一网打尽:测序数据下载


摘要
SRA(Sequence Read Archive) 与 ENA(European Nucleotide Archive) 数据库基本上保存了 90% 以上的测序原始数据。其中 SRA 数据库位于在美国,ENA 数据库在欧洲。所以,国内的研究人员想要从中下载数据,是一件棘手的事情。因此本文将介绍 3 种下载方式,让您免受数据下载之痛,赢在科研起跑线。
1. 迅雷
第一种办法是利用迅雷来进行下载,它是三种办法中最稳定,但同时也是最慢的办法。
以SRR4785812为例,首先在 SRA 数据库中检索SRR4785812,结果如下:
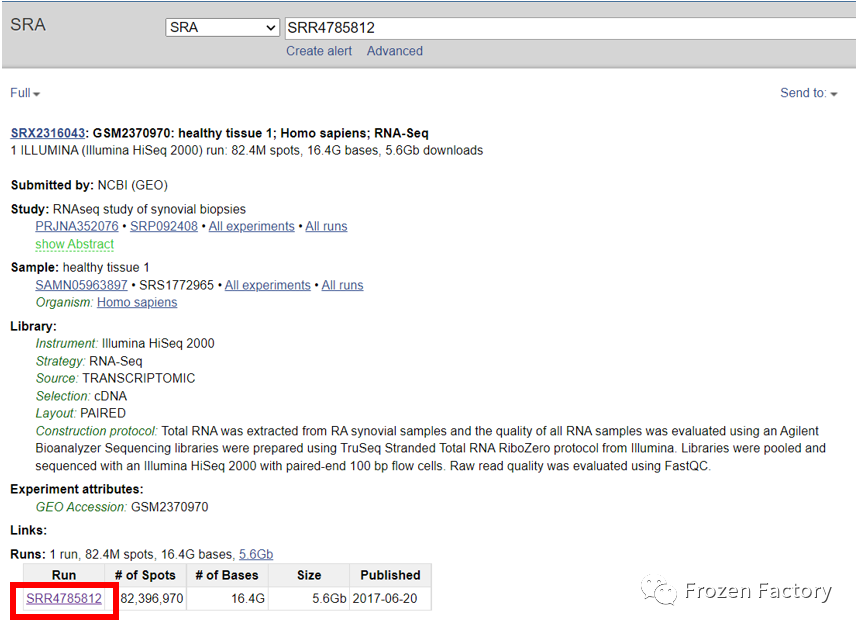
单击上方被红色框选的 ID 即可跳转到数据下载页面,如下图所示:
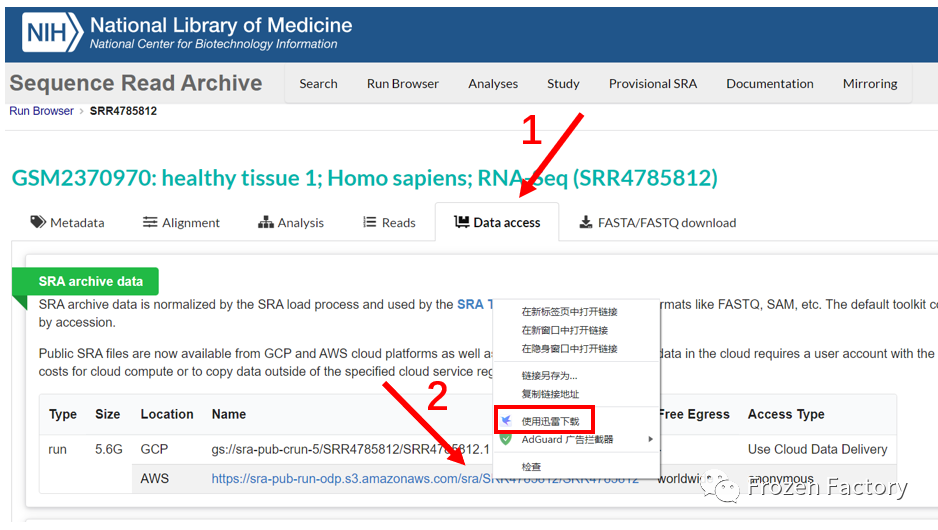
首先点击一号箭头所指的Data access模块,再右键单击二号箭头所指的链接,选择使用迅雷下载即可。
