【协同语音手势】开源 | 一个新的框架ANGIE,有效地捕获可重用的共同语音手势模式以及精细的节奏运动

【协同语音手势】开源 | 一个新的框架ANGIE,有效地捕获可重用的共同语音手势模式以及精细的节奏运动

CNNer
发布于 2023-02-28 11:12:40
发布于 2023-02-28 11:12:40
论文地址: http://arxiv.org/pdf/2212.02350v1.pdf
来源: 香港中文大学
论文名称:Audio-Driven Co-Speech Gesture Video Generation
原文作者:Xian Liu
内容提要
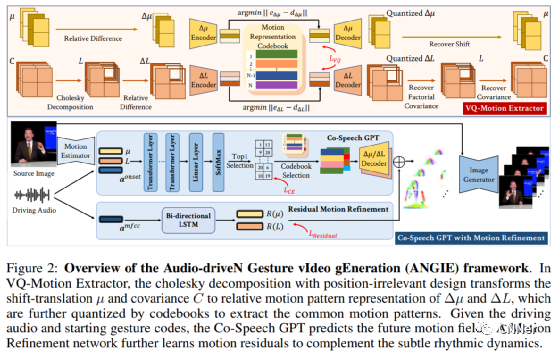
协同语音手势对于人机交互和数字娱乐至关重要。而之前的作品大多将语音音频映射到人类骨骼(例如,2D关键点),在图像域中直接生成说话者的手势问题未解决。在这项工作中,我们正式定义并研究了音频驱动的联合语音手势视频生成,即使用统一框架以生成由语音音频驱动的说话者图像序列。本文的关键是共同语音手势可以被分解成共同的运动模式微妙的节奏动态。为此,我们提出了一个新的框架AudiodriveN Gesture vIdeo gEneration(ANGIE),以有效地捕获可重用的共同语音手势模式以及精细的节奏运动。为了实现高保真的图像序列生成,我们利用了无监督的而不是结构人体先验(例如2D骨架)。具体而言,1)我们提出了一种矢量量化运动提取器(VQ-motion Extractor)从内隐运动中总结常见的共同语音手势模式表示为码本。2)此外,具有运动的协同语音手势GPT细化(Co-Speech GPT)旨在补充微妙的韵律运动细节。大量实验表明,我们的框架能够渲染逼真的语音手势视频。
主要框架及实验结果

声明:文章来自于网络,仅用于学习分享,版权归原作者所有
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-02-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号