知识图谱项目实战(一):瑞金医院MMC人工智能辅助构建知识图谱--初赛实体识别【1】

知识图谱项目实战(一):瑞金医院MMC人工智能辅助构建知识图谱--初赛实体识别【1】

汀丶人工智能
发布于 2022-12-21 16:27:05
发布于 2022-12-21 16:27:05
1.技术背景&赛题介绍:
A Labeled Chinese Dataset for Diabetes中文糖尿病标注数据集详情请见。
数据集链接:瑞金医院MMC人工智能辅助构建知识数据源:知识图谱构建SPO,知识图谱构建SPO-机器学习文档类资源-CSDN下载
代码链接:瑞金医院MMC人工智能辅助构建知识代码-机器学习文档类资源-CSDN下载
本地代码推荐BiLSTM+CRF(经调试效果佳):知识图谱项目实战(一):瑞金医院MMC人工智能辅助构建知识图谱--初赛实体识别【1】码源。-深度学习文档类资源-CSDN下载
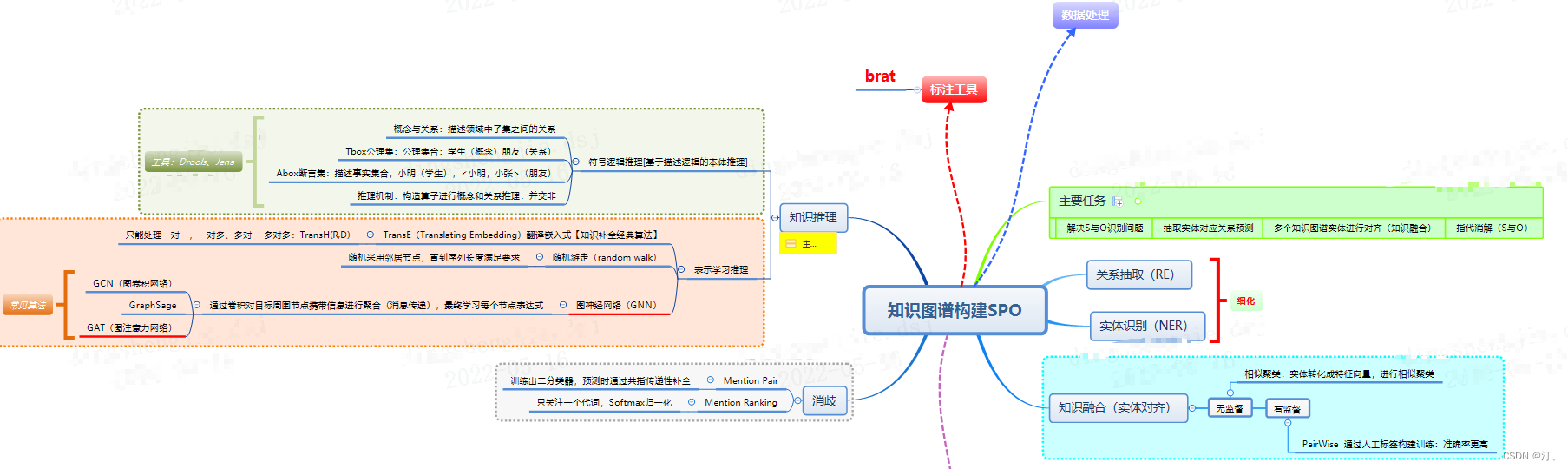
赛题说明 本次大赛旨在通过糖尿病相关的教科书、研究论文来做糖尿病文献挖掘并构建糖尿病知识图谱。参赛选手需要设计高准确率,高效的算法来挑战这一科学难题。第一赛季课题为“基于糖尿病临床指南和研究论文的实体标注构建”,第二赛季课题为“基于糖尿病临床指南和研究论文的实体间关系构建”。本次大赛禁止使用外部数据,可以使用外部工具。本次大赛禁止通过构造字典方式来进行实体预测。 文件标注工作基于brat软件,brat rapid annotation tool。其中.txt文件为原始文档,.ann文件为标注信息,标注实体以T开头,后接实体序号,实体类别,起始位置和实体对应的文档中的词。如果需要在brat软件中查看标注结果,需要添加.conf文件。
初赛 提供与糖尿病相关的学术论文以及糖尿病临床指南,要求选手在学术论文和临床指南的基础上,做实体的标注。实体类别共十五类。 类别名称和定义 疾病相关: 1、疾病名称 (Disease),如I型糖尿病。 2、病因(Reason),疾病的成因、危险因素及机制。比如“糖尿病是由于胰岛素抵抗导致”,胰岛素抵抗是属于病因。 3、临床表现 (Symptom),包括症状、体征,病人直接表现出来的和需要医生进行查体得出来的判断。如"头晕" "便血" 等。 4、检查方法(Test),包括实验室检查方法,影像学检查方法,辅助试验,对于疾病有诊断及鉴别意义的项目等,如甘油三酯。 5、检查指标值(Test_Value),指标的具体数值,阴性阳性,有无,增减,高低等,如”>11.3 mmol/L”。 治疗相关: 6、药品名称(Drug),包括常规用药及化疗用药,比如胰岛素。 7、用药频率(Frequency),包括用药的频率和症状的频率,比如一天两次。 8、用药剂量(Amount),比如500mg/d。 9、用药方法(Method):比如早晚,餐前餐后,口服,静脉注射,吸入等。 10、非药治疗(Treatment),在医院环境下进行的非药物性治疗,包括放疗,中医治疗方法等,比如推拿、按摩、针灸、理疗,不包括饮食、运动、营养等。 11、手术(Operation),包括手术名称,如代谢手术等。 12、不良反应(SideEff),用药后的不良反应。
常规实体: 13、部位(Anatomy),包括解剖部位和生物组织,比如人体各个部位和器官,胰岛细胞。 14、程度(level),包括病情严重程度,治疗后缓解程度等。 15、持续时间(Duration),包括症状持续时间,用药持续时间,如“头晕一周”的“一周”。
复赛 提供与糖尿病相关的学术论文以及糖尿病临床指南。选手从中抽取实体之间的关系。实体之间关系共十类。
实体关系类别名称 1、检查方法 -> 疾病(Test_Disease) 2、临床表现 -> 疾病(Symptom_Disease) 3、非药治疗 -> 疾病(Treatment_Disease) 4、药品名称 -> 疾病(Drug_Disease) 5、部位 -> 疾病(Anatomy_Disease) 6、用药频率 -> 药品名称(Frequency_Drug) 7、持续时间 -> 药品名称(Duration_Drug) 8、用药剂量 -> 药品名称(Amount_Drug) 9、用药方法 -> 药品名称(Method_Drug) 10、不良反应 -> 药品名称(SideEff-Drug) 评估标准 采用F1-Measure作为评测指标。 复赛评测采用严格交集的方式来计算F1,即选手提交文件中的关系部分的第二列的整个字符串必须与答案完全一致。
