智能字幕功能简介
智能字幕功能支持处理离线音频文件、视频文件及直播流,可通过 ASR 语音识别或 OCR 文本识别提取视频源语言字幕,并实现多语言翻译。同时也支持对字幕文件进行大模型文本翻译。该功能还支持配置热词库和术语库,以提高语音识别和大模型翻译的准确率。
智能字幕功能 | 描述 | 支持输入类型 |
语音识别(ASR)生成字幕 | 通过 ASR 语音识别,将对白转换为字幕文件,并进行大模型翻译。 支持配置热词库和术语库,以提高语音识别和大模型翻译的准确率。 支持将字幕压制渲染到视频画面中。 | 音频文件、视频文件、直播流、实时音频流 |
文本识别(OCR)生成字幕 | 通过 OCR 文本识别,将画面上的文字提取为字幕文件,并进行大模型翻译。 | 视频文件(且画面上带有硬字幕) |
翻译字幕文件 | 输入需为字幕文件,通过大模型翻译为多语种,生成新字幕文件。 | 字幕文件(支持 WebVTT 、SRT 格式) |
技术优势
全平台支持:支持处理离线文件、直播流、互动音视频、会议字幕。直播实时同传字幕支持稳态、渐变模式,接入门槛低,无需播放端改造。
准确率高:大模型处理,支持热词、术语库,准确率行业领先。
语种丰富:支持上百种语种,支持多地方言,支持中英文夹杂等混合语种识别。
样式自定义:支持将字幕压制至视频,且字幕样式(字体、字号、颜色、背景、位置等)可自定义,支持页面自定义渲染。
免费体验
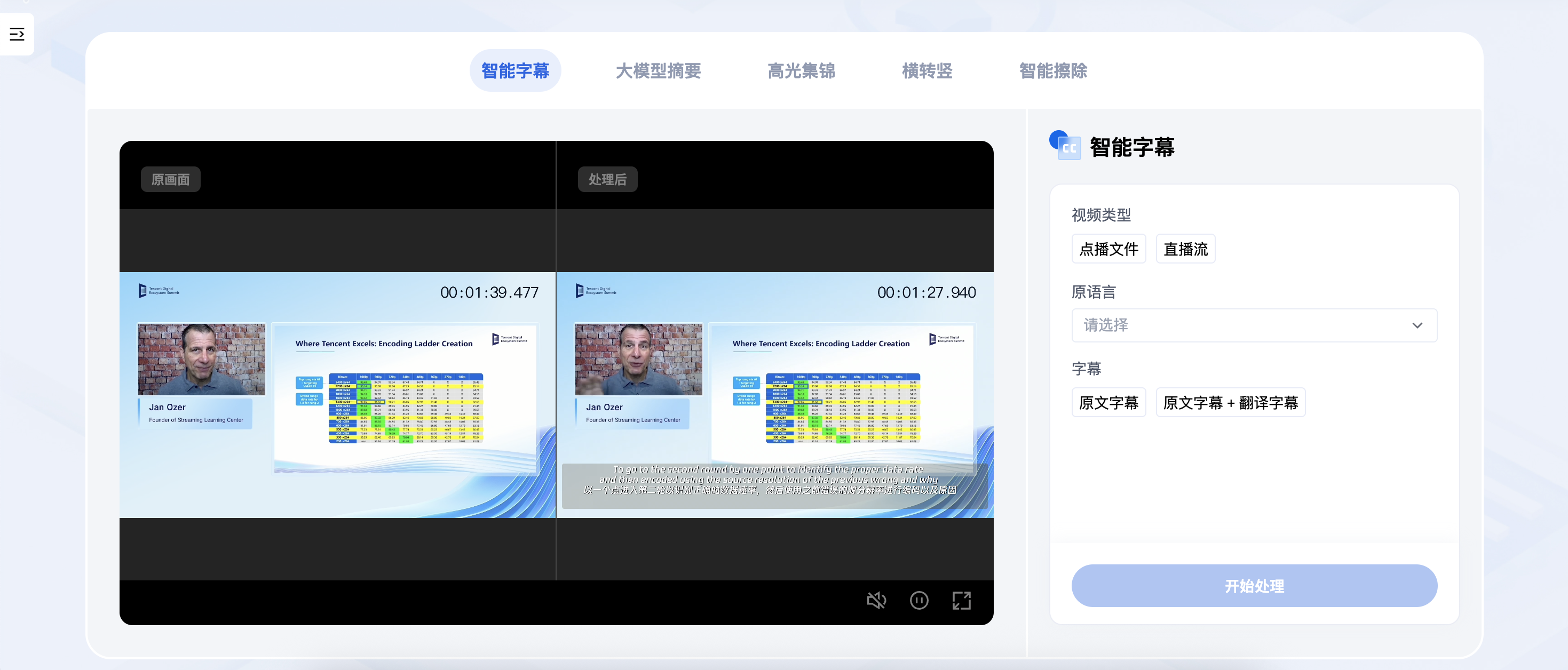
1. 打开 体验馆,进入智能字幕体验页,在右侧选择点播文件或直播流,选择原语言和字幕类型,单击开始处理。
2. 等待处理完成后即可查看结果。
说明:
体验馆功能较简单,仅用于体验基础效果,测试完整效果请使用 API 接入。
场景一:处理离线文件
方式一:控制台零代码发起任务
手动发起任务
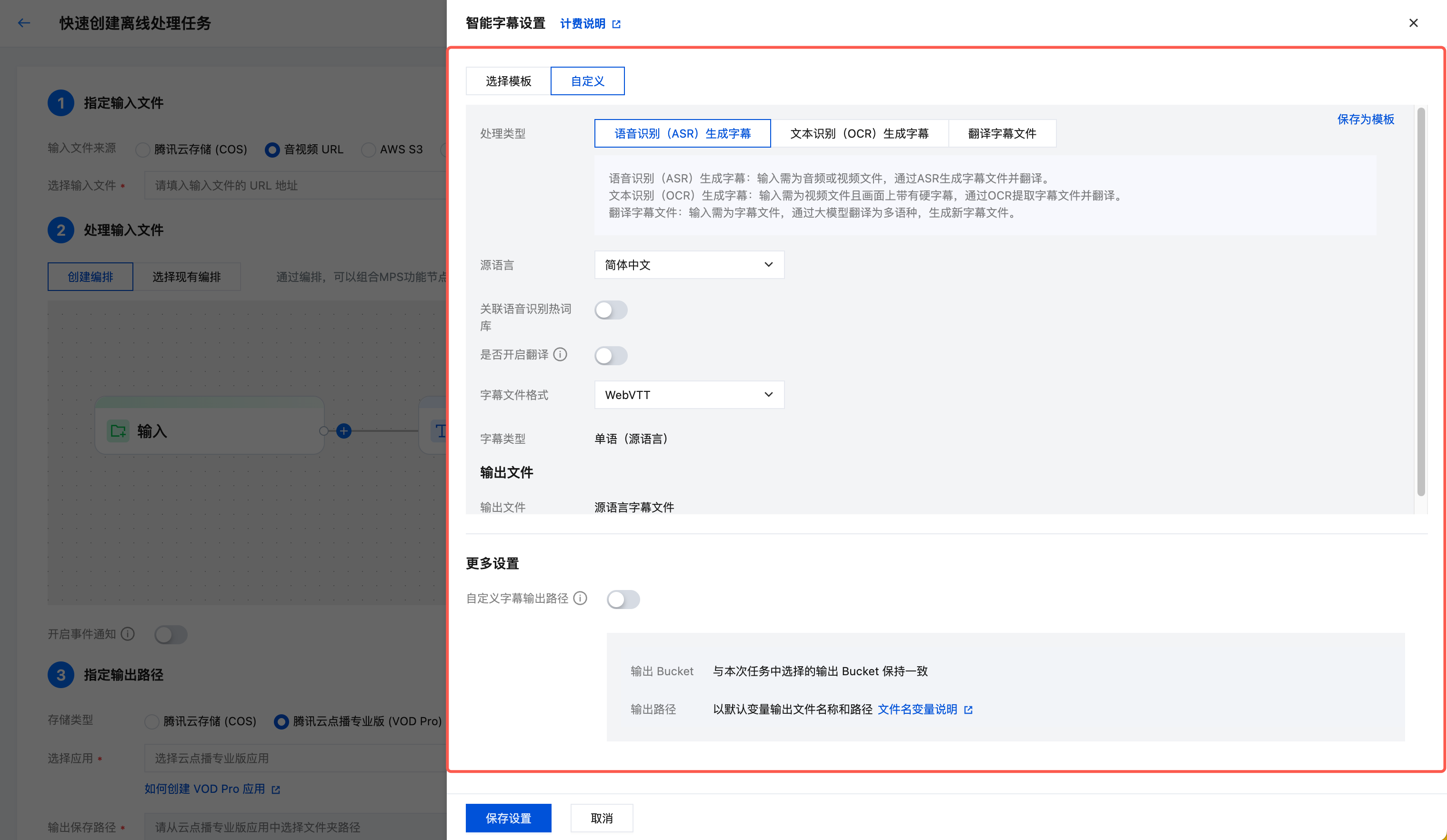
1. 指定输入文件
您可以选择腾讯云 COS 存储桶中的视频文件,或提供视频下载 URL。当前字幕生成及翻译功能暂不支持以 AWS S3 为输入文件来源。
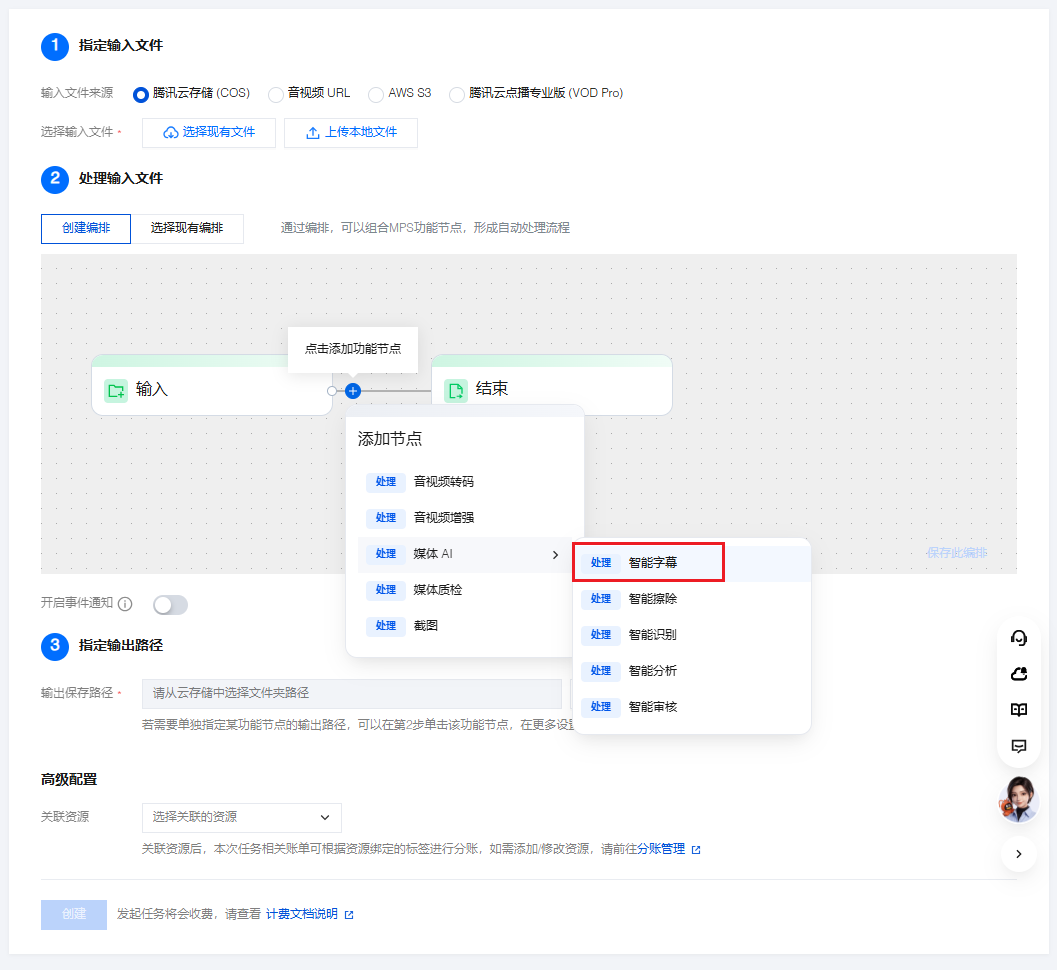
2. 处理输入文件
选择创建编排,插入“智能字幕”节点。
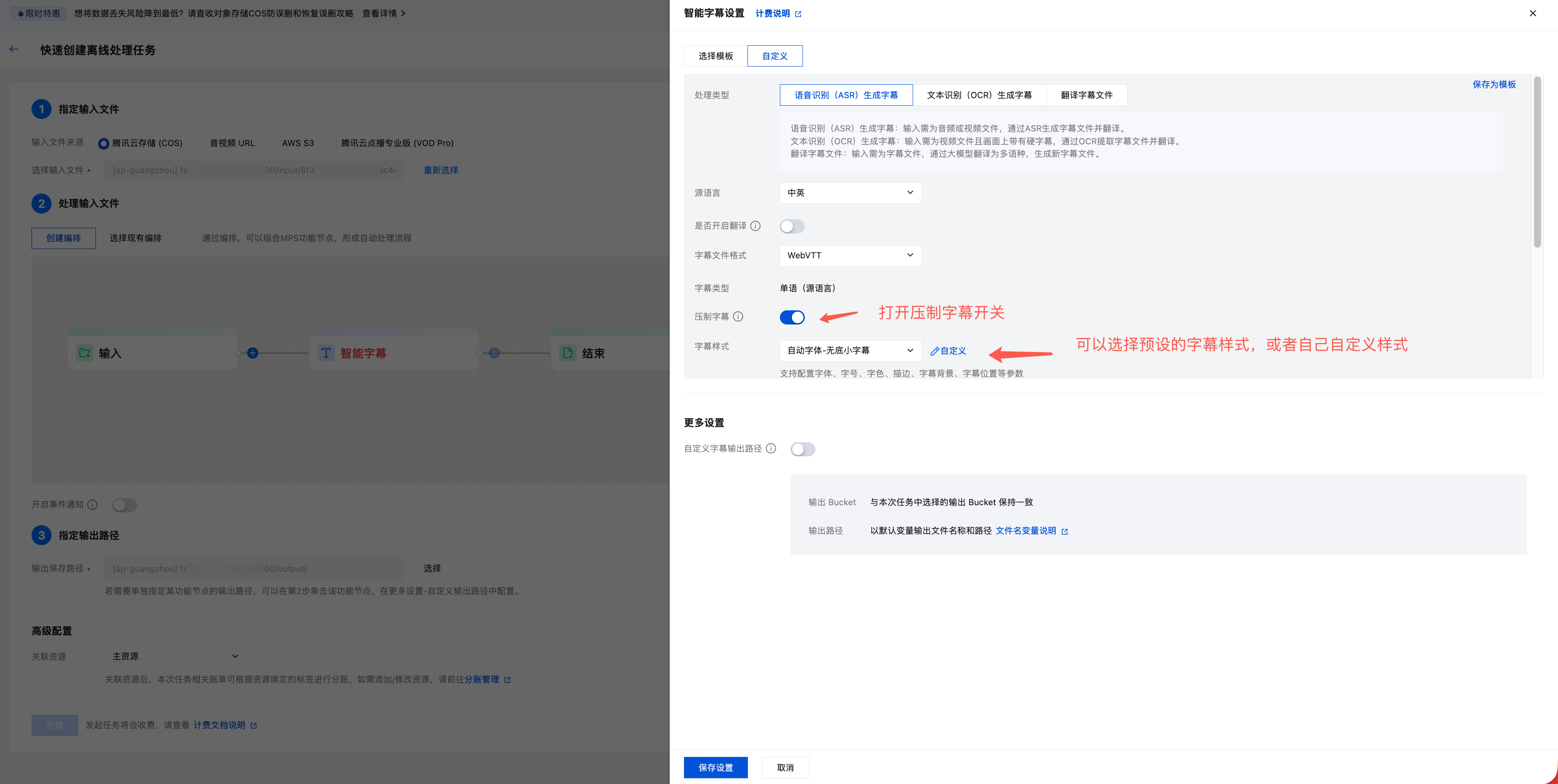
3. 将字幕压制到视频(可选)
模板中支持开启“压制字幕”,配置字幕样式。
4. 指定输出路径
指定输出文件的保存路径。
5. 发起任务
单击创建,发起任务。
通过编排自动触发任务
若您希望实现:在 COS 桶指定路径下上传了新视频文件,自动按照预设参数对新视频文件进行智能字幕处理。您可以:
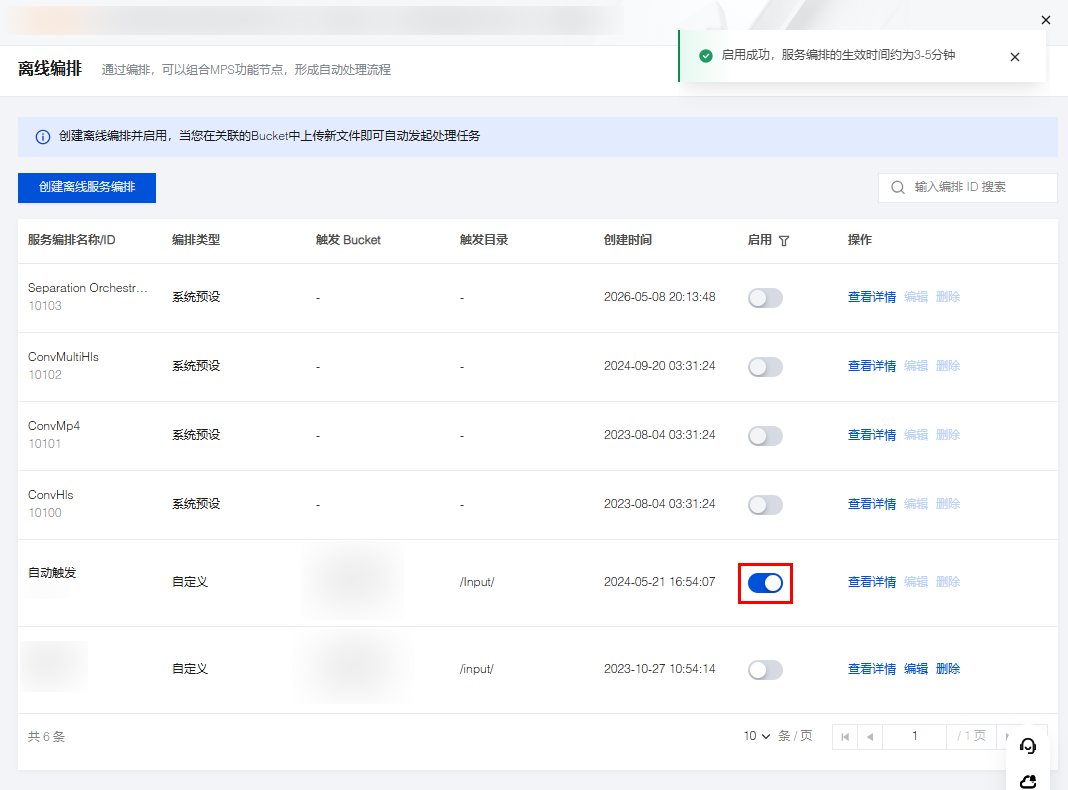
1. 进入菜单离线编排,单击创建离线服务编排,任务配置选择智能字幕节点,并配置触发 Bucket、触发目录等参数。
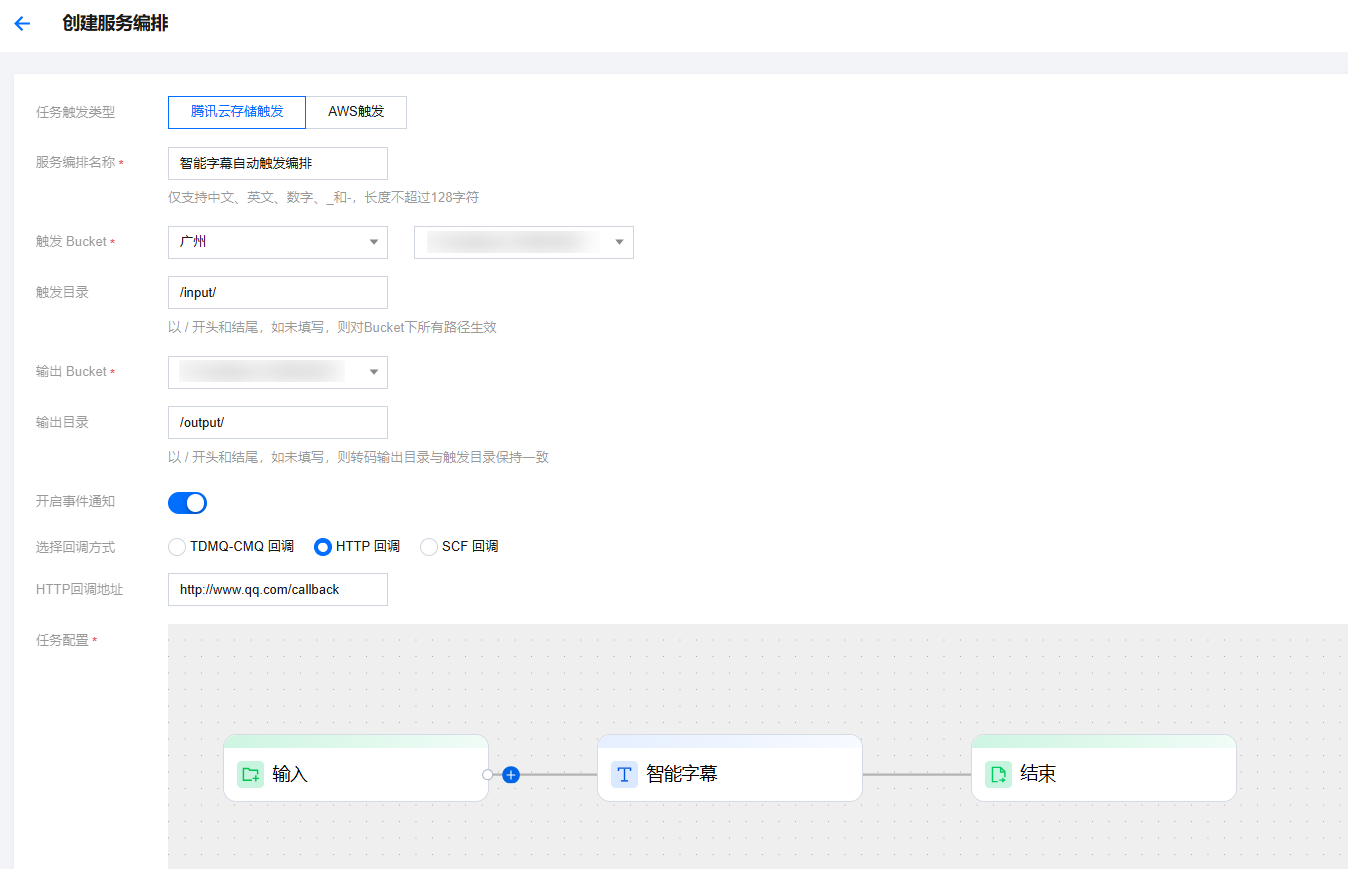
