Flink1.13架构全集| 一文带你由浅入深精通Flink方方面面(三)SQL篇
Flink1.13架构全集| 一文带你由浅入深精通Flink方方面面(三)SQL篇

心向阳光,才不会荒芜
阳光甚好,春暖花开
繁花开放就在眼前
每天早晨起床都是生命最美的开始
哈喽各位,本章主要写的是FlinkSQL也是Flink章节的倒数第二篇了,最后还有一篇FlinkCEP,稍后会出,耐心关注哦!好了,进入正题!!!!

Table API和SQL是最上层的API,在Flink中这两种API被集成在一起,SQL执行的对象也是Flink中的表(Table),所以我们一般会认为它们是一体的。Flink是批流统一的处理框架,无论是批处理(DataSet API)还是流处理(DataStream API),在上层应用中都可以直接使用Table API或者SQL来实现;这两种API对于一张表执行相同的查询操作,得到的结果是完全一样的。我们主要还是以流处理应用为例进行讲解。需要说明的是,Table API和SQL最初并不完善,在Flink 1.9版本合并阿里巴巴内部版本Blink之后发生了非常大的改变,此后也一直处在快速开发和完善的过程中,直到Flink 1.12版本才基本上做到了功能上的完善。而即使是在目前最新的1.13版本中,Table API和SQL也依然不算稳定,接口用法还在不停调整和更新。所以这部分希望大家重在理解原理和基本用法,具体的API调用可以随时关注官网的更新变化。
一、直接上手
如果我们对关系型数据库和SQL非常熟悉,那么Table API和SQL的使用其实非常简单:只要得到一个“表”(Table),然后对它调用Table API,或者直接写SQL就可以了。接下来我们就以一个非常简单的例子上手,初步了解一下这种高层级API的使用方法。
1.1 需要引入的依赖
我们想要在代码中使用Table API,必须引入相关的依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
这里的依赖是一个Java的“桥接器”(bridge),主要就是负责Table API和下层DataStream API的连接支持,按照不同的语言分为Java版和Scala版。如果我们希望在本地的集成开发环境(IDE)里运行Table API和SQL,还需要引入以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
这里主要添加的依赖是一个“计划器”(planner),它是Table API的核心组件,负责提供运行时环境,并生成程序的执行计划。这里我们用到的是新版的blink planner。由于Flink安装包的lib目录下会自带planner,所以在生产集群环境中提交的作业不需要打包这个依赖。而在Table API的内部实现上,部分相关的代码是用 Scala 实现的,所以还需要额外添加一个Scala版流处理的相关依赖。
1.2 一个简单示例
有了基本的依赖,接下来我们就可以尝试在Flink代码中使用Table API和SQL了。比如,我们可以自定义一些Event类型的用户访问事件,作为输入的数据源;而后从中提取url地址和用户名user两个字段作为输出。如果使用DataStream API,我们可以直接读取数据源后,用一个简单转换算子map来做字段的提取。而这个需求直接写SQL的话,实现会更加简单:
select url, user from EventTable;
这里我们把流中所有数据组成的表叫作EventTable。在Flink代码中直接对这个表执行上面的SQL,就可以得到想要提取的数据了。在代码中具体实现如下:
public class TableExample {
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
// 用执行SQL 的方式提取数据
Table visitTable = tableEnv.sqlQuery("select url, user from " + eventTable);
// 将表转换成数据流,打印输出
tableEnv.toDataStream(visitTable).print();
// 执行程序
env.execute();
}
}
这里我们需要创建一个“表环境”(TableEnvironment),然后将数据流(DataStream)转换成一个表(Table);之后就可以执行SQL在这个表中查询数据了。
二、基本API
2.1 程序架构
在Flink中,Table API和SQL可以看作联结在一起的一套API,这套API的核心概念就是“表”(Table)。在我们的程序中,输入数据可以定义成一张表;然后对这张表进行查询,就可以得到新的表,这相当于就是流数据的转换操作;最后还可以定义一张用于输出的表,负责将处理结果写入到外部系统。程序基本架构如下:
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建输入表,连接外部系统读取数据
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector' = ... )");
// 注册一个表,连接到外部系统,用于输出
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
// 执行SQL对表进行查询转换,得到一个新的表
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
// 使用Table API对表进行查询转换,得到一个新的表
Table table2 = tableEnv.from("inputTable").select(...);
// 将得到的结果写入输出表
TableResult tableResult = table1.executeInsert("outputTable");
这里不是从一个DataStream转换成Table,而是通过执行DDL来直接创建一个表。这里执行的CREATE语句中用WITH指定了外部系统的连接器,于是就可以连接外部系统读取数据了。这其实是更加一般化的程序架构,因为这样我们就可以完全抛开DataStream API,直接用SQL语句实现全部的流处理过程。
2.2 创建表环境
对于Flink这样的流处理框架来说,数据流和表在结构上还是有所区别的。所以使用Table API和SQL需要一个特别的运行时环境,这就是所谓的“表环境”(TableEnvironment)。它主要负责:
(1)注册Catalog和表;
(2)执行 SQL 查询;
(3)注册用户自定义函数(UDF);
(4)DataStream 和表之间的转换。
每个表和SQL的执行,都必须绑定在一个表环境(TableEnvironment)中。TableEnvironment是Table API中提供的基本接口类,可以通过调用静态的create()方法来创建一个表环境实例。方法需要传入一个环境的配置参数EnvironmentSettings,它可以指定当前表环境的执行模式和计划器(planner)。执行模式有批处理和流处理两种选择,默认是流处理模式;计划器默认使用blink planner。
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 使用流处理模式
.build();
TableEnvironment tableEnv = TableEnvironment.create(setting);
对于流处理场景,其实默认配置就完全够用了。所以我们也可以用另一种更加简单的方式来创建表环境:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
这里我们引入了一个“流式表环境”(StreamTableEnvironment),它是继承自TableEnvironment的子接口。调用它的create()方法,只需要直接将当前的流执行环境(StreamExecutionEnvironment)传入,就可以创建出对应的流式表环境了。
2.3 创建表
表(Table)是我们非常熟悉的一个概念,它是关系型数据库中数据存储的基本形式,也是SQL执行的基本对象。具体创建表的方式,有通过连接器(connector)和虚拟表(virtual tables)两种。
1. 连接器表(Connector Tables)
最直观的创建表的方式,就是通过连接器(connector)连接到一个外部系统,然后定义出对应的表结构。在代码中,我们可以调用表环境的executeSql()方法,可以传入一个DDL作为参数执行SQL操作。这里我们传入一个CREATE语句进行表的创建,并通过WITH关键字指定连接到外部系统的连接器:
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable ... WITH ( 'connector' = ... )");
这里的TEMPORARY关键字可以省略。关于连接器的具体定义,我们会在11.8节中展开讲解。
2. 虚拟表(Virtual Tables)
在环境中注册之后,我们就可以在SQL中直接使用这张表进行查询转换了。
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
这里调用了表环境的sqlQuery()方法,直接传入一条SQL语句作为参数执行查询,得到的结果是一个Table对象。Table是Table API中提供的核心接口类,就代表了一个Java中定义的表实例。由于newTable是一个Table对象,并没有在表环境中注册;所以如果希望直接在SQL中使用,我们还需要将这个中间结果表注册到环境中:
tableEnv.createTemporaryView("NewTable", newTable);
我们发现,这里的注册其实是创建了一个“虚拟表”(Virtual Table)。这个概念与SQL语法中的视图(View)非常类似,所以调用的方法也叫作创建“虚拟视图”(createTemporaryView)。
2.4 表的查询
创建好了表,接下来自然就是对表进行查询转换了。对一个表的查询(Query)操作,就对应着流数据的转换(Transform)处理。Flink为我们提供了两种查询方式:SQL,和Table API。
1. 执行SQL进行查询
基于表执行SQL语句,是我们最为熟悉的查询方式。在代码中,我们只要调用表环境的sqlQuery()方法,传入一个字符串形式的SQL查询语句就可以了。执行得到的结果,是一个Table对象。
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
// 查询用户Alice的点击事件,并提取表中前两个字段
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
