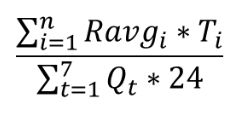「资源监控」通过提供资源看板方式,支持用户查看“资源”和“业务”相关指标,以对资源使用情况、任务运行情况做评估。
您可以选择一个或多个资源组,系统将聚合展示这些资源组的资源使用情况。关键指标包括:
GPU 分配率:衡量任务已使用的资源卡时占总资源卡时的比例,反映资源的需求饱和度。
GPU 均值利用率:评估 GPU 卡在被分配后,实际处于计算状态的时间占比,反映资源使用的真实效率。
任务均值利用率:评估任务在占用资源期间的实际计算繁忙程度。
一、资源维度
详细指标说明
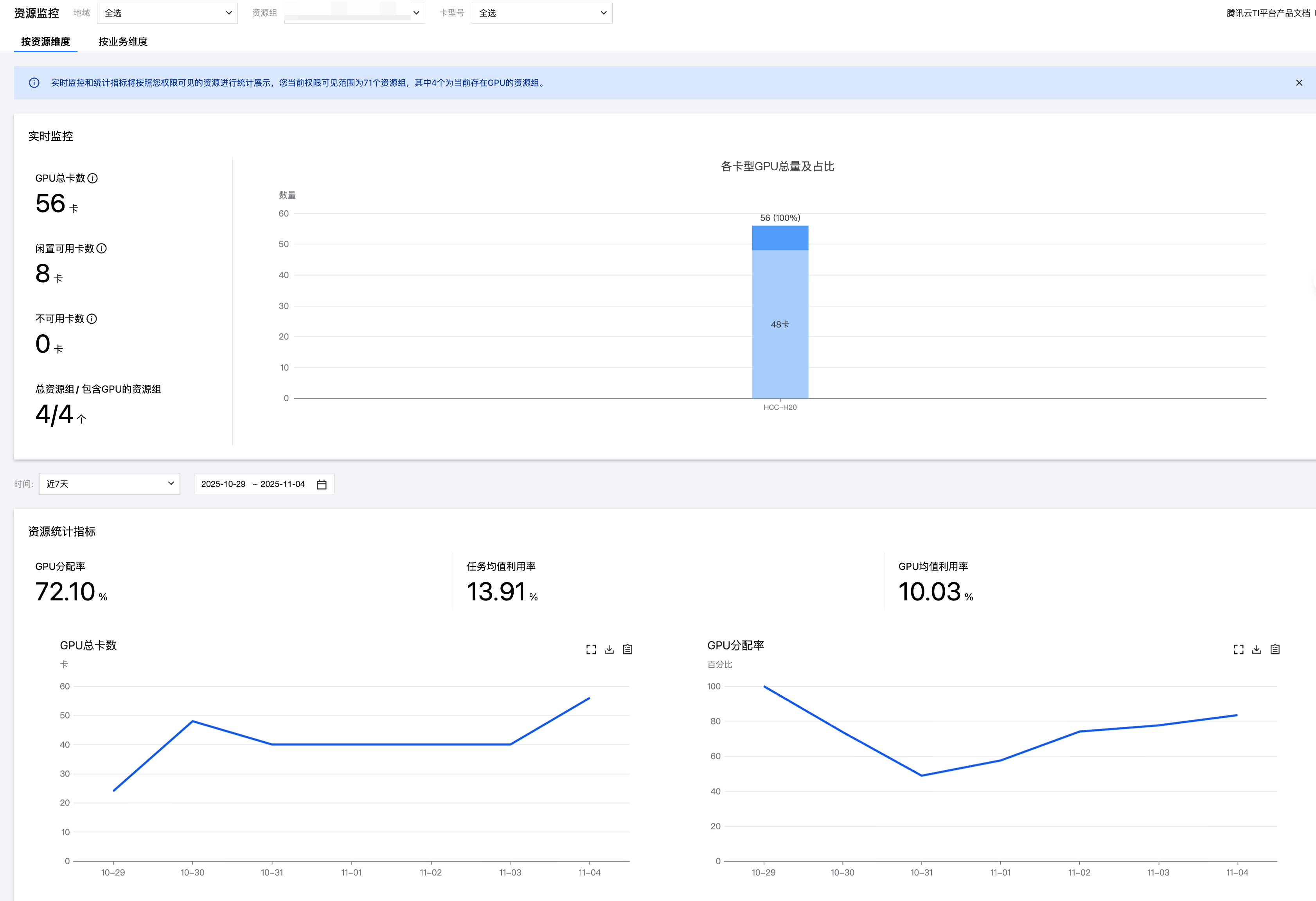
实时监控
指标名称 | 指标说明 |
GPU 总卡数 | 统计的范围为当前资源组中包含的卡,包含包年包月、按量计费以及资源组节点完成部署后的卡 |
闲置可用卡数 | 目前未被使用且可用的卡数 |
不可用卡数 | 目前未被使用且不可用的卡数 |
总资源组/包含 GPU 的资源组 | 总资源组包含用户权限可见的全部资源组 |
各卡型 GPU 总量占比 | 当前各卡型的卡数以及占总卡数的比例,柱状图中会同步展示被占用的卡数 |
总卡数、闲置卡数、不可用卡数按照资源组节点状态是否计入说明:
资源组节点状态 | 总卡数 | 闲置可用卡数 | 不可用卡数 |
购买中 | 否 | 不计入 | 不计入 |
部署中 | 否 | 不计入 | 不计入 |
运行中 | 是 | 计入 | 不计入 |