2. 创建后,进入离线编排列表,找到刚创建好的编排,在启动处开启按钮即可。后续在触发目录下新增的视频文件,将自动按照该编排预设的流程和参数发起任务,并将处理后的视频文件保存到编排配置的输出路径中。
注意:
启用编排成功后,需要3-5分钟才会生效。
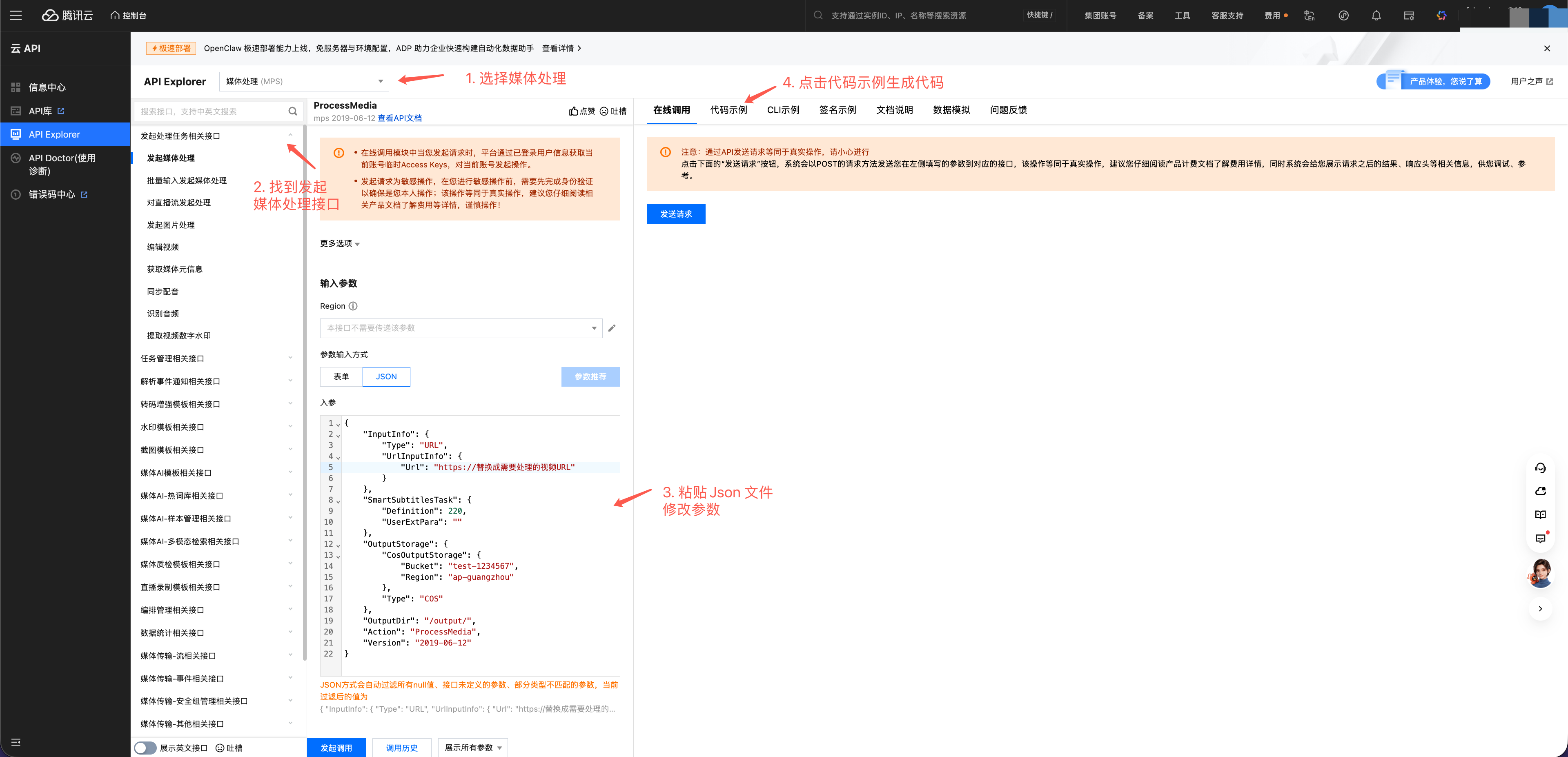
方式二:API 接口调用
{"InputInfo": {"Type": "URL","UrlInputInfo": {"Url": "https://替换成需要处理的视频URL"}},"SmartSubtitlesTask": {"Definition": 220,"UserExtPara": ""},"OutputStorage": {"CosOutputStorage": {"Bucket": "test-1234567","Region": "ap-guangzhou"},"Type": "COS"},"OutputDir": "/output/","Action": "ProcessMedia","Version": "2019-06-12"}
说明:
点击参数输入方式下方的 JSON,将上方的 JSON 代码复制后,粘贴到输入框中。然后再次点击参数输入方式下面的表单,JSON 会自动填充到表单中的对应参数。之后只需要修改少量的参数就可以直接调用,或者点击代码实例,即可生成各种语言与 SDK 下的代码。
{"InputInfo": {"Type": "COS","CosInputInfo": {"Bucket": "test-1234567","Region": "ap-guangzhou","Object": "/video/123.mp4"}},"ScheduleId": 12345, //替换为自定义编排ID,12345为填写示例,不具备实际意义"Action": "ProcessMedia","Version": "2019-06-12"}
说明:
使用扩展参数自定义功能
智能字幕提供各种自定义的功能,可以通过扩展参数 UserExtPara 生效,扩展参数是序列化后的 JSON 字符串。下面是支持的扩展参数列表:
参数名称 | 参数类型 | 功能描述 | 参考值 |
need_wordlist | int | 是否返回字词时间戳(部分模板不支持,不返回),默认不返回。 1:返回字词时间戳。 | 1 |
accurate_mode | int | 是否开启精准模式,精准模式是一个可选项,提供更加精准的时间戳,默认不开启。 1:开启精准模式。 | 1 |
adapt_words | string | 腾讯云|10,媒体处理|10 |
以上能力没有特殊说明,可以同时开启。
将字幕压制到视频(可选能力)
智能字幕模板现在支持绑定压制模板,直接将识别到的字幕压制到视频画面上。在控制台创建压制模板,根据需要自定义字幕样式。
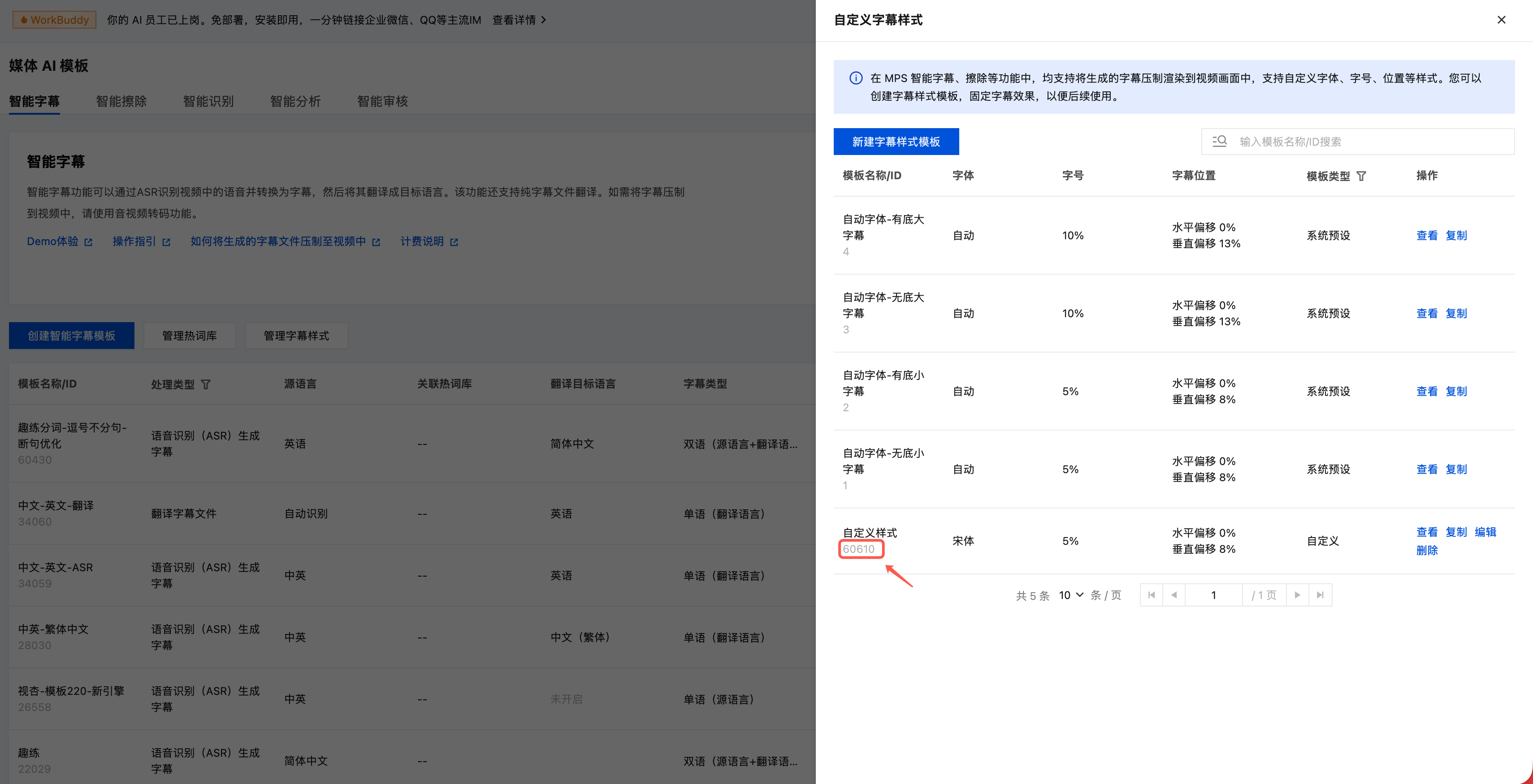
创建字幕样式模板
1. 进入控制台的模板管理 > 媒体 AI 模板 > 智能字幕 页面,单击管理字幕样式,然后在右侧弹出页面继续单击新建字幕样式模板并完成创建。