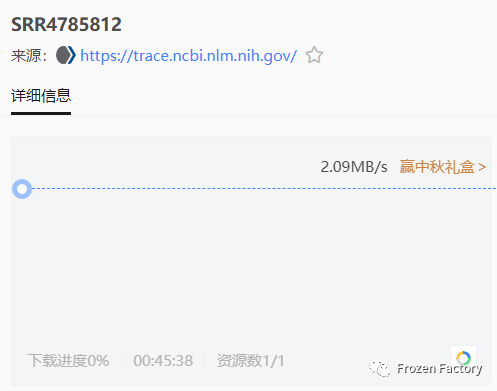
小编实测,平均下载速度可达到2MB/s。
2. ASCP
第二种是Aspera,它是 IBM 公司的一款高速传输软件,创造了新一代的传输技术(faspTM),并能不受文件大小、形态、传输距离、网络条件限制,以最高效的速度来协助用户迁移各地的数据。使用 fasp 传输专利技术,充分利用现有的 WAN 基础设施和通用硬件,传输速度比 FTP 和 HTTP 快达数百倍。
Aspera是三种办法中最快,但同时也是最不稳定的,且配置有一点点麻烦。
- Aspera 安装
考虑到安装依赖的复杂性,小编建议直接使用conda新建环境安装。
# 创建环境并安装Aspera
conda create -n ascp -c hcc aspera-cli -y
# 激活环境
conda activate ascp- 使用方法
首先在ENA数据库中检索SRR4785812,结果如下:
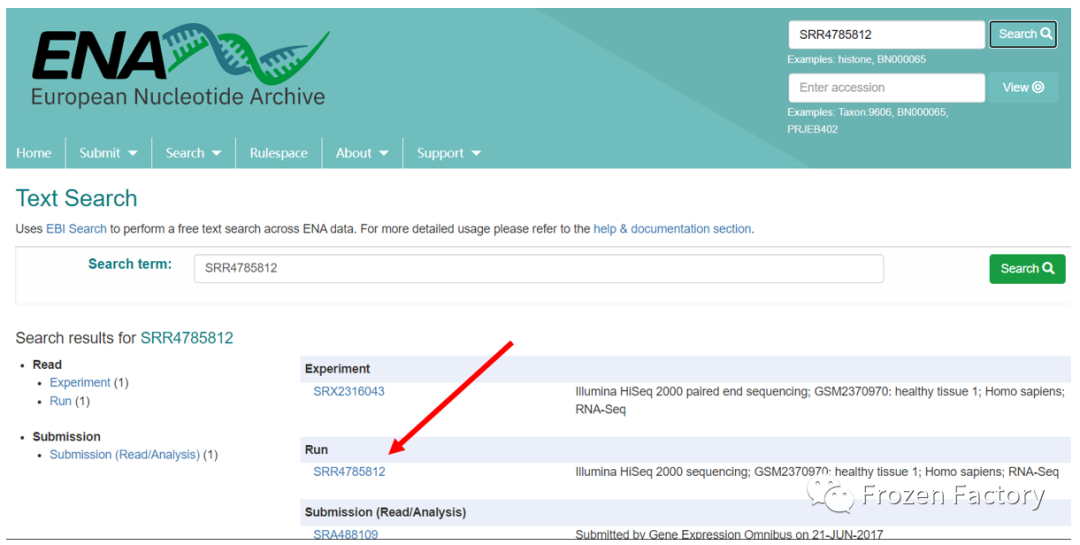
单击箭头所指的ID,即可跳转至下载页面。
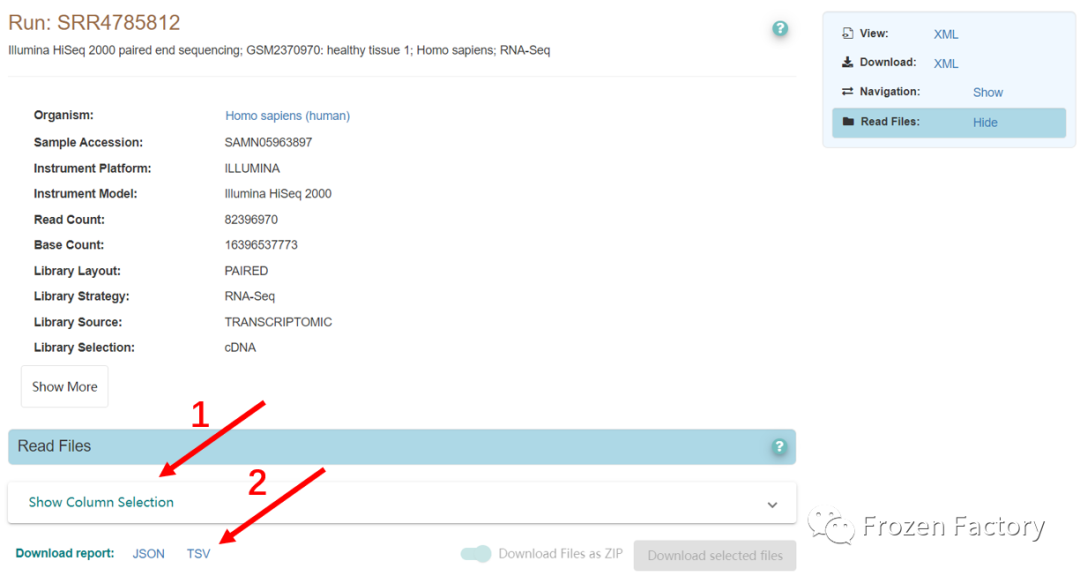
点击上图红色箭头1所指的选项后,选择下图中的数据框。
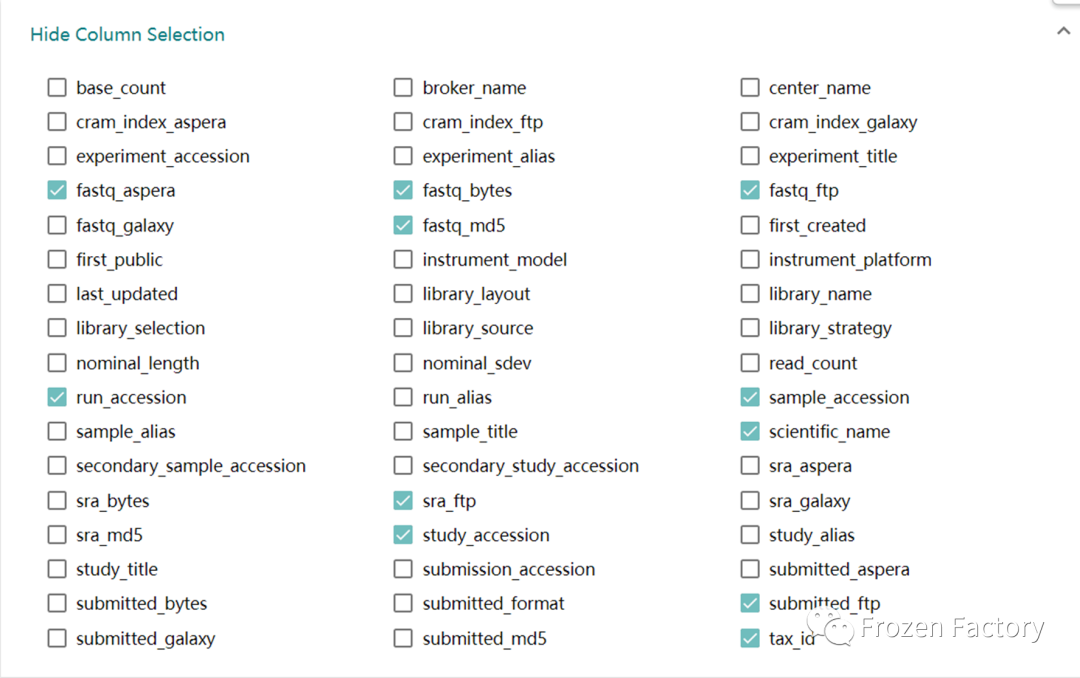
最后单击红色箭头2所指的TSV后,即可获取数据下载的配置文件。
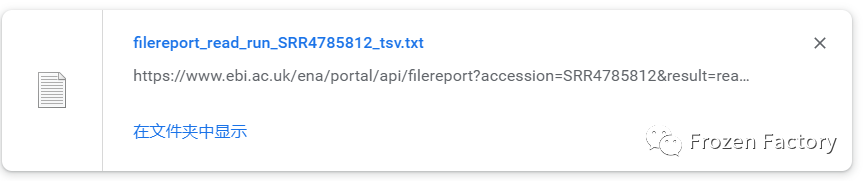
文件内容如下图,其中包含了数据 ID 和下载链接等。

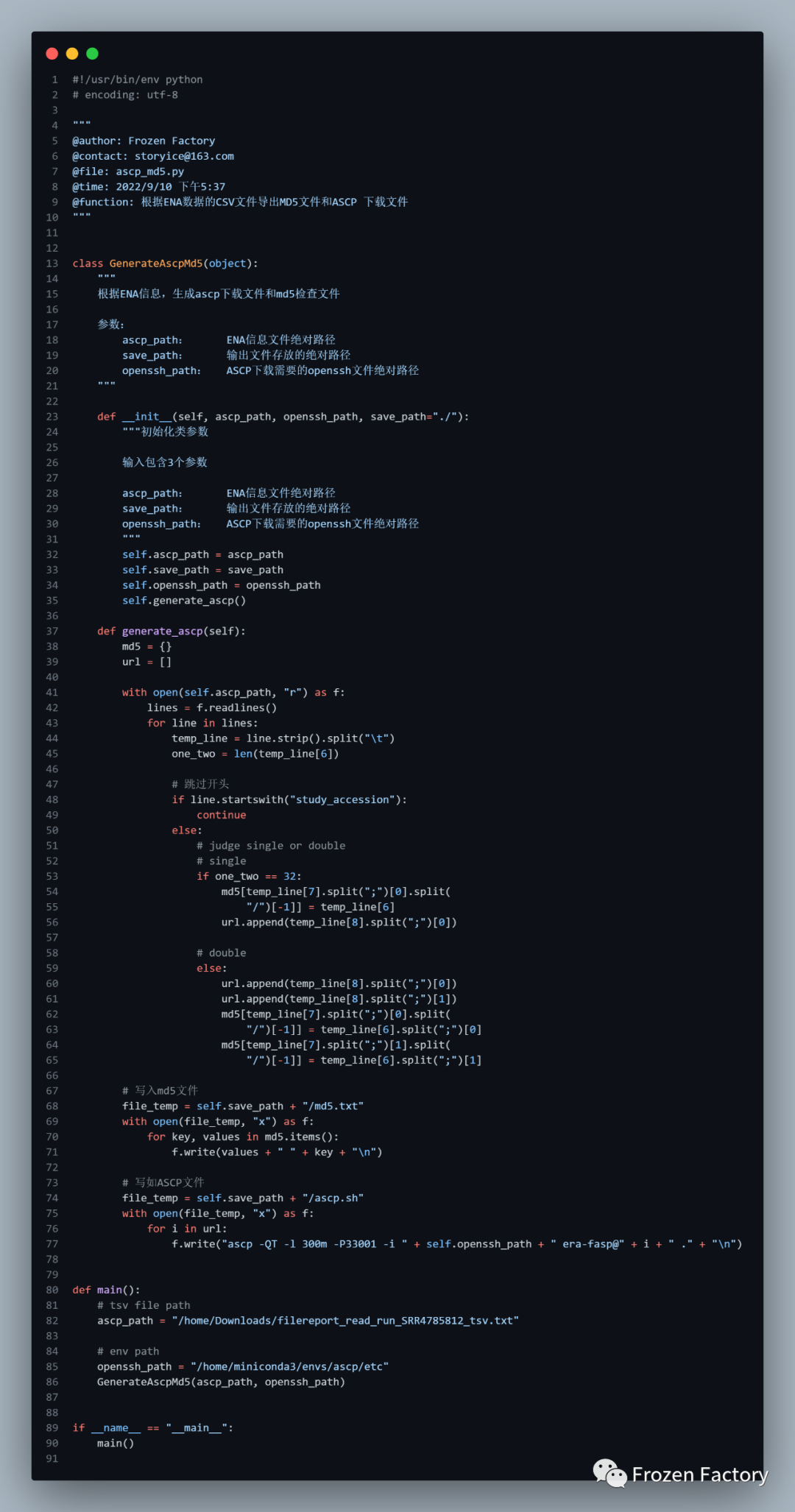
然后利用ascp_md5.py,一键生成下载脚本。
需要准备2个文件:
1.上面下载的tsv文件
2.ascp的openssh文件路径,该路径是虚拟环境路径即"/home/conda/envs/ascp/etc"。(可在终端输入 conda env list查看)
然后运行下面的python脚本,即可获取数据的下载bash文件和校对数据完整性的md5文件。
完整文件结构如下:
随后即可开始下载:
- 使用方式
# 后台下载
nohup bash ascp.sh > run.log 2>&1 &
# 数据下载完后,进行数据完整性检查
md5sum -c md5.txt由于ascp不是很稳定和网络原因,小编在测试时,未能成功下载,但是根据以往经验,其平均下载速度可达到50MB/s左右,在下载大批量数据时,还是比较推荐。
3. mwget
最后是mwget,简单来说它是wget的升级版本,能够多线程下载数据。
它是三种办法中比较快,但同时也是比较稳定的。
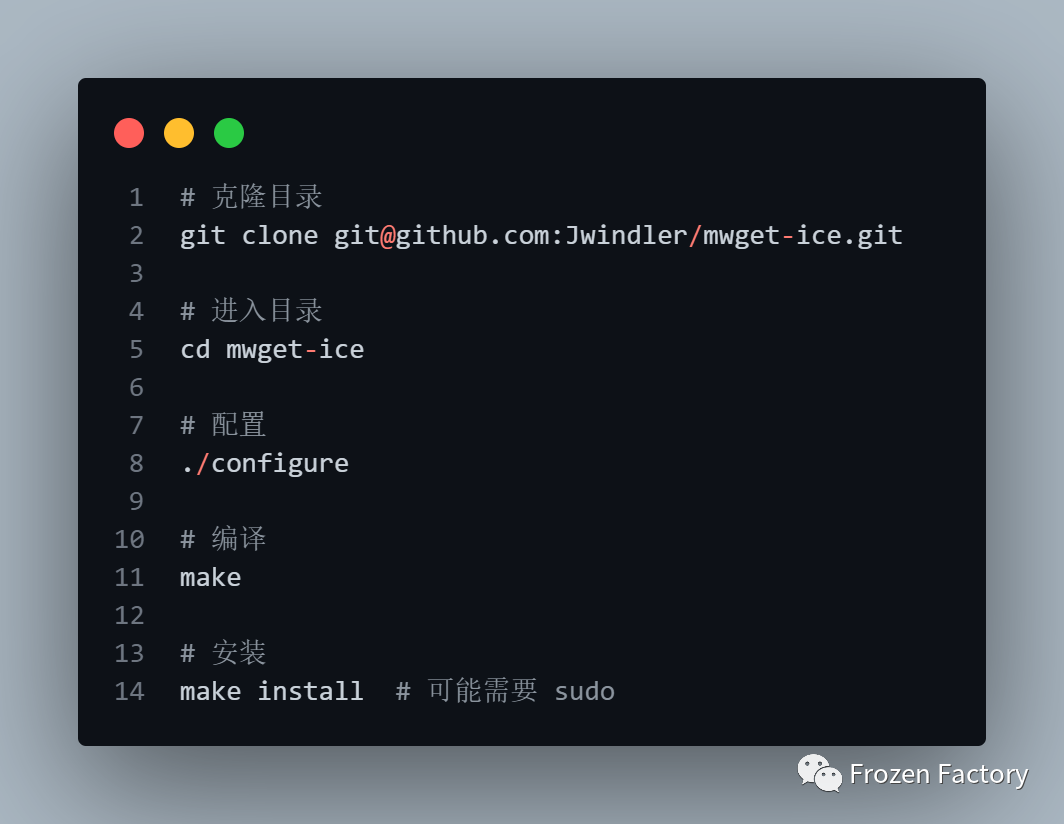
- 安装方式
- 使用方式
mwget [URL] # 默认开4个线程
mwget -n 10 [URL] # 10个线程下载- 例子
# 以SRR4785812为例,使用10个线程进行下载
mwget -n 10 https://sra-pub-run-odp.s3.amazonaws.com/sra/SRR4785812/SRR4785812- 此处下载链接可以参考使用迅雷下载时的链接获取方式
- 线程不建议设置过大
小编实测,平均速度可达到65MB/s。

4. 小结
本文介绍了三种测序数据的下载方式:迅雷,ASCP,mwget。其中迅雷属于常规下载,ASCP虽然下载速度快,但是需要配置环境和生成配置文件,mwget是三者中比较简单和快速的方法。
因此小编建议,在数据量不是非常大的情况下,首推mwget下载,如果下载数据非常大,建议使用ASCP来进行下载。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-09-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号