挂载磁盘中 | 是 | 计入 | 不计入 |
节点移动中 | 是 | 不计入 | 计入 |
异常 | 否 | 不计入 | 计入 |
节点维修中 | 是 | 不计入 | 计入 |
欠费到期 | 否 | 不计入 | 计入 |
待维修 | 是 | 不计入 | 计入 |
已隔离 | 是 | 不计入 | 计入 |
CVM 资源过期 | 否 | 不计入 | 计入 |
部署失败 | 否 | 不计入 | 不计入 |
释放中 | 否 | 不计入 | 计入 |
已释放 | 否 | 不计入 | 计入 |
纳管已不使用 | 否 | 不计入 | 计入 |
统计指标
支持按照一定周期对指标做统计(保留了测试阶段数据用作参考,有效数据以11月1日起为准),统计指标分为整体所选资源组中各 Pod 加权后的"GPU 分配率”、“任务均值利用率”、“GPU 均值利用率”展示、资源组列表中对每个资源组的"GPU 分配率”、“任务均值利用率”、“GPU 均值利用率”展示、卡时消耗列表中对每个资源组的占用卡时的统计展示。
资源统计指标:
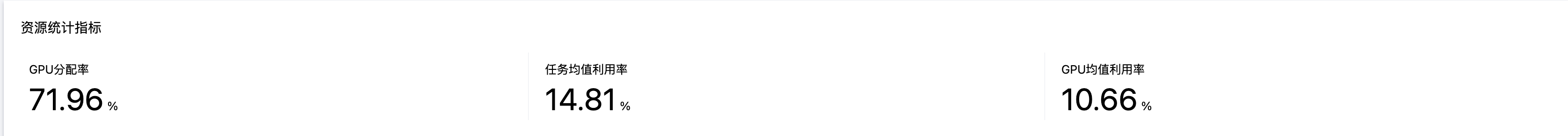
资源组列表:

卡时消耗列表:

指标名称 | 指标说明 |
GPU 分配率 | 时间范围内被分配且使用的 GPU 卡时占总卡时的比例,具体计算公式详见“核心指标说明”标题的“资源组任务利用率/GPU利用率/分配率”(健康监测任务暂未纳入统计) |