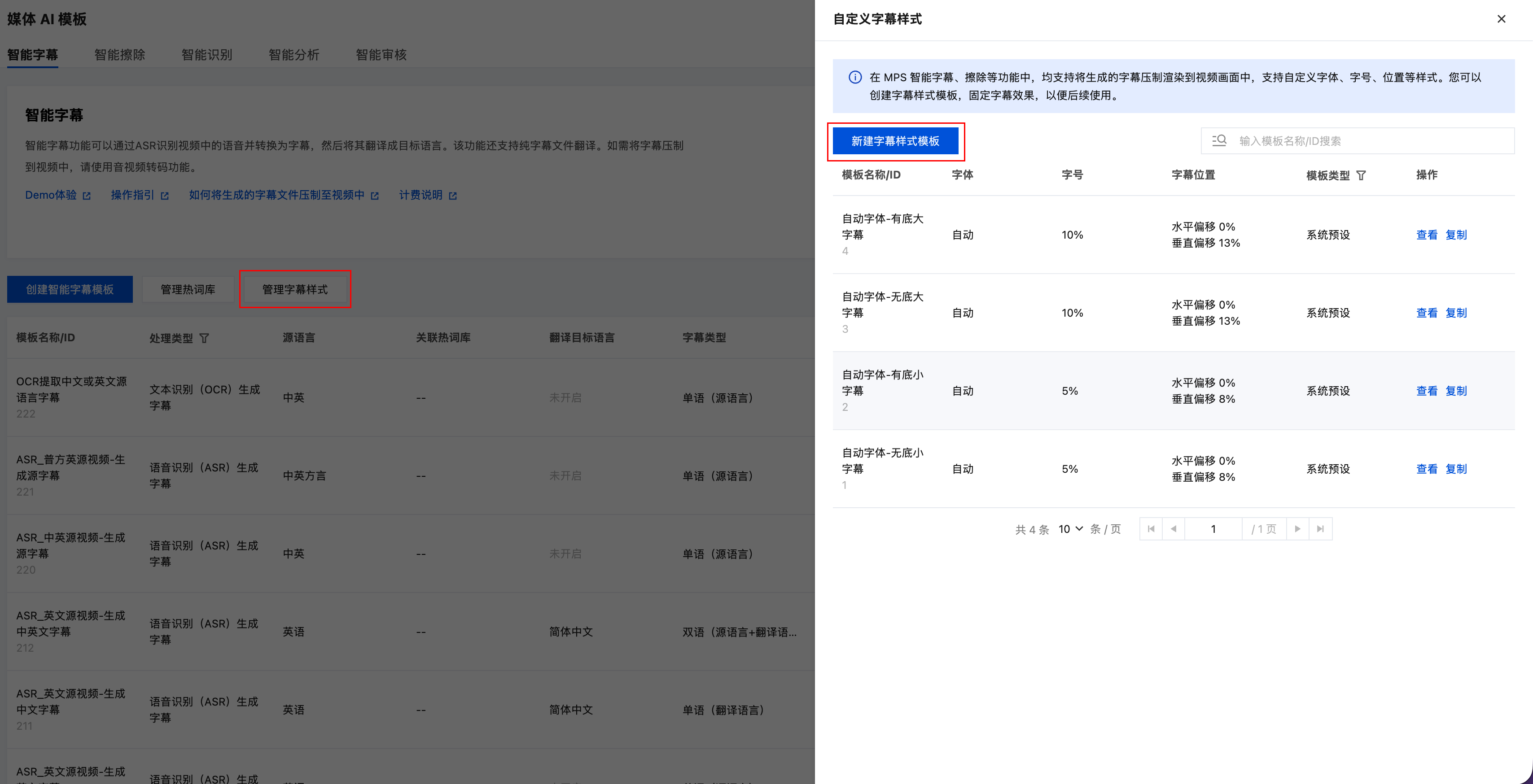
2. 复制新建的字幕样式模板 ID。
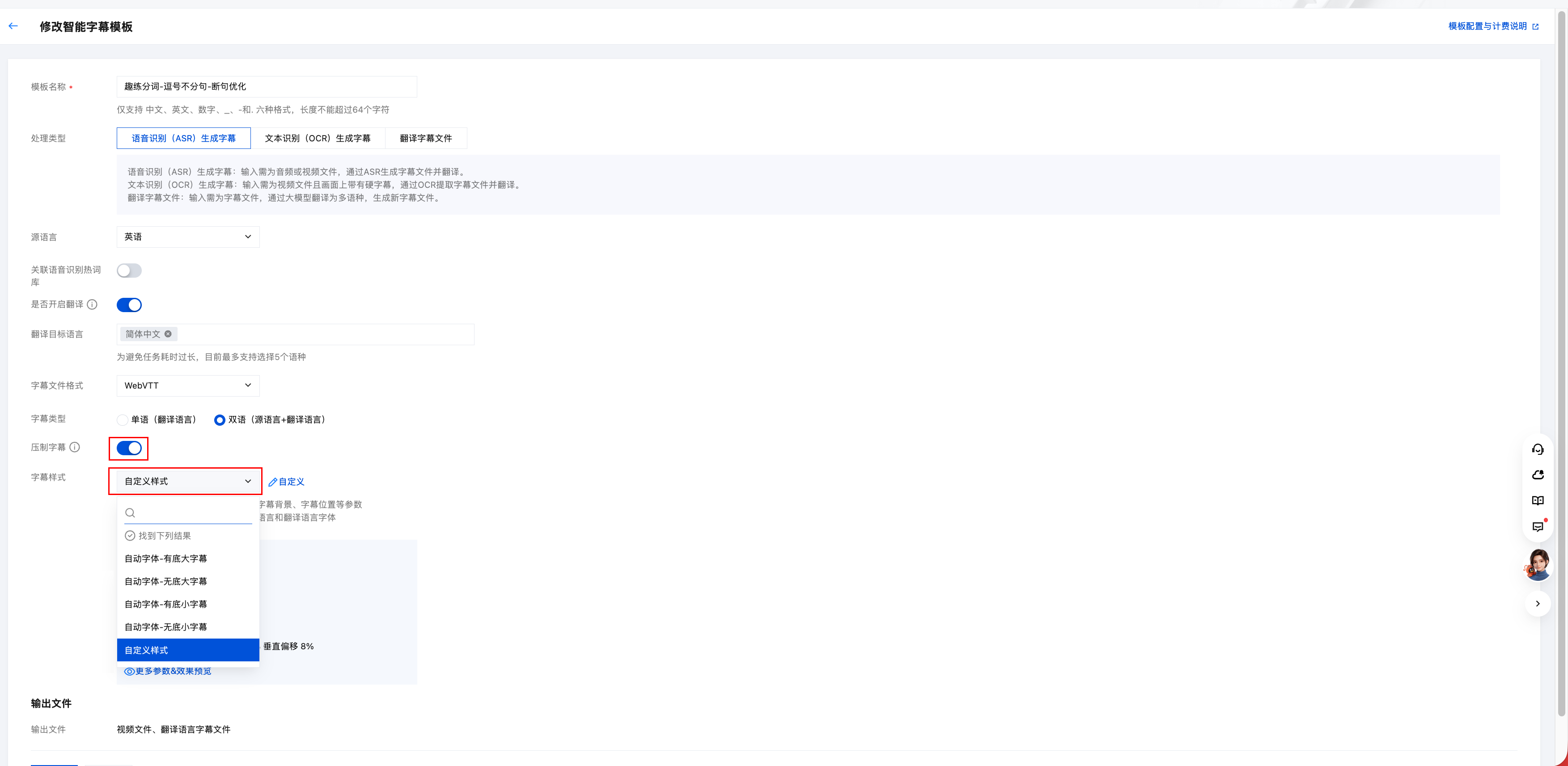
将字幕样式模板绑定到字幕模板
对目标字幕模板进行编辑时,开启“压制字幕”的开关,选择创建的字幕样式完成修改。
查询任务结果
控制台查询任务
1. 进入控制台 离线任务管理,任务列表中会展示刚发起的任务。
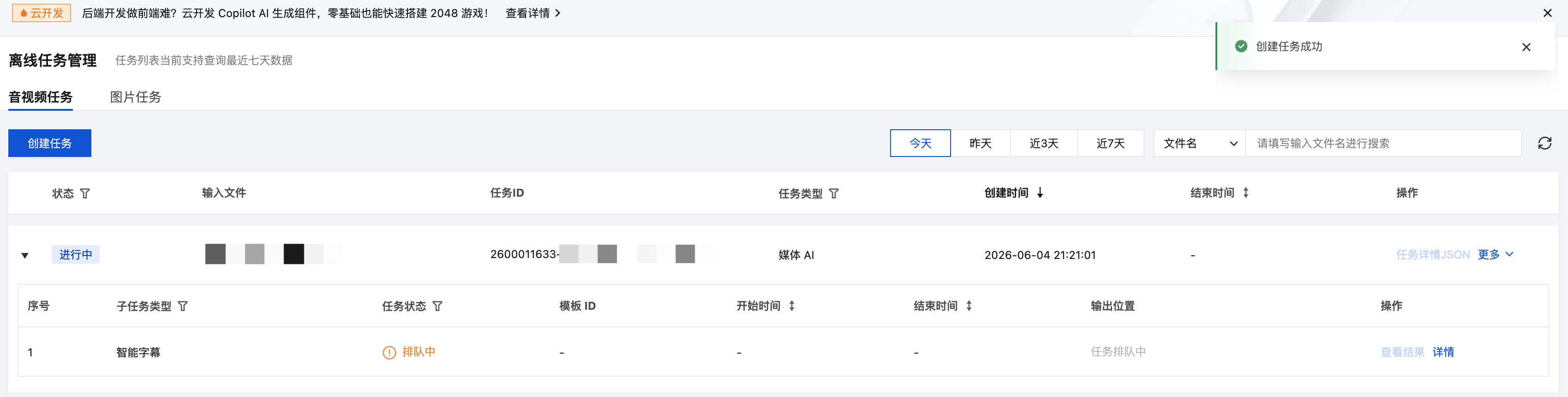
2. 子任务状态为“成功”时,单击查看结果,可以预览字幕样式。

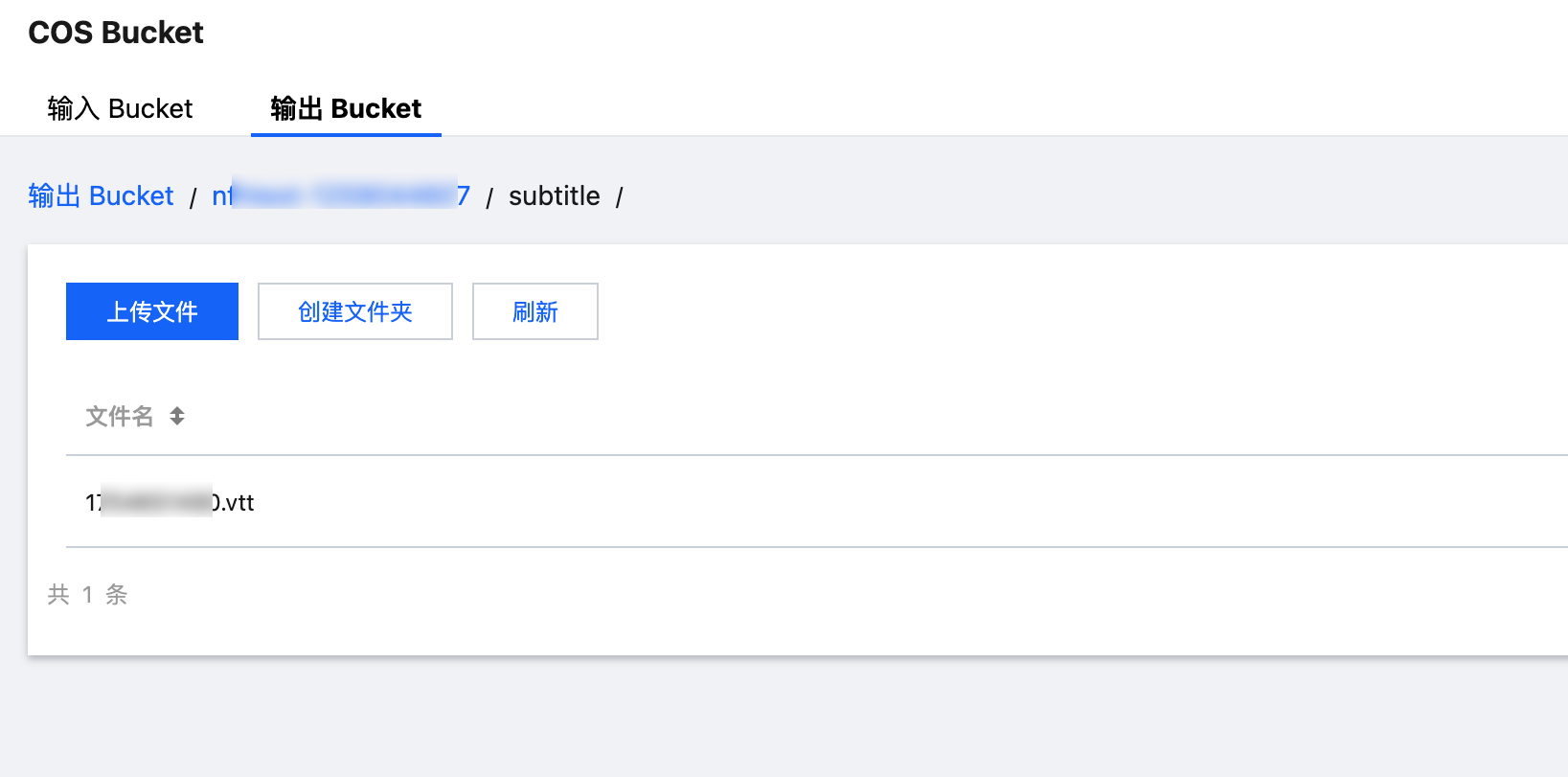
3. 生成的 VTT 字幕文件可以在编排管理 > COS Bucket > 输出 Bucket 中找到。
中文字幕样例:

中英字幕样例:

事件通知回调
在使用 ProcessMedia 发起媒体处理任务时,可以通过
TaskNotifyConfig 参数配置事件回调。当任务处理完成后,会通过配置的回调信息回调任务结果,您可以通过 ParseNotification 解析事件通知结果。调用接口查询任务结果
调用 DescribeTaskDetail 接口,输入任务 ID (例如:24000022-WorkflowTask-b20a8exxxxxxx1tt110253、24000022-ScheduleTask-774f101xxxxxxx1tt110253)查询任务结果,示例如下:
场景二:处理直播流
支持对直播流进行如下智能字幕处理:
智能字幕功能 | 描述 |
语音识别(ASR)生成字幕 | 通过 ASR 语音识别,将对白转换为字幕文件,并进行大模型翻译。 支持将字幕压制渲染到直播流画面中。 |
在直播流中使用字幕及翻译目前有两种方案:云直播控制台开启字幕功能和通过 MPS 回调文本并压制到直播流。建议使用云直播控制台开启字幕功能,方案介绍如下文。
方式一:云直播控制台开启字幕功能
1. 配置直播字幕功能
2. 拉字幕流
说明:
目前字幕展示有两种形式:实时动态字幕和延时稳态字幕。实时动态字幕指实时直播中的字幕会根据语音内容逐字动态校正字幕内容,输出的字幕内容会实时变动;延时稳态字幕指系统会按设定的时间延时展示直播,输出的是整句字幕,观看体验更佳。
方式二:通过 MPS 回调文本
暂不支持使用 MPS 控制台发起直播流智能字幕任务,您可以通过 API 发起。且处理直播流,目前需要通过智能识别模板,通过配置语音识别或语音翻译功能实现字幕生成。
{"Url": "http://5000-wenzhen.liveplay.myqcloud.com/live/123.flv","AiRecognitionTask": {"Definition": 10101 //10101为预设中文字幕模板ID,可替换为您的自定义智能识别模板ID},"OutputStorage": {"CosOutputStorage": {"Bucket": "test-1234567","Region": "ap-guangzhou-2"},"Type": "COS"},"OutputDir": "/test/output/","TaskNotifyConfig": {"NotifyType": "URL","NotifyUrl": "http://xxxx.qq.com/callback/qtatest/?token=xxxxxx"},"Action": "ProcessLiveStream","Version": "2019-06-12"}
场景三:通过 WebSocket 处理私有音频流
在视频会议、双工语音等场景可以通过 WebSocket 协议将音频传给识别翻译服务,然后将结果通过 WebSocket 协议返回。支持单识别、识别并翻译、多路实时音频流同时识别并翻译、实时结果字幕支持稳态、渐变模式。协议参考 WebSocket 识别协议。
代码示例:
#!/usr/bin/env python3# -*- coding: utf-8 -*-import argparseimport structimport timeimport osimport signalimport sysimport hashlibimport hmacimport randomfrom urllib.parse import urlencode, urlunsplit, quoteimport websocketsimport asyncioimport loggingimport json# Setup logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)class AudioPacket:def __init__(self, format=1, is_end=False, timestamp=0, audio_src_id="123456", ext_data=b'', data=b''):self.format = formatself.is_end = is_endself.timestamp = timestampself.audio_src_id = audio_src_idself.ext_data = ext_dataself.data = datadef marshal(self):"""Serialize audio packet to binary format"""header = struct.pack('>BBQH',self.format,1 if self.is_end else 0,self.timestamp,len(self.audio_src_id))audio_src_bytes = self.audio_src_id.encode('utf-8')ext_len = struct.pack('>H', len(self.ext_data))return header + audio_src_bytes + ext_len + self.ext_data + self.datadef sha256hex(s):"""Calculate SHA256 hex digest"""if