软硬件融合技术内幕 进阶篇 (12) —— PDF小作文的主角
软硬件融合技术内幕 进阶篇 (12) —— PDF小作文的主角

在前几期,我们简要介绍了SmartNIC的几种实现,以及Mellanox和Intel的实现思路。
但是,各大云厂商对于SmartNIC的实现,也有自己的想法。
实际上,SmartNIC思路的提出,是云计算的先驱者——AWS。2013年,AWS开始研发自己的Nitro,其思路是利用SmartNIC实现统一的网卡驱动,并在网卡内部实现VPC的接入、VM路由选路等网络处理,而不是用CPU软件模拟。
当时光流转到2022年,Nitro已经进化为一个体系结构,并被拆分为三个部分:
- Nitro Card,安装在每台计算机上的Smart Nic,实现Virtio-net, Virtio-blk以及NVMe等功能;
- Nitro Security,实际上是取代服务器的TPM,嵌入到服务器主板上,提供系统启动的信任根;
- Nitro Hypervisor,将KVM的Hypervisor功能卸载到专用硬件;
有意思地是,AWS把1和3拆分,并单独设立了3,其架构如下图:

图中,Nitro Hypervisor管理了一个Nitro集群。AWS的官方文档宣称,采用AWS Nitro Hypervisor后,虚拟机的性能可以和物理机相当,也就是说,Hypervisor几乎不会占用宿主机的CPU资源。
那么,AWS Nitro Hypervisor到底是如何做到的呢?
让我们回顾一下前期对虚拟化技术的小结。
在Intel发明了VT-X技术后,虚拟机GuestOS及应用层的所有指令都不需要修改,硬件能够处理以下几种情况:
- 内核运行在ring0时,特权指令和敏感指令的特殊处理,使之不影响物理机的状态;
- 虚拟机GuestOS看到的内存地址 (GLA)映射为虚拟机的硬件地址(GPA)后,可以正确转换为物理机内存地址HPA;
- 将来自IO设备的中断通过vAPIC硬件,重新定向到虚拟机所在的Hyperthread上;
这样看来,如果每个VM绑定了自己所在的Hyperthread,实际上,Hypervisor本身不会对虚拟机的运行效率造成太大损耗,唯一与真实硬件服务器产生性能差异的地方在于,VirtIO设备的后端驱动。而SmartNIC实现Virtio offload后,这一点差异也能够抹平了。
那么,所谓Hypervisor Offload指的具体是什么呢?
原来,在大规模的公有云上,大部分虚拟机是“超卖”的。
所谓的超卖,也就是像时间管理大师那样,把QEMU的多个线程调度到一个物理HT上,让的时间片分给多个VM视角的vCPU。由于Hypervisor所在的HostOS可以通过时间片分配的方式,把一个HT调度给多个QEMU线程,在VM看来,就拥有了多个独立的vCPU。
然而,随着系统压力的上升,最终,罗姓男明星的黑眼圈,出卖了他“时间管理大师”的本质,并且使得他成为了PDF的主角。
一样,在系统压力上升的时候,这样超分出来的VM,其性能会比非超分的VM有显著的差异。因此,在这种时候,为了充分发挥宿主机上的计算资源效能,Hypervisor需要将挤在繁忙的HT上的VM,调度到较为空闲的HT上。
本来是这样:(每种颜色代表一个VM)
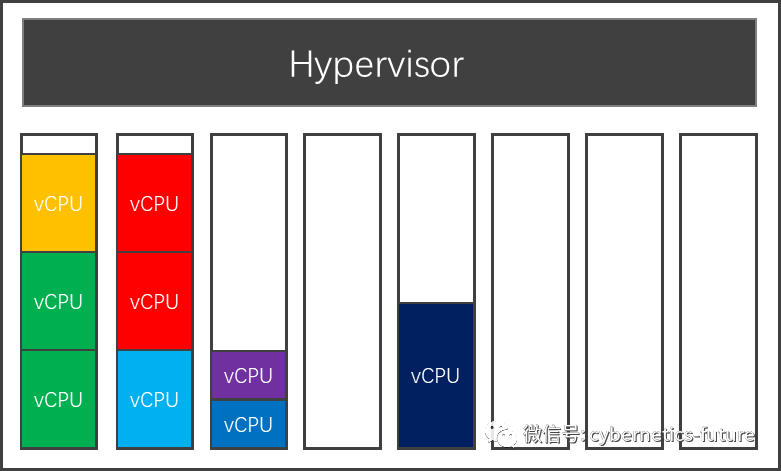
如图,最左边两个HT的占有率较高,而其他HT大部分空闲,这时候,HostOS会进行调度:

这样,每个VM即使接受的业务压力继续上升,也不会出现显著的性能下降。只要不是所有的VM都在承受过大的压力,公有云服务商就不会被用户发现“时间管理大师”的行为。
但是,这种调度对hypervisor是有一定压力的。由于每个VM的VirtIO设备在工作时,需要通过中断的方式让CPU感知到数据包的抵达,或磁盘IO的完成等,因此,如果我们将VM的vCPU调度到其他HT上,就需要让VirtIO设备能够将中断送到对应的HT上。
进一步地,在AWS中,如果部分宿主机上的EC2超分实例过于繁忙,也有可能迁移到其他相对空闲的宿主机上。我们知道,VM迁移的工作包括内存拷贝、脏内存标记复制、块存储重新挂载、VirtIO-net状态迁移等一系列工作。这些都需要Hypervisor进行操作。
所谓的Hypervisor卸载,实质上就是在Nitro Hypervisor的指挥下,让Nitro Card执行Hypervisor的功能,如下图:
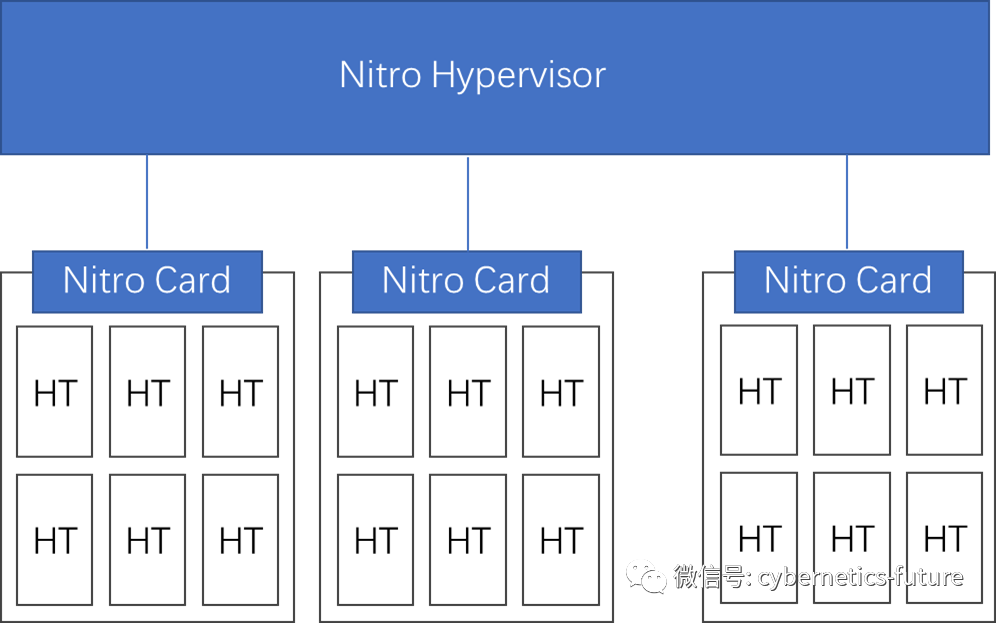
图中,Nitro Hypervisor视角下,若干台Nitro Card宿主机组成一个资源池。在每个Nitro Card看来,宿主机上所有的HT都是自己可以调度的资源。这样一来,整个资源池就变成了一个AMP(非对称多处理)架构的多处理器系统。与常见的基于Linux等操作系统的SMP处理架构相比,AMP将控制平面与数据平面分离,Nitro Hypervisor和Nitro Card充当所谓的控制平面,同时Nitro Card还负责部分数据平面IO快速路径功能(类似上期),而各宿主机CPU的HT只作为数据平面,按照控制平面的要求工作即可。
在Nitro Hypervisor的帮助下,AWS上虚拟机的性能大大接近了物理机的性能,节约了虚拟化的开销,还可以避免“时间管理大师”暴露,成为PDF小作文的主角的风险。
然而,另一个问题逐渐浮出了水面。是什么问题呢?请看下期。
腾讯云开发者
