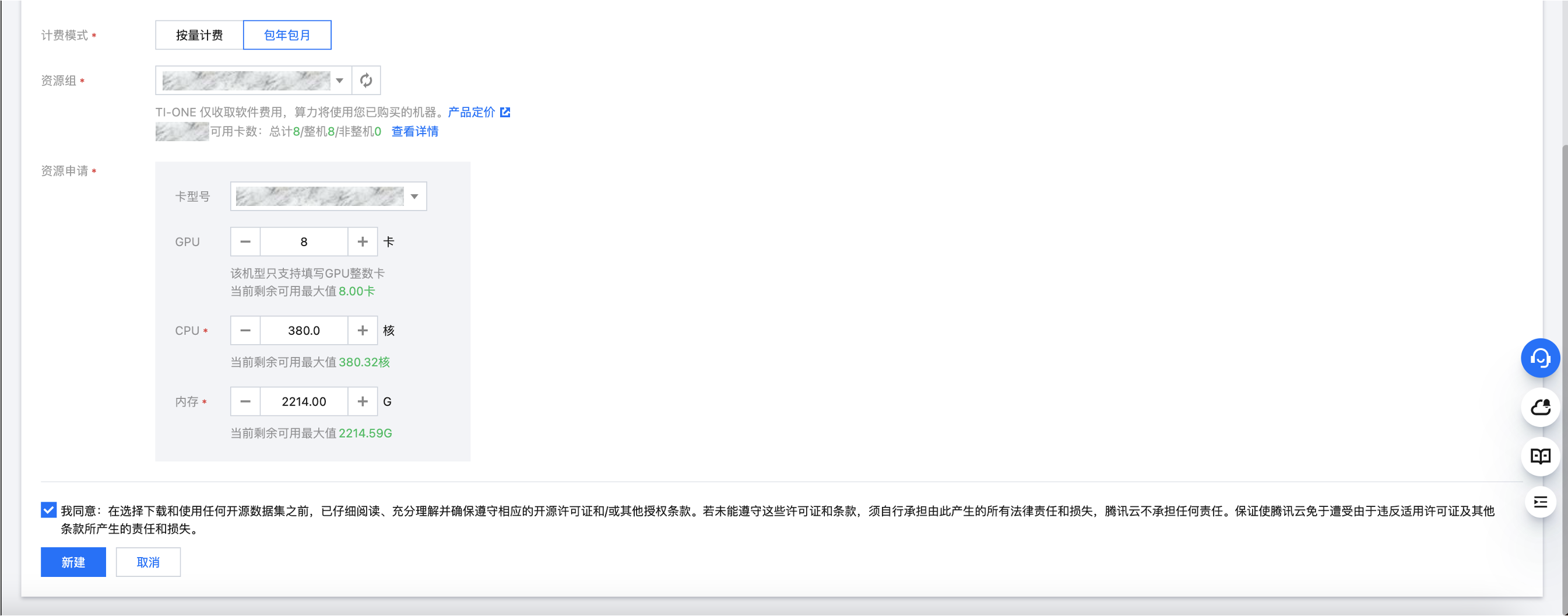
5. 计费模式:请选择“包年包月”(因“按量计费”模型可选的机型无法支撑大模型评测)。
6. 资源组:选择您用来启动评测任务的资源组。若您还没有包年包月的资源组,可参考 资源组管理 产品文档新建。
7. 资源申请:为了评测 Hunyuan-Large 大模型,请使用一台完整的腾讯云 HCCPNV6 节点的资源。
