总览
自动评测支持对模型的通用效果和模型的业务效果进行评测,平台为用户内置了开源评测集,用户可一键发起模型通用能力自动评测。用户也可上传自定义评测集、自定义设置评测指标,支持通过前后处理以及裁判模型输出打分结果。
自动评测支持三种评测模式,分别为“仅评测”、“推理及评测”以及“自定义模式”:
评测模式 | 模式说明 | 指标配置及结果输出 |
仅评测 | 用户上传带模型推理结果的评测集,在自动评测模块完成打分功能。 | 支持自定义评测指标、调试指标、整体结果查看和单条评测结果查看: 自定义指标: 在自定义的评测指标时,需要对每个指标的打分方式进行配置。例如使用裁判模型打分时,需要设置裁判模型、打分 Prompt、以及支持自定义前后脚本对输入输出进行处理,以获得指标结果。 调试指标: 支持在正式发起评测任务前对评测样本进行少量评测,调试时,通过调整打分 Prompt 和前后处理脚本以获得预期的评测效果。 整体结果查看: 支持各模型在各评测集的评测结果查看。 单条评测结果查看: 支持对每条评测数据进行各打分步骤的结果进行查看。 |
推理及评测 | 用户上传只有query(问题)的评测集,在自动评测模块完成推理结果输出和打分。 | |