目前Flink支持标准SQL中的绝大部分用法,并提供了丰富的计算函数。这样我们就可以把已有的技术迁移过来,像在MySQL、Hive中那样直接通过编写SQL实现自己的处理需求,从而大大降低了Flink上手的难度。例如,我们也可以通过GROUP BY关键字定义分组聚合,调用COUNT()、SUM()这样的函数来进行统计计算:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
上面的例子得到的是一个新的Table对象,我们可以再次将它注册为虚拟表继续在SQL中调用。另外,我们也可以直接将查询的结果写入到已经注册的表中,这需要调用表环境的executeSql()方法来执行DDL,传入的是一个INSERT语句:
// 注册表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 将查询结果输出到OutputTable中
tableEnv.executeSql (
"INSERT INTO OutputTable " +
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
2. 调用Table API进行查询
另外一种查询方式就是调用Table API。这是嵌入在Java和Scala语言内的查询API,核心就是Table接口类,通过一步步链式调用Table的方法,就可以定义出所有的查询转换操作。由于Table API是基于Table的Java实例进行调用的,因此我们首先要得到表的Java对象。基于环境中已注册的表,可以通过表环境的from()方法非常容易地得到一个Table对象:Table eventTable = tableEnv.from("EventTable"); 传入的参数就是注册好的表名。注意这里eventTable是一个Table对象,而EventTable是在环境中注册的表名。得到Table对象之后,就可以调用API进行各种转换操作了,得到的是一个新的Table对象:
Table maryClickTable = eventTable
.where($("user").isEqual("Alice"))
.select($("url"), $("user"));
这里每个方法的参数都是一个“表达式”(Expression),用方法调用的形式直观地说明了想要表达的内容;“$”符号用来指定表中的一个字段。上面的代码和直接执行SQL是等效的。Table API是嵌入编程语言中的DSL,SQL中的很多特性和功能必须要有对应的实现才可以使用,因此跟直接写SQL比起来肯定就要麻烦一些。目前Table API支持的功能相对更少,可以预见未来Flink社区也会以扩展SQL为主,为大家提供更加通用的接口方式;所以我们接下来也会以介绍SQL为主,简略地提及Table API。
3. 两种API的结合使用
可以发现,无论是调用Table API还是执行SQL,得到的结果都是一个Table对象;所以这两种API的查询可以很方便地结合在一起。(1)无论是哪种方式得到的Table对象,都可以继续调用Table API进行查询转换;(2)如果想要对一个表执行SQL操作(用FROM关键字引用),必须先在环境中对它进行注册。所以我们可以通过创建虚拟表的方式实现两者的转换:tableEnv.createTemporaryView("MyTable", myTable); 两种API殊途同归,实际应用中可以按照自己的习惯任意选择。不过由于结合使用容易引起混淆,而Table API功能相对较少、通用性较差,所以企业项目中往往会直接选择SQL的方式来实现需求。
2.5 输出表
表的创建和查询,就对应着流处理中的读取数据源(Source)和转换(Transform);而最后一个步骤Sink,也就是将结果数据输出到外部系统,就对应着表的输出操作。在代码上,输出一张表最直接的方法,就是调用Table的方法executeInsert()方法将一个 Table写入到注册过的表中,方法传入的参数就是注册的表名。
// 注册表,用于输出数据到外部系统
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 经过查询转换,得到结果表
Table result = ...
// 将结果表写入已注册的输出表中
result.executeInsert("OutputTable");
在底层,表的输出是通过将数据写入到TableSink来实现的。TableSink是Table API中提供的一个向外部系统写入数据的通用接口,可以支持不同的文件格式(比如CSV、Parquet)、存储数据库(比如JDBC、Elasticsearch)和消息队列(比如Kafka)。
2.6 表和流的转换
1. 将表(Table)转换成流(DataStream)
(1)调用toDataStream()方法 将一个Table对象转换成DataStream非常简单,只要直接调用表环境的方法toDataStream()就可以了。例如,我们可以将2.4小节经查询转换得到的表aliceClickTable转换成流打印输出:
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
// 将表转换成数据流
tableEnv.toDataStream(aliceVisitTable).print();
(2)调用toChangelogStream()方法 urlCountTable这个表中进行了分组聚合统计,所以表中的每一行是会“更新”的。对于这样有更新操作的表,我们不应该直接把它转换成DataStream打印输出,而是记录一下它的“更新日志”(change log)。这样一来,对于表的所有更新操作,就变成了一条更新日志的流,我们就可以转换成流打印输出了。代码中需要调用的是表环境的toChangelogStream()方法:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
// 将表转换成更新日志流
tableEnv.toDataStream(urlCountTable).print();
2. 将流(DataStream)转换成表(Table)
(1)调用fromDataStream()方法 想要将一个DataStream转换成表也很简单,可以通过调用表环境的fromDataStream()方法来实现,返回的就是一个Table对象。例如,我们可以直接将事件流eventStream转换成一个表:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env.addSource(...)
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
由于流中的数据本身就是定义好的POJO类型Event,所以我们将流转换成表之后,每一行数据就对应着一个Event,而表中的列名就对应着Event中的属性。另外,我们还可以在fromDataStream()方法中增加参数,用来指定提取哪些属性作为表中的字段名,并可以任意指定位置:
// 提取Event中的timestamp和url作为表中的列
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp"), $("url"));
需要注意的是,timestamp本身是SQL中的关键字,所以我们在定义表名、列名时要尽量避免。这时可以通过表达式的as()方法对字段进行重命名:
// 将timestamp字段重命名为ts
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"), $("url"));
(2)调用createTemporaryView()方法 调用fromDataStream()方法简单直观,可以直接实现DataStream到Table的转换;不过如果我们希望直接在SQL中引用这张表,就还需要调用表环境的createTemporaryView()方法来创建虚拟视图了。对于这种场景,也有一种更简洁的调用方式。我们可以直接调用createTemporaryView()方法创建虚拟表,传入的两个参数,第一个依然是注册的表名,而第二个可以直接就是DataStream。之后仍旧可以传入多个参数,用来指定表中的字段
tableEnv.createTemporaryView("EventTable", eventStream, $("timestamp").as("ts"),$("url"));
这样,我们接下来就可以直接在SQL中引用表EventTable了。
3. 支持的数据类型
整体来看,DataStream中支持的数据类型,Table中也是都支持的,只不过在进行转换时需要注意一些细节。(1)原子类型 在Flink中,基础数据类型(Integer、Double、String)和通用数据类型(也就是不可再拆分的数据类型)统一称作“原子类型”。原子类型的DataStream,转换之后就成了只有一列的Table,列字段(field)的数据类型可以由原子类型推断出。另外,还可以在fromDataStream()方法里增加参数,用来重新命名列字段。
StreamTableEnvironment tableEnv = ...;
DataStream<Long> stream = ...;
// 将数据流转换成动态表,动态表只有一个字段,重命名为myLong
Table table = tableEnv.fromDataStream(stream, $("myLong"));
(2)Tuple类型 当原子类型不做重命名时,默认的字段名就是“f0”,容易想到,这其实就是将原子类型看作了一元组Tuple1的处理结果。Table支持Flink中定义的元组类型Tuple,对应在表中字段名默认就是元组中元素的属性名f0、f1、f2...。所有字段都可以被重新排序,也可以提取其中的一部分字段。字段还可以通过调用表达式的as()方法来进行重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Tuple2<Long, Integer>> stream = ...;
// 将数据流转换成只包含f1字段的表
Table table = tableEnv.fromDataStream(stream, $("f1"));
// 将数据流转换成包含f0和f1字段的表,在表中f0和f1位置交换
Table table = tableEnv.fromDataStream(stream, $("f1"), $("f0"));
// 将f1字段命名为myInt,f0命名为myLong
Table table = tableEnv.fromDataStream(stream, $("f1").as("myInt"), $("f0").as("myLong"));
