大数据随记 —— Spark Core 与 RDD 简介

大数据随记 —— Spark Core 与 RDD 简介

繁依Fanyi
发布于 2023-05-07 19:24:40
发布于 2023-05-07 19:24:40

一、Spark Core
Spark Core 是 Spark 的核心,Spark SQL、Spark Streaming、MLib、GraphX 等都需要在 Spark Core 的基础上进行操作。Spark Core 定义了 RDD、DataFrame 和 DataSet,而 Spark Core 的核心概念是 RDD(Resilient Distributed Datasets,即弹性分布式数据集)。
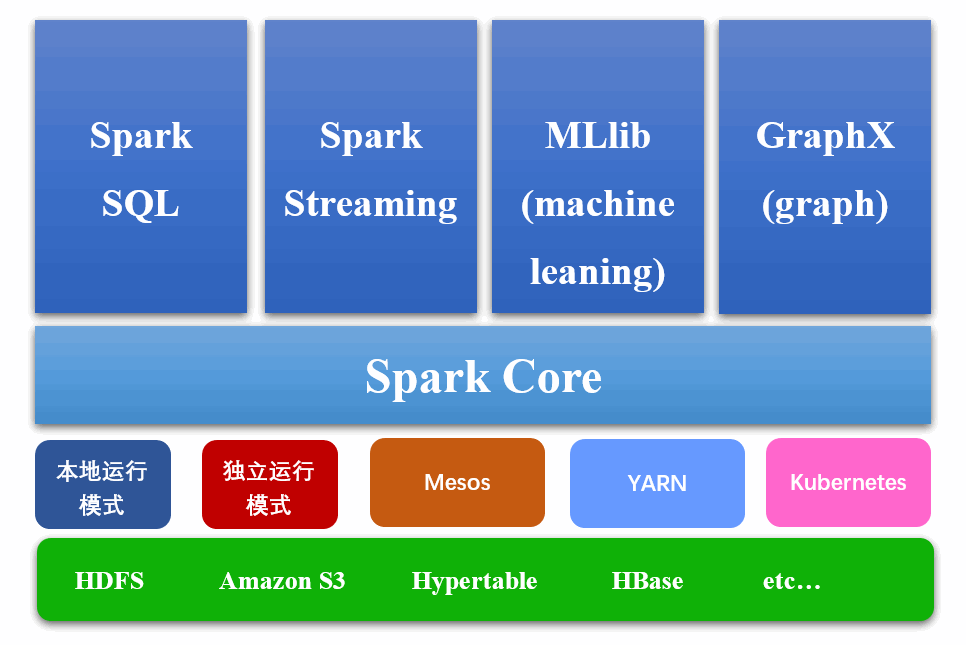
二、RDD
1. RDD 简介
弹性分布式数据集(RDD,Resilient Distributed Datasets),它具备像 MapReduce 等数据流模型的容错特性,能在并行计算中高效地进行数据共享进而提升计算性能。RDD 中提供了一些转换操作,在转换过程中记录了“血统”关系,而在 RDD 中并不会存储真正的数据,只是数据的描述和操作描述。
RDD 是只读的、分区记录的集合。RDD 只能基于在稳定物理存储中的数据集和其他已有的 RDD 上执行确定性操作来创建。这些确定性操作称之为转换,如 map、filter、groupBy、join等。RDD 不需要物化,RDD 含有如何从其他 RDD 衍生(即计算)出本 RDD 的相关信息(即 Lineage),据此可以从物理存储的数据计算出相应的 RDD 分区。
2. RDD 的特性(核心属性)
RDD 有五大特性:
- Ⅰ)A list of partitions
- Ⅱ)A function for computing each split
- Ⅲ)A list of dependencies on other RDDs
- Ⅳ)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Ⅴ)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
描述五大特征的源码:
/**
* Implemented by subclasses to compute a given partition.
*
* It can be seen that compute is an abstract method that all RDD subclasses must implement to calculate a given partition.
* Note that the input parameter of compute here is split: Partition, so all calculations are based on Partition (feature 2)
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property:
* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`
*
* It can be seen that getPartitions must be implemented by all RDD subclasses. It is used to return the partition set of RDD
* This also shows that RDD itself is composed of Partition (feature 1)
* In addition: this method will only be called once. This illustrates a hidden feature of RDD: RDD is immutable
*/
protected def getPartitions: Array[Partition]
/**
* Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*
* getDependencies Get the dependencies of this RDD. Note: deps is passed in by the structure of the RDD.
* This means that RDD must record its dependencies (the construction must be passed in) (feature 3)
*/
protected def getDependencies: Seq[Dependency[_]] = deps
/**
* Optionally overridden by subclasses to specify placement preferences.
*
* getPreferredLocations Get the storage path of this RDD. Seq[String] because of the concept of copy. Seq(0) is the preferred address (feature 5)
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
/** Optionally overridden by subclasses to specify how they are partitioned.
*
* partitioner partition function. If necessary, you can customize the partition algorithm to cover the partition function (feature 4)
*/
@transient val partitioner: Option[Partitioner] = NoneⅠ)一系列的分区信息(分区列表)
对于 RDD 来说,每个分区都会被一个任务处理,这决定了并行度。用户可以在创建 RDD 时指定 RDD 的分区个数,如果没有设置则采用默认值。
2)由一个函数计算每一个分片(分区计算函数)
Spark 中的 RDD 的计算是以分片为单位的,每个 RDD 都会实现 compute 函数以达到这个目的。
3)RDD 之间的依赖关系
RDD 的每次转换都会生成一个新的 RDD,那么多个 RDD 之间就有前后的依赖关系。在每个分区的数据丢失时,Spark 可以通过这层依赖关系重新计算丢失的分区数据,而不需要从头对 RDD 的所有分区数据进行重新计算。
4)分区器
Partitioner 是 RDD 的分区函数,类似于 Hadoop 中的 Partitoner,使得数据按照一定的规则分配到指定的 Reducer 上去处理。当前 Spark 中有两种类型的分区函数,一个是基于 Hash 的 HashPartitioner,另一个是基于范围的 RangePartitioner。对于普通数据的 Partitioner 为 None,当遇到的 RDD 数据是 key-value 才会有 Partitioner,比如在使用 join 或者 group by 时。
5)最佳位置列表(首选位置)
一个 RDD 会对应有多个 Partitioner,那么这些 Partitioner 最佳的计算位置是在哪。对于 HDFS 来说,这个列表保存的是每个 Partition 所在的 Block 的位置。按照 “移动数据不如移动计算”的理念,Spark 在进行任务调度时会尽可能地将计算任务分派到其所在处理数据块的存储位置。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2022-08-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号