自定义评测 | 支持用户通过自定义评测镜像进行评测。可将评测集、自定义镜像以及存储挂载等内容合并为一个“任务配置”,每一组配置包含评测集、选择镜像、选择版本、挂载路径设置、启动命令、参数设置、环境变量。用户可通过仅选择镜像和版本,或者选择镜像和版本后再设置挂载路径,以实现镜像或者镜像+挂载路径的方式进行评测。 | 用户可在镜像中或者另外挂载评测脚本自定义评测指标、输出评测结果。 |
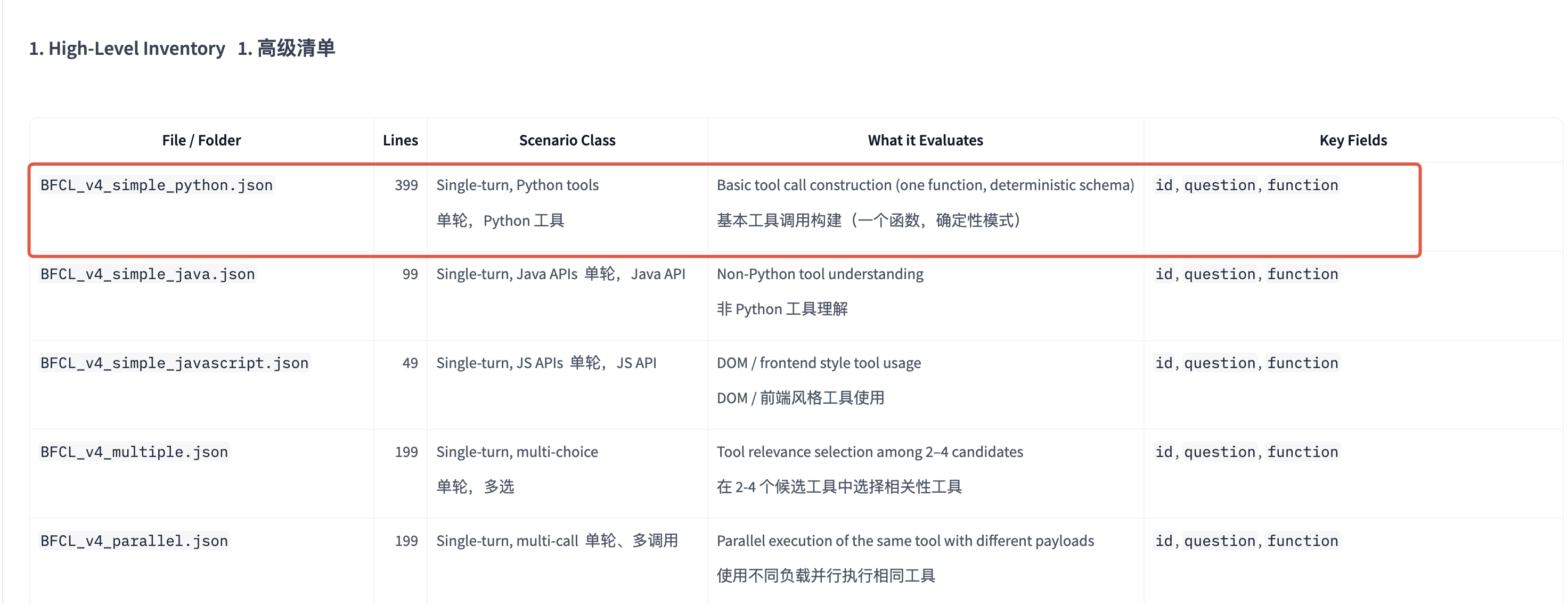
本实践采用“自定义”模式,选择DeepSeek-V3.2为示例的待评测模型在 BFCL_v4_simple_python通过自定义镜像进行评测。
BFCL(Berkeley Function Calling Leaderboard)是首个针对大语言模型(LLM)函数调用与工具使用能力的系统性评估体系。本次选用其中的BFCL_v4_simple_python进行评测,评测DeepSeek-V3.2在此评测集的基础函数调用能力,包含指定函数调用和函数选择调用。
前置准备条件
在创建自动评测任务前,您需要做好以下准备:
1. 制作评测任务镜像
1.1 配置开发机信息
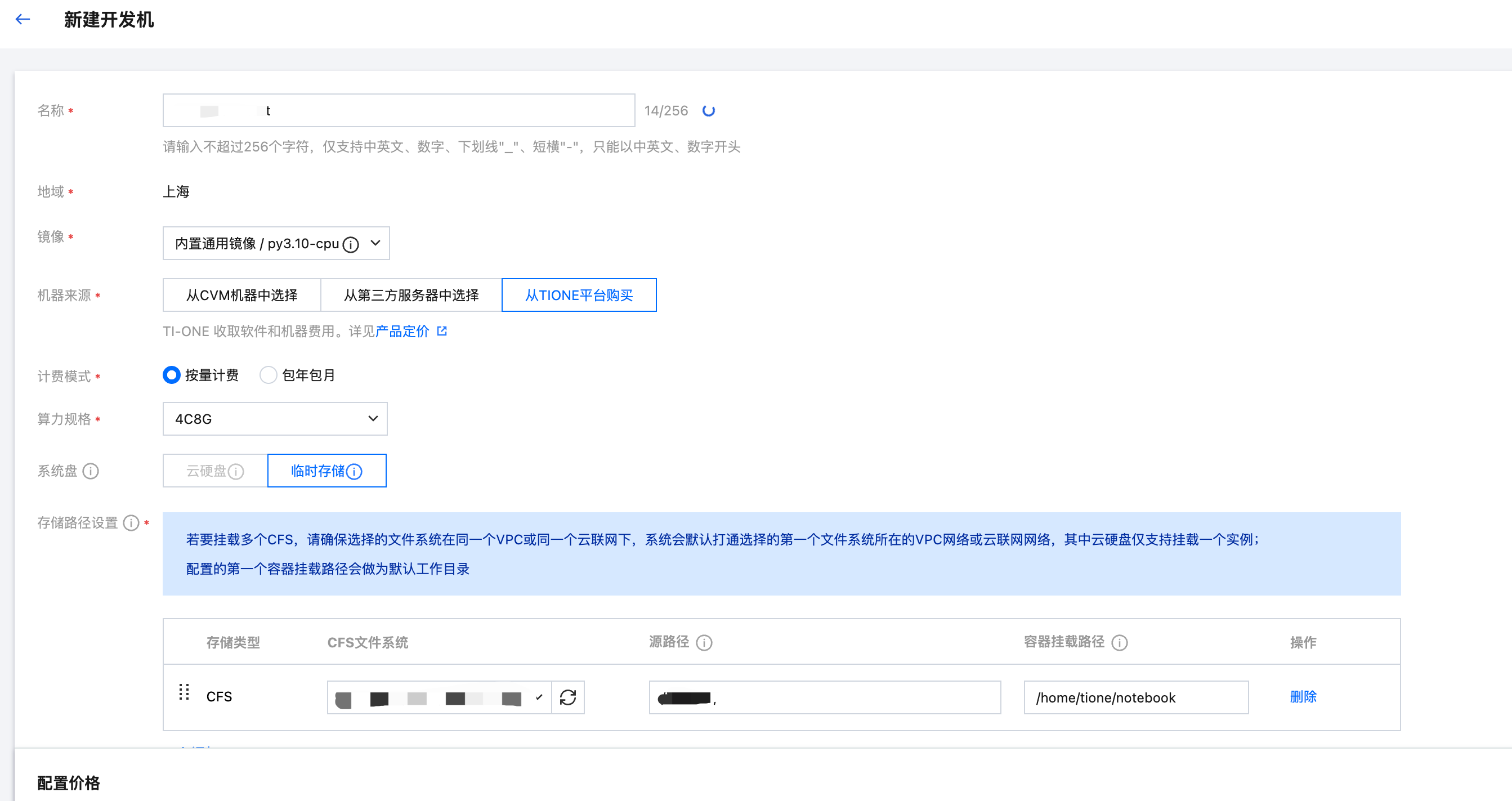
单击 训练工坊-新建开发机,镜像选择内置通用镜像/py3.10-cpu,如果您需要torch的环境也可根据需求选择其他版本内置镜像