任务均值利用率 | 统计周期内,通过单实例 GPU 实际使用率卡时加权平均后获得,具体计算公式详见“核心指标说明”标题的“资源组任务利用率/GPU利用率/分配率”(健康监测任务暂未纳入统计) |
GPU 均值利用率 | 统计周期内,通过单实例 GPU 实际使用率卡时加权后除以总 GPU 卡时后获得,具体计算公式详见“核心指标说明”标题的“资源组任务利用率/GPU利用率/分配率”(健康监测任务暂未纳入统计) |
占用分配率 | 时间范围内被占用的 GPU 卡时占总卡时的比例,具体计算公式详见“核心指标说明”标题的“资源组任务利用率/GPU利用率/分配率”(健康监测任务暂未纳入统计) |
占用卡时 | 时间范围内被占用的 GPU 卡时 |
其中,当资源组的资源被不同的团队成员使用时,卡时消耗列表支持按照团队成员分别统计,用户需要在创建任务时,对任务打上标签,标签的 key 为ti_sys_usergroupid。
二、业务维度
详细指标说明
实时监控

指标名称 | 指标说明 |
在线服务版本数 | 当前平台所有在线服务实例版本数 |
运行中的在线服务版本数 | 当前平台运行中的在线服务实例版本数 |
训练任务数 | 当前平台所有的训练任务总数 |
运行中的训练任务数 | 当前平台运行中的训练任务总数 |
开发机实例数 | 当前平台所有的开发机实例数 |
运行中的开发机实例数 | 当前平台运行中的开发机实例数 |
统计指标
支持按照一定周期对指标做统计(保留了测试阶段数据用作参考,有效数据以11月1日始为准),统计指标分为运行过的和低利用率的任务/服务数,每个大模型服务的"GPU分配率”、“GPU均值利用率”展示、时延、每分钟请求数等指标。