(3)POJO 类型 Flink也支持多种数据类型组合成的“复合类型”,最典型的就是简单Java对象(POJO 类型)。由于POJO中已经定义好了可读性强的字段名,这种类型的数据流转换成Table就显得无比顺畅了。将POJO类型的DataStream转换成Table,如果不指定字段名称,就会直接使用原始 POJO 类型中的字段名称。POJO中的字段同样可以被重新排序、提却和重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Event> stream = ...;
Table table = tableEnv.fromDataStream(stream);
Table table = tableEnv.fromDataStream(stream, $("user"));
Table table = tableEnv.fromDataStream(stream, $("user").as("myUser"), $("url").as("myUrl"));
(4)Row类型 Flink中还定义了一个在关系型表中更加通用的数据类型——行(Row),它是Table中数据的基本组织形式。Row类型也是一种复合类型,它的长度固定,而且无法直接推断出每个字段的类型,所以在使用时必须指明具体的类型信息;我们在创建Table时调用的CREATE语句就会将所有的字段名称和类型指定,这在Flink中被称为表的“模式结构”(Schema)。
4. 综合应用示例
现在,我们可以将介绍过的所有API整合起来,写出一段完整的代码。同样还是用户的一组点击事件,我们可以查询出某个用户(例如Alice)点击的url列表,也可以统计出每个用户累计的点击次数,这可以用两句SQL来分别实现。具体代码如下:
public class TableToStreamExample {
public static void main(String[] args) throws Exception {
// 获取流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
tableEnv.createTemporaryView("EventTable", eventStream);
// 查询Alice的访问url列表
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Alice'");
// 统计每个用户的点击次数
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) FROM EventTable GROUP BY user");
// 将表转换成数据流,在控制台打印输出
tableEnv.toDataStream(aliceVisitTable).print("alice visit");
tableEnv.toChangelogStream(urlCountTable).print("count");
// 执行程序
env.execute();
}
}
三、流处理中的表 我们可以将关系型表/SQL与流处理做一个对比,如表所示。
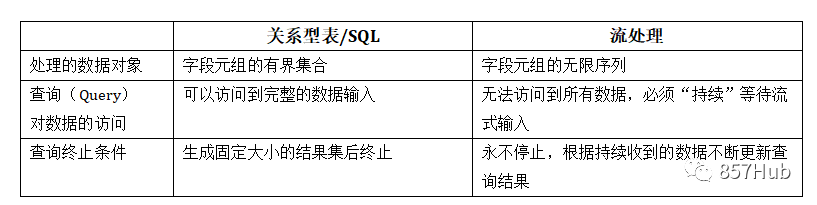
可以看到,其实关系型表和SQL,主要就是针对批处理设计的,这和流处理有着天生的隔阂。接下来我们就来深入探讨一下流处理中表的概念。
3.1 动态表和持续查询
流处理面对的数据是连续不断的,这导致了流处理中的“表”跟我们熟悉的关系型数据库中的表完全不同;而基于表执行的查询操作,也就有了新的含义。
1. 动态表(Dynamic Tables)
当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为“动态表”(Dynamic Tables)。动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。我们所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是“静态表”;而动态表则完全不同,它里面的数据会随时间变化。
2. 持续查询(Continuous Query)
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作“持续查询”(Continuous Query)。对动态表定义的查询操作,都是持续查询;而持续查询的结果也会是一个动态表。由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个“快照”(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了“持续查询”。
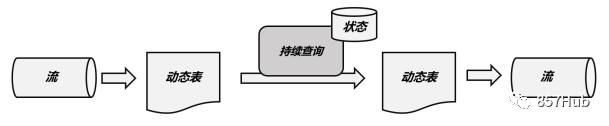
持续查询的步骤如下:
(1)流(stream)被转换为动态表(dynamic table);
(2)对动态表进行持续查询(continuous query),生成新的动态表;
(3)生成的动态表被转换成流。
这样,只要API将流和动态表的转换封装起来,我们就可以直接在数据流上执行SQL查询,用处理表的方式来做流处理了。
3.2 将流转换成动态表
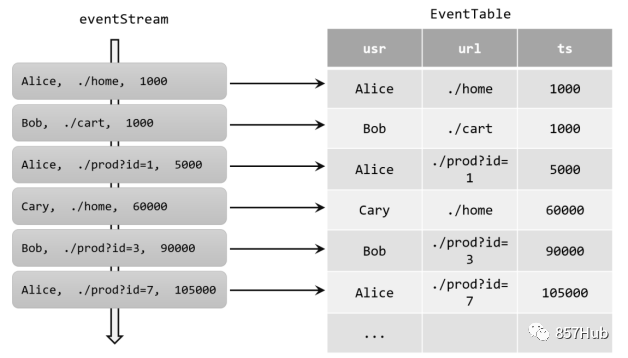
为了能够使用SQL来做流处理,我们必须先把流(stream)转换成动态表。当然,之前在讲解基本API时,已经介绍过代码中的DataStream和Table如何转换;现在我们则要抛开具体的数据类型,从原理上理解流和动态表的转换过程。如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加;所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。例如,当用户点击事件到来时,就对应着动态表中的一次插入(Insert)操作,每条数据就是表中的一行;随着插入更多的点击事件,得到的动态表将不断增长。
3.3 用SQL持续查询
1. 更新(Update)查询
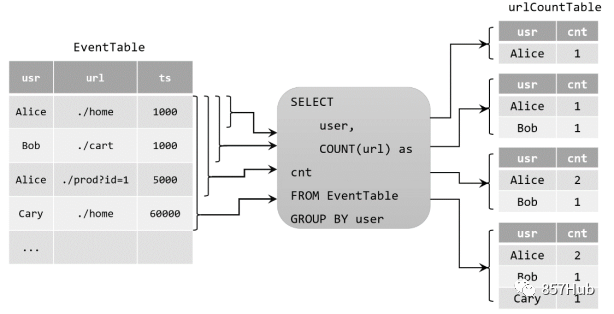
我们在代码中定义了一个SQL查询。
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user");
当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用toChangelogStream()方法。
2. 追加(Append)查询
上面的例子中,查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表EventTable一样,只有插入(Insert)操作了。
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Cary'");
这样的持续查询,就被称为追加查询(Append Query),它定义的结果表的更新日志(changelog)流中只有INSERT操作。追加查询得到的结果表,转换成DataStream调用方法没有限制,可以直接用toDataStream(),也可以像更新查询一样调用toChangelogStream()。
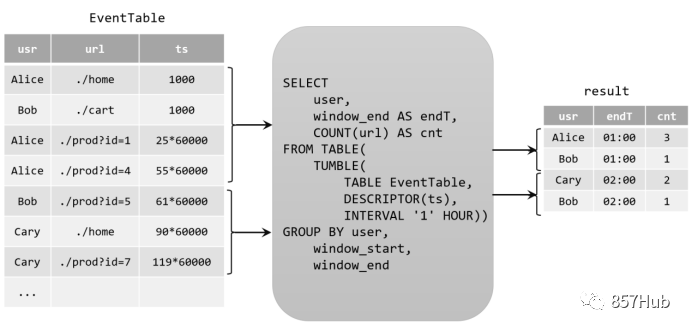
由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入INSERT操作,而没有更新UPDATE操作。所以这里的持续查询,依然是一个追加(Append)查询。结果表result如果转换成DataStream,可以直接调用toDataStream()方法。
3.4 将动态表转换为流
与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)和删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。在Flink中,Table API和SQL支持三种编码方式:
仅追加(Append-only)流
仅通过插入(Insert)更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据,其实就是动态表中新增的每一行。
撤回(Retract)流
撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。具体的编码规则是:INSERT插入操作编码为add消息;DELETE删除操作编码为retract消息;而UPDATE更新操作则编码为被更改行的retract消息,和更新后行(新行)的add消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。

更新插入(Upsert)流
更新插入流中只包含两种类型的消息:更新插入(upsert)消息和删除(delete)消息。所谓的“upsert”其实是“update”和“insert”的合成词,所以对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息;而DELETE删除操作则被编码为delete消息。
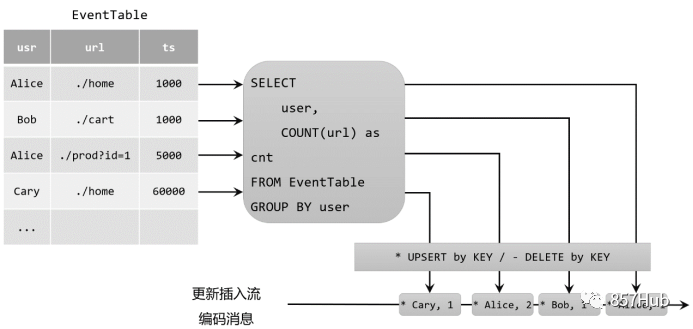
需要注意的是,在代码里将动态表转换为DataStream时,只支持仅追加(append-only)和撤回(retract)流,我们调用toChangelogStream()得到的其实就是撤回流。而连接到外部系统时,则可以支持不同的编码方法,这取决于外部系统本身的特性。
四、时间属性和窗口
基于时间的操作(比如时间窗口),需要定义相关的时间语义和时间数据来源的信息。在Table API和SQL中,会给表单独提供一个逻辑上的时间字段,专门用来在表处理程序中指示时间。所以所谓的时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的DDL里直接定义为一个字段,也可以在DataStream转换成表时定义。一旦定义了时间属性,它就可以作为一个普通字段引用,并且可以在基于时间的操作中使用。时间属性的数据类型为TIMESTAMP,它的行为类似于常规时间戳,可以直接访问并且进行计算。按照时间语义的不同,可以把时间属性的定义分成事件时间(event time)和处理时间(processing time)两种情况。
4.1 事件时间
事件时间属性可以在创建表DDL中定义,也可以在数据流和表的转换中定义。
1. 在创建表的DDL中定义
在创建表的DDL(CREATE TABLE语句)中,可以增加一个字段,通过WATERMARK语句来定义事件时间属性。具体定义方式如下:
CREATE TABLE EventTable(
user STRING,
url STRING,
ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
) WITH (
...
