【 文智背后的奥秘 】系列篇:关键词智能提取
原创

一.关键词自动标注简介
1.关键词自动标注
关键词是指能反映文本主题或者意思的词语,如论文中的Keyword字段。大多数人写文章的时候,不会像写论文的那样明确的指出文章的关键词是什么,关键词自动标注任务正是在这种背景下产生的。
目前,关键词自动标注方法分为两类:1)关键词分配,预先定义一个关键词词库,对于一篇文章,从词库中选取若干词语作为文章的关键词;2)关键词抽取,从文章的内容中抽取一些词语作为关键词。
2.应用场景
在文献检索初期,由于当时还不支持全文搜索,关键词就成为了搜索文献的重要途径。随着网络规模的增长,关键词成为了用户获取所需信息的重要工具,从而诞生了如Google、百度等基于关键词的搜索引擎公司。
关键词自动标注技术在推荐领域也有着广泛的应用。如图1所示,当用户阅读图中左边的新闻时,推荐系统可以给用户推荐包含关键词”Dropbox”、”云存储”的资讯,同时也可以根据文章关键词给用户推荐相关的广告。

图1基于关键词的资讯推荐系统
关键词可以作为用户兴趣的特征,从而满足用户的长尾阅读兴趣。传统的信息订阅系统一般使用类别或者主题作为订阅的内容,如图2所示。如果用户想订阅更细粒度的内容,这类系统就无能为力了。关键词作为一种对文章更细粒度的描述,刚好可以满足上述需求。
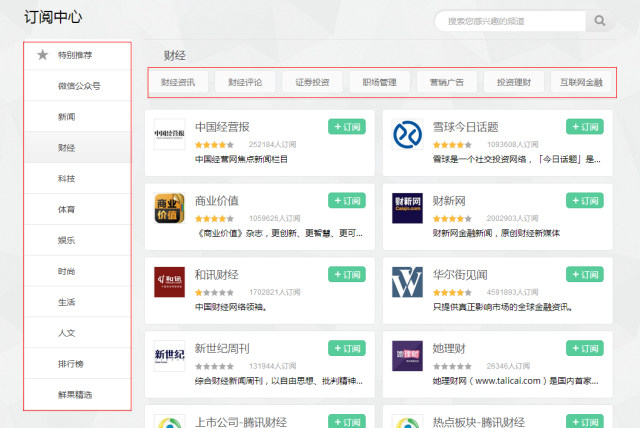
图2传统的订阅系统
除了这些以外,关键词还在文本聚类、分类、摘要等领域中有着重要的作用。比如在聚类时,将关键词相似的几篇文章看成一个类团可以大大提高K-means聚类的收敛速度。从某天所有新闻中提取出这些新闻的关键词,就可以大致知道那天发生了什么事情。或者将某段时间中几个人的微博拼成一篇长文本,然后抽取关键词就可以知道他们主要在讨论些什么话题。
3.现有问题与挑战
文章的关键词通常具有以下三个特点[1]:
- 可读性。关键词本身应该是有意义的词或者短语。例如,“我们约会吧”是有意义的短语,而“我们”则不是。
- 相关性。关键词必须与文章的主题相关。例如,一篇介绍巴萨在德比中输给皇马的新闻,其中可能顺带提到了“中超联赛”这个关短语,这时就不希望这个短语被选取作为该新闻的关键词。
- 覆盖度。关键词集合能对文章的主题有较好的覆盖度,不能只集中在文章的某个主题而忽略了文章的其他主题。
从上述三个特点,可以看到关键词标注算法的要求以及面临的挑战:
a.新词发现以及短语识别问题,怎样快速识别出网络上最新出现的词汇(人艰不拆、可行可珍惜…)?
b.关键词候选集合的问题,并不是文章中所有的词语都可以作为候选
c.怎么计算候选词和文章之间的相关性?
d.如何覆盖文章的各个主题?