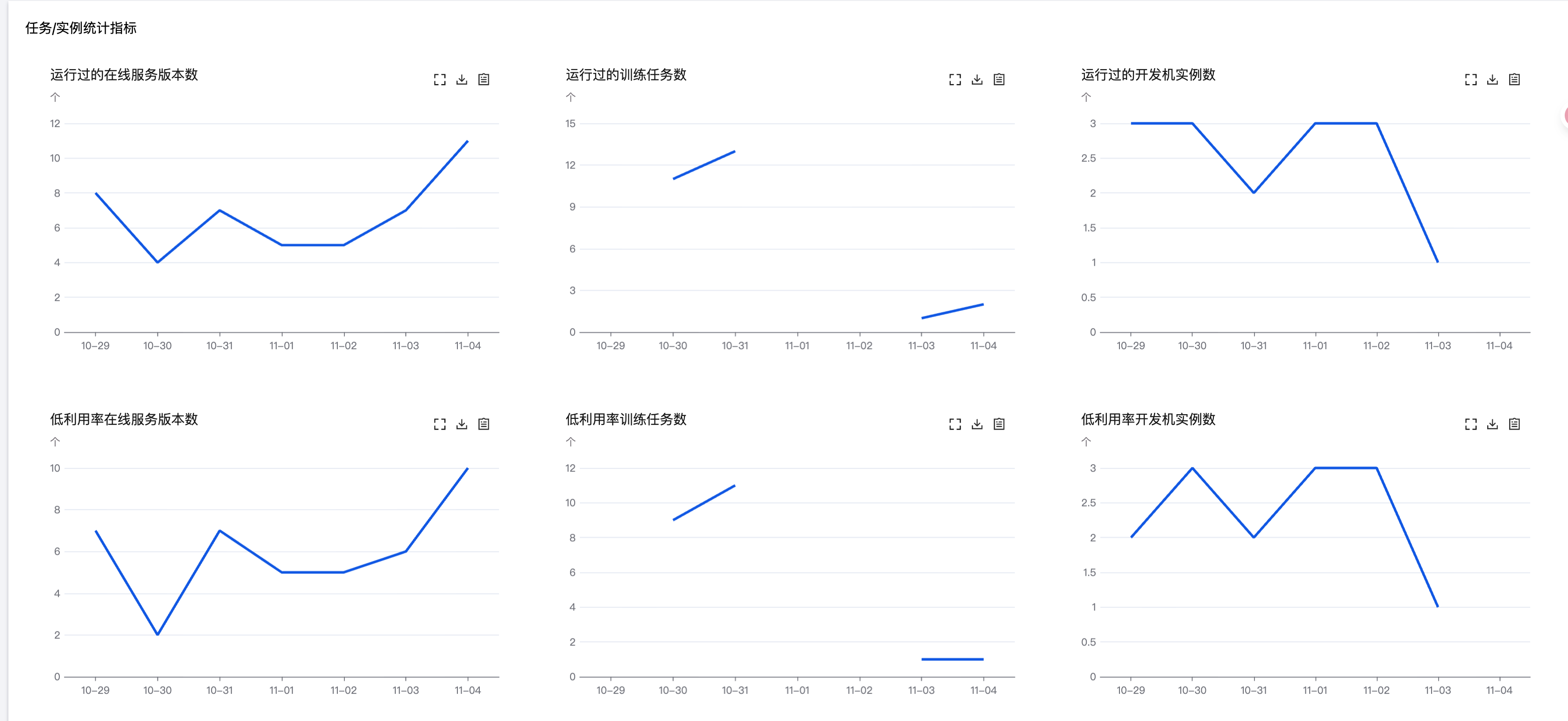

指标名称 | 指标说明 |
运行过的在线服务版本数 | 统计周期内有 GPU 使用上报的服务实例版本数趋势图 |
运行过的训练任务数 | 统计周期内有 GPU 使用上报的训练任务总数趋势图 |
运行过的开发机实例数 | 统计周期内有 GPU 使用上报的开发机实例数趋势图 |
低利用率服务版本数 | 统计周期内运行过的单任务 GPU 利用率低于50%时的任务数趋势图 |
低利用率训练任务数 | 统计周期内运行过的单任务 GPU 利用率低于50%时的任务数趋势图 |
低利用率开发机实例数 | 统计周期内运行过的单任务 GPU 利用率低于50%时的任务数趋势图 |
GPU均值利用率 | 统计周期内,通过单实例 GPU 实际使用利用率卡时加权后除以总 GPU 卡时后获得,具体计算公式详见“核心指标说明”标题的“资源组任务利用率/GPU利用率/分配率”(健康监测任务暂未纳入统计) |
GPU峰值利用率 | 统计周期内,通过单实例 GPU 实际使用 max 利用率卡时加权后除以总 GPU 卡时后获得,具体计算公式详见“核心指标说明”标题的“资源组任务利用率/GPU利用率/分配率”(健康监测任务暂未纳入统计) |
其他指标(时延、每分钟请求数)等 |
三、核心指标计算说明
GPU任务均值/峰值利用率计算过程
GPU任务有多个pod,每个pod有多张卡,利用率上报的最小粒度为卡,每张卡每分钟上报一个利用率数值。