);
这里我们把ts字段定义为事件时间属性,而且基于ts设置了5秒的水位线延迟。
2. 在数据流转换为表时定义
事件时间属性也可以在将DataStream 转换为表的时候来定义。我们调用fromDataStream()方法创建表时,可以追加参数来定义表中的字段结构;这时可以给某个字段加上.rowtime() 后缀,就表示将当前字段指定为事件时间属性。这个字段可以是数据中本不存在、额外追加上去的“逻辑字段”,也可以是本身固有的字段。不论那种方式,时间属性字段中保存的都是事件的时间戳(TIMESTAMP类型)。需要注意的是,这种方式只负责指定时间属性,而时间戳的提取和水位线的生成应该之前就在DataStream上定义好了。在代码中的定义方式如下:
// 方法一:
// 流中数据类型为二元组Tuple2,包含两个字段;需要自定义提取时间戳并生成水位线
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"), $("ts").rowtime());
// 方法二:
// 流中数据类型为三元组Tuple3,最后一个字段就是事件时间戳
DataStream<Tuple3<String, String, Long>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 不再声明额外字段,直接用最后一个字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user"), $("url"), $("ts").rowtime());
4.2 处理时间
在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。类似地,处理时间属性的定义也有两种方式:创建表DDL中定义,或者在数据流转换成表时定义。
1. 在创建表的DDL中定义
在创建表的DDL(CREATE TABLE语句)中,可以增加一个额外的字段,通过调用系统内置的PROCTIME()函数来指定当前的处理时间属性。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
2. 在数据流转换为表时定义
处理时间属性同样可以在将DataStream 转换为表的时候来定义。我们调用fromDataStream()方法创建表时,可以用.proctime()后缀来指定处理时间属性字段。由于处理时间是系统时间,原始数据中并没有这个字段,所以处理时间属性一定不能定义在一个已有字段上,只能定义在表结构所有字段的最后,作为额外的逻辑字段出现。代码中定义处理时间属性的方法如下:
DataStream<Tuple2<String, String>> stream = ...;
// 声明一个额外的字段作为处理时间属性字段
Table table = tEnv.fromDataStream(stream, $("user"), $("url"), $("ts").proctime());
4.3 窗口(Window)
有了时间属性,接下来就可以定义窗口进行计算了。在DataStream API中提供了对不同类型的窗口进行定义和处理的接口,而在Table API和SQL中,类似的功能也都可以实现。
1. 分组窗口(Group Window,老版本)
在Flink 1.12之前的版本中,Table API和SQL提供了一组“分组窗口”(Group Window)函数,常用的时间窗口如滚动窗口、滑动窗口、会话窗口都有对应的实现;具体在SQL中就是调用TUMBLE()、HOP()、SESSION(),传入时间属性字段、窗口大小等参数就可以了。以滚动窗口为例:TUMBLE(ts, INTERVAL '1' HOUR) 这里的ts是定义好的时间属性字段,窗口大小用“时间间隔”INTERVAL来定义。在进行窗口计算时,分组窗口是将窗口本身当作一个字段对数据进行分组的,可以对组内的数据进行聚合。基本使用方式如下:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"TUMBLE_END(ts, INTERVAL '1' HOUR) as endT, " +
"COUNT(url) AS cnt " +
"FROM EventTable " +
"GROUP BY " + // 使用窗口和用户名进行分组
"user, " +
"TUMBLE(ts, INTERVAL '1' HOUR)" // 定义1小时滚动窗口
);
分组窗口的功能比较有限,只支持窗口聚合,所以目前已经处于弃用(deprecated)的状态。
2. 窗口表值函数(Windowing TVFs,新版本)
从1.13版本开始,Flink开始使用窗口表值函数(Windowing table-valued functions, Windowing TVFs)来定义窗口。窗口表值函数是Flink定义的多态表函数(PTF),可以将表进行扩展后返回。表函数(table function)可以看作是返回一个表的函数,关于这部分内容,我们会在11.6节进行介绍。目前Flink提供了以下几个窗口TVF:
滚动窗口(Tumbling Windows)
滑动窗口(Hop Windows,跳跃窗口)
累积窗口(Cumulate Windows)
会话窗口(Session Windows,目前尚未完全支持)
窗口表值函数性能得到了优化,拥有更强大的功能,可以完全替代传统的分组窗口函数。目前窗口TVF的功能还不完善,会话窗口和很多高级功能还不支持,不过正在快速地更新完善。可以预见在未来的版本中,窗口TVF将越来越强大,将会是窗口处理的唯一入口。在SQL中的声明方式,与以前的分组窗口是类似的,直接调用TUMBLE()、HOP()、CUMULATE()就可以实现滚动、滑动和累积窗口,不过传入的参数会有所不同。下面我们就分别对这几种窗口TVF进行介绍。
(1)滚动窗口(TUMBLE)
滚动窗口在SQL中的概念与DataStream API中的定义完全一样,是长度固定、时间对齐、无重叠的窗口,一般用于周期性的统计计算。在SQL中通过调用TUMBLE()函数就可以声明一个滚动窗口,只有一个核心参数就是窗口大小(size)。在SQL中不考虑计数窗口,所以滚动窗口就是滚动时间窗口,参数中还需要将当前的时间属性字段传入;另外,窗口TVF本质上是表函数,可以对表进行扩展,所以还应该把当前查询的表作为参数整体传入。具体声明如下:
TUMBLE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR)
(2)滑动窗口(HOP)
滑动窗口的使用与滚动窗口类似,可以通过设置滑动步长来控制统计输出的频率。在SQL中通过调用HOP()来声明滑动窗口;除了也要传入表名、时间属性外,还需要传入窗口大小(size)和滑动步长(slide)两个参数。
HOP(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '5' MINUTES, INTERVAL '1' HOURS));
需要注意的是,紧跟在时间属性字段后面的第三个参数是步长(slide),第四个参数才是窗口大小(size)。
(3)累积窗口(CUMULATE)
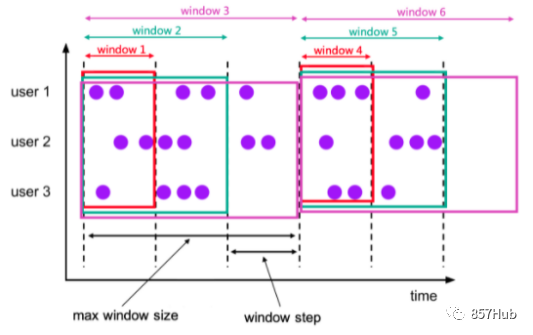
累积窗口是窗口TVF中新增的窗口功能,它会在一定的统计周期内进行累积计算。累积窗口中有两个核心的参数:最大窗口长度(max window size)和累积步长(step)。所谓的最大窗口长度其实就是我们所说的“统计周期”,最终目的就是统计这段时间内的数据 在SQL中可以用CUMULATE()函数来定义,具体如下:
CUMULATE(TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOURS, INTERVAL '1' DAYS))
注意第三个参数为步长step,第四个参数则是最大窗口长度。上面所有的语句只是定义了窗口,类似于DataStream API中的窗口分配器;在SQL中窗口的完整调用,还需要配合聚合操作和其它操作。
五、聚合(Aggregation)查询
Flink 中的SQL是流处理与标准SQL结合的产物,所以聚合查询也可以分成两种:流处理中特有的聚合(主要指窗口聚合),以及SQL原生的聚合查询方式。
5.1 分组聚合
SQL中一般所说的聚合我们都很熟悉,主要是通过内置的一些聚合函数来实现的,比如SUM()、MAX()、MIN()、AVG()以及COUNT()。它们的特点是对多条输入数据进行计算,得到一个唯一的值,属于“多对一”的转换。比如我们可以通过下面的代码计算输入数据的个数:
Table eventCountTable = tableEnv.sqlQuery("select COUNT(*) from EventTable");
而更多的情况下,我们可以通过GROUP BY子句来指定分组的键(key),从而对数据按照某个字段做一个分组统计。例如之前我们举的例子,可以按照用户名进行分组,统计每个用户点击url的次数:
SELECT user, COUNT(url) as cnt FROM EventTable GROUP BY user
这种聚合方式,就叫作“分组聚合”(group aggregation)。想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成DataStream打印输出,需要调用toChangelogStream()。
分组聚合既是SQL原生的聚合查询,也是流处理中的聚合操作,这是实际应用中最常见的聚合方式。当然,使用的聚合函数一般都是系统内置的,如果希望实现特殊需求也可以进行自定义。
5.2 窗口聚合
在Flink的Table API和SQL中,窗口的计算是通过“窗口聚合”(window aggregation)来实现的。与分组聚合类似,窗口聚合也需要调用SUM()、MAX()、MIN()、COUNT()一类的聚合函数,通过GROUP BY子句来指定分组的字段。只不过窗口聚合时,需要将窗口信息作为分组key的一部分定义出来。
在Flink 1.12版本之前,是直接把窗口自身作为分组key放在GROUP BY之后的,所以也叫“分组窗口聚合”;而1.13版本开始使用了“窗口表值函数”(Windowing TVF),窗口本身返回的是就是一个表,所以窗口会出现在FROM后面,GROUP BY后面的则是窗口新增的字段window_start和window_end。例如:
Table result = tableEnv.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"TUMBLE( TABLE EventTable, " +
"DESCRIPTOR(ts), " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
Flink SQL目前提供了滚动窗口TUMBLE()、滑动窗口HOP()和累积窗口(CUMULATE)三种表值函数(TVF)。在具体应用中,我们还需要提前定义好时间属性。下面是一段窗口聚合的完整代码,以累积窗口为例:
public class CumulateWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
