全网最硬核 JVM 内存解析 - 3.大页分配 UseLargePages
全网最硬核 JVM 内存解析 - 3.大页分配 UseLargePages

个人创作公约:本人声明创作的所有文章皆为自己原创,如果有参考任何文章的地方,会标注出来,如果有疏漏,欢迎大家批判。如果大家发现网上有抄袭本文章的,欢迎举报,并且积极向这个 github 仓库 提交 issue,谢谢支持~ 另外,本文为了避免抄袭,会在不影响阅读的情况下,在文章的随机位置放入对于抄袭和洗稿的人的“亲切”的问候。如果是正常读者看到,笔者在这里说声对不起,。如果被抄袭狗或者洗稿狗看到了,希望你能够好好反思,不要再抄袭了,谢谢。 今天又是干货满满的一天,这是全网最硬核 JVM 解析系列第四篇,往期精彩:
本篇是关于 JVM 内存的详细分析。网上有很多关于 JVM 内存结构的分析以及图片,但是由于不是一手的资料亦或是人云亦云导致有很错误,造成了很多误解;并且,这里可能最容易混淆的是一边是 JVM Specification 的定义,一边是 Hotspot JVM 的实际实现,有时候人们一些部分说的是 JVM Specification,一部分说的是 Hotspot 实现,给人一种割裂感与误解。本篇主要从 Hotspot 实现出发,以 Linux x86 环境为主,紧密贴合 JVM 源码并且辅以各种 JVM 工具验证帮助大家理解 JVM 内存的结构。但是,本篇仅限于对于这些内存的用途,使用限制,相关参数的分析,有些地方可能比较深入,有些地方可能需要结合本身用这块内存涉及的 JVM 模块去说,会放在另一系列文章详细描述。最后,洗稿抄袭狗不得 house
本篇全篇目录(以及涉及的 JVM 参数):
- 从 Native Memory Tracking 说起(全网最硬核 JVM 内存解析 - 1.从 Native Memory Tracking 说起开始)
- Native Memory Tracking 的开启
- Native Memory Tracking 的使用(涉及 JVM 参数:
NativeMemoryTracking) - Native Memory Tracking 的 summary 信息每部分含义
- Native Memory Tracking 的 summary 信息的持续监控
- 为何 Native Memory Tracking 中申请的内存分为 reserved 和 committed
- JVM 内存申请与使用流程(全网最硬核 JVM 内存解析 - 2.JVM 内存申请与使用流程开始)
- Linux 下内存管理模型简述
- JVM commit 的内存与实际占用内存的差异
- JVM commit 的内存与实际占用内存的差异
- 大页分配 UseLargePages(全网最硬核 JVM 内存解析 - 3.大页分配 UseLargePages开始)
- Linux 大页分配方式 - Huge Translation Lookaside Buffer Page (hugetlbfs)
- Linux 大页分配方式 - Transparent Huge Pages (THP)
- JVM 大页分配相关参数与机制(涉及 JVM 参数:
UseLargePages,UseHugeTLBFS,UseSHM,UseTransparentHugePages,LargePageSizeInBytes)
- Java 堆内存相关设计(全网最硬核 JVM 内存解析 - 4.Java 堆内存大小的确认开始)
- 通用初始化与扩展流程
- 直接指定三个指标的方式(涉及 JVM 参数:
MaxHeapSize,MinHeapSize,InitialHeapSize,Xmx,Xms) - 不手动指定三个指标的情况下,这三个指标(MinHeapSize,MaxHeapSize,InitialHeapSize)是如何计算的
- 压缩对象指针相关机制(涉及 JVM 参数:
UseCompressedOops)(全网最硬核 JVM 内存解析 - 5.压缩对象指针相关机制开始)- 压缩对象指针存在的意义(涉及 JVM 参数:
ObjectAlignmentInBytes) - 压缩对象指针与压缩类指针的关系演进(涉及 JVM 参数:
UseCompressedOops,UseCompressedClassPointers) - 压缩对象指针的不同模式与寻址优化机制(涉及 JVM 参数:
ObjectAlignmentInBytes,HeapBaseMinAddress)
- 压缩对象指针存在的意义(涉及 JVM 参数:
- 为何预留第 0 页,压缩对象指针 null 判断擦除的实现(涉及 JVM 参数:
HeapBaseMinAddress) - 结合压缩对象指针与前面提到的堆内存限制的初始化的关系(涉及 JVM 参数:
HeapBaseMinAddress,ObjectAlignmentInBytes,MinHeapSize,MaxHeapSize,InitialHeapSize) - 使用 jol + jhsdb + JVM 日志查看压缩对象指针与 Java 堆验证我们前面的结论
- 验证
32-bit压缩指针模式 - 验证
Zero based压缩指针模式 - 验证
Non-zero disjoint压缩指针模式 - 验证
Non-zero based压缩指针模式
- 验证
- 堆大小的动态伸缩(涉及 JVM 参数:
MinHeapFreeRatio,MaxHeapFreeRatio,MinHeapDeltaBytes)(全网最硬核 JVM 内存解析 - 6.其他 Java 堆内存相关的特殊机制开始) - 适用于长期运行并且尽量将所有可用内存被堆使用的 JVM 参数 AggressiveHeap
- JVM 参数 AlwaysPreTouch 的作用
- JVM 参数 UseContainerSupport - JVM 如何感知到容器内存限制
- JVM 参数 SoftMaxHeapSize - 用于平滑迁移更耗内存的 GC 使用
- JVM 元空间设计(全网最硬核 JVM 内存解析 - 7.元空间存储的元数据开始)
- 什么是元数据,为什么需要元数据
- 什么时候用到元空间,元空间保存什么
- 什么时候用到元空间,以及释放时机
- 元空间保存什么
- 元空间的核心概念与设计(全网最硬核 JVM 内存解析 - 8.元空间的核心概念与设计开始)
- 元空间的整体配置以及相关参数(涉及 JVM 参数:
MetaspaceSize,MaxMetaspaceSize,MinMetaspaceExpansion,MaxMetaspaceExpansion,MaxMetaspaceFreeRatio,MinMetaspaceFreeRatio,UseCompressedClassPointers,CompressedClassSpaceSize,CompressedClassSpaceBaseAddress,MetaspaceReclaimPolicy) - 元空间上下文
MetaspaceContext - 虚拟内存空间节点列表
VirtualSpaceList - 虚拟内存空间节点
VirtualSpaceNode与CompressedClassSpaceSize MetaChunkChunkHeaderPool池化MetaChunk对象ChunkManager管理空闲的MetaChunk
- 类加载的入口
SystemDictionary与保留所有ClassLoaderData的ClassLoaderDataGraph - 每个类加载器私有的
ClassLoaderData以及ClassLoaderMetaspace - 管理正在使用的
MetaChunk的MetaspaceArena - 元空间内存分配流程(全网最硬核 JVM 内存解析 - 9.元空间内存分配流程开始)
- 类加载器到
MetaSpaceArena的流程 - 从
MetaChunkArena普通分配 - 整体流程 - 从
MetaChunkArena普通分配 -FreeBlocks回收老的current chunk与用于后续分配的流程 - 从
MetaChunkArena普通分配 - 尝试从FreeBlocks分配 - 从
MetaChunkArena普通分配 - 尝试扩容current chunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk- 从VirtualSpaceList申请新的RootMetaChunk - 从
MetaChunkArena普通分配 - 从ChunkManager分配新的MetaChunk- 将RootMetaChunk切割成为需要的MetaChunk MetaChunk回收 - 不同情况下,MetaChunk如何放入FreeChunkListVector
- 类加载器到
ClassLoaderData回收
- 元空间的整体配置以及相关参数(涉及 JVM 参数:
- 元空间分配与回收流程举例(全网最硬核 JVM 内存解析 - 10.元空间分配与回收流程举例开始)
- 首先类加载器 1 需要分配 1023 字节大小的内存,属于类空间
- 然后类加载器 1 还需要分配 1023 字节大小的内存,属于类空间
- 然后类加载器 1 需要分配 264 KB 大小的内存,属于类空间
- 然后类加载器 1 需要分配 2 MB 大小的内存,属于类空间
- 然后类加载器 1 需要分配 128KB 大小的内存,属于类空间
- 新来一个类加载器 2,需要分配 1023 Bytes 大小的内存,属于类空间
- 然后类加载器 1 被 GC 回收掉
- 然后类加载器 2 需要分配 1 MB 大小的内存,属于类空间
- 元空间大小限制与动态伸缩(全网最硬核 JVM 内存解析 - 11.元空间分配与回收流程举例开始)
CommitLimiter的限制元空间可以 commit 的内存大小以及限制元空间占用达到多少就开始尝试 GC- 每次 GC 之后,也会尝试重新计算
_capacity_until_GC
jcmd VM.metaspace元空间说明、元空间相关 JVM 日志以及元空间 JFR 事件详解(全网最硬核 JVM 内存解析 - 12.元空间各种监控手段开始)jcmd <pid> VM.metaspace元空间说明- 元空间相关 JVM 日志
- 元空间 JFR 事件详解
jdk.MetaspaceSummary元空间定时统计事件jdk.MetaspaceAllocationFailure元空间分配失败事件jdk.MetaspaceOOM元空间 OOM 事件jdk.MetaspaceGCThreshold元空间 GC 阈值变化事件jdk.MetaspaceChunkFreeListSummary元空间 Chunk FreeList 统计事件
- JVM 线程内存设计(重点研究 Java 线程)(全网最硬核 JVM 内存解析 - 13.JVM 线程内存设计开始)
- JVM 中有哪几种线程,对应线程栈相关的参数是什么(涉及 JVM 参数:
ThreadStackSize,VMThreadStackSize,CompilerThreadStackSize,StackYellowPages,StackRedPages,StackShadowPages,StackReservedPages,RestrictReservedStack) - Java 线程栈内存的结构
- Java 线程如何抛出的 StackOverflowError
- 解释执行与编译执行时候的判断(x86为例)
- 一个 Java 线程 Xss 最小能指定多大
- JVM 中有哪几种线程,对应线程栈相关的参数是什么(涉及 JVM 参数:
2. JVM 内存申请与使用流程
2.3. 大页分配 UseLargePages
前面提到了虚拟内存需要映射物理内存才能使用,这个映射关系被保存在内存中的页表(Page Table)。现代 CPU 架构中一般有 TLB (Translation Lookaside Buffer,翻译后备缓冲,也称为页表寄存器缓冲)存在,在里面保存了经常使用的页表映射项。TLB 的大小有限,一般 TLB 如果只能容纳小于 100 个页表映射项。 我们能让程序的虚拟内存对应的页表映射项都处于 TLB 中,那么能大大提升程序性能,这就要尽量减少页表映射项的个数:页表项个数 = 程序所需内存大小 / 页大小。我们要么缩小程序所需内存,要么增大页大小。我们一般会考虑增加页大小,这就大页分配的由来,JVM 对于堆内存分配也支持大页分配,用于优化大堆内存的分配。那么 Linux 环境中有哪些大页分配的方式呢?
2.3.1. Linux 大页分配方式 - Huge Translation Lookaside Buffer Page (hugetlbfs)
相关的 Linux 内核文档:https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
这是出现的比较早的大页分配方式,其实就是在之前提到的页表映射上面做文章:
默认 4K 页大小:
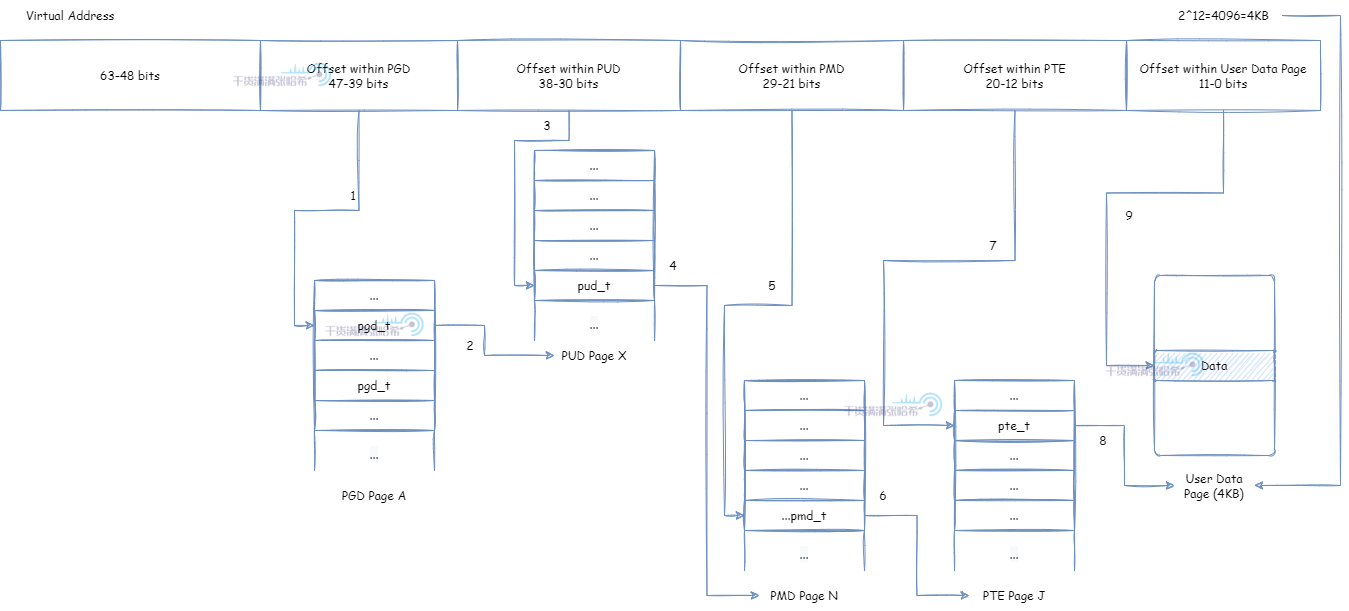
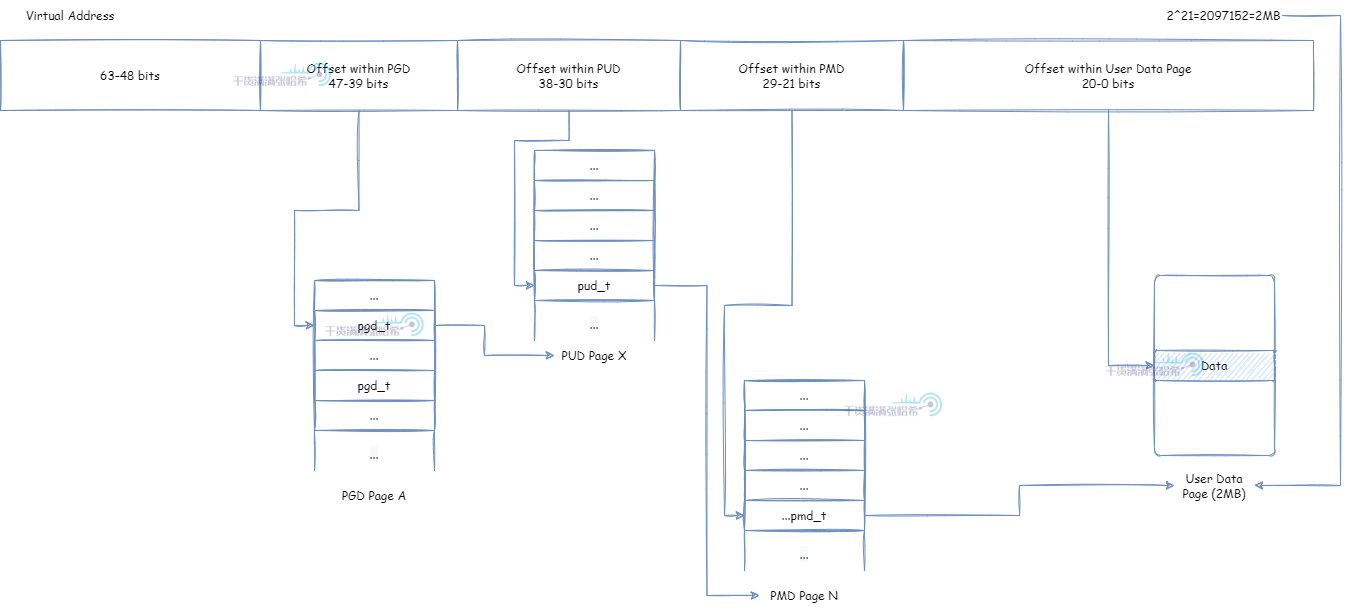
PMD 直接映射实际物理页面,页面大小为 4K * 2^9 = 2M:
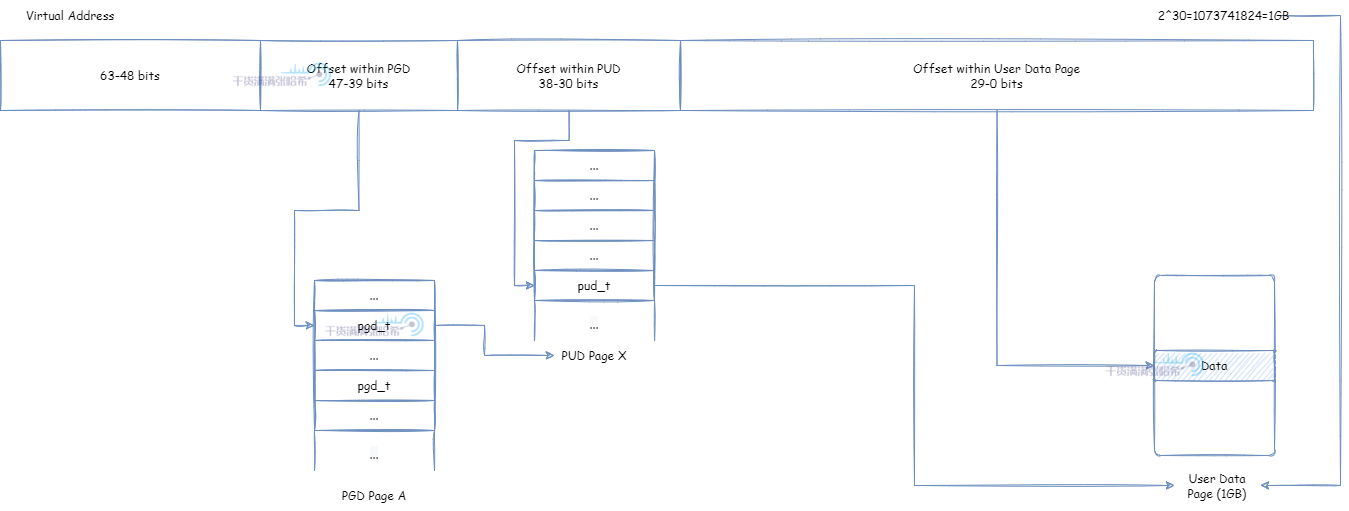
PUD 直接映射实际物理页面,页面大小为 2M * 2^9 = 1G:
但是,要想使用这个特性,需要操作系统构建的时候开启 CONFIG_HUGETLBFS 以及 CONFIG_HUGETLB_PAGE。之后,大的页面通常是通过系统管理控制预先分配并放入池里面的。然后,可以通过 mmap 系统调用或者 shmget,shmat 这些 SysV 的共享内存系统调用使用大页分配方式从池中申请内存。
这种大页分配的方式,需要系统预设开启大页,预分配大页之外,对于代码也是有一定侵入性的,在灵活性上面查一些。但是带来的好处就是,性能表现上更加可控。另一种灵活性很强的 Transparent Huge Pages (THP) 方式,总是可能在性能表现上有一些意想不到的情况。
2.3.2. Linux 大页分配方式 - Transparent Huge Pages (THP)
相关的 Linux 内核文档:https://www.kernel.org/doc/Documentation/vm/transhuge.txt
THP 是一种使用大页的第二种方法,它支持页面大小的自动升级和降级,这样对于用户使用代码基本没有侵入性,非常灵活。但是,前面也提到过,这种系统自己去做页面大小的升级降级,并且系统一般考虑通用性,所以在某些情况下会出现意想不到的性能瓶颈。
2.3.3. JVM 大页分配相关参数与机制
相关的参数如下:
UseLargePages:明确指定是否开启大页分配,如果关闭,那么下面的参数就都不生效。在 linux 下默认为 false。UseHugeTLBFS:明确指定是否使用前面第一种大页分配方式 hugetlbfs 并且通过mmap系统调用分配内存。在 linux 下默认为 false。UseSHM:明确指定是否使用前面第一种大页分配方式 hugetlbfs 并且通过shmget,shmat系统调用分配内存。在 linux 下默认为 false。UseTransparentHugePages:明确指定是否使用前面第二种大页分配方式 THP。在 linux 下默认为 false。LargePageSizeInBytes:指定明确的大页的大小,仅适用于前面第一种大页分配方式 hugetlbfs,并且必须属于操作系统支持的页大小否则不生效。默认为 0,即不指定
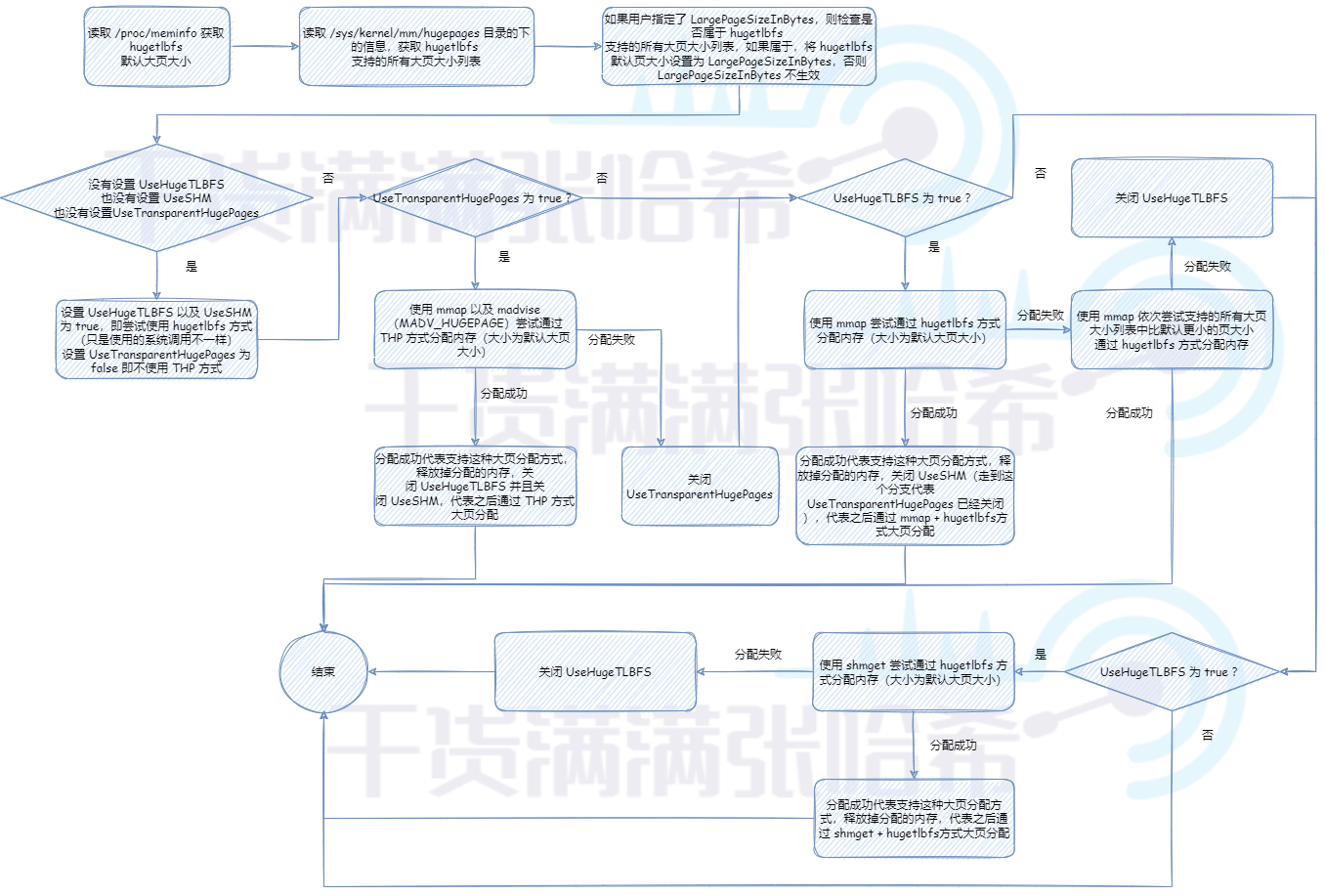
首先,需要对以上参数做一个简单的判断:如果没有指定 UseLargePages,那么使用对应系统的默认 UseLargePages 的值,在 linux 下是 false,那么就不会启用大页分配。如果启动参数明确指定 UseLargePages 不启用,那么也不会启用大页分配。如果读取 /proc/meminfo 获取默认大页大小读取不到或者为 0,则代表系统也不支大页分配,大页分配也不启用。
那么如果大页分配启用的话,我们需要初始化并验证大页分配参数可行性,流程是:
首先,JVM 会读取根据当前所处的平台与系统环境读取支持的页的大小,当然,这个是针对前面第一种大页分配方式 hugetlbfs 的。在 Linux 环境下,JVM 会从 /proc/meminfo 读取默认的 Hugepagesize,从 /sys/kernel/mm/hugepages 目录下检索所有支持的大页大小,这块可以参考源码:https://github.com/openjdk/jdk/blob/jdk-21%2B3/src/hotspot/os/linux/os_linux.cpp。有关这些文件或者目录的详细信息,请参考前面章节提到的 Linux 内核文档:https://www.kernel.org/doc/Documentation/vm/hugetlbpage.txt
如果操作系统开启了 hugetlbfs,/sys/kernel/mm/hugepages 目录下的结构类似于:
> tree /sys/kernel/mm/hugepages
/sys/kernel/mm/hugepages