isinstance(s, str):s = s.encode('utf-8')return hashlib.sha256(s).hexdigest()def hmacsha256(s, key):"""Calculate HMAC-SHA256"""if isinstance(s, str):s = s.encode('utf-8')if isinstance(key, str):key = key.encode('utf-8')return hmac.new(key, s, hashlib.sha256).digest()def generate_random_number(digits):"""Generate random number with specified digits"""low = 10 ** (digits - 1)high = (10 ** digits) - 1return random.randint(low, high)def generate_url_v3(args):"""Generate WebSocket URL with TC3-HMAC-SHA256 signature"""query_params = {}if args.dstLang:query_params["transSrc"] = args.langquery_params["transDst"] = args.dstLangelse:query_params["asrDst"] = args.langquery_params["fragmentNotify"] = "1" if args.frame else "0"query_params["timeoutSec"] = str(args.timeout)timestamp = int(time.time())expire_timestamp = timestamp + 3600query_params["timeStamp"] = str(timestamp)query_params["expired"] = str(expire_timestamp)query_params["secretId"] = args.secretIdquery_params["nonce"] = str(generate_random_number(10))# Sort keys and build canonical query stringsorted_keys = sorted(query_params.keys())canonical_query = "&".join(["{}={}".format(k, quote(query_params[k], safe=''))for k in sorted_keys])# Build canonical requestpath = "/wss/v1/{}".format(args.appid)http_method = "post"canonical_uri = pathcanonical_headers = "content-type:application/json; charset=utf-8\\nhost:{}\\n".format(args.addr)signed_headers = "content-type;host"canonical_request = "{}\\n{}\\n{}\\n{}\\n{}\\n".format(http_method,canonical_uri,canonical_query,canonical_headers,signed_headers,)# Build string to signdate = time.strftime("%Y-%m-%d", time.gmtime(timestamp))credential_scope = "{}/mps/tc3_request".format(date)hashed_canonical = sha256hex(canonical_request)algorithm = "TC3-HMAC-SHA256"string_to_sign = "{}\\n{}\\n{}\\n{}".format(algorithm,timestamp,credential_scope,hashed_canonical)# Calculate signaturesecret_date = hmacsha256(date, "TC3" + args.secretKey)secret_service = hmacsha256("mps", secret_date)secret_signing = hmacsha256("tc3_request", secret_service)signature = hmac.new(secret_signing,string_to_sign.encode('utf-8'),hashlib.sha256).hexdigest()# Add signature to query paramsquery_params["signature"] = signature# Build final URLscheme = "wss" if args.ssl else "ws"url = urlunsplit((scheme,args.addr,path,urlencode(query_params),""))return urlasync def receive_messages(websocket, stop_event):"""Handle incoming WebSocket messages"""try:while not stop_event.is_set():message = await websocket.recv()if isinstance(message, bytes):try:message = message.decode('utf-8')except UnicodeDecodeError:message = str(message)logger.info("Received: %s", message)except Exception as