关键词分配算法需要预先定义一个关键词词库,这就限定了关键词候选范围,算法的可扩展性较差,且耗时耗力;关键词抽取算法是从文章的内容中抽取一些词语作为标签词,当文章中没有质量较高的词语时,这类方法就无能为力了。为了解决上述这些问题和挑战,我们设计了层次化关键词自动标注算法.
二.层次化关键词自动标注算法
1.层次化关键词体系
针对新闻的关键词识别任务,我们设计了一套层次化的关键词体系,如图3所示。第一层是新闻频道(体育、娱乐、科技、etc),第二层是新闻的主题(一篇新闻可以包含多个主题),第三次是文章中出现的标签词。
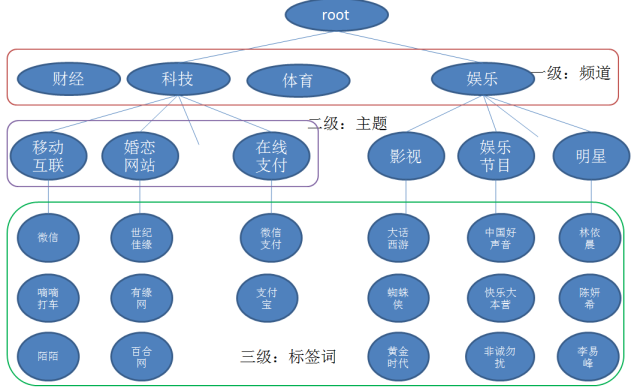
图3层次化关键词体系
三层关键词体系有以下几个优点:
- 三层关键词体系从不同角度描述文章所表达的内容,从而能让标注结果能更好地覆盖文章的各个主题,缓解了关键词覆盖度不够的问题。
- 由于各层之间有隶属关系,利用这种关系,可以抽取出更相关的关键词,如:“非诚勿扰”在娱乐新闻中可能是指娱乐节目或者电影,可以作为一个关键词;如果是出现在汽车新闻中,则不太可能是文章的关键词。
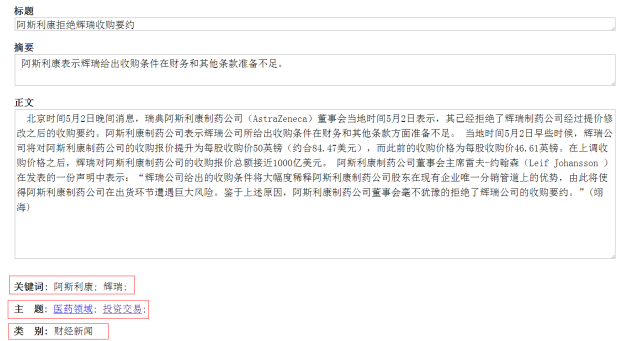
图4层次化关键词自动标注结果示例
2.算法流程
从图3中可以看出,主题和标签词依赖于新闻频道,所以在标注一篇新闻的关键词时,首先需要获取新闻的类别,然后根据新闻的类别选择不同的主题模型预测新闻的主题,最后再抽取新闻中的标签词。
在关键词标注方法上,我们融合了关键词分配和关键词抽取两类方法。图5描述了算法处理一篇文章的流程。其中频道和主题的抽取方法属于关键词分配这一类算法,标签词抽取则属于关键词抽取这一类算法。除了上一节中所说的层次化关键词的两个优点之外,我们的算法有如下几点好处:
- 关键词分配算法有效缓解关键词抽取算法召回不足的问题。
- 在关键词分配算法中,使用频道和主题代替传统的关键词,从而减少词库构建成本、增强算法的可移植性。

图5层次化关键词自动标注算法流程
2.1 文本分类器
文本分类器我们采用最大熵模型[2],使用业务最近一年带频道标签的新闻作为训练集。每个频道选取频道相关度最高的1W个词语作为分类特征。
对于最大熵模型,网上可以找到很多相关资料,这里就不作介绍了。
2.2 主题预测
使用LDA[3]作为主题聚类模型。LDA开源的大部分开源实现都是单进程的,在处理较大规模的语料时,其时间和内存开销都非常大,无法满足我们的要求。因此我们实现了一套分布式的LDA平台,使得能够快速处理大规模的数据。