选手提交格式 初赛提交结果为zip文件,参考submit。zip中的文件需要与测试txt文件的文件名相同,后缀名为.ann。文件中每一列以tab分割,共三列:第一列为实体编号,编号自拟且需唯一,不参与评测;第二列包含实体类别和实体的起始和终止位置,以空格分割,注意部分实体可能在第二列有分号,表示该实体跨行;第三列是实体所对应的词语, 不参与评测 。
复赛提交结果为zip文件,参考submit。zip中的文件名需要与测试的ann的文件名一致,并且保留测试ann文件的原有内容。在原有内容的基础上,后面添加行代表关系。关系行以tab分割,共两列:第一列为关系编号,以字符R开头,如“R1”,编号需唯一;第二列包含关系类别和关系的起始(以Arg1:开始,后接实体id,如“Arg1:T1”)和终止位置(以Arg2:开始,后接实体id,如“Arg2:T2”),以空格分割。
2.数据预处理
数据连接见文章开头
把数据解压最好放到同路径下即可
! unzip data.zip 去终端cd 路径 解压即可安装pandas库后
pip install pandasimport pandas as pd
label=pd.read_csv("train/0.ann",header=None,sep="\t")
print(label) 0 1 2
0 T1 Disease 1845 1850 1型糖尿病
1 T2 Disease 1983 1988 1型糖尿病
2 T4 Disease 30 35 2型糖尿病
3 T5 Disease 1822 1827 2型糖尿病
4 T6 Disease 2055 2060 2型糖尿病
.. ... ... ...
593 R206 Symptom_Disease Arg1:T329 Arg2:T325 NaN
594 R207 Symptom_Disease Arg1:T331 Arg2:T325 NaN
595 R208 Test_Disease Arg1:T337 Arg2:T338 NaN
596 R209 Treatment_Disease Arg1:T343 Arg2:T345 NaN
597 R210 Treatment_Disease Arg1:T344 Arg2:T345 NaN
[598 rows x 3 columns]entity&connect的标注格式化解析
label_T=label[label[0].str.startswith("T")] #选出开头
0 1 2
0 T1 Disease 1845 1850 1型糖尿病
1 T2 Disease 1983 1988 1型糖尿病
2 T4 Disease 30 35 2型糖尿病
3 T5 Disease 1822 1827 2型糖尿病
4 T6 Disease 2055 2060 2型糖尿病
.. ... ... ...
383 T309 Disease 5984 5987 糖尿病
384 T310 Test 6335 6339 血红蛋白
385 T385 Test 6340 6345 红细胞转换
386 T343 Disease 6616 6621 2型糖尿病
387 T344 Test 6621 6629 HBA1C c
[388 rows x 3 columns]
label_T.columns=["id","entity","text"] #表头设置,并划分信息
label_T["category"]=[e.split()[0] for e in label_T["entity"].tolist()]
label_T["start"]=[int(e.split()[1]) for e in label_T["entity"].tolist()]
label_T["end"]=[int(e.split()[-1]) for e in label_T["entity"].tolist()]
print(label_T)
id entity text category start end
0 T1 Disease 1845 1850 1型糖尿病 Disease 1845 1850
1 T2 Disease 1983 1988 1型糖尿病 Disease 1983 1988
2 T4 Disease 30 35 2型糖尿病 Disease 30 35
3 T5 Disease 1822 1827 2型糖尿病 Disease 1822 1827
4 T6 Disease 2055 2060 2型糖尿病 Disease 2055 2060
.. ... ... ... ... ... ...