机器来源可选自有的资源组 或者 通过从TIONE平台购买,由于仅制作镜像不需要太多的资源,选择2c4g及以上资源即可。
启动后,打开WebIDE,可根据个人喜好进行选择,这里选择vscode:
1.2 配置评测集环境
开发机启动之后,打开terminal,以 clone 评测集源码:
git clone https://github.com/ShishirPatil/gorilla.git
cd gorilla/berkeley-function-call-leaderboardpip install -e .
为支持更多且灵活的模型进行评测,可在model_config.py的文件最后加上如下代码:
# 在最后补充这段代码import os# add custom modelCUSTOM_MODEL_NAME = os.getenv("MODEL_NAME", "")if CUSTOM_MODEL_NAME:MODEL_CONFIG_MAPPING.update({CUSTOM_MODEL_NAME: ModelConfig(model_name=CUSTOM_MODEL_NAME,display_name=CUSTOM_MODEL_NAME,url="",org="Custom",license="apache-2.0",model_handler=OpenAICompletionsHandler,input_price=None,output_price=None,is_fc_model=True,underscore_to_dot=True,)})
1.3 新建启动代码文件、评测代码、指标保存文件
启动代码文件
四个环境变量及要求如下:
环境变量 | 说明 | 备注 | 示例 |
EVAL_OUTPUT_DIR | 结果输出目录 | 镜像中需要将评测结果保存至此目录,以用于结果展示/可视化对比 | /opt/ml/output |
EVAL_INFERENCE_URL | 模型API地址 | 由于一个任务配置可能会对多个模型服务进行评测,平台通过该环境变量传递模型服务的调用信息 | https://api.openai.com/v1/chat/completions |
EVAL_AUTHORIZATION_HEADER_KEY | 鉴权头名称 | | Authorization |
EVAL_AUTHORIZATION_HEADER_VALUE | 鉴权头值 | | sk-xxx... |
启动代码(run.sh):
TEST_CATEGORY="simple_python"export MODEL_NAME=$MODEL_NAMEexport