语料通过LDA平台处理后,会得到每个主题下概率较高的词语。人工选取质量较高的主题,并使用一个词语或者短语概括这个主题。对于一篇文章,LDA的inference结果是一个概率向量,我们选取概率值大于阈值的主题作为文章所属的主题。
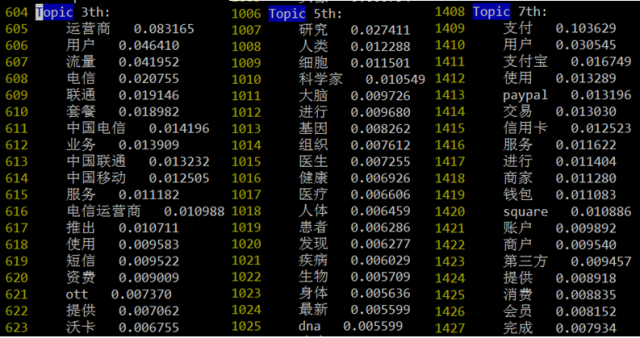
图6高质量的主题
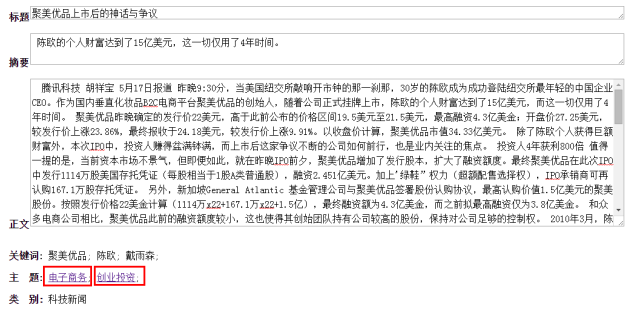
图7文章的主题关键词
2.3 标签词抽取
标签词抽取包括:生成候选词和相关性计算。下面分别介绍这两部分。
1)生成候选词
通过分词得到的基本词、短语等,过滤掉基本词中的停用词
命名实体(有效解决新词、热词的自动发现)
2)相关性计算
使用线性加权对候选词打分,其特征包括:
- TF*IDF
- 候选词和文章频道的相关程度
- 候选词和文章的相似度
- 候选词的长度
- 候选词出现的位置
- 候选词的类型(基本词、实体类型、短语等)
选取相关性得分大于阈值的候选词作为文章的标签词。
3.效果评价
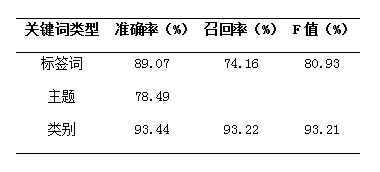
在腾讯网上随机抽取的351篇新闻上做测试,各项指标如表格1所示。由于主题集合的开放性,其召回率很难评价,故只评价其准确率。
表格1 层次化关键词自动标注算法准召率
三.接入业务与展望
对抽取错误的关键词进行分析,算法还存在一些问题,后续会针对这些问题继续改进。
- 泛义词过滤不彻底,后续需要继续优化候选词过滤模块。
- 抽取出来的两个关键词可能是表述同一个语义,后续引入同义词等资源解决。
目前已经接入的公司业务有:腾讯新闻客户端、手机Qzone个性化资讯。欢迎有需求的团队联系我们,使用腾讯文智自然语言处理。
参考文献
[1] 刘知远. 基于文档主题结构的关键词抽取方法研究[D]. 北京: 清华大学, 2011. [2] Berger A L, Pietra VJ D, Pietra S A D. A maximum entropy approach to natural languageprocessing[J]. Computational linguistics, 1996, 22(1): 39-71. [3] Blei D M, Ng A Y,Jordan M I. Latent dirichlet allocation[J]. the Journal of machine Learning research,2003, 3: 993-1022.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号