383 T309 Disease 5984 5987 糖尿病 Disease 5984 5987
384 T310 Test 6335 6339 血红蛋白 Test 6335 6339
385 T385 Test 6340 6345 红细胞转换 Test 6340 6345
386 T343 Disease 6616 6621 2型糖尿病 Disease 6616 6621
387 T344 Test 6621 6629 HBA1C c Test 6621 6629
[388 rows x 6 columns]同理对待实体之间的关系:
label_R=label[label[0].str.startswith("R")] #选出开头
print(label_R)
0 1 2
388 R1 Test_Disease Arg1:T369 Arg2:T368 NaN
389 R2 Test_Disease Arg1:T13 Arg2:T25 NaN
390 R3 Test_Disease Arg1:T14 Arg2:T25 NaN
391 R4 Test_Disease Arg1:T3 Arg2:T25 NaN
392 R5 Test_Disease Arg1:T31 Arg2:T33 NaN
.. ... ... ...
593 R206 Symptom_Disease Arg1:T329 Arg2:T325 NaN
594 R207 Symptom_Disease Arg1:T331 Arg2:T325 NaN
595 R208 Test_Disease Arg1:T337 Arg2:T338 NaN
596 R209 Treatment_Disease Arg1:T343 Arg2:T345 NaN
597 R210 Treatment_Disease Arg1:T344 Arg2:T345 NaN
[210 rows x 3 columns]
label_R.columns=["id","relation","nan"] #表头设置,并划分信息
label_R["category"]=[r.split()[0] for r in label_R["relation"].tolist()]
label_R["arg1"]=[r.split()[1][5:] for r in label_R["relation"].tolist()]
label_R["arg2"]=[r.split()[2][5:] for r in label_R["relation"].tolist()]
print(label_R)
id relation nan category \
388 R1 Test_Disease Arg1:T369 Arg2:T368 NaN Test_Disease
389 R2 Test_Disease Arg1:T13 Arg2:T25 NaN Test_Disease
390 R3 Test_Disease Arg1:T14 Arg2:T25 NaN Test_Disease
391 R4 Test_Disease Arg1:T3 Arg2:T25 NaN Test_Disease
392 R5 Test_Disease Arg1:T31 Arg2:T33 NaN Test_Disease
.. ... ... ... ...
593 R206 Symptom_Disease Arg1:T329 Arg2:T325 NaN Symptom_Disease
594 R207 Symptom_Disease Arg1:T331 Arg2:T325 NaN Symptom_Disease
595 R208 Test_Disease Arg1:T337 Arg2:T338 NaN Test_Disease
596 R209 Treatment_Disease Arg1:T343 Arg2:T345 NaN Treatment_Disease
597 R210 Treatment_Disease Arg1:T344 Arg2:T345 NaN Treatment_Disease
arg1 arg2
388 T369 T368
389 T13 T25
390 T14 T25
391 T3 T25
392 T31 T33
.. ... ...
593 T329 T325
594 T331 T325
595 T337 T338
596 T343 T345
597 T344 T345
[210 rows x 6 columns]后续会讲把里面处理过的冗余信息提出
3.初赛--实体识别
本地代码推荐BiLSTM+CRF(经调试效果佳):瑞金医院MMC人工智能辅助构建知识代码-机器学习文档类资源-CSDN下载
下面给出常见方法的核心代码,使用方法只需要把上面BiLSTM+CRF对应算法部分替换即可
3.1 传统方法:概率图模型——条件随机场CRF
# 构建概率图模型——条件随机场
import keras
from keras.layers import Input, Embedding
from keras_contrib.layers import CRF
from keras.models import Model
def build_crf_model(num_cates, seq_len, vocab_size, model_opts=dict()):
opts = {
'emb_size': 256,
'emb_trainable': True,
'emb_matrix': None,
'optimizer': keras.optimizers.Adam()
}
opts.update(model_opts)
input_seq = Input(shape=(seq_len,), dtype='int32')
if opts.get('emb_matrix') is not None:
embedding = Embedding(vocab_size, opts['emb_size'],
weights=[opts['emb_matrix']],
trainable=opts['emb_trainable'])
else:
embedding = Embedding(vocab_size, opts['emb_size'])
x = embedding(input_seq)
crf = CRF(num_cates, sparse_target=True)
output = crf(x)
model = Model(input_seq, output)