OPENAI_BASE_URL=${EVAL_INFERENCE_URL%/chat/completions}export OPENAI_API_KEY="${EVAL_AUTHORIZATION_HEADER_VALUE#Bearer* }"python openfunctions_evaluation.py --model $MODEL_NAME --test-category $TEST_CATEGORY --num-threads 16
评测代码(evaluate.sh):
TEST_CATEGORY="simple_python"export MODEL_NAME=$MODEL_NAMEexport OPENAI_BASE_URL=${EVAL_INFERENCE_URL%/chat/completions}export OPENAI_API_KEY="${EVAL_AUTHORIZATION_HEADER_VALUE#Bearer* }"python -m bfcl_eval.eval_checker.eval_runner --model $MODEL_NAME --test-category $TEST_CATEGORY
保存指标代码(save_metric.py):
# save_metric.pyimport jsonimport os# 获取输出目录output_dir = os.getenv("EVAL_OUTPUT_DIR")model_name = os.getenv("MODEL_NAME")# 构造结果数据original_result_file = os.path.join("score", model_name, "non_live", "BFCL_v4_simple_python_score.json")with open(original_result_file) as f:first_line = f.readline().strip()original_result = json.loads(first_line)result = {"metrics": [{"name": "accuracy", "value": original_result["accuracy"]},]}# 写入结果文件result_file = os.path.join(output_dir, 'metrics.json')with open(result_file, 'w', encoding='utf-8') as f:json.dump(result, f, indent=2, ensure_ascii=False)
1.4 进行任务调试
准备调试代码文件:
# 模拟由平台注入的环境变量export MODEL_NAME={YOUR_MODEL_NAME}export EVAL_INFERENCE_URL={YOUR_MODEL_BASE_URL}export EVAL_AUTHORIZATION_HEADER_VALUE={YOUR_API_KEY}export EVAL_OUTPUT_DIR="/opt/ml/output"mkdir -p $EVAL_OUTPUT_DIRbash run.shbash evaluate.shpython save_metric.py
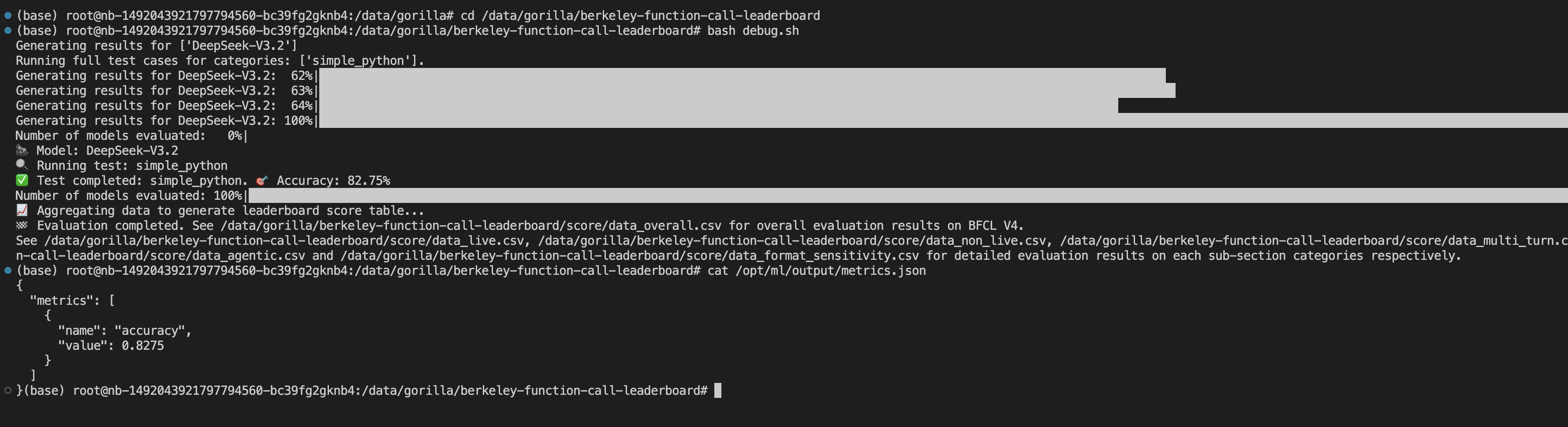
单击运行后,结果如下:
1.5 保存镜像
选择对应的开发机任务,单击保存镜像。

通过以上步骤完成评测镜像制作,并且将评测依赖、评测代码等都内置在了镜像中。在接下来的自动评测-自定义评测任务中,可直接选择待评测模型以及此镜像直接运行评测任务。
2. 准备待评测的模型服务
使用自定义评测模式进行评测
1. 配置基本信息
配置任务名称等基本信息。
2. 配置任务
进行任务配置。支持用户通过自定义评测镜像进行评测时,可将评测集、自定义镜像以及存储挂载等内容合并为一个“任务配置”,每一组配置包含评测集、选择镜像、选择版本、挂载路径设置、启动命令、参数设置、环境变量。用户可通过仅选择镜像和版本,或者选择镜像和版本后再设置挂载路径,以实现镜像或者镜像+挂载路径的方式进行评测。本实践中由于制作镜像时,已将依赖、评测文件等安装在镜像中,可直接通过镜像进行评测,不需要进行文件挂载。