e:logger.info("Connection closed: %s", e)async def run_client():parser = argparse.ArgumentParser()parser.add_argument("--addr", default="mps.cloud.tencent.com", help="websocket service address")parser.add_argument("--file", default="./wx_voice.pcm", help="pcm file path")parser.add_argument("--appid", default="121313131", help="app id")parser.add_argument("--lang", default="zh", help="language")parser.add_argument("--dstLang", default="", help="destination language")parser.add_argument("--frame", action="store_true", help="enable frame notify")parser.add_argument("--secretId", default="123456", help="secret id")parser.add_argument("--secretKey", default="123456", help="secret key")parser.add_argument("--ssl", action="store_true", help="use SSL")parser.add_argument("--timeout", type=int, default=10, help="timeout seconds")parser.add_argument("--wait", type=int, default=700, help="wait seconds after end")args = parser.parse_args()url = generate_url_v3(args)logger.info("Connecting to %s", url)try:# Python 3.6 compatible websockets connectionwebsocket = await websockets.connect(url, ping_timeout=5)# Handle initial responseinitial_msg = await websocket.recv()try:result = json.loads(initial_msg)if result.get("Code", 0) != 0:logger.error("Handshake failed: %s", result.get("Message", ""))returnlogger.info("TaskId %s handshake