实验背景
本实验通过一个简单的图像分类场景,演示如何使用 TI-ONE 平台开发套件 Tikit 在 Notebook 中提交分布式训练任务和注册模型,通过此案例的学习,您可以掌握 Tikit 的基本使用方法。
实验准备
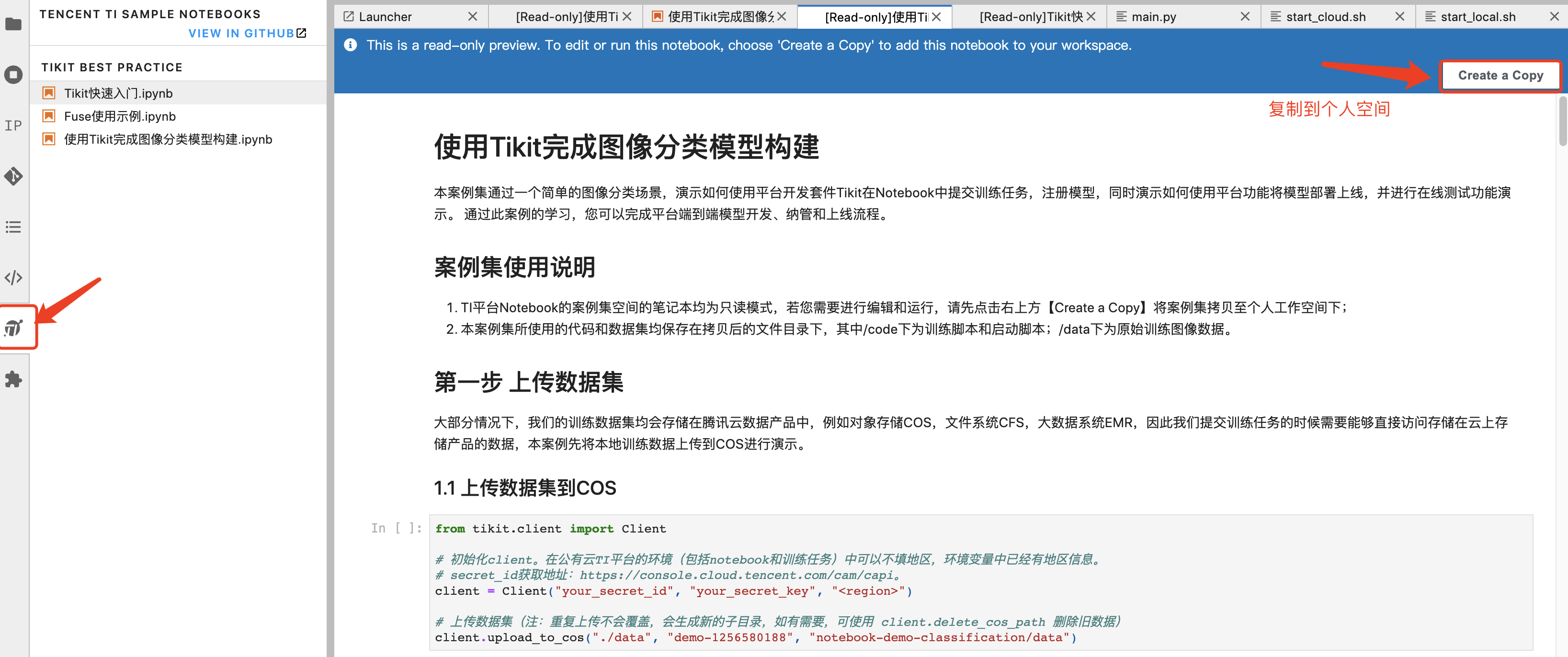
Notebook 环境内已内置本案例代码包和说明指引,您可以前往 Notebook 案例集进行 Copy 体验。

实验步骤
第一步 上传数据集
大部分情况下,我们的训练数据集均会存储在腾讯云数据产品中,例如对象存储 COS,文件系统 CFS,大数据系统 EMR,因此我们提交训练任务的时候需要能够直接访问存储在云上存储产品的数据。因此您需要将实验数据上传到您的腾讯云 COS 存储桶中。本实验教程中,已将训练数据上传至存储桶“demo-1256580188”下的"notebook-demo-classification/data"目录下。
from tikit.client import Client# 初始化client。在公有云TI平台的环境(包括notebook和训练任务)中可以不填地区,环境变量中已经有地区信息。# secret_id获取地址:https://console.cloud.tencent.com/cam/capi。client = Client("your_secret_id", "your_secret_key", "<region>")# 上传数据集(注:重复上传不会覆盖,会生成新的子目录,如有需要,可使用 client.delete_cos_path 删除旧数据)client.upload_to_cos("LOCAL_PATH", "YOUR_BUCKE_NAME", "YOUR_COS_PATH")
第二步 准备训练代码
下面介绍如何准备实验代码。
2.1 脚本命名
1. 将算法脚本命名为 main.py。
2. 准备本地运行启动命令 start_local.sh。
3. 准备提交到远程算力集群启动命令 start_cloud.sh。
2.2 根据 Pytorch 1.9 提供的接口开发训练算法
使用pytorch ddp进行分布式多机训练时,启动命令有 --nodes,--node_rank,--nproc_per_node,--master_addr,–master_port等几个参数(详见pytorch官方文档):
--nnodes:对应环境变量NODE_NUM--node_rank:对应环境变量INDEX--nproc_per_node:对应环境变量GPU_NUM_PER_NODE--master_addr:对应环境变量CHIEF_IP--master_port:没有对应环境变量,用户自己指定一个即可
2.3 读取训练数据
在启动命令 main.py 后紧跟训练数据路径,/opt/ml/input/data 是平台任务默认的数据存放路径(这个路径存在于训练机器上),在任务启动后,会将 COS 中的数据下载到这个指定的路径下或自定义子路径下(例如这里的 image_classify),用户脚本读取对应路径下的数据即可。
以下代码段来自 start_cloud.sh:
python3 -m torch.distributed.launch --nnode=${num_nodes} --node_rank=${node_index} --nproc_per_node=${num_gpus} --master_addr=${maddr} --master_port=23457 main.py \\/opt/ml/input/data/image_classify -a resnet50 --batch-size 128 --lr 0.01 --pretrained --local_world_size=${num_gpus}
2.4 自定义上传指标
2.4.1 初始化 tikit(这里需要替换为用户自己的 secret_id、secret_key)
from tikit.client import Clientclient = Client("your_secret_id", "your_secret_key", "<region>")
2.4.2 查看上传指标用法
# 查看上传指标方法help(client.push_training_metrics)
2.4.3 上传指标
在valide函数中,上传训练指标 acc1和acc5。
def validate(val_loader, model, criterion, epoch, args):batch_time = AverageMeter('Time', ':6.3f')losses = AverageMeter('Loss', ':.4e')top1 = AverageMeter('Acc@1', ':6.2f')top5 = AverageMeter('Acc@5', ':6.2f')progress = ProgressMeter(len(val_loader),[batch_time, losses, top1, top5],prefix='Test: ')# switch to evaluate modemodel.eval()with torch.no_grad():end = time.time()for i, (images, target) in enumerate(val_loader):if args.gpu is not None:images = images.cuda(args.gpu, non_blocking=True)target = target.cuda(args.gpu, non_blocking=True)# compute outputoutput = model(images)loss = criterion(output, target)# measure accuracy and record lossacc1, acc5 = accuracy(output, target, topk=(1, 5))losses.update(loss.item(), images.size(0))top1.update(acc1[0], images.size(0))top5.update(acc5[0], images.size(0))# measure elapsed timebatch_time.update(time.time() - end)end = time.time()if i % args.print_freq == 0:progress.display(i)# 上传指标client.push_training_metrics(int(time.time()), {"acc1": float(format(top1.avg, '.3f')), "acc5": float(format(top5.avg, '.3f'))}, epoch=epoch)# TODO: this should also be done with the ProgressMeterprint('TIACC - * Acc@1 {top1.avg:.3f} Acc@5 {top5.avg:.3f} Epoch={epoch}'.format(top1=top1, top5=top5, epoch=epoch))return top1.avg
任务完成后,可以在“任务式建模/监控”下查看指标(可能会存在一点延迟)。
2.5 上传训练代码到 COS
此时,我们已经准备好训练代码了,将写好的训练代码上传到 COS 中,后续提交训练任务时读取 COS 中的代码。
client.upload_to_cos("LOCAL_PATH", "YOUR_BUCKE_NAME", "YOUR_COS_PATH")
第三步 本地调试
start_local.sh 是可以本地运行脚本,脚本中已经指定了训练数据路径,用户可以切换到pytorch环境(source activate pytorch_py3)直接执行 sh start_local.sh 命令运行(注:该脚本需要 GPU 环境,如果当前 notebook 不是 GPU 环境,则需要启动一个 GPU 环境的 notebook 运行)。
运行命令:
cd ~/classify_example_2022-04-28/codesource activate pytorch_py3sh start_local.sh
第四步 使用 Tikit 提交训练任务
本地进行单机调试成功后,可以使用Tikit的远程任务提交命令,提交分布式训练任务。此任务提交了一个 Pytorch DDP 分布式训练任务(2节点)。我们来看下具体代码如何撰写:
# 查询平台支持的训练框架client.describe_training_frameworks()# 查询计算资源配置client.describe_postpaid_training_price()# 创建训练任务from tikit import models# 配置训练任务的计算框架和训练模式,此处选择训练框架为torch1.9-py3.8-cuda11.1-gpu,训练模式为DDPframework = models.FrameworkInfo.new_system_framework("PYTORCH", "torch1.9-py3.8-cuda11.1-gpu", "DDP")# 配置计算资源,此处配置为V100节点*2worker_resource = models.ResourceConfigInfo.new_postpaid("TI.GN10.2XLARGE40.POST", 2)# 配置数据输入信息,需要将COS中的训练数据映射到容器目录中# 'demo-1256580188/notebook-demo-classification/data'是第一步数据上传的cos路径,# '/opt/ml/input/data/image_classify'是步骤2.3中指定的数据读取路径,也就是容器本地路径(代码中读取)input_data = models.TrainingDataConfig.new_cos_data({"demo-1256580188/notebook-demo-classification/data/":"/opt/ml/input/data/image_classify"})# 创建训练任务client.create_training_task("xxx5", # 任务名称framework, # 训练框架"demo-1256580188/output/", # 训练输出路径worker_resource, # 资源配置信息input_data_config=input_data, # 数据输入配置code_package_path="demo-1256580188/notebook-demo-classification/code/", # 训练代码所在路径worker_start_cmd="sh start_cloud.sh") # 启动命令
任务提交完成后可返回对应的任务ID,可以通过如下命令查看训练日志
# 查看训练日志client.describe_train_logs("train-544168070598700544*")
训练过程中也可以进入任务式建模前端控制台点击任务名称,查看训练任务详情和训练过程指标。
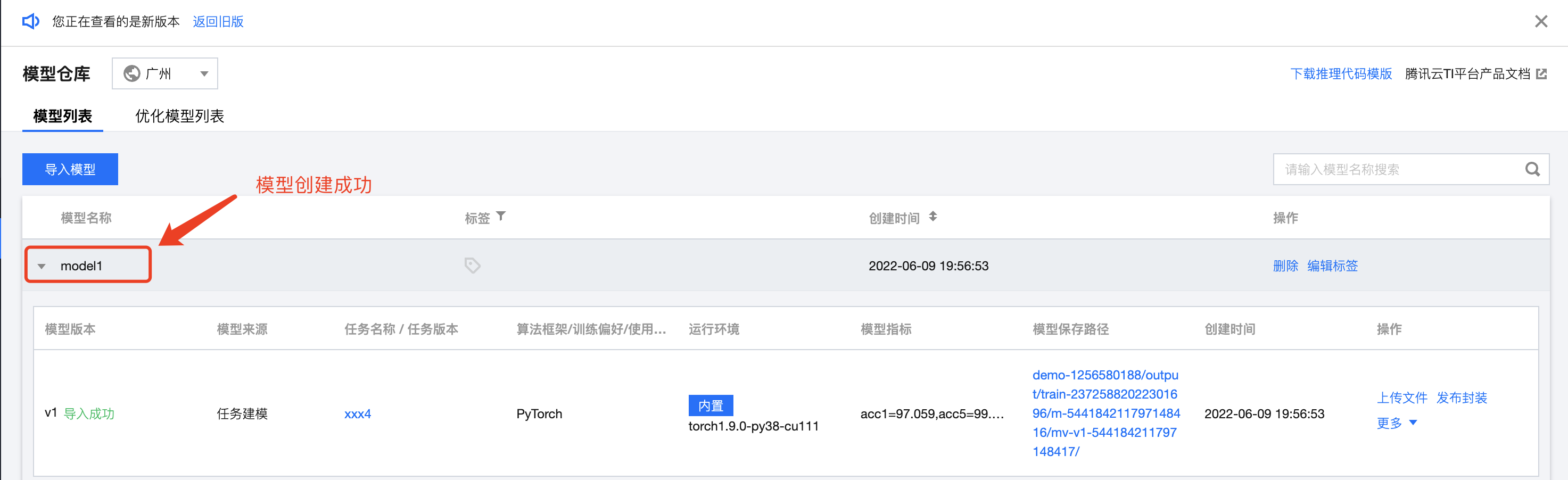
第五步 注册模型
任务训练完成后,需要将模型注册到模型仓库;注册模型时需要指定模型后续的推理框架。
# 查看推理镜像。(运行查看最新版本信息)client.describe_system_reasoning_images()```确定好推理框架后开始创建模型。```# 指定模型推理框架reasoning_env = models.ReasoningEnvironment.new_system_environment("torch1.9.0-py38-cu111")# 模型输出路径,即/model文件目录,为用户在训练任务配置的模型输出路径+task_id,如下output/train-544168070598700544/所示model_output_path = models.CosPathInfo("demo-1256580188", "output/train-544168070598700544/", "ap-guangzhou")# 创建模型,这里训练任务ID就是上面创建的训练任务IDclient.create_model_by_task("model1", "train-544168070598700544", reasoning_env, module_output_path, "PYTORCH")```模型创建成功后可在模型仓库查看对应的模型信息。