);
// 为方便在SQL中引用,在环境中注册表EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 设置累积窗口,执行SQL统计查询
Table result = tableEnv
.sqlQuery(
"SELECT " +
"user, " +
"window_end AS endT, " +
"COUNT(url) AS cnt " +
"FROM TABLE( " +
"CUMULATE( TABLE EventTable, " + // 定义累积窗口
"DESCRIPTOR(ts), " +
"INTERVAL '30' MINUTE, " +
"INTERVAL '1' HOUR)) " +
"GROUP BY user, window_start, window_end "
);
tableEnv.toDataStream(result).print();
env.execute();
}
}
基于窗口的聚合,是流处理中聚合统计的一个特色,也是与标准SQL最大的不同之处。在实际项目中,很多统计指标其实都是基于时间窗口来进行计算的,所以窗口聚合是Flink SQL中非常重要的功能;基于窗口TVF的聚合未来也会有更多功能的扩展支持,比如窗口TOP-N、会话窗口、窗口联结等等。
5.3 开窗(Over)聚合
在标准SQL中还有另外一类比较特殊的聚合方式,可以针对每一行计算一个聚合值,这就是所谓的“开窗函数”。开窗函数的聚合与之前两种聚合有本质的不同:分组聚合、窗口TVF聚合都是“多对一”的关系,将数据分组之后每组只会得到一个聚合结果;而开窗函数是对每行都要做一次开窗聚合,因此聚合之后表中的行数不会有任何减少,是一个“多对多”的关系。
与标准SQL中一致,Flink SQL中的开窗函数也是通过OVER子句来实现的,所以有时开窗聚合也叫作“OVER聚合”(Over Aggregation)。基本语法如下:
SELECT
<聚合函数> OVER (
[PARTITION BY <字段1>[, <字段2>, ...]]
ORDER BY <时间属性字段>
<开窗范围>),
...
FROM ...
这里OVER关键字前面是一个聚合函数,它会应用在后面OVER定义的窗口上。在OVER子句中主要有以下几个部分:
PARTITION BY(可选)
用来指定分区的键(key),类似于GROUP BY的分组,这部分是可选的;
ORDER BY
在OVER子句中必须用ORDER BY明确地指出数据基于那个字段排序。在Flink的流处理中,目前只支持按照时间属性的升序排列,所以这里ORDER BY后面的字段必须是定义好的时间属性。
开窗范围
由BETWEEN <下界> AND <上界> 定义,也就是“从下界到上界”的范围。目前支持的上界只能是CURRENT ROW,也就是定义一个“从之前某一行到当前行”的范围,所以一般的形式为:
BETWEEN ... PRECEDING AND CURRENT ROW
开窗选择的范围可以基于时间,也可以基于数据的数量。所以开窗范围还应该在两种模式之间做出选择:范围间隔(RANGE intervals)和行间隔(ROW intervals)。
范围间隔
范围间隔以RANGE为前缀,就是基于ORDER BY指定的时间字段去选取一个范围,一般就是当前行时间戳之前的一段时间。例如开窗范围选择当前行之前1小时的数据:
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
行间隔
行间隔以ROWS为前缀,就是直接确定要选多少行,由当前行出发向前选取就可以了。例如开窗范围选择当前行之前的5行数据(最终聚合会包括当前行,所以一共6条数据):
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
下面是一个具体示例:
SELECT user, ts,
COUNT(url) OVER (
PARTITION BY user
ORDER BY ts
RANGE BETWEEN INTERVAL '1' HOUR PRECEDING AND CURRENT ROW
) AS cnt
FROM EventTable
开窗聚合与窗口聚合(窗口TVF聚合)本质上不同,不过也还是有一些相似之处的:它们都是在无界的数据流上划定了一个范围,截取出有限数据集进行聚合统计;这其实都是“窗口”的思路。事实上,在Table API中确实就定义了两类窗口:分组窗口(GroupWindow)和开窗窗口(OverWindow);而在SQL中,也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口:
SELECT user, ts,
COUNT(url) OVER w AS cnt,
MAX(CHAR_LENGTH(url)) OVER w AS max_url
FROM EventTable
WINDOW w AS (
PARTITION BY user
ORDER BY ts
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
上面的SQL中定义了一个选取之前2行数据的OVER窗口,并重命名为w;接下来就可以基于它调用多个聚合函数,扩展出更多的列提取出来。
5.4 应用实例 —— TOP-N
目前在Flink SQL中没有能够直接调用的TOP-N函数,而是提供了稍微复杂些的变通实现方法。下面是一个具体案例的代码实现。由于用户访问事件Event中没有商品相关信息,因此我们统计每小时内有最多访问行为的用户,取前两名,相当于是一个每小时活跃用户的查询。
public class WindowTopNExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源,并分配时间戳、生成水位线
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 25 * 60 * 1000L),
new Event("Alice", "./prod?id=4", 55 * 60 * 1000L),
new Event("Bob", "./prod?id=5", 3600 * 1000L + 60 * 1000L),
new Event("Cary", "./home", 3600 * 1000L + 30 * 60 * 1000L),
new Event("Cary", "./prod?id=7", 3600 * 1000L + 59 * 60 * 1000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
// 创建表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表,并指定时间属性
Table eventTable = tableEnv.fromDataStream(
eventStream,
$("user"),
$("url"),
$("timestamp").rowtime().as("ts")
// 将timestamp指定为事件时间,并命名为ts
);
// 为方便在SQL中引用,在环境中注册表EventTable
tableEnv.createTemporaryView("EventTable", eventTable);
// 定义子查询,进行窗口聚合,得到包含窗口信息、用户以及访问次数的结果表
String subQuery =
"SELECT window_start, window_end, user, COUNT(url) as cnt " +
"FROM TABLE ( " +
"TUMBLE( TABLE EventTable, DESCRIPTOR(ts), INTERVAL '1' HOUR )) " +
"GROUP BY window_start, window_end, user ";
// 定义TOP-N的外层查询
String topNQuery =
"SELECT * " +
"FROM (" +
"SELECT *, " +
"ROW_NUMBER() OVER ( " +
"PARTITION BY window_start, window_end " +
"ORDER BY cnt desc " +
") AS row_num " +
"FROM (" + subQuery + ")) " +
"WHERE row_num <= 2";
// 执行SQL得到结果表
Table result = tableEnv.sqlQuery(topNQuery);
tableEnv.toDataStream(result).print();
env.execute();
}
}
六、联结(Join)查询
在标准SQL中,可以将多个表连接合并起来,从中查询出想要的信息;这种操作就是表的联结(Join)。在Flink SQL中,同样支持各种灵活的联结(Join)查询,操作的对象是动态表。在流处理中,动态表的Join对应着两条数据流的Join操作。Flink SQL中的联结查询大体上也可以分为两类:SQL原生的联结查询方式,和流处理中特有的联结查询。
6.1 常规联结查询
常规联结(Regular Join)是SQL中原生定义的Join方式,是最通用的一类联结操作。它的具体语法与标准SQL的联结完全相同,通过关键字JOIN来联结两个表,后面用关键字ON来指明联结条件。与标准SQL一致,Flink SQL的常规联结也可以分为内联结(INNER JOIN)和外联结(OUTER JOIN),区别在于结果中是否包含不符合联结条件的行。目前仅支持“等值条件”作为联结条件,也就是关键字ON后面必须是判断两表中字段相等的逻辑表达式。
1. 等值内联结(INNER Equi-JOIN)
内联结用INNER JOIN来定义,会返回两表中符合联接条件的所有行的组合,也就是所谓的笛卡尔积(Cartesian product)。目前仅支持等值联结条件。例如:
SELECT *
FROM Order
INNER JOIN Product
ON Order.product_id = Product.id
2. 等值外联结(OUTER Equi-JOIN)
与内联结类似,外联结也会返回符合联结条件的所有行的笛卡尔积;另外,还可以将某一侧表中找不到任何匹配的行也单独返回。Flink SQL支持左外(LEFT JOIN)、右外(RIGHT JOIN)和全外(FULL OUTER JOIN),分别表示会将左侧表、右侧表以及双侧表中没有任何匹配的行返回。具体用法如下:
SELECT *
FROM Order
LEFT JOIN Product
ON Order.product_id = Product.id
SELECT *
FROM Order
RIGHT JOIN Product
ON Order.product_id = Product.id
SELECT *
FROM Order
FULL OUTER JOIN Product
ON Order.product_id = Product.id
这部分知识与标准SQL中是完全一样的。
6.2 间隔联结查询