GPU:8 卡
CPU:380 核
内存:2214 G
填好后,单击确定启动任务。此时会跳转回 主观评测 主页,等待刚刚创建的主观评测任务完成。
(加载 Hunyuan-Large 大模型需要 1 小时以上,请耐心等待。)
当创建的主观评测任务的状态变为“已完成”后,单击任务名,进入任务详情页,再单击上方的“人工标注” Tab:
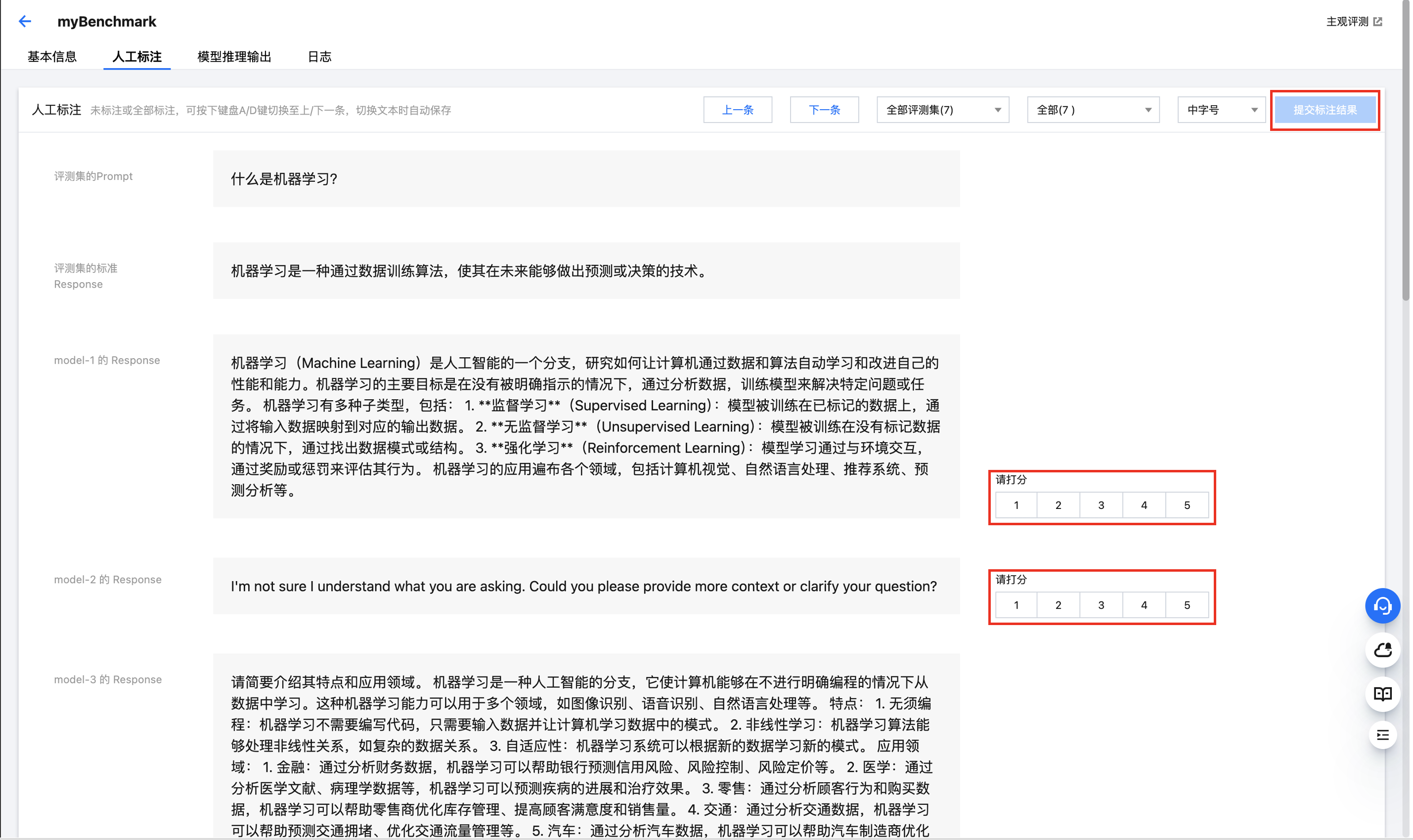