success", result.get("TaskId", ""))except ValueError: # json.JSONDecodeError not available in 3.6logger.error("Invalid initial message")return# Setup signal handlerloop = asyncio.get_event_loop()stop_event = asyncio.Event()loop.add_signal_handler(signal.SIGINT, stop_event.set)# Start receiverreceiver_task = asyncio.ensure_future(receive_messages(websocket, stop_event))# Audio processingtry:with open(args.file, "rb") as fd:PCM_DUR_MS = 40pcm = bytearray(PCM_DUR_MS * 32)pkt = AudioPacket(data=pcm)is_end = Falsewait_until = 0while not stop_event.is_set():if is_end:if time.time() > wait_until:logger.info("Finish")breakawait asyncio.sleep(0.1)continue# Read PCM datan = fd.readinto(pkt.data)if n < len(pkt.data):pkt.is_end = Trueis_end = Truewait_until = time.time() + args.wait# Send audio packetawait websocket.send(pkt.marshal())logger.info("Sent ts %d", pkt.timestamp)pkt.timestamp += n // 32await asyncio.sleep(PCM_DUR_MS / 1000)except IOError: # FileNotFoundError not available in 3.6logger.error("Open file error: %s", args.file)return# Cleanupawait asyncio.wait_for(receiver_task, timeout=1)await websocket.close()except Exception as e:logger.error("Connection error: %s", e)returnif __name__ == "__main__":# Python 3.6 compatible asyncio runnerloop = asyncio.get_event_loop()try:loop.run_until_complete(run_client())finally:loop.close()