我们曾经学习过DataStream API中的双流Join,包括窗口联结(window join)和间隔联结(interval join)。两条流的Join就对应着SQL中两个表的Join,这是流处理中特有的联结方式。目前Flink SQL还不支持窗口联结,而间隔联结则已经实现。间隔联结(Interval Join)返回的,同样是符合约束条件的两条中数据的笛卡尔积。只不过这里的“约束条件”除了常规的联结条件外,还多了一个时间间隔的限制。具体语法有以下要点:
两表的联结
间隔联结不需要用JOIN关键字,直接在FROM后将要联结的两表列出来就可以,用逗号分隔。这与标准SQL中的语法一致,表示一个“交叉联结”(Cross Join),会返回两表中所有行的笛卡尔积。
联结条件
联结条件用WHERE子句来定义,用一个等值表达式描述。交叉联结之后再用WHERE进行条件筛选,效果跟内联结INNER JOIN ... ON ...非常类似。
时间间隔限制
我们可以在WHERE子句中,联结条件后用AND追加一个时间间隔的限制条件;做法是提取左右两侧表中的时间字段,然后用一个表达式来指明两者需要满足的间隔限制。具体定义方式有下面三种,这里分别用ltime和rtime表示左右表中的时间字段:
(1)ltime = rtime
(2)ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
(3)ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
例如,我们现在除了订单表Order外,还有一个“发货表”Shipment,要求在收到订单后四个小时内发货。那么我们就可以用一个间隔联结查询,把所有订单与它对应的发货信息连接合并在一起返回。
SELECT *
FROM Order o, Shipment s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
七、函数
在SQL中,我们可以把一些数据的转换操作包装起来,嵌入到SQL查询中统一调用,这就是“函数”(functions)。Flink的Table API和SQL同样提供了函数的功能。两者在调用时略有不同:Table API中的函数是通过数据对象的方法调用来实现的;而SQL则是直接引用函数名称,传入数据作为参数。例如,要把一个字符串str转换成全大写的形式,Table API的写法是调用str这个String对象的upperCase()方法:
str.upperCase();
而SQL中的写法就是直接引用UPPER()函数,将str作为参数传入:
UPPER(str)
由于Table API是内嵌在Java语言中的,很多方法需要在类中额外添加,因此扩展功能比较麻烦,目前支持的函数比较少;而且Table API也不如SQL的通用性强,所以一般情况下较少使用。下面我们主要介绍Flink SQL中函数的使用。
Flink SQL中的函数可以分为两类:一类是SQL中内置的系统函数,直接通过函数名调用就可以,能够实现一些常用的转换操作,比如之前我们用到的COUNT()、CHAR_LENGTH()、UPPER()等等;而另一类函数则是用户自定义的函数(UDF),需要在表环境中注册才能使用。
7.1 系统函数
系统函数(System Functions)也叫内置函数(Built-in Functions),是在系统中预先实现好的功能模块。我们可以通过固定的函数名直接调用,实现想要的转换操作。Flink SQL提供了大量的系统函数,几乎支持所有的标准SQL中的操作,这为我们使用SQL编写流处理程序提供了极大的方便。
Flink SQL中的系统函数又主要可以分为两大类:标量函数(Scalar Functions)和聚合函数(Aggregate Functions)。
1. 标量函数(Scalar Functions)
标量函数指的就是只对输入数据做转换操作、返回一个值的函数。标量函数是最常见、也最简单的一类系统函数,数量非常庞大,很多在标准SQL中也有定义。所以我们这里只对一些常见类型列举部分函数,做一个简单概述,具体应用可以查看官网的完整函数列表。
比较函数(Comparison Functions)
比较函数其实就是一个比较表达式,用来判断两个值之间的关系,返回一个布尔类型的值。这个比较表达式可以是用 <、>、= 等符号连接两个值,也可以是用关键字定义的某种判断。例如:
(1)value1 = value2 判断两个值相等;
(2)value1 <> value2 判断两个值不相等
(3)value IS NOT NULL 判断value不为空
逻辑函数(Logical Functions)
逻辑函数就是一个逻辑表达式,也就是用与(AND)、或(OR)、非(NOT)将布尔类型的值连接起来,也可以用判断语句(IS、IS NOT)进行真值判断;返回的还是一个布尔类型的值。例如:
(1)boolean1 OR boolean2 布尔值boolean1与布尔值boolean2取逻辑或
(2)boolean IS FALSE 判断布尔值boolean是否为false
(3)NOT boolean 布尔值boolean取逻辑非
算术函数(Arithmetic Functions)
进行算术计算的函数,包括用算术符号连接的运算,和复杂的数学运算。例如:
(1)numeric1 + numeric2 两数相加
(2)POWER(numeric1, numeric2) 幂运算,取数numeric1的numeric2次方
(3)RAND() 返回(0.0, 1.0)区间内的一个double类型的伪随机数
字符串函数(String Functions)
进行字符串处理的函数。例如:
(1)string1 || string2 两个字符串的连接
(2)UPPER(string) 将字符串string转为全部大写
(3)CHAR_LENGTH(string) 计算字符串string的长度
时间函数(Temporal Functions)
进行与时间相关操作的函数。例如:
(1)DATE string 按格式"yyyy-MM-dd"解析字符串string,返回类型为SQL Date
(2)TIMESTAMP string 按格式"yyyy-MM-dd HH:mm:ss[.SSS]"解析,返回类型为SQL timestamp
(3)CURRENT_TIME 返回本地时区的当前时间,类型为SQL time(与LOCALTIME等价)
(4)INTERVAL string range 返回一个时间间隔。
2. 聚合函数(Aggregate Functions)
聚合函数是以表中多个行作为输入,提取字段进行聚合操作的函数,会将唯一的聚合值作为结果返回。聚合函数应用非常广泛,不论分组聚合、窗口聚合还是开窗(Over)聚合,对数据的聚合操作都可以用相同的函数来定义。标准SQL中常见的聚合函数Flink SQL都是支持的,目前也在不断扩展,为流处理应用提供更强大的功能。例如:
(1)COUNT(*) 返回所有行的数量,统计个数。
(2)SUM([ ALL | DISTINCT ] expression) 对某个字段进行求和操作。默认情况下省略了关键字ALL,表示对所有行求和;如果指定DISTINCT,则会对数据进行去重,每个值只叠加一次。
(3)RANK() 返回当前值在一组值中的排名。
(4)ROW_NUMBER() 对一组值排序后,返回当前值的行号。
其中,RANK()和ROW_NUMBER()一般用在OVER窗口中。
7.2 自定义函数(UDF)
系统函数尽管庞大,也不可能涵盖所有的功能;如果有系统函数不支持的需求,我们就需要用自定义函数(User Defined Functions,UDF)来实现了。Flink的Table API和SQL提供了多种自定义函数的接口,以抽象类的形式定义。当前UDF主要有以下几类:
标量函数(Scalar Functions):将输入的标量值转换成一个新的标量值;
表函数(Table Functions):将标量值转换成一个或多个新的行数据,也就是扩展成一个表;
聚合函数(Aggregate Functions):将多行数据里的标量值转换成一个新的标量值;
表聚合函数(Table Aggregate Functions):将多行数据里的标量值转换成一个或多个新的行数据。
1. 整体调用流程要想在代码中使用自定义的函数,我们需要首先自定义对应UDF抽象类的实现,并在表环境中注册这个函数,然后就可以在Table API和SQL中调用了。
(1)注册函数
注册函数时需要调用表环境的createTemporarySystemFunction()方法,传入注册的函数名以及UDF类的Class对象:
// 注册函数
tableEnv.createTemporarySystemFunction("MyFunction", MyFunction.class);
我们自定义的UDF类叫作MyFunction,它应该是上面四种UDF抽象类中某一个的具体实现;在环境中将它注册为名叫MyFunction的函数。
(2)使用Table API调用函数
在Table API中,需要使用call()方法来调用自定义函数:
tableEnv.from("MyTable").select(call("MyFunction", $("myField")));
这里call()方法有两个参数,一个是注册好的函数名MyFunction,另一个则是函数调用时本身的参数。这里我们定义MyFunction在调用时,需要传入的参数是myField字段。
(3)在SQL中调用函数
当我们将函数注册为系统函数之后,在SQL中的调用就与内置系统函数完全一样了:
tableEnv.sqlQuery("SELECT MyFunction(myField) FROM MyTable");
可见,SQL的调用方式更加方便,我们后续依然会以SQL为例介绍UDF的用法。
2. 标量函数(Scalar Functions)
自定义标量函数可以把0个、 1个或多个标量值转换成一个标量值,它对应的输入是一行数据中的字段,输出则是唯一的值。所以从输入和输出表中行数据的对应关系看,标量函数是“一对一”的转换。想要实现自定义的标量函数,我们需要自定义一个类来继承抽象类ScalarFunction,并实现叫作eval() 的求值方法。标量函数的行为就取决于求值方法的定义,它必须是公有的(public),而且名字必须是eval。求值方法eval可以重载多次,任何数据类型都可作为求值方法的参数和返回值类型。
这里需要特别说明的是,ScalarFunction抽象类中并没有定义eval()方法,所以我们不能直接在代码中重写(override);但Table API的框架底层又要求了求值方法必须名字为eval()。这是Table API和SQL目前还显得不够完善的地方,未来的版本应该会有所改进。下面我们来看一个具体的例子。我们实现一个自定义的哈希(hash)函数HashFunction,用来求传入对象的哈希值。
public static class HashFunction extends ScalarFunction {
// 接受任意类型输入,返回 INT 型输出
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
// 注册函数
tableEnv.createTemporarySystemFunction("HashFunction", HashFunction.class);