单击 +添加配置,输入评测集名称。选择上述已准备完成的镜像和版本,填写启动命令。
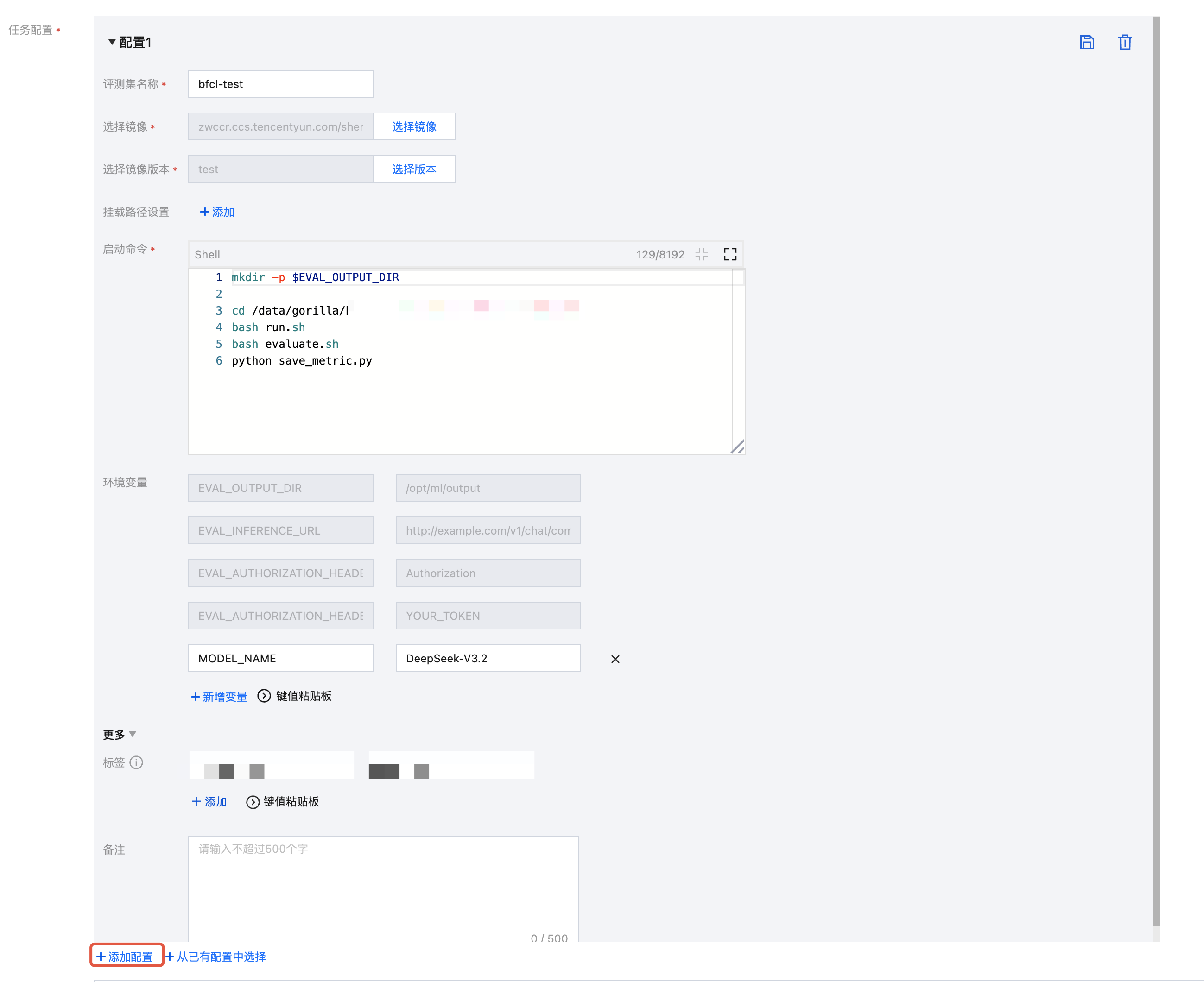
在环境变量中增加“MODEL_NAME"指定待评测的模型名称。
可单击右上角的“保存”图标,将此配置保存至配置列表,以便成员和个人下次直接选择此配置进行复用。
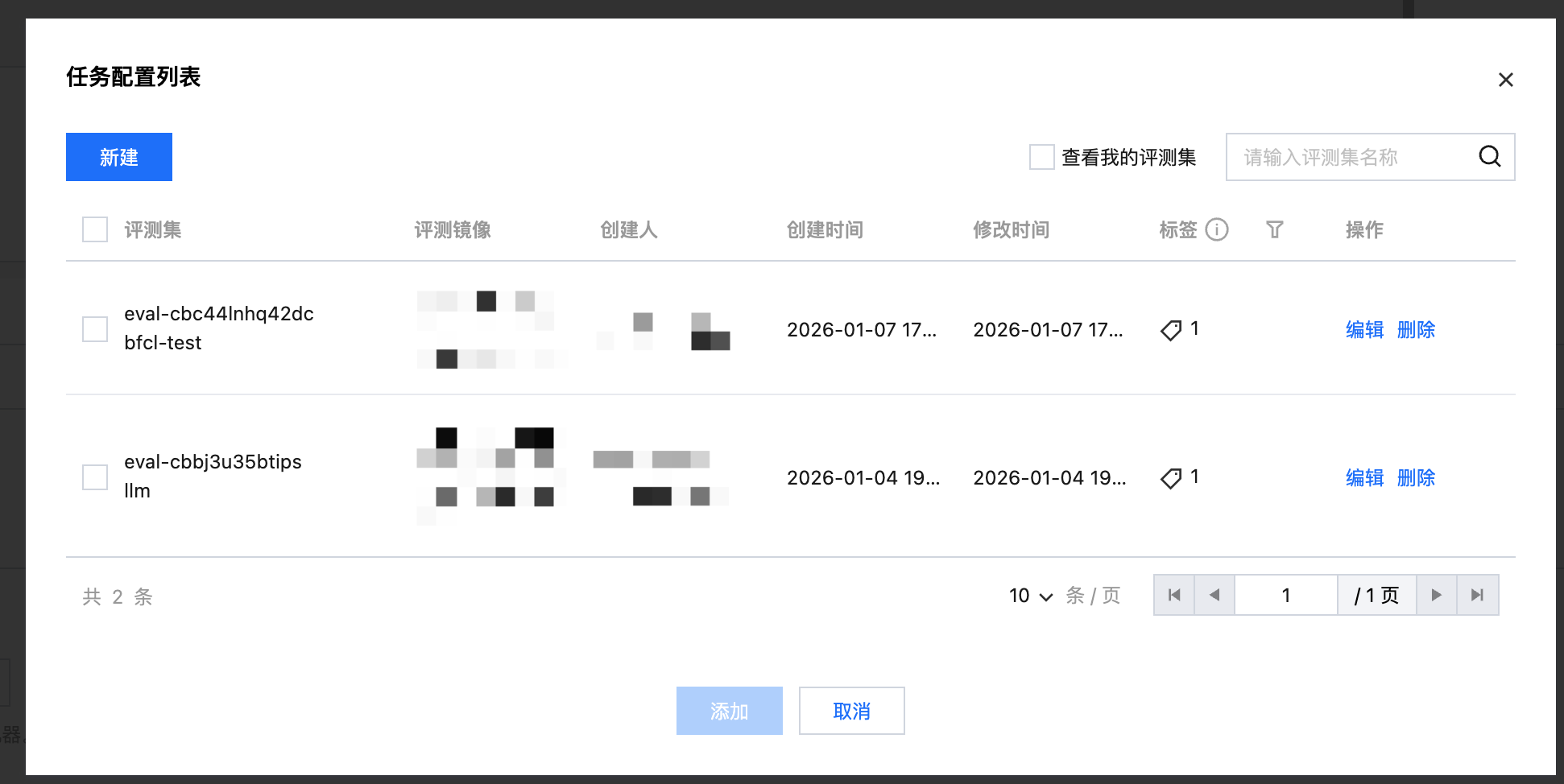
单击 +从已有配置中选择 可看到配置列表,勾选对应的配置可直接添加。
3. 配置待评测的模型
待评测的模型支持选择模型和模型服务,这里填入事先准备好的运行中的模型服务地址。

4. 配置任务资源
配置资源时,需要申请任务资源和模型资源,任务资源用于运行评测镜像,模型资源用于将模型部署成服务。由于待评测的模型为模型服务,所以本次只需申请任务资源。
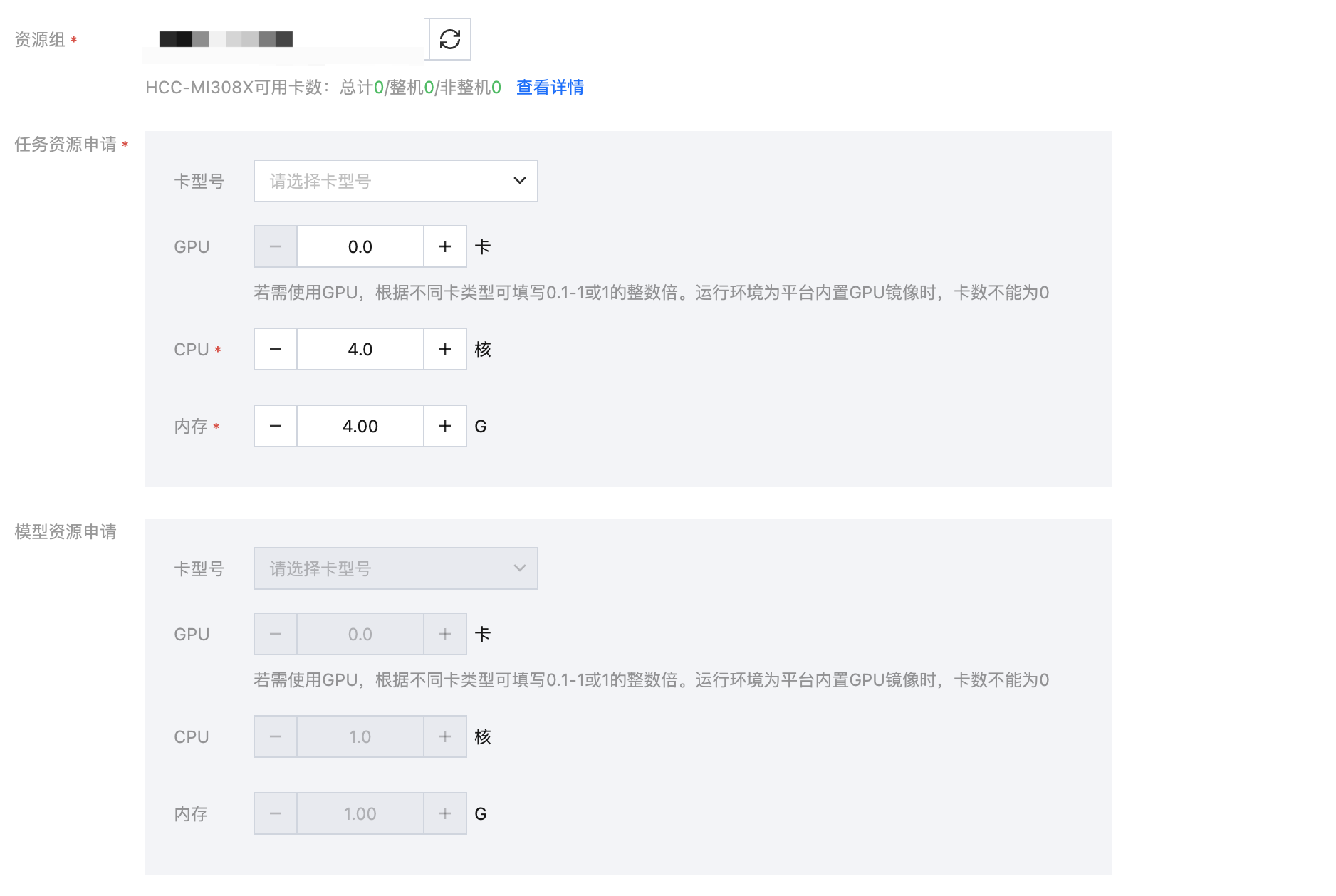
单击提交任务 ,开始正式进行评测。
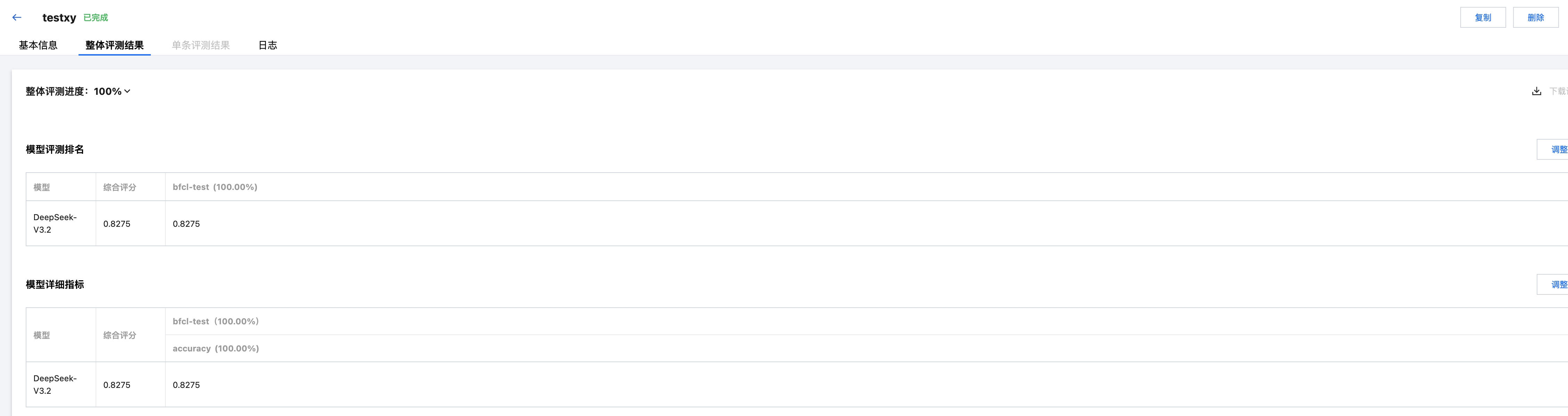
5. 查看评测结果
单击 整体评测结果 查看评测结果。