单个任务的均值/峰值利用率由其所用卡在任务生命周期内的利用率聚合,图1展示了一个有两个Pod,每个Pod有4张卡的任务,其均值/峰值利用率计算过程:
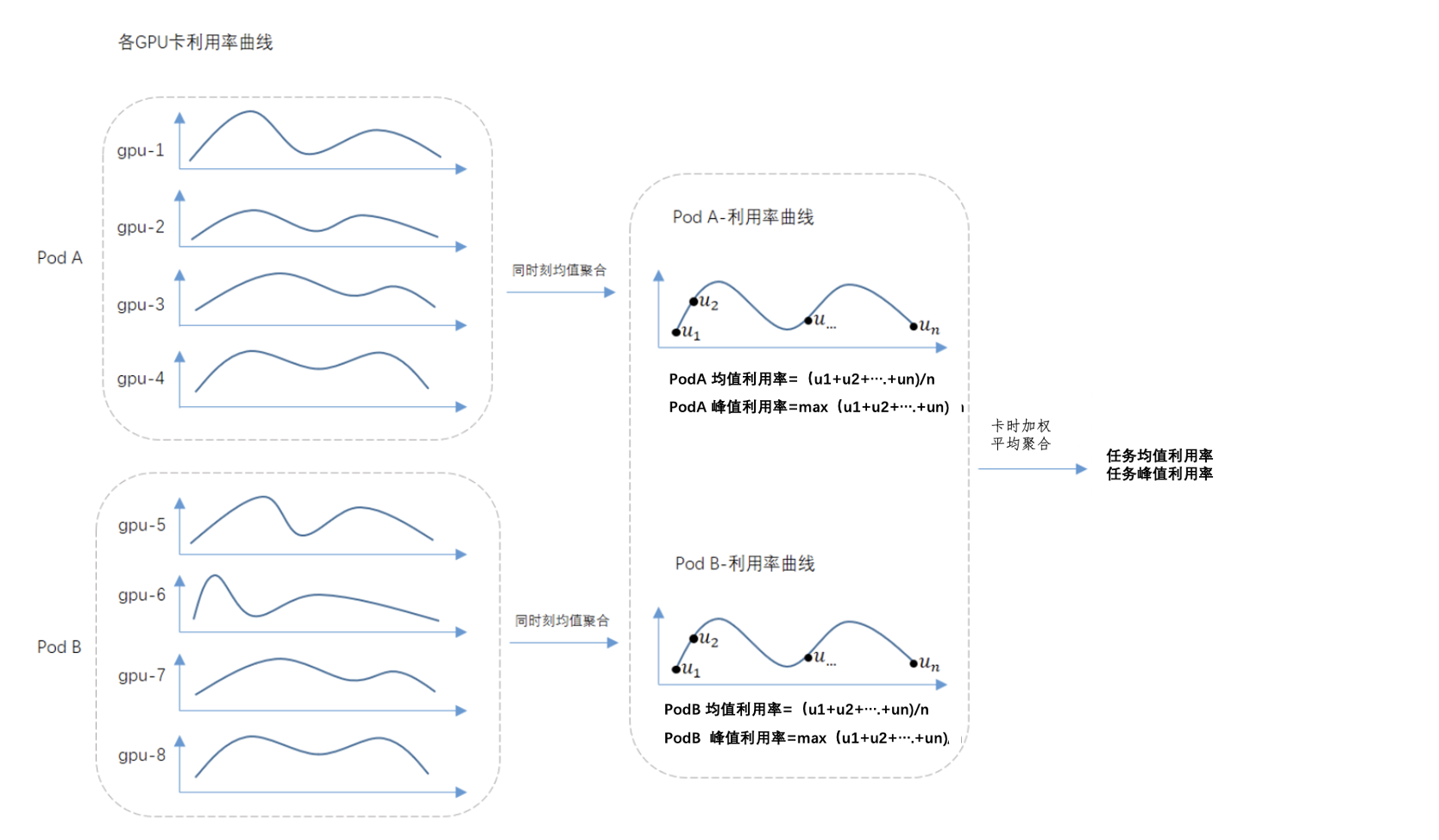
图1 GPU任务均值/峰值利用率计算过程
注意:
每个任务每天都会计算当日的均值和峰值利用率(运行多天的任务,会按天切片计算均值/峰值利用率,例如: 一个运行了3天的任务,会被切片成3个任务)。
每个任务通过先计算单 pod 的 GPU 利用率,不同pod之间通过卡时加权得到任务的平均利用率和峰值利用率。
平台支持同一个任务的不同 pod 使用不同的卡型,在进行卡型汇总时,也是根据使用此卡的 pod 进行卡时加权。
资源组任务利用率/GPU利用率/分配率
pod卡时:T=pod使用卡数 * 运行时长(小时),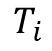
任务均值利用率:Ravg (计算过程如图1所述),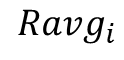
资源组卡数:Q,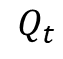
资源组任务利用率 = 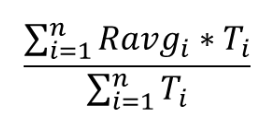
资源组分配率=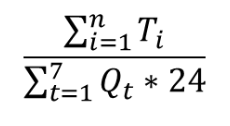
资源组 GPU 利用率=