model.compile(opts['optimizer'], loss=crf.loss_function, metrics=[crf.accuracy])
return model# CRF条件随机场实例化
seq_len = sent_len + 2 * sent_pad
model = build_crf_model(num_cates, seq_len=seq_len, vocab_size=vocab_size,model_opts={'emb_matrix': w2v_embeddings, 'emb_size': 100, 'emb_trainable': False})
model.summary()
# 条件随机场模型训练
model.fit(train_X, train_y, batch_size=64, epochs=10)效果展示:
Epoch 8/10
2622/2622 [==============================] - 6s 2ms/step - loss: 0.7750 - crf_viterbi_accuracy: 0.7705
Epoch 9/10
2622/2622 [==============================] - 5s 2ms/step - loss: 0.7346 - crf_viterbi_accuracy: 0.7745
Epoch 10/10
2622/2622 [==============================] - 5s 2ms/step - loss: 0.7014 - crf_viterbi_accuracy: 0.7773# 输出评价指标
f_score, precision, recall = Evaluator.f1_score(test_docs, pred_docs)
print('f_score: ', f_score)
print('precision: ', precision)
print('recall: ', recall)
f_score: 0.4847994451508496
precision: 0.5801632314289666
recall: 0.416360567854660973.2 深度学习基础算法-RNN模型加crf模型
# 构建RNN模型加crf模型
import keras
from keras.layers import Input, SimpleRNN, Embedding, Bidirectional
from keras_contrib.layers import CRF
from keras.models import Model
def build_rnn_model(num_cates, seq_len, vocab_size, model_opts=dict()):
opts = {
'emb_size': 256,
'emb_trainable': True,
'emb_matrix': None,
'rnn_units': 256,
'optimizer': keras.optimizers.Adam()
}
opts.update(model_opts)
input_seq = Input(shape=(seq_len,), dtype='int32')
if opts.get('emb_matrix') is not None:
embedding = Embedding(vocab_size, opts['emb_size'],
weights=[opts['emb_matrix']],
trainable=opts['emb_trainable'])
else:
embedding = Embedding(vocab_size, opts['emb_size'])
x = embedding(input_seq)
rnn = SimpleRNN(opts['rnn_units'], return_sequences=True)
x = rnn(x)
crf = CRF(num_cates, sparse_target=True)
output = crf(x)
model = Model(input_seq, output)
model.compile(opts['optimizer'], loss=crf.loss_function, metrics=[crf.accuracy])
return modelEpoch 7/10
2622/2622 [==============================] - 15s 6ms/step - loss: 0.4254 - crf_viterbi_accuracy: 0.8507
Epoch 8/10
2622/2622 [==============================] - 15s 6ms/step - loss: 0.4047 - crf_viterbi_accuracy: 0.8560
Epoch 9/10
2622/2622 [==============================] - 15s 6ms/step - loss: 0.3860 - crf_viterbi_accuracy: 0.8605
Epoch 10/10
2622/2622 [==============================] - 15s 6ms/step - loss: 0.3729 - crf_viterbi_accuracy: 0.8625
f_score: 0.692128403432567
precision: 0.7419647927314026
recall: 0.6485654720540057性能已经提升了很多了。
3.3 深度学习高级算法--LSTM加crf模型
# 构建长短时记忆模型模型加crf模型
import keras
from keras.layers import Input, LSTM, Embedding, Bidirectional
from keras_contrib.layers import CRF
from keras.models import Model
def build_lstm_model(num_cates, seq_len, vocab_size, model_opts=dict()):
opts = {
'emb_size': 256,
'emb_trainable': True,
'emb_matrix': None,
'rnn_units': 256,
'optimizer': keras.optimizers.Adam()
}