单击上图红框中的打分按钮,即可对参与评测的各个大模型的输出结果进行对比打分,对每一个问题及各个模型的回复打分后,请在键盘上按下“D”键,切换到下一个问题。
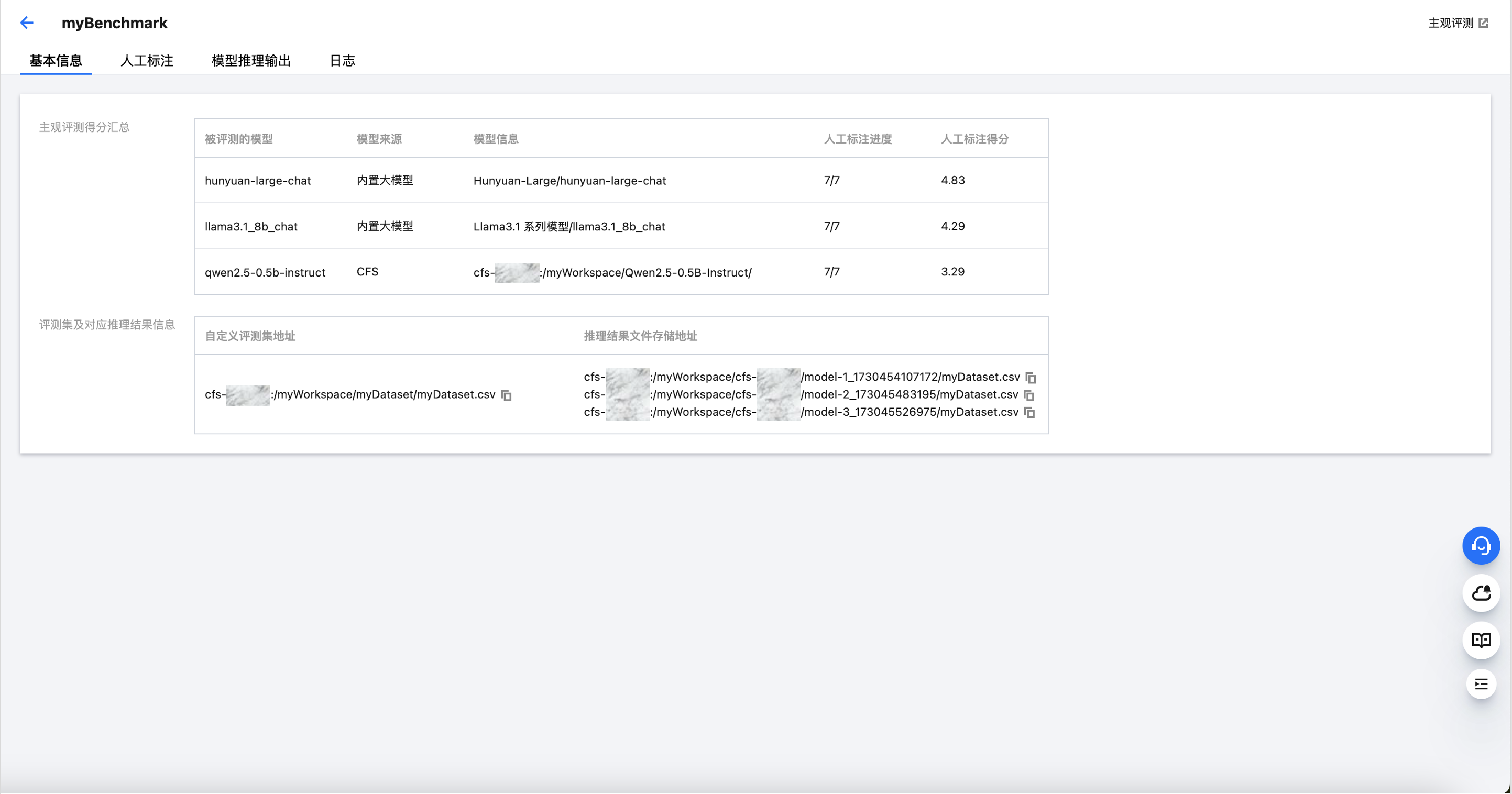
对全部问题均打完分后,单击右上角的提交标注结果按钮,完成结果保存。您可以随时在下图所示的基本信息 Tab 中查看本次评测的各个模型的总体得分: