【数据挖掘】K-Means 二维数据聚类分析 ( K-Means 迭代总结 | K-Means 初始中心点选择方案 | K-Means 算法优缺点 | K-Means 算法变种 )
【数据挖掘】K-Means 二维数据聚类分析 ( K-Means 迭代总结 | K-Means 初始中心点选择方案 | K-Means 算法优缺点 | K-Means 算法变种 )

文章目
K-Means 二维数据 聚类分析 数据样本及聚类要求
数据样本及聚类要求 :
① 数据样本 : 数据集样本为
个点 ,
,
,
,
,
,
;
② 聚类个数 : 分为
个聚类 ;
③ 距离计算方式 : 使用 曼哈顿距离 , 计算样本之间的相似度 ; 曼哈顿距离的计算方式是 两个维度的数据差 的 绝对值 相加 ;
④ 中心点初始值 : 选取
三个样本为聚类的初始值 , 这是实点 ; 如果选取非样本的点作为初始值 , 就是虚点 ;
⑤ 要求 : 使用 K-Means 算法迭代
次 ;
⑥ 中心值精度 : 计算过程中中心值小数向下取整 ;
二维数据曼哈顿距离计算
1 . 曼哈顿距离 公式如下 :
表示两个样本之间的距离 , 曼哈顿距离 ;
表示属性的个数 , 每个样本有
个属性 ;
和
表示两个 样本的索引值 , 取值范围是
;
表示两个样本 第
个属性值 的差值 ,
表示两个样本 第
个属性值 的差值 ,
表示两个样本 第
个属性值 的差值 ;
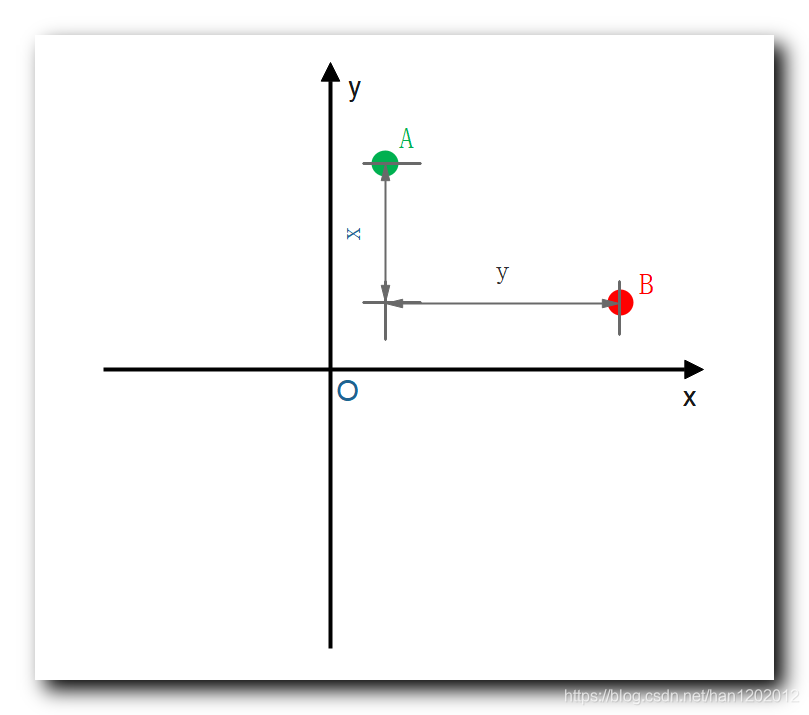
2 . 曼哈顿距离图示 : 曼哈顿的街道都是横平竖直的 , 从
点到
点 , 一般就是其
轴坐标差 加上其
轴坐标差 , 即
;
3 . 本题目中的样本距离计算示例 : 两个样本的曼哈顿距离是
属性差的绝对值 , 加上
属性差的绝对值 , 之和 ;
计算
,
的距离 :
样本与
样本之间的距离是
;
K-Means 算法 步骤
K-Means 算法 步骤 : 给定数据集
, 该数据集有
个样本 , 将其分成
个聚类 ;
① 中心点初始化 : 为
个聚类分组选择初始的中心点 , 这些中心点称为 Means ; 可以依据经验 , 也可以随意选择 ;
② 计算距离 : 计算
个对象与
个中心点 的距离 ; ( 共计算
次 )
③ 聚类分组 : 每个对象与
个中心点的值已计算出 , 将每个对象分配给距离其最近的中心点对应的聚类 ;
④ 计算中心点 : 根据聚类分组中的样本 , 计算每个聚类的中心点 ;
⑤ 迭代直至收敛 : 迭代执行 ② ③ ④ 步骤 , 直到 聚类算法收敛 , 即 中心点 和 分组 经过多少次迭代都不再改变 , 也就是本次计算的中心点与上一次的中心点一样 ;
第一次迭代 : 步骤 ( 1 ) 中心点初始化
初始化中心点 :
个聚类的中心点 , 在题目中已经给出 ;
① 聚类
中心点 :
;
② 聚类
中心点 :
;
③ 聚类
中心点 :
;
第一次迭代 : 步骤 ( 2 ) 计算距离
距离计算次数 : 这里需要计算所有的样本 , 与所有的中心点的距离 , 每个样本都需要计算与
个中心点的距离 , 共需要计算
次 ;
数据样本 :
,
,
,
,
,
1 . 计算
与 三个中心点
之间的距离 :
①
与
的距离 : ( 最小 )
②
与
的距离 :
③
与
的距离 :
与
的距离最小 ;
2 . 计算
与 三个中心点
之间的距离 :
①
与
的距离 :
②
与
的距离 : ( 最小 )
③
与
的距离 :
与
的距离最小 ;
3 . 计算
与 三个中心点
之间的距离 :
①
与
的距离 :
②
与
的距离 : ( 最小 )
③
与
的距离 :
与
的距离最小 ;
4 . 计算
与 三个中心点
之间的距离 :
①
与
的距离 :
②
与
的距离 :
③
与
的距离 : ( 最小 )
与
的距离最小 ;
5 . 计算
与 三个中心点
之间的距离 :
①
与
的距离 :
②
与
的距离 :
③
与
的距离 : ( 最小 )
与
的距离最小 ;
6 . 计算
与 三个中心点
之间的距离 :
①
与
的距离 :
②
与
的距离 : ( 最小 )
③
与
的距离 :
与
的距离最小 ;
8 . 生成距离表格 : 将上面计算的内容总结到如下表格中 ;
A 1 ( 2 , 4 ) A_1 ( 2 , 4 ) A1(2,4) | A 2 ( 3 , 7 ) A_2 ( 3 , 7 ) A2(3,7) | B 1 ( 5 , 8 ) B_1 ( 5 , 8 ) B1(5,8) | B 2 ( 9 , 5 ) B_2 ( 9 , 5 ) B2(9,5) | C 1 ( 6 , 2 ) C_1 ( 6 , 2 ) C1(6,2) | C 2 ( 4 , 9 ) C_2 ( 4 , 9 ) C2(4,9) | |
|---|---|---|---|---|---|---|
A 1 ( 2 , 4 ) A_1 ( 2 , 4 ) A1(2,4) | 0 0 0 | 4 4 4 | 7 7 7 | 8 8 8 | 6 6 6 | 7 7 7 |
B 1 ( 5 , 8 ) B_1 ( 5 , 8 ) B1(5,8) | 7 7 7 | 3 3 3 | 0 0 0 | 7 7 7 | 7 7 7 | 2 2 2 |
C 1 ( 6 , 2 ) C_1 ( 6 , 2 ) C1(6,2) | 6 6 6 | 8 8 8 | 7 7 7 | 6 6 6 | 0 0 0 | 9 9 9 |
第一次迭代 : 步骤 ( 3 ) 聚类分组
1 . 聚类分组 : 根据计算出的 , 每个样本与
个中心点的距离 , 将样本划分到 距离该样本最近的中心点 对应的分组中 ;
A 1 ( 2 , 4 ) A_1 ( 2 , 4 ) A1(2,4) | A 2 ( 3 , 7 ) A_2 ( 3 , 7 ) A2(3,7) | B 1 ( 5 , 8 ) B_1 ( 5 , 8 ) B1(5,8) | B 2 ( 9 , 5 ) B_2 ( 9 , 5 ) B2(9,5) | C 1 ( 6 , 2 ) C_1 ( 6 , 2 ) C1(6,2) | C 2 ( 4 , 9 ) C_2 ( 4 , 9 ) C2(4,9) | |
|---|---|---|---|---|---|---|
A 1 ( 2 , 4 ) A_1 ( 2 , 4 ) A1(2,4) | 0 0 0 | 4 4 4 | 7 7 7 | 8 8 8 | 6 6 6 | 7 7 7 |
B 1 ( 5 , 8 ) B_1 ( 5 , 8 ) B1(5,8) | 7 7 7 | 3 3 3 | 0 0 0 | 7 7 7 | 7 7 7 | 2 2 2 |
C 1 ( 6 , 2 ) C_1 ( 6 , 2 ) C1(6,2) | 6 6 6 | 8 8 8 | 7 7 7 | 6 6 6 | 0 0 0 | 9 9 9 |
2 . 根据表格中的距离 , 为每个样本分组 :
①
距离
中心点最近 , 划分到 聚类
中 ;
②
距离
中心点最近 , 划分到 聚类
中 ;
③
距离
中心点最近 , 划分到 聚类
中 ;
④
距离
中心点最近 , 划分到 聚类
中 ;
⑤
距离
中心点最近 , 划分到 聚类
中 ;
⑥
距离
中心点最近 , 划分到 聚类
中 ;
3 . 最终的聚类分组为 :
① 聚类
:
② 聚类
:
③ 聚类
:
第二次迭代 : 步骤 ( 1 ) 中心点初始化
,
,
,
,
,
1 . 聚类
中心点计算 : 计算
中心点
2 . 聚类
中心点计算 : 计算
中心点
3 . 聚类
中心点计算 : 计算
中心点
第二次迭代 : 步骤 ( 2 ) 计算距离
计算
个点 , 到
个中心点的距离 ,
个中心点分别是
, 直接将两个点的曼哈顿距离填在对应的表格中 ;
如 : 第
行 , 第
列 :
样本 与
聚类
中心点的 曼哈顿距离 是
, 计算过程如下 :
A 1 ( 2 , 4 ) A_1 ( 2 , 4 ) A1(2,4) | A 2 ( 3 , 7 ) A_2 ( 3 , 7 ) A2(3,7) | B 1 ( 5 , 8 ) B_1 ( 5 , 8 ) B1(5,8) | B 2 ( 9 , 5 ) B_2 ( 9 , 5 ) B2(9,5) | C 1 ( 6 , 2 ) C_1 ( 6 , 2 ) C1(6,2) | C 2 ( 4 , 9 ) C_2 ( 4 , 9 ) C2(4,9) | |
|---|---|---|---|---|---|---|
( 2 , 4 ) ( 2 , 4 ) (2,4) | 0 0 0 | 4 4 4 | 7 7 7 | 8 8 8 | 6 6 6 | 7 7 7 |
( 4 , 8 ) ( 4 , 8 ) (4,8) | 6 6 6 | 2 2 2 | 1 1 1 | 8 8 8 | 8 8 8 | 1 1 1 |
( 7 , 3 ) ( 7 , 3 ) (7,3) | 6 6 6 | 8 8 8 | 7 7 7 | 4 4 4 | 2 2 2 | 9 9 9 |
第二次迭代 : 步骤 ( 3 ) 聚类分组
1 . 聚类分组 : 根据计算出的 , 每个样本与
个中心点的距离 , 将样本划分到 距离该样本最近的中心点 对应的分组中 ;
A 1 ( 2 , 4 ) A_1 ( 2 , 4 ) A1(2,4) | A 2 ( 3 , 7 ) A_2 ( 3 , 7 ) A2(3,7) | B 1 ( 5 , 8 ) B_1 ( 5 , 8 ) B1(5,8) | B 2 ( 9 , 5 ) B_2 ( 9 , 5 ) B2(9,5) | C 1 ( 6 , 2 ) C_1 ( 6 , 2 ) C1(6,2) | C 2 ( 4 , 9 ) C_2 ( 4 , 9 ) C2(4,9) | |
|---|---|---|---|---|---|---|
( 2 , 4 ) ( 2 , 4 ) (2,4) | 0 0 0 | 4 4 4 | 7 7 7 | 8 8 8 | 6 6 6 | 7 7 7 |
( 4 , 8 ) ( 4 , 8 ) (4,8) | 6 6 6 | 2 2 2 | 1 1 1 | 8 8 8 | 8 8 8 | 1 1 1 |
( 7 , 3 ) ( 7 , 3 ) (7,3) | 6 6 6 | 8 8 8 | 7 7 7 | 4 4 4 | 2 2 2 | 9 9 9 |
2 . 根据表格中的距离 , 为每个样本分组 :
①
距离
中心点最近 , 划分到 聚类
中 ;
②
距离
中心点最近 , 划分到 聚类
中 ;
③
距离
中心点最近 , 划分到 聚类
中 ;
④
距离
中心点最近 , 划分到 聚类
中 ;
⑤
距离
中心点最近 , 划分到 聚类
中 ;
⑥
距离
中心点最近 , 划分到 聚类
中 ;
3 . 最终的聚类分组为 :
① 聚类
:
② 聚类
:
③ 聚类
:
第二次迭代的聚类分组 , 与第一次迭代的聚类分组 , 没有改变 , 说明聚类算法分析结果已经收敛 , 该聚类结果就是最终的结果 ;
K-Means 迭代总结
1 . 第一次迭代 :
① 设置中心点 : 设置了
个初始中心点 ,
对应聚类
中心点 ,
对应聚类
中心点 ,
对应聚类
中心点 ;
② 计算中心点距离 : 然后就算
个样本距离这
个中心点的距离 ;
③ 根据距离聚类分组 : 每个样本取距离最近的
个中心点 , 将该样本分类成该中心点对应的聚类分组 , 聚类分组结果是 , 聚类
:
, 聚类
:
, 聚类
:
;
2 . 第二次迭代 :
① 计算中心点 : 根据第一次迭代的聚类分组结果计算 3 3 3 个中心点 , ( 2 , 4 ) ( 2 , 4 ) (2,4) 对应聚类 1 1 1 中心点 , ( 4 , 8 ) 对应聚类 2 2 2 中心点 , ( 7 , 3 ) ( 7 , 3 ) (7,3) 对应聚类 3 3 3 中心点 ;
② 计算中心点距离 : 然后就算
个样本距离这
个中心点的距离 ;
③ 根据距离聚类分组 : 每个样本取距离最近的
个中心点 , 将该样本分类成该中心点对应的聚类分组 , 聚类分组结果是 , 聚类
:
, 聚类
:
, 聚类
:
;
3 . 最终结果 : 经过
次迭代 , 发现 , 根据最初选择中心点 , 进行聚类分组的结果 , 就是最终的结果 , 迭代
次的分组结果相同 , 说明聚类算法已经收敛 , 此时的聚类结果就是最终结果 , 聚类算法终止 ;
K-Means 初始中心点选择方案
1 . 初始中心点选择 :
① 初始种子 : 初始的中心点 , 又称为种子 , 如果种子选择的好 , 迭代的次数就会非常少 , 迭代的最少次数为
, 如上面的示例 ;
② 种子选择影响 : 初始种子选择的好坏 , 即影响算法收敛的速度 , 又影响聚类结果的质量 ; 选择的好 , 迭代
次 , 算法收敛 , 得到最终结果 , 并且聚类效果很好 ; 选择的不好 , 迭代很多次才收敛 , 并且聚类效果很差 ;
2 . 初始中心点选择方案 :
① 随机选择 ;
② 使用已知聚类算法的结果 ;
③ 爬山算法 : K-Means 采用的是爬山算法 , 只找局部最优的中心点 ;
K-Means 算法优缺点
1 . K-Means 算法优点 :
① 算法可扩展性高 : 算法复杂度随数据量增加 , 而线性增加 ;
② 算法的复杂度 : K-Means 的算法复杂度是
,
是数据样本个数 ,
是聚类分组的个数 ,
是迭代次数 ,
一般不超过
;
2 . K-Means 算法缺点 :
③ 事先必须设定聚类个数 : K-Means 的聚类分组的个数, 必须事先确定 , 有些应用场景中 , 事先是不知道聚类个数的 ;
④ 有些中心点难以确定 : 有些数据类型的中心点不好确定 , 如字符型的数据 , 离散型数据 , 布尔值数据 等 ;
⑤ 鲁棒性差 : 对于数据样本中的噪音数据 , 异常数据 , 不能有效的排除这些数据的干扰 ;
⑥ 局限性 : 只能处理凸状 , 或 球状分布的样本数据 , 对于 凹形分布 的样本数据 , 无法有效的进行聚类分析 ;
K-Means 算法变种
1 . K-Means 方法有很多变种 :
① K_Modes : 处理离散型的属性值 , 如字符型数据等 ;
② K-Prototypes : 处理 离散型 或 连续型 的属性 ;
③ K-Medoids : 其计算中心点不是使用算术平均值 , 其使用的是中间值 ;
2 . K-Means 变种算法 与 k-Means 算法的区别与联系 :
① 原理相同 : 这些变种算法 与 K-Means 算法原理基本相同 ;
② 中心点选择不同 : 变种算法 与 原算法 最初的中心点选择不同 ;
③ 距离计算方式不同 : K-Means 使用曼哈顿距离 , 变种算法可能使用 欧几里得距离 , 明科斯基距离 , 边际距离 等 ;
④ 计算聚类中心点策略不同 : K-Means 算法中使用算术平均 , 有的使用中间值 ;