// 在 SQL 里调用注册好的函数
tableEnv.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
这里我们自定义了一个ScalarFunction,实现了eval()求值方法,将任意类型的对象传入,得到一个Int类型的哈希值返回。当然,具体的求哈希操作就省略了,直接调用对象的hashCode()方法即可。
另外注意,由于Table API在对函数进行解析时需要提取求值方法参数的类型引用,所以我们用DataTypeHint(inputGroup = InputGroup.ANY)对输入参数的类型做了标注,表示eval的参数可以是任意类型。
3. 表函数(Table Functions)
跟标量函数一样,表函数的输入参数也可以是 0个、1个或多个标量值;不同的是,它可以返回任意多行数据。“多行数据”事实上就构成了一个表,所以“表函数”可以认为就是返回一个表的函数,这是一个“一对多”的转换关系。之前我们介绍过的窗口TVF,本质上就是表函数。
类似地,要实现自定义的表函数,需要自定义类来继承抽象类TableFunction,内部必须要实现的也是一个名为 eval 的求值方法。与标量函数不同的是,TableFunction类本身是有一个泛型参数T的,这就是表函数返回数据的类型;而eval()方法没有返回类型,内部也没有return语句,是通过调用collect()方法来发送想要输出的行数据的。
在SQL中调用表函数,需要使用LATERAL TABLE()来生成扩展的“侧向表”,然后与原始表进行联结(Join)。这里的Join操作可以是直接做交叉联结(cross join),在FROM后用逗号分隔两个表就可以;也可以是以ON TRUE为条件的左联结(LEFT JOIN)。
下面是表函数的一个具体示例。我们实现了一个分隔字符串的函数SplitFunction,可以将一个字符串转换成(字符串,长度)的二元组。
// 注意这里的类型标注,输出是Row类型,Row中包含两个字段:word和length。
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public static class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
// 使用collect()方法发送一行数据
collect(Row.of(s, s.length()));
}
}
}
// 注册函数
tableEnv.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
// 在 SQL 里调用注册好的函数
// 1. 交叉联结
tableEnv.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
// 2. 带ON TRUE条件的左联结
tableEnv.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE");
// 重命名侧向表中的字段
tableEnv.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE");
这里我们直接将表函数的输出类型定义成了ROW,这就是得到的侧向表中的数据类型;每行数据转换后也只有一行。我们分别用交叉联结和左联结两种方式在SQL中进行了调用,还可以对侧向表的中字段进行重命名。
4. 聚合函数(Aggregate Functions)
用户自定义聚合函数(User Defined AGGregate function,UDAGG)会把一行或多行数据(也就是一个表)聚合成一个标量值。这是一个标准的“多对一”的转换。聚合函数的概念我们之前已经接触过多次,如SUM()、MAX()、MIN()、AVG()、COUNT()都是常见的系统内置聚合函数。而如果有些需求无法直接调用系统函数解决,我们就必须自定义聚合函数来实现功能了。自定义聚合函数需要继承抽象类AggregateFunction。AggregateFunction有两个泛型参数<T, ACC>,T表示聚合输出的结果类型,ACC则表示聚合的中间状态类型。
Flink SQL中的聚合函数的工作原理如下:
(1)首先,它需要创建一个累加器(accumulator),用来存储聚合的中间结果。这与DataStream API中的AggregateFunction非常类似,累加器就可以看作是一个聚合状态。调用createAccumulator()方法可以创建一个空的累加器。
(2)对于输入的每一行数据,都会调用accumulate()方法来更新累加器,这是聚合的核心过程。
(3)当所有的数据都处理完之后,通过调用getValue()方法来计算并返回最终的结果。
所以,每个 AggregateFunction 都必须实现以下几个方法:
createAccumulator()
这是创建累加器的方法。没有输入参数,返回类型为累加器类型ACC。
accumulate()
这是进行聚合计算的核心方法,每来一行数据都会调用。它的第一个参数是确定的,就是当前的累加器,类型为ACC,表示当前聚合的中间状态;后面的参数则是聚合函数调用时传入的参数,可以有多个,类型也可以不同。这个方法主要是更新聚合状态,所以没有返回类型。需要注意的是,accumulate()与之前的求值方法eval()类似,也是底层架构要求的,必须为public,方法名必须为accumulate,且无法直接override、只能手动实现。
getValue()
这是得到最终返回结果的方法。输入参数是ACC类型的累加器,输出类型为T。
在遇到复杂类型时,Flink 的类型推导可能会无法得到正确的结果。所以AggregateFunction也可以专门对累加器和返回结果的类型进行声明,这是通过 getAccumulatorType()和getResultType()两个方法来指定的。AggregateFunction 的所有方法都必须是 公有的(public),不能是静态的(static),而且名字必须跟上面写的完全一样。createAccumulator、getValue、getResultType 以及 getAccumulatorType 这几个方法是在抽象类 AggregateFunction 中定义的,可以override;而其他则都是底层架构约定的方法。
下面举一个具体的示例,我们从学生的分数表ScoreTable中计算每个学生的加权平均分。
// 累加器类型定义
public static class WeightedAvgAccumulator {
public long sum = 0; // 加权和
public int count = 0; // 数据个数
}
// 自定义聚合函数,输出为长整型的平均值,累加器类型为 WeightedAvgAccumulator
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccumulator> {
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator(); // 创建累加器
}
@Override
public Long getValue(WeightedAvgAccumulator acc) {
if (acc.count == 0) {
return null; // 防止除数为0
} else {
return acc.sum / acc.count; // 计算平均值并返回
}
}
// 累加计算方法,每来一行数据都会调用
public void accumulate(WeightedAvgAccumulator acc, Long iValue, Integer iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
}
// 注册自定义聚合函数
tableEnv.createTemporarySystemFunction("WeightedAvg", WeightedAvg.class);
// 调用函数计算加权平均值
Table result = tableEnv.sqlQuery(
"SELECT student, WeightedAvg(score, weight) FROM ScoreTable GROUP BY student"
);
聚合函数的accumulate()方法有三个输入参数。第一个是WeightedAvgAccum类型的累加器;另外两个则是函数调用时输入的字段:要计算的值 ivalue 和 对应的权重 iweight。这里我们并不考虑其它方法的实现,只要有必须的三个方法就可以了。
5. 表聚合函数(Table Aggregate Functions)
用户自定义表聚合函数(UDTAGG)可以把一行或多行数据(也就是一个表)聚合成另一张表,结果表中可以有多行多列。很明显,这就像表函数和聚合函数的结合体,是一个“多对多”的转换。自定义表聚合函数需要继承抽象类TableAggregateFunction。TableAggregateFunction的结构和原理与AggregateFunction非常类似,同样有两个泛型参数<T, ACC>,用一个ACC类型的累加器(accumulator)来存储聚合的中间结果。聚合函数中必须实现的三个方法,在TableAggregateFunction中也必须对应实现:
createAccumulator()
创建累加器的方法,与AggregateFunction中用法相同。
accumulate()
聚合计算的核心方法,与AggregateFunction中用法相同。
emitValue()
所有输入行处理完成后,输出最终计算结果的方法。这个方法对应着AggregateFunction中的getValue()方法;区别在于emitValue没有输出类型,而输入参数有两个:第一个是ACC类型的累加器,第二个则是用于输出数据的“收集器”out,它的类型为Collect<T>。另外,emitValue()在抽象类中也没有定义,无法override,必须手动实现。
表聚合函数相对比较复杂,它的一个典型应用场景就是TOP-N查询。比如我们希望选出一组数据排序后的前两名,这就是最简单的TOP-2查询。没有现成的系统函数,那么我们就可以自定义一个表聚合函数来实现这个功能。在累加器中应该能够保存当前最大的两个值,每当来一条新数据就在accumulate()方法中进行比较更新,最终在emitValue()中调用两次out.collect()将前两名数据输出。具体代码如下:
// 聚合累加器的类型定义,包含最大的第一和第二两个数据
public static class Top2Accumulator {
public Integer first;
public Integer second;
}
// 自定义表聚合函数,查询一组数中最大的两个,返回值为(数值,排名)的二元组
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accumulator> {
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator acc = new Top2Accumulator();
