提升内存资源利用率,TencentOS“悟净”硬核技术详解

提升内存资源利用率,TencentOS“悟净”硬核技术详解


👉腾小云导读
随着云数据中心应用程序对内存的需求持续增长,TencentOS“悟净”——服务器内存多级卸载方案应运而生。“悟净”利用OS内核侧进行内存优化的天然优势,保障业务内存使用性能前提下,将较冷的内存换出至较便宜的设备上,从而降低整机的内存消耗,提高内存资源利用率,通过平滑降配、负载调压、内存超卖等手段实现降本增效,助力业务和客户商业增值。下面跟着本篇文章,来了解一下TencentOS“悟净”的强大之处吧!
01、业界面临的问题与机遇
1.1 高昂的内存成本
近年来,随着业务发展,内存使用成本日益陡增。根据公开报告显示,服务器硬件在数据中心成本占比达到80%左右,其中 DRAM 的采购是主要成本之一,外加能耗、维护等开支,内存开销随着内存密集型业务的持续增长而日益上升。
应用程序为了提高性能,大都采用内存密集性策略,即尽量将内存利用起来,提高缓存性能。与此同时,由于有“数据中心税”(为了维持数据中心运作而在服务器上运行的大量额外运维程序)的开销,服务器中也会存在大量长时间占据内存的常驻应用。这一系列问题导致服务器内存使用率居高不下。
下图展示了服务器运行 splash2x/water_nsquared/rec 时,内存的访问热度。其中冷页(黑色)部分占比将近一半:
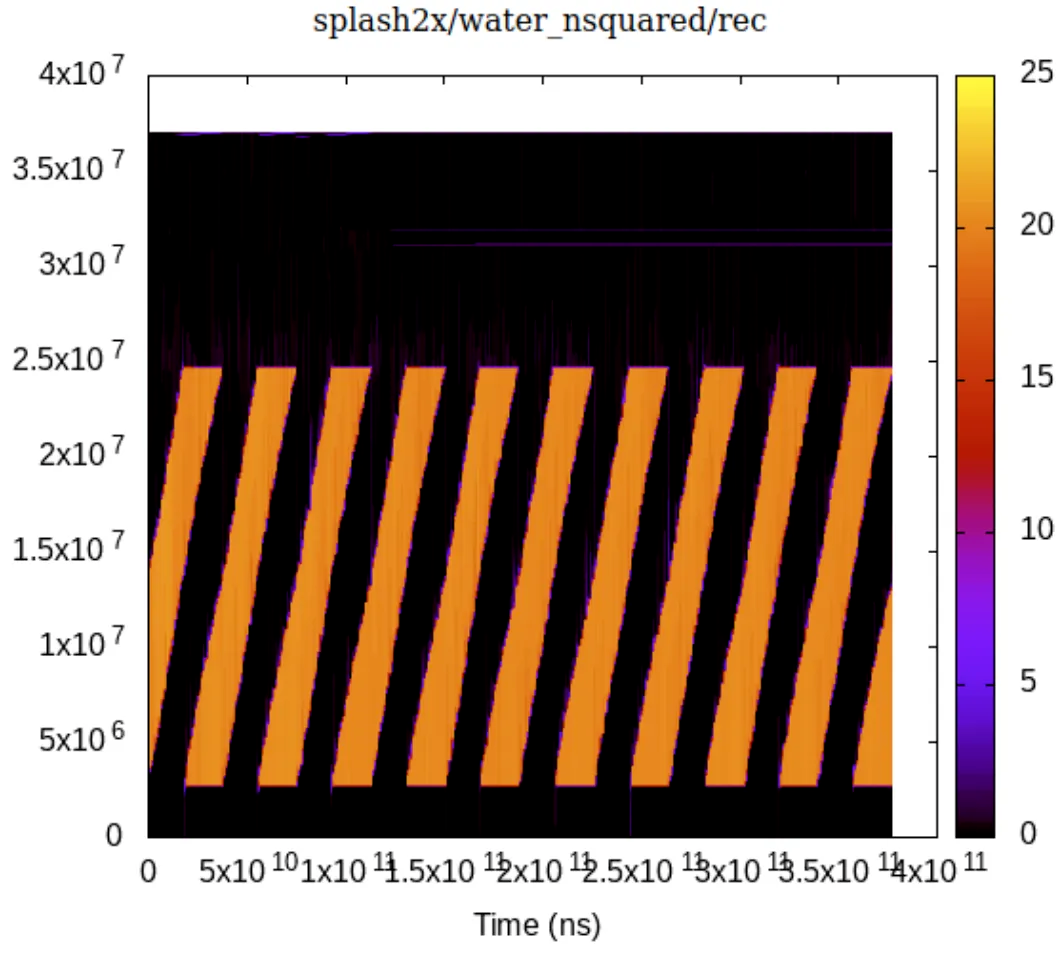
如何将这些冷内存页节省下来,是一个挑战和收益均巨大的问题。同时降低内存中这些无效冷页驻留,将内存留给更有需要的业务,可以极大程度上提升业务性能体验。
1.2 内存换出与内存压缩技术
对于内存的降本增效,最常用的方法是将其换出到相对廉价的存储设备上。随着技术发展,SWAP 内存换出已经有了满足高性能需求的潜力。
一方面,得益于高性能内存压缩算法和 CPU 性能的提升,我们可以消耗极少的 CPU 时间来进行内存内部的 SWAP 压缩换出,换取内存空间。另一方面,新的高速存储设备也能在满足换出精度的情况下,作为次级 SWAP 后备使用。
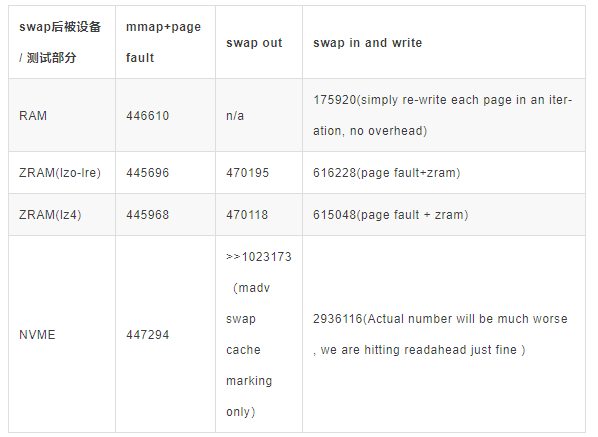
针对这些技术,社区也有过相关讨论[1]。我们进行了摸底测试,模拟 fault in 与 swap out 对连续全页读写的影响。以内存压缩 SWAP 设备 ZRAM 和高速 NVME 为例,在全页访问的模拟业务中,ZRAM 整体性能慢于内存 3-4 倍,NVME 由于 IO 栈干涉,性能逊色很多。若使用 ZRAM 作为首选设备,可以做到相对平滑的换出。
1.3 CXL内存池化
CXL 作为新兴的满足内存一致性互联协议,使得内存分级卸载有了更多的使用需求。CXL 可以通过池化方式让 CPU 访问海量内存,其慢于 CPU 所对应的 Local Node 内存,但远快于 IO 与内存压缩,因此换出优先级是最高的,若将 CXL 作为内存卸载的首选设备,可以在提升内存利用率的同时提高业务性能。
02、业界方案
针对内存降本增效这一大问题,Meta 提出了 TMO 方案[2],也是我们着重进行了摸底与分析的方案之一。
TMO(Transparent Memory Offloading,透明内存卸载)在用户态无感知的情况下,将内存换出到相对便宜的设备上,其大致原理如下图中三个部分所示:
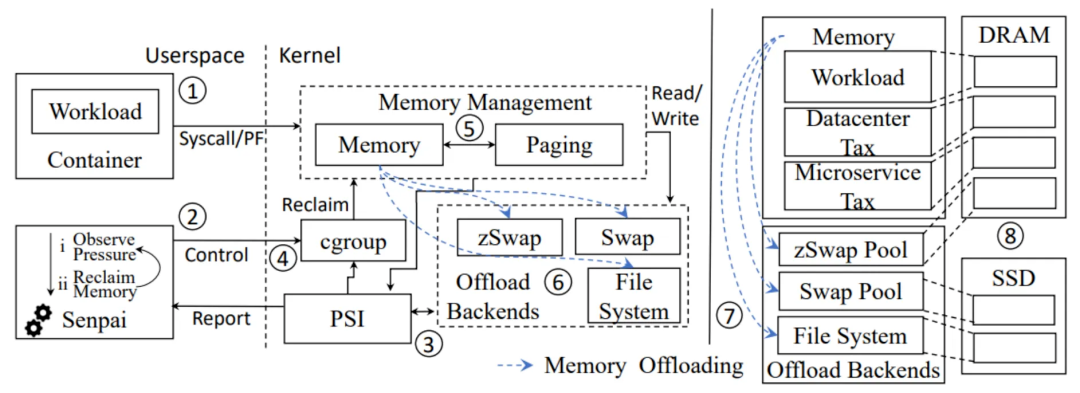
用户回收策略层:用户态监控工具根据 Cgroup 内存压力信息,自动调整 Cgroup 水位线。
内核数据采集层:内核中采集 Cgroup 级别的内存压力信息为用户策略层提供信息。
内核均衡回收层:内核依据 Cgroup 水位线回收内存页,并根据 LRU 自动匿名页的 refault 率和匿名页的 swapin 率进行反馈调节。
Meta 声称 TMO 方案在数百万的服务器上节省了总内存的20%~32%。我们在调研过程中,进行了基于 TencentOS 的全量功能复现,在技术、性能等多方面进行摸底。可以得出和Meta论文相似结果:性能轻微损失、内存大幅降低。
03、悟净技术方案
总结业界方案,结合内部的错综环境与部署需求后,悟净方案应运而生。悟净经过多次迭代和反复推敲,通过将多个模块松耦合、紧设计的方式聚合而成,做到了部署上的灵活性、应用上的高效性。
3.1 方案架构设计
悟净核心方案设计如下图(图中所有功能已全量实现):
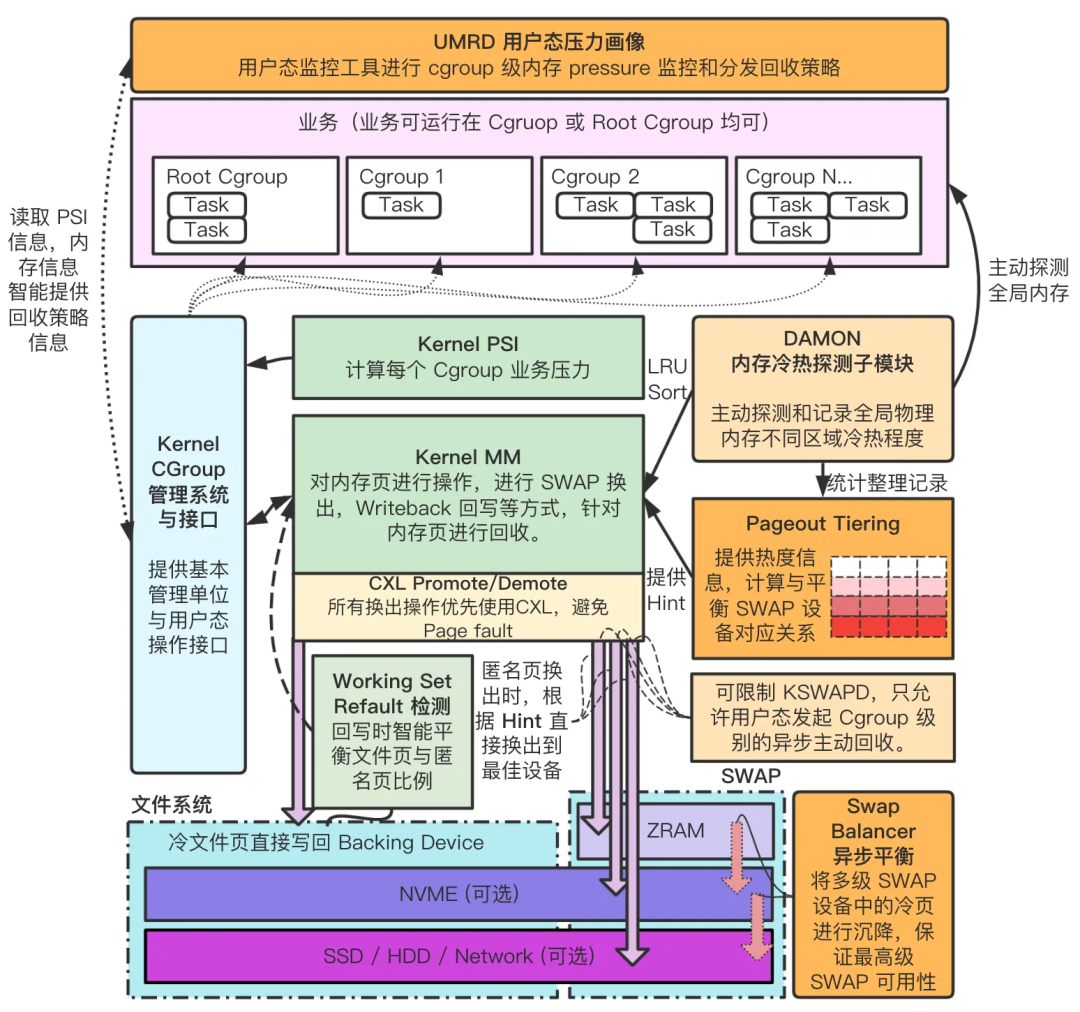
悟净基于内核内存管理系统 LRU 页面回收机制,对其核心路径做了大幅调优与改造,并引入以下几大独立自研模块:
UMRD (Userspace Memory Reclaim Daemon):用户态主动式异步回收进程,根据压力信息平衡回收策略。DAMON 核心子模块:主动探测内存热度,提供分级回收数据源。SWAP hinting 框架:在页换出时根据页面热度进行多级回写平衡。SWAP balancer 模块:异步平衡多级 SWAP 设备,精准冷内存沉降。CXL 支持:利用内核 Promote / Demote 框架避免 Page Fault 与 IO,提高性能。核心性能优化:针对内核内存管理核心代码、Cgroup V1 PSI、SWAP 路径、Working Set 统计等,进行了大量优化,部分已经upstream。 |
|---|