opts.update(model_opts)
input_seq = Input(shape=(seq_len,), dtype='int32')
if opts.get('emb_matrix') is not None:
embedding = Embedding(vocab_size, opts['emb_size'],
weights=[opts['emb_matrix']],
trainable=opts['emb_trainable'])
else:
embedding = Embedding(vocab_size, opts['emb_size'])
x = embedding(input_seq)
lstm = LSTM(opts['rnn_units'], return_sequences=True)
x = lstm(x)
crf = CRF(num_cates, sparse_target=True)
output = crf(x)
model = Model(input_seq, output)
model.compile(opts['optimizer'], loss=crf.loss_function, metrics=[crf.accuracy])
return model2622/2622 [==============================] - 37s 14ms/step - loss: 0.4122 - crf_viterbi_accuracy: 0.8570
Epoch 7/10
2622/2622 [==============================] - 37s 14ms/step - loss: 0.3836 - crf_viterbi_accuracy: 0.8642
Epoch 8/10
2622/2622 [==============================] - 37s 14ms/step - loss: 0.3598 - crf_viterbi_accuracy: 0.8708
Epoch 9/10
2622/2622 [==============================] - 37s 14ms/step - loss: 0.3386 - crf_viterbi_accuracy: 0.8758
Epoch 10/10
2622/2622 [==============================] - 36s 14ms/step - loss: 0.3150 - crf_viterbi_accuracy: 0.8816f_score: 0.6853306967788938
precision: 0.7201443569553806
recall: 0.65372778715377743.4 主流算法:BiLSTM+CRF
# 构建双向长短时记忆模型模型加crf模型
import keras
from keras.layers import Input, LSTM, Embedding, Bidirectional
from keras_contrib.layers import CRF
from keras.models import Model
def build_lstm_crf_model(num_cates, seq_len, vocab_size, model_opts=dict()):
opts = {
'emb_size': 256,
'emb_trainable': True,
'emb_matrix': None,
'lstm_units': 256,
'optimizer': keras.optimizers.Adam()
}
opts.update(model_opts)
input_seq = Input(shape=(seq_len,), dtype='int32')
if opts.get('emb_matrix') is not None:
embedding = Embedding(vocab_size, opts['emb_size'],
weights=[opts['emb_matrix']],
trainable=opts['emb_trainable'])
else:
embedding = Embedding(vocab_size, opts['emb_size'])
x = embedding(input_seq)
lstm = LSTM(opts['lstm_units'], return_sequences=True)
x = Bidirectional(lstm)(x)
crf = CRF(num_cates, sparse_target=True)
output = crf(x)
model = Model(input_seq, output)
model.compile(opts['optimizer'], loss=crf.loss_function, metrics=[crf.accuracy])
return model完整代码见前面,下载即可。
Epoch 8/10
2622/2622 [==============================] - 88s 34ms/step - loss: 0.2898 - crf_viterbi_accuracy: 0.9190
Epoch 9/10
2622/2622 [==============================] - 88s 33ms/step - loss: 0.2664 - crf_viterbi_accuracy: 0.9248
Epoch 10/10
2622/2622 [==============================] - 87s 33ms/step - loss: 0.2430 - crf_viterbi_accuracy: 0.9313f_score: 0.7060570071258908
precision: 0.7038973852984707
recall: 0.7082299215725206性能显著提升。
看一下可视化效果:标注出来的实体还可以

3.5 准确率、精确率、召回率和F-score讲解
参考文章:
『NLP学习笔记』Sklearn计算准确率、精确率、召回率及F1 Score_布衣小张的博客-CSDN博客_sklearn 准确率 召回率
分类是机器学习中比较常见的任务,对于分类任务常见的评价指标有 准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 score、ROC曲线(Receiver Operating Characteristic Curve)等。
3.5.1 混淆矩阵定义
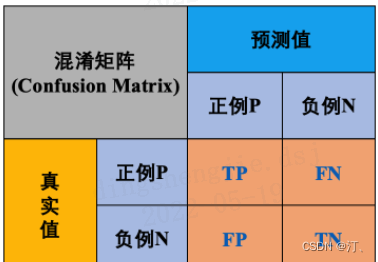
首先需要知道混淆矩阵,混淆矩阵中的 P表示Positive,即正例或者阳性,N表示Negative,即负例 或者阴性。
- TP(True Positive): 表示 实际为正被预测为正 的样本数量。从英文名可以看出,首先是true,正确的,说明判断正确;再看后面的是Positive,正类,那么联系前文可知是判断正确的,即将正类判断为正类。
- TN: 表示 实际为负被预测为负 的样本的数量。首先是True,判断正确;再看后者,Negative,负类,可以记忆为负类判断为负类。
- FN: 表示 实际为正但被预测为负 的样本的数量。首先是False,错误的,说明判断错误;再看后者,Negative,负类,可以记忆为 将正类判断错误为负类。
- FP(False Positive): 表示 实际为负但被预测为正 的样本数量。首先是False,错误的,说明判断错误;再看后者,Positive,正类,那么联系前文可以记忆 将负类判断错误为正类。
另外:TP+FP表示所有被 预测为正的样本数量,同理FN+TN为所有被 预测为负的样本数量,TP+FN为 实际为正的样本数量,FP+TN为 实际为负的样本数量。
容器记住的方法:
TP:首先看P表示预测为正,T表示预测正确(也就是实际为正,预测为正);TN:首先表示预测为负,预测正确;FP:首先表示预测为正,预测错误;
- 例如:下面例子中的混淆矩阵(11类别): 注意sklearn中横坐标表示的预测,纵坐标表示的是真实标签。
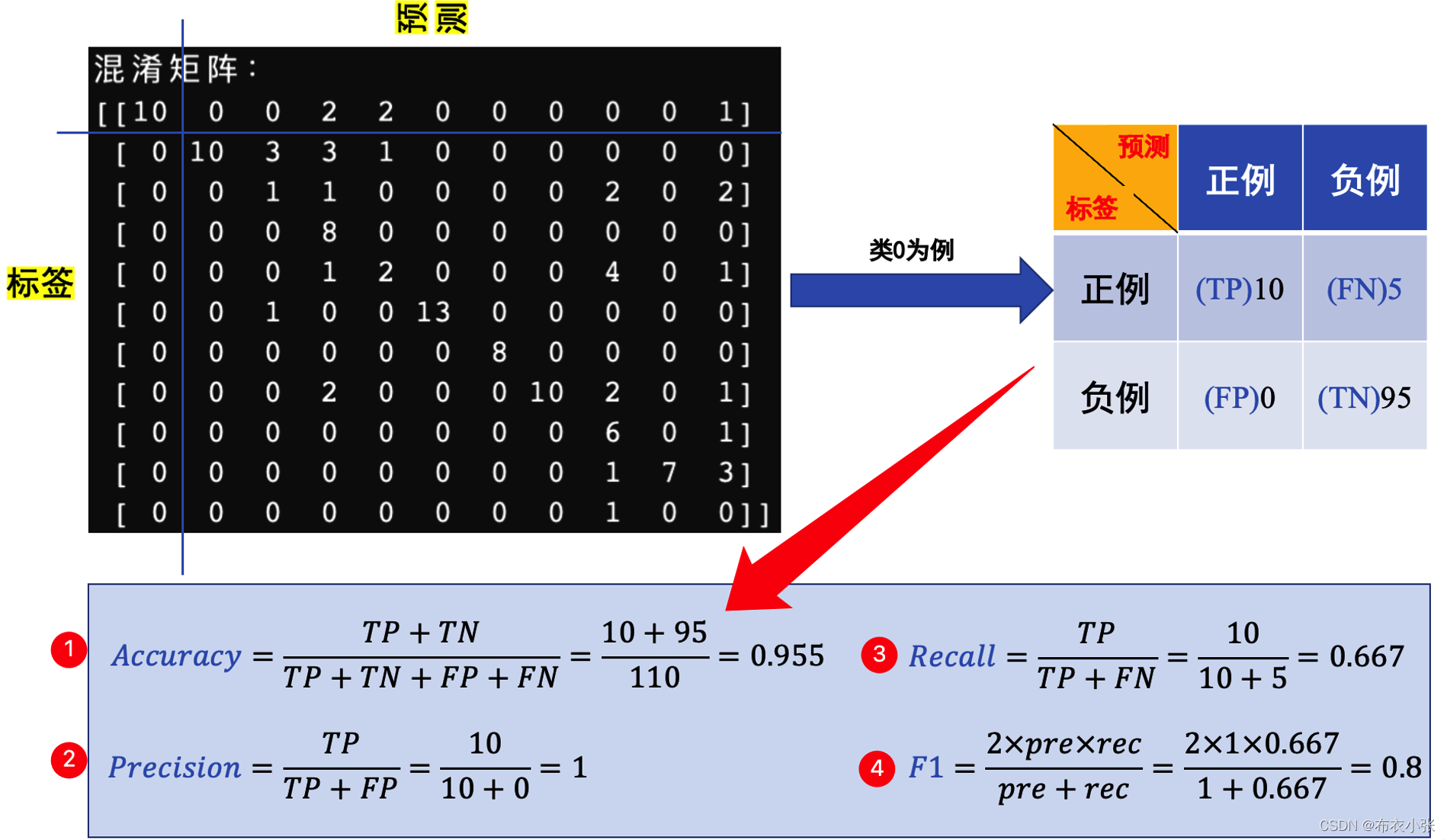
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
# y_true: 是样本真实分类结果
# y_pred: 是样本预测分类结果
# labels:是所给出的类别,通过这个可对类别进行选择
# sample_weight: 样本权重
from sklearn.metrics import confusion_matrix
y_true=[2,1,0,1,2,0]
y_pred=[2,0,0,1,2,1]
C=confusion_matrix(y_true, y_pred)
# 结果如下
# array([[1, 1, 0],
# [1, 1, 0],
# [1, 0, 2]])
y_true = ["cat", "ant", "cat", "cat", "ant", "bird"]
y_pred = ["ant", "ant", "cat", "cat", "ant", "cat"]
confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"])
# 结果如下
# array([[2, 0, 0],
# [0, 0, 1],
# [1, 0, 2]])3.5.2 :准确率

Sklearn函数接口的描述是这样的:
准确度分类得分
在多标签分类中,此函数计算子集精度:为样本预测的标签集必须完全匹配y_true(实际标签)中相应的标签集。
参数
y_true: 一维数组,或标签指示符 / 稀疏矩阵,实际(正确的)标签.
y_pred: 一维数组,或标签指示符 / 稀疏矩阵,分类器返回的预测标签.
normalize: 布尔值, 可选的(默认为True). 如果为False,返回分类正确的样本数量,否则,返回正 确分类的得分.
sample_weight: 形状为[样本数量]的数组,可选. 样本权重.
返回值
score: 浮点型
如果normalize为True,返回正确分类的得分(浮点型),否则返回分类正确的样本数量(整型).
当normalize为True时,最好的表现是score为1,当normalize为False时,最好的表现是score未样本数量import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
print(accuracy_score(y_true, y_pred)) # 0.5
print(accuracy_score(y_true, y_pred, normalize=False)) # 2
# 在具有二元标签指示符的多标签分类案例中
print(accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2)))) # 0.5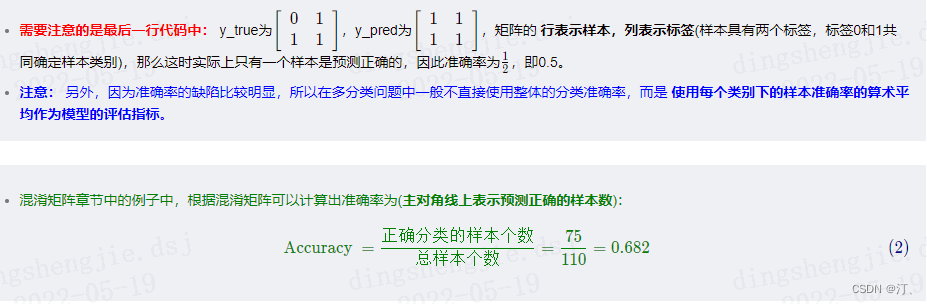
3.5.3 :精确率

Sklearn中的函数接口precision_score的描述如下: 一、计算精确率 其中 T P TPTP是预测为正&实际为正的数量,F P FPFP 是实际为负&预测为正. 精确率直观地可以说是 分类器不将负样本标记为正样本的能力. 精确率最好的值是1,最差的值是0. 二、参数 y_true : 一维数组,或标签指示符 / 稀疏矩阵,实际(正确的)标签. y_pred : 一维数组,或标签指示符 / 稀疏矩阵,分类器返回的预测标签. labels : 列表,可选值. 当average != binary时被包含的标签集合,如果average是None的话还包含它们的顺序. 在数据中存在的标签可以被排除,比如计算一个忽略多数负类的多类平均值时,数据中没有出现的标签会导致宏平均值(marco average)含有0个组件. 对于多标签的目标,标签是列索引. 默认情况下,y_true和y_pred中的所有标签按照排序后的顺序使用. pos_label : 字符串或整型,默认为1. 如果average = binary并且数据是二进制时需要被报告的类. 若果数据是多类的或者多标签的,这将被忽略;设置labels=[pos_label]和average != binary就只会报告设置的特定标签的分数. average : 字符串,可选值为 [None, ‘binary’ (默认), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]. 多类或者多标签目标需要这个参数. 如果为None,每个类别的分数将会返回. 否则,它决定了数据的平均值类型.
- ‘binary’: 仅报告由pos_label指定的类的结果. 这仅适用于目标(y_{true, pred})是二进制的情况.
- ‘micro微观’: 通过计算总的真正性、假负性和假正性来全局计算指标.(常用).
- ‘weighted’: 为每个标签计算指标,并通过各类占比找到它们的加权均值(每个标签的正例数).它解决了’macro’的标签不平衡问题;它可以产生不在精确率和召回率之间的F-score.
- ‘samples’: 为每个实例计算指标,找到它们的均值(只在多标签分类的时候有意义,并且和函数accuracy_score不同).
- sample_weight : 形状为[样本数量]的数组,可选参数. 样本权重.
三、返回值 precision : 浮点数(如果average不是None) 或浮点数数组, shape =[唯一标签的数量] 二分类中正类的精确率或者在多分类任务中每个类的精确率的加权平均. ‘macro宏观’: 为每个标签计算指标,找到它们未加权的均值. 它不考虑标签数量不平衡的情况
from sklearn.metrics import precision_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(precision_score(y_true, y_pred, average='macro')) # 0.2222222222222222
print(precision_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(precision_score(y_true, y_pred, average='weighted')) # 0.2222222222222222
print(precision_score(y_true, y_pred, average=None)) # [0.66666667 0. 0. ]- 直接看函数接口和示例代码还是让人有点云里雾里的,我们这里先介绍两个与多分类相关的概念,再说说上面的代码是如何计算的。
- Macro[ˈmækroʊ]宏观 Average:宏平均是指在计算均值时使 每个类别具有相同的权重,最后结果是每个类别的指标的算术平均值。
- Micro Average:微平均是指计算多分类指标时 赋予所有类别的每个样本相同的权重,将所有样本合在一起计算各个指标。
根据precision_score接口的解释,我们可以知道,当average参数为None时,得到的结果是每个类别的precision。上面的y_true有3个类别,分别为类0、类1、类2。我们将每个类别的TP、FP、FN列在下表中。
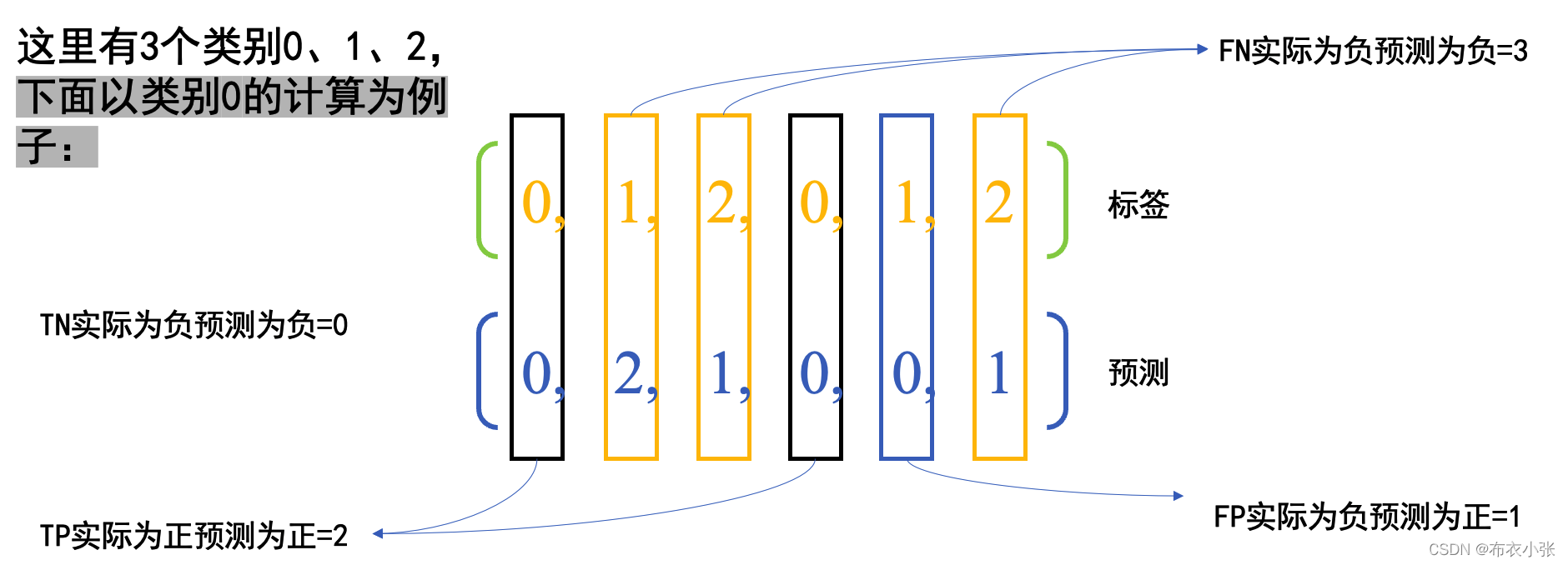


宏平均和微平均的关系:
虽然,我们是主要讲精确率的,但是 宏平均和微平均的概念也很重要,这里顺便对比一下。 如果每个类别的样本数量差不多,那么宏平均和 微平均没有太大差异 如果每个类别的样本数量差异很大,那么注重样本量多的类时使用微平均,注重样本量少的类时使用宏平均 如果微平均大大低于宏平均,那么检查样本量多的类来确定指标表现差的原因 如果宏平均大大低于微平均,那么检查样本量少的类来确定指标表现差的原因
3.5.4 :召回率

计算召回率 召回率是比率tp / (tp + fn),其中tp是真正性的数量,fn是假负性的数量. 召回率直观地说是分类器找到所有正样本的能力. 召回率最好的值是1,最差的值是0. 返回值 recall : 浮点数(如果average不是None) 或者浮点数数组,shape = [唯一标签的数量] 二分类中正类的召回率或者多分类任务中每个类别召回率的加权平均值.
from sklearn.metrics import recall_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(recall_score(y_true, y_pred, average='macro')) # 0.3333333333333333
print(recall_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(recall_score(y_true, y_pred, average='weighted')) # 0.3333333333333333
print(recall_score(y_true, y_pred, average=None)) # [1. 0. 0.]
3.5.5:F1 Score

计算召回率 计算F1 score,它也被叫做F-score或F-measure. F1 score可以解释为精确率和召回率的加权平均值. F1 score的最好值为1,最差值为0. 精确率和召回率对F1 score的相对贡献是相等的. 在多类别或者多标签的情况下,这是权重取决于average参数的对于每个类别的F1 score的加权平均值。 返回值 f1_score : 浮点数或者是浮点数数组,shape=[唯一标签的数量] 二分类中的正类的F1 score或者是多分类任务中每个类别F1 score的加权平均.
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
print(f1_score(y_true, y_pred, average='macro')) # 0.26666666666666666
print(f1_score(y_true, y_pred, average='micro')) # 0.3333333333333333
print(f1_score(y_true, y_pred, average='weighted')) # 0.26666666666666666
print(f1_score(y_true, y_pred, average=None)) # [0.8 0. 0. ]3.6 各个指标意义和优缺点
1. 准确率
虽然准确率能够判断总的正确率,但是在样本不均衡的情况下,并不能作为很好的指标来衡量结果。
比如在样本集中,正样本有90个,负样本有10个,样本是严重的不均衡。对于这种情况,我们只需要将全部样本预测为正样本,就能得到90%的准确率,但是完全没有意义。对于新数据,完全体现不出准确率。因此,在样本不平衡的情况下,得到的高准确率没有任何意义,此时准确率就会失效。所以,我们需要寻找新的指标来评价模型的优劣。
2 . 精确率
精确率(Precision) 是针对预测结果而言的,其含义是在被所有预测为正的样本中实际为正样本的概率,精确率和准确率看上去有些类似,但是是两个完全不同的概念。精确率代表对正样本结果中的预测准确程度,准确率则代表整体的预测准确程度,包括正样本和负样本。
3. 召回率
召回率(Recall) 是针对原样本而言的,其含义是在实际为正的样本中被预测为正样本的概率。准确率和召回率互相影响,理想状态下肯定追求两个都高,但是实际情况是两者相互“制约”:追求准确率高,则召回率就低;追求召回率高,则通常会影响准确率。我们当然希望预测的结果precision越高越好, recall越高越好, 但事实上这两者在某些情况下是矛盾的。这样就需要综合考虑它们,最常见的方法就是F-score。 也可以绘制出P-R曲线图,观察它们的分布情况。
4. F-score
一般来说准确率和召回率呈负相关,一个高,一个就低,如果两个都低,一定是有问题的。 一般来说,精确度和召回率之间是矛盾的,这里引入F1-Score作为综合指标,就是为了平衡准确率和召回率的影响,较为全面地评价一个分类器。F1是精确率和召回率的调和平均。
3.7 多分类指标实战:
from prettytable import PrettyTable
def convert_to_one_hot(y):
return np.eye(len(self.labels))[y.reshape(-1)]
def cus_metrics(all_preds, all_labels): # 这里都是向量的形式
all_preds = convert_to_one_hot(np.array(all_preds)) # 转成one_hot编码
all_labels = convert_to_one_hot(np.array(all_labels)) # 转成one_hot编码
tab = PrettyTable(['accuracy', 'precision', 'recall', 'F1-Score(macro)', 'num', 'label'])
for i in range(len(self.labels)):
out = all_preds[:, i]
tgt = all_labels[:, i]
# ############## 自己计算 ###############
TP = 0 # TP表示实际为正被预测为正的样本数量
FN = 0 # FN表示实际为正但被预测为负的样本的数量
FP = 0 # FP表示实际为负但被预测为正的样本数量
TN = 0 # TN表示实际为负被预测为负的样本的数量
for o, t in zip(out, tgt):
if o and t:
TP += 1
elif o and (not t):
FP += 1
elif (not o) and t:
FN += 1
else:
TN += 1
acc = (TP + TN) / (TP + FN + FP + TN) if (TP + FN + FP + TN) > 0 else 0
pre = TP / (TP + FP) if (TP + FP) > 0 else 0
rec = TP / (TP + FN) if (TP + FN) > 0 else 0
F1 = 2 * pre * rec / (pre + rec) if (pre + rec) > 0 else 0
tab.add_row([round(acc, 3), round(pre, 3), round(rec, 3), round(F1, 3), int(sum(tgt)), labels[i]])
############### sklearn计算 ###############
acc = accuracy_score(tgt, out)
pre = precision_score(tgt, out, average='macro')
rec = recall_score(tgt, out, average='macro')
F1 = f1_score(tgt, out, average='macro')
tab.add_row([round(acc, 3), round(pre, 3), round(rec, 3), round(F1, 3), int(sum(tgt)), labels[i]])
print(tab)4.小结
后续将会分享实体标注的其他算法和开源工具以及关系抽取的实现
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号