acc.first = Integer.MIN_VALUE; // 为方便比较,初始值给最小值
acc.second = Integer.MIN_VALUE;
return acc;
}
// 每来一个数据调用一次,判断是否更新累加器
public void accumulate(Top2Accumulator acc, Integer value) {
if (value > acc.first) {
acc.second = acc.first;
acc.first = value;
} else if (value > acc.second) {
acc.second = value;
}
}
// 输出(数值,排名)的二元组,输出两行数据
public void emitValue(Top2Accumulator acc, Collector<Tuple2<Integer, Integer>> out) {
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
目前SQL中没有直接使用表聚合函数的方式,所以需要使用Table API的方式来调用:
// 注册表聚合函数函数
tableEnv.createTemporarySystemFunction("Top2", Top2.class);
// 在Table API中调用函数
tableEnv.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call("Top2", $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
这里使用了flatAggregate()方法,它就是专门用来调用表聚合函数的接口。对MyTable中数据按myField字段进行分组聚合,统计value值最大的两个;并将聚合结果的两个字段重命名为value和rank,之后就可以使用select()将它们提取出来了。
八、连接到外部系统
在Table API和SQL编写的Flink程序中,可以在创建表的时候用WITH子句指定连接器(connector),这样就可以连接到外部系统进行数据交互了。Flink的Table API和SQL支持了各种不同的连接器。当然,最简单的其实就是连接到控制台打印输出:
CREATE TABLE ResultTable (
user STRING,
cnt BIGINT
WITH (
'connector' = 'print'
);
这里只需要在WITH中定义connector为print就可以了。而对于其它的外部系统,则需要增加一些配置项。
8.1 Kafka
Kafka的SQL连接器可以从Kafka的主题(topic)读取数据转换成表,也可以将表数据写入Kafka的主题。换句话说,创建表的时候指定连接器为Kafka,则这个表既可以作为输入表,也可以作为输出表。
1. 引入依赖
想要在Flink程序中使用Kafka连接器,需要引入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
这里我们引入的Flink和Kafka的连接器,与之前DataStream API中引入的连接器是一样的。如果想在SQL客户端里使用Kafka连接器,还需要下载对应的jar包放到lib目录下。另外,Flink为各种连接器提供了一系列的“表格式”(table formats),比如CSV、JSON、Avro、Parquet等等。这些表格式定义了底层存储的二进制数据和表的列之间的转换方式,相当于表的序列化工具。对于Kafka而言,CSV、JSON、Avro等主要格式都是支持的, 根据Kafka连接器中配置的格式,我们可能需要引入对应的依赖支持。以CSV为例:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
由于SQL客户端中已经内置了CSV、JSON的支持,因此使用时无需专门引入;而对于没有内置支持的格式(比如Avro),则仍然要下载相应的jar包。
2. 创建连接到Kafka的表
创建一个连接到Kafka表,需要在CREATE TABLE的DDL中在WITH子句里指定连接器为Kafka,并定义必要的配置参数。下面是一个具体示例:
CREATE TABLE KafkaTable (
`user` STRING,
`url` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'events',
'properties.bootstrap.servers' = 'hadoop102:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
3. Upsert Kafka
正常情况下,Kafka作为保持数据顺序的消息队列,读取和写入都应该是流式的数据,对应在表中就是仅追加(append-only)模式。如果我们想要将有更新操作(比如分组聚合)的结果表写入Kafka,就会因为Kafka无法识别撤回(retract)或更新插入(upsert)消息而导致异常。为了解决这个问题,Flink专门增加了一个“更新插入Kafka”(Upsert Kafka)连接器。这个连接器支持以更新插入(UPSERT)的方式向Kafka的topic中读写数据。下面是一个创建和使用Upsert Kafka表的例子:
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = '...',
'key.format' = 'avro',
'value.format' = 'avro'
);
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP,
user_region STRING,
WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'pageviews',
'properties.bootstrap.servers' = '...',
'format' = 'json'
);
-- 计算 pv、uv 并插入到 upsert-kafka表中
INSERT INTO pageviews_per_region
SELECT
user_region,
COUNT(*),
COUNT(DISTINCT user_id)
FROM pageviews
GROUP BY user_region;
8.2 文件系统
另一类非常常见的外部系统就是文件系统(File System)了。Flink提供了文件系统的连接器,支持从本地或者分布式的文件系统中读写数据。这个连接器是内置在Flink中的,所以使用它并不需要额外引入依赖。下面是一个连接到文件系统的示例:
CREATE TABLE MyTable (
column_name1 INT,
column_name2 STRING,
...
part_name1 INT,
part_name2 STRING
) PARTITIONED BY (part_name1, part_name2) WITH (
'connector' = 'filesystem', -- 连接器类型
'path' = '...', -- 文件路径
'format' = '...' -- 文件格式
)
这里在WITH前使用了PARTITIONED BY对数据进行了分区操作。文件系统连接器支持对分区文件的访问。
8.3 JDBC
Flink提供的JDBC连接器可以通过JDBC驱动程序(driver)向任意的关系型数据库读写数据,比如MySQL、PostgreSQL、Derby等。作为TableSink向数据库写入数据时,运行的模式取决于创建表的DDL是否定义了主键(primary key)。如果有主键,那么JDBC连接器就将以更新插入(Upsert)模式运行,可以向外部数据库发送按照指定键(key)的更新(UPDATE)和删除(DELETE)操作;如果没有定义主键,那么就将在追加(Append)模式下运行,不支持更新和删除操作。
1. 引入依赖
想要在Flink程序中使用JDBC连接器,需要引入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
此外,为了连接到特定的数据库,我们还用引入相关的driver依赖,比如MySQL:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
2. 创建JDBC表
创建JDBC表的方法与前面Upsert Kafka大同小异。下面是一个具体示例:-- 创建一张连接到 MySQL的表
CREATE TABLE MyTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/mydatabase',
'table-name' = 'users'
);
-- 将另一张表 T的数据写入到 MyTable 表中
INSERT INTO MyTable
SELECT id, name, age, status FROM T;
这里创建表的DDL中定义了主键,所以数据会以Upsert模式写入到MySQL表中;而到MySQL的连接,是通过WITH子句中的url定义的。
8.4 Elasticsearch
Elasticsearch作为分布式搜索分析引擎,在大数据应用中有非常多的场景。Flink提供的Elasticsearch的SQL连接器只能作为TableSink,可以将表数据写入Elasticsearch的索引(index)。Elasticsearch连接器的使用与JDBC连接器非常相似,写入数据的模式同样是由创建表的DDL中是否有主键定义决定的。
1. 引入依赖
想要在Flink程序中使用Elasticsearch连接器,需要引入对应的依赖。具体的依赖与Elasticsearch服务器的版本有关,对于6.x版本引入依赖如下:
<dependency>
<groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
对于Elasticsearch 7以上的版本,引入的依赖则是:
<dependency>
<groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch7_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
2. 创建连接到Elasticsearch的表
创建Elasticsearch表的方法与JDBC表基本一致。下面是一个具体示例:
-- 创建一张连接到 Elasticsearch的 表
CREATE TABLE MyTable (
user_id STRING,
user_name STRING
uv BIGINT,
pv BIGINT,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'elasticsearch-7',
'hosts' = 'http://hadoop102:9200',
'index' = 'users'
);
这里定义了主键,所以会以更新插入(Upsert)模式向Elasticsearch写入数据。
END
腾讯云开发者