├── hugepages-1048576kB
│ ├── free_hugepages
│ ├── nr_hugepages
│ ├── nr_hugepages_mempolicy
│ ├── nr_overcommit_hugepages
│ ├── resv_hugepages
│ └── surplus_hugepages
└── hugepages-2048kB
├── free_hugepages
├── nr_hugepages
├── nr_hugepages_mempolicy
├── nr_overcommit_hugepages
├── resv_hugepages
└── surplus_hugepages这个 hugepages-1048576kB 就代表支持大小为 1GB 的页,hugepages-2048kB 就代表支持大小为 2KB 的页。
如果没有设置 UseHugeTLBFS,也没有设置 UseSHM,也没有设置 UseTransparentHugePages,那么其实就是走默认的,默认使用 hugetlbfs 方式,不使用 THP 方式,因为如前所述, THP 在某些场景下有意想不到的性能瓶颈表现,在大型应用中,稳定性优先于峰值性能。之后,默认优先尝试 UseHugeTLBFS(即使用 mmap 系统调用通过 hugetlbfs 方式大页分配),不行的话再尝试 UseSHM(即使用 shmget 系统调用通过 hugetlbfs 方式大页分配)。这里只是验证下这些大页内存的分配方式是否可用,只有可用后面真正分配内存的时候才会采用那种可用的大页内存分配方式。