- UMRD (Userspace Memory Reclaim Daemon):用户态主动式异步回收进程,根据压力信息平衡回收策略。
- DAMON 核心子模块:主动探测内存热度,提供分级回收数据源。
- SWAP hinting 框架:在页换出时根据页面热度进行多级回写平衡。
- SWAP balancer 模块:异步平衡多级 SWAP 设备,精准冷内存沉降。
- CXL 支持:利用内核 Promote / Demote 框架避免 Page Fault 与 IO,提高性能。
- 核心性能优化:针对内核内存管理核心代码、Cgroup V1 PSI、SWAP 路径、Working Set 统计等,进行了大量优化,部分已经upstream。
其中大部分模块均可以独立工作,SWAP 设备类型也可以自由灵活选配,满足设计与部署上的灵活需求。
3.2 悟净的技术优势与突破
悟净方案涉及多角度、全方位的内核调优与联动,下面分不同子系统分别进行介绍:
3.2.1 Cgroup 级内存压力与热度监控
Cgroup 级别的资源监控是悟净核心要点之一,在上游和已有方案中,PSI、DAMON 等均缺失 Cgroup 兼容支持方案。
PSI V1 支持
PSI 模块(Pressure Stall Information)是监控内存压力的主要指标。典型的 PSI 统计值输出如下所示,其展示了进程因为内存缺乏而发生阻塞时间比例统计与总计时:
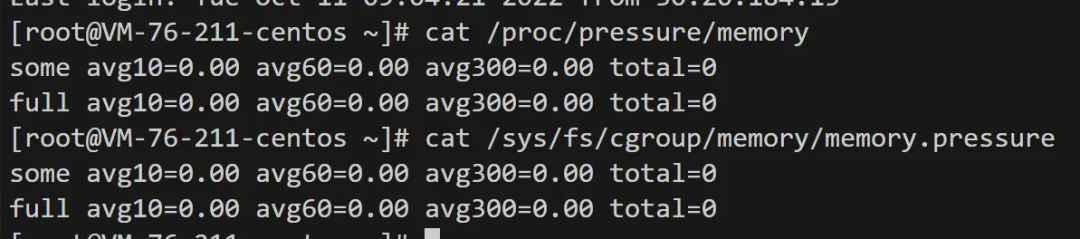
由于 Cgroup V1 设计缺陷,PSI 无法整合不同资源进行联合计算,所以上游放弃了相关支持。社区提出过 Cgroup V1 PSI 方案[3],该方案被众多云厂商采用,但是实测发现,具有对性能有一定冲击、并且在内存压力大的时候会失准等问题。我们重新构思,对 Cgroup V1 PSI 进行了完全重构,对资源事件分类过滤,大幅度优化代码实现,获得最大的上游兼容性同时提高性能。
上游 DAMON 亦缺失 Cgroup 支持。我们与 DAMON 作者进行了沟通,讨论了多种实现方法,最终实现了per-cgroup DAMON支持,并且和PSI结合提供更高监控精度。
3.2.2 UMRD - 业务压力自适应画像
UMRD 负责根据 PSI、RSS 等内核信息,主动进行异步回收,采用了循序渐进的回收策略,兼顾性能与回收效能。
UMRD 回收算法
UMRD 基于 PSI 进行内存回收负反馈调节,其大致回收量计算公式如下:
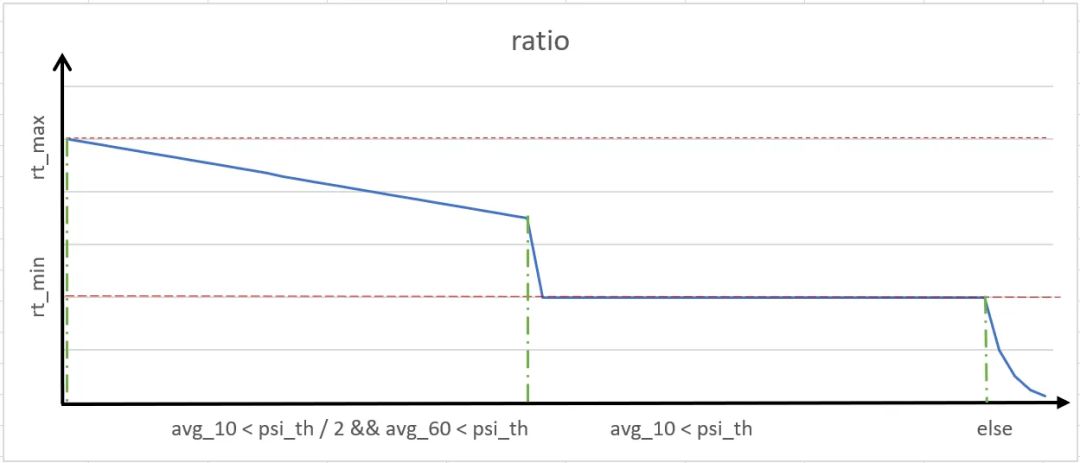
在部署方面,UMRD 提供多种灵活的回收模式来适应多变的业务需求。例如,支持非容器化业务的 Root Cgroup 监控回收、支持监控所有 Cgroup 并自动平衡回收、支持黑白名单、容器优先级选择性回收等。
UMRD 既支持传统的 Systemd 与包管理结合的方式部署,也兼容 DaemonSet 的云原生部署方式,并提供大量可调节参数,做到了开箱即用和灵活部署。
UMRD 针对大规模 Cgroup 部署进行的优化
在大规模 Cgroup 环境中,我们使用大量 profiler 进行了长时间监控调优。在引入 Pypy 运行时,大量使用 slot,dequeue 等等 Python 高性能操作原型,对缓存、类设计等模块进行调优,让 UMRD 在万级容器服务器中也可以以不足 0.5% 的开销进行全局监控。
3.2.3 Workingset Refault 模块 - 页面换出自适应平衡
内存卸载回收过程中一个重要步骤是平衡文件页和匿名页的回收比例。匿名页的换出需要 SWAP 设备来作为后备回写对象,文件页则直接回写到文件对应设备。为了防止过激的回收带来的重复换入 IO 负载和性能损耗,内核中引入 Workingset 机制,通过统计换入换出时的信息,计算出保持内存回收的最佳回收比例。
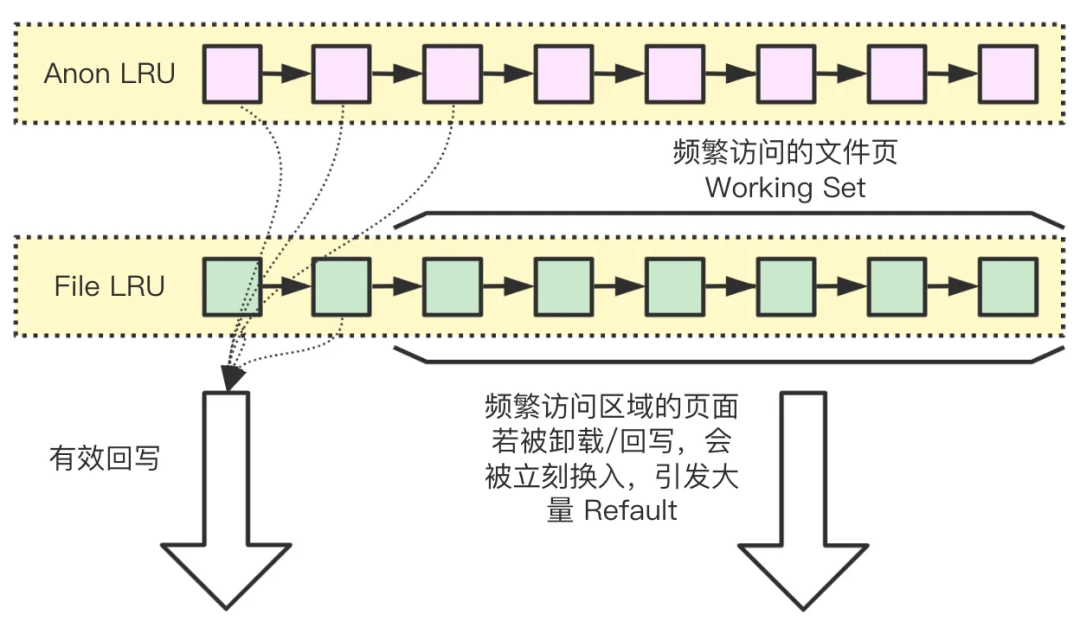
我们深入优化了 TencentOS Working Set 模块,与上游进行对齐,只需扫描更少的页面数量,就能回收到足够的页面数,与之前的回收策略相比,refault 次数明显减少。
3.2.4 Pageout Tiering & Hinting - 主动内存热度探测与分级
为了实现页面热度分级,我们利用 DAMON 作为热度分级功能实现的基石。
DAMON 核心算法
DAMON 可以以极低开销监控全局内存的冷热分布。其核心思想是内存可以根据冷热程度进行分区。DAMON 采用随机稀疏采样,推测每个区域内存的整体热度。可以大致分为如下几个步骤:
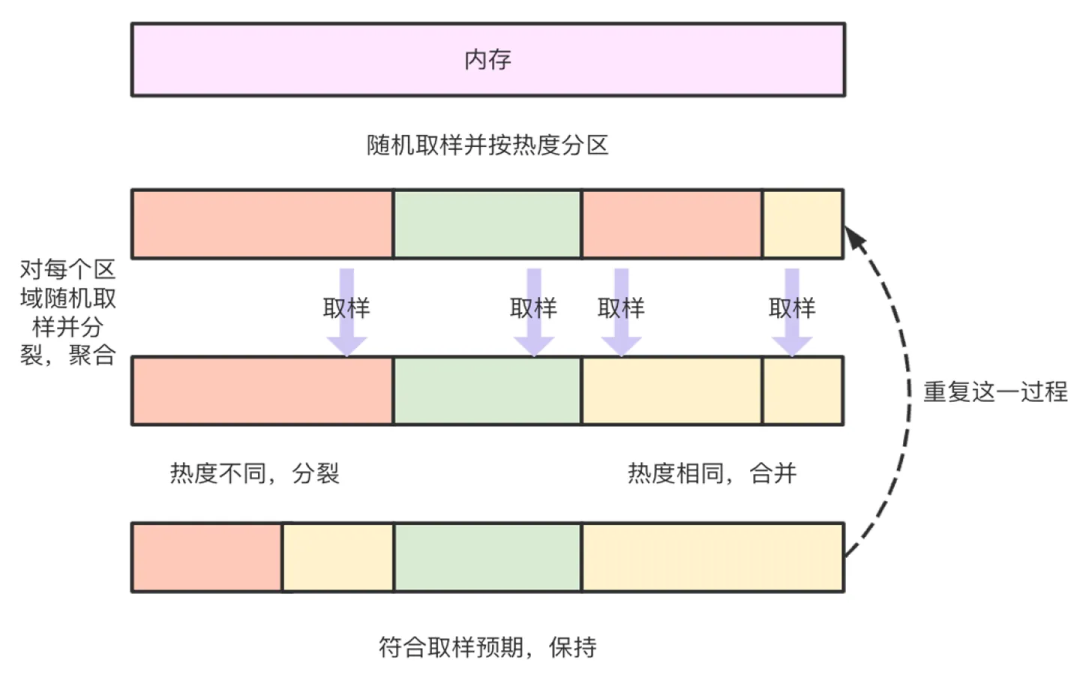
每个采样区域会经过随机稀疏采样、合并相似近邻区、现存区域分裂等步骤迭代。大部分情况下,DAMON 都可以收敛到一个相对精准而低开销的稳态。
LRU Sort 与 Page Tiering—内存热度分级
利用 DAMON 得到的热度信息我们做了两个处理。首先,我们使用该信息对内核中现存 LRU 进行了优化,通过页面热度信息调整 LRU 表,使得回收页面采集更加精确,其过程如图:
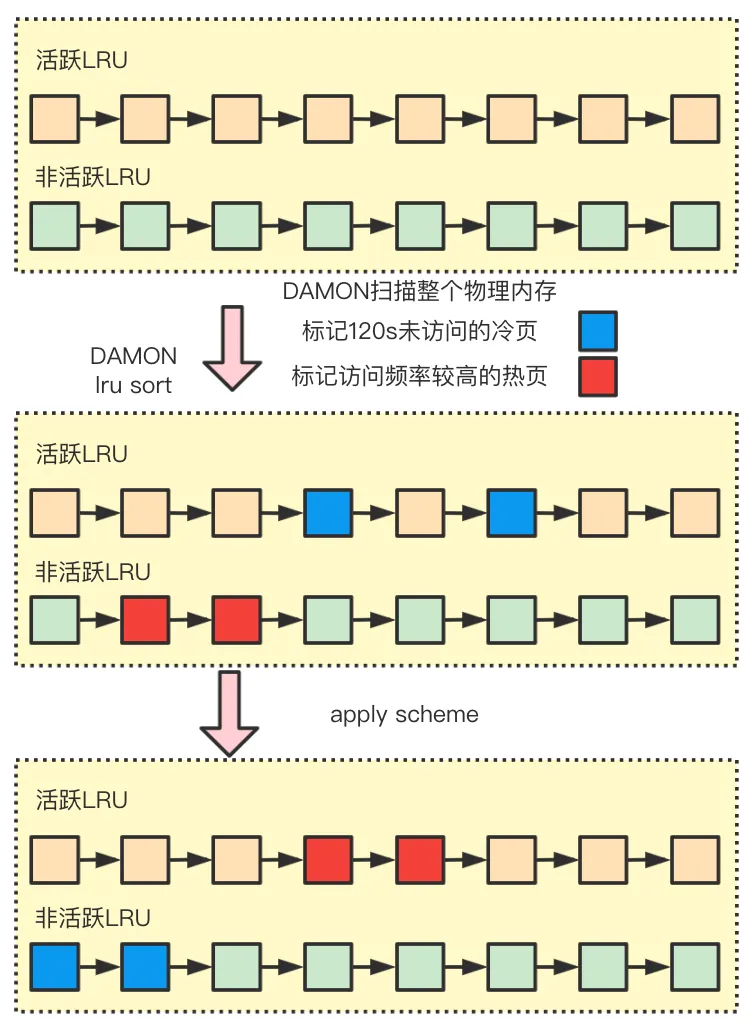
另外,我们大幅度扩充了 DAMON 核心功能,增加默认的全量物理地址监控,并实现了 Page Tiering 模块,将内存热度信息存于高性能快速查询表中,为 SWAP hinting 提供了热度信息来源。
SWAP hinting - 主动内存回收分级
SWAP Hinting 模块根据 Page Tiering 提供的热度信息,在页面换出时将页面均衡地换出到不同速率 SWAP cache 上。为提高换出性能,我们对 SWAP cache 模块也进行了优化,实现对每个 SWAP 设备的独立 cache,保证多级换出换入性能。
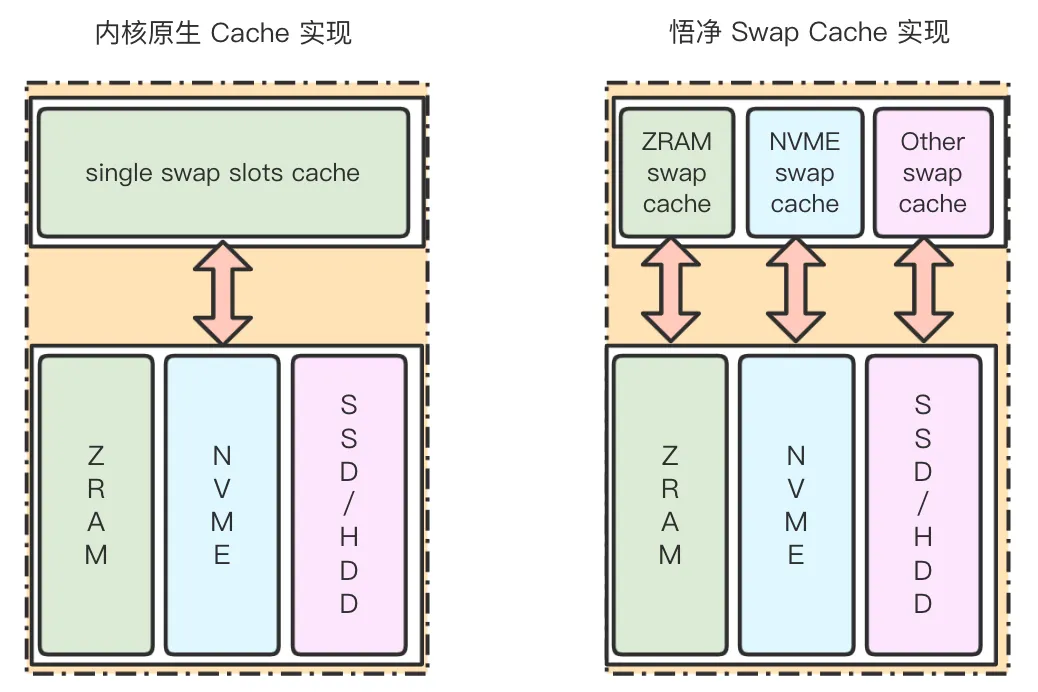
3.2.5 Swap Balancer 模块 - 统一自适应后备设备平衡
目前 ZRAM 设备是最容易部署且性能最好的 SWAP 后备设备。因此,我们的换出策略中尽可能保证 ZRAM 这样的高性能设备优先使用。但长期运行会导致 ZRAM 被占满,并且 ZRAM 本身依旧需要耗费内存,这都会造成性能损失。
SWAP Balancer 应运而生,其对于每个 SWAP 后备设备维护一个 LRU,当 SWAP 设备用量达到水位线(如 80%)时,便可以将最冷页异步迁移到次级 SWAP 设备。
SWAP Balancer 以页为单位进行异步迁移,直接操作页表,保证了 Critical Section 尽可能的短,通过慢速长期的异步迁移操作,可以很好得使冷页精准“沉降”到冷设备上。
3.2.6 Anon Protection 模块
原生 kswapd 有可能会因水位线回收而造成一些业务抖动,我们提供的方法只允许“悟净”异步进行匿名页回收,并细粒度控制文件页和匿名页回收比例。
考虑到上游 Cgroup V2 的 Per Cgroup Swappiness 已被废弃,我们扩充了内核 memory.reclaim 接口,实现了单次回收独立 Swappiness 支持,统一了 Cgroup V1、V2 回收接口,可以细粒度、可控地进行页面回收。
3.2.7 针对内核核心代码的优化
在“悟净”开发过程中,我们也发现并优化了大量内核中的上游缺陷和特性,有些已经存在了十年之久,因为原因错综复杂而迟迟未得以修复,比如 RSS 计数器的滞后和性能问题等。我们针对现代处理器结构,进行了重新设计,彻底修复精度问题的同时提高了性能,一些数据库 benchmark 中可以有近 5% 的提升,相关工作也被摘录到了 LWN Weekly [4]。
04、悟净效果
在研发过程中,我们使用大量 benchmark 工具与 TMO、原生内核进行对比测试,不断迭代和调优得到最终效果。
4.1 效果自测
此处展示目前我们的自测数据:
为了更好的模拟混合部署情况下的性能问题,我们分别使用了 pgbench,nginx,build-linux-kernel 等进行了混合部署、重负载情况下的交叉测试,结果如下:
pgbench | pgbench TPS | Avg - lat (ms) | nginx - RPS | BLK - Time |
|---|---|---|---|---|
na | 2733 | 36.612 | 152135.12 | 188.693 |
Meta-TMO | 2763 | 36.323 | 149332.00 | 180.166 |
Tencent-umrd | 2869 | 34.903 | 140989.81 | 203.169 |
内存使用情况如下,其中“悟净”(灰色)内存使用显著下降:
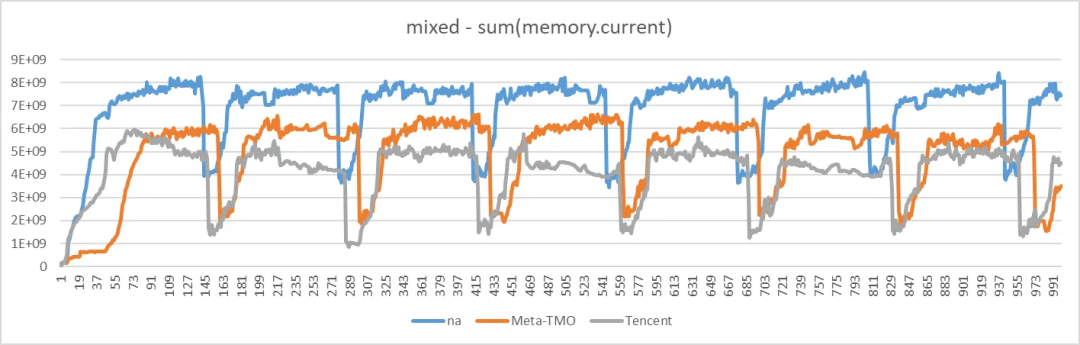
从以上结果可以看出,除调度策略导致的差异外,悟净在性能上和 TMO 相近,而回收策略上更加优秀。
4.2 业务联动实测效果
悟净已经放出第一版 Stable Release,联合业务进行部署测试。在目前的测试中,我们得到了不错的结果反馈。
现网业务中,开启悟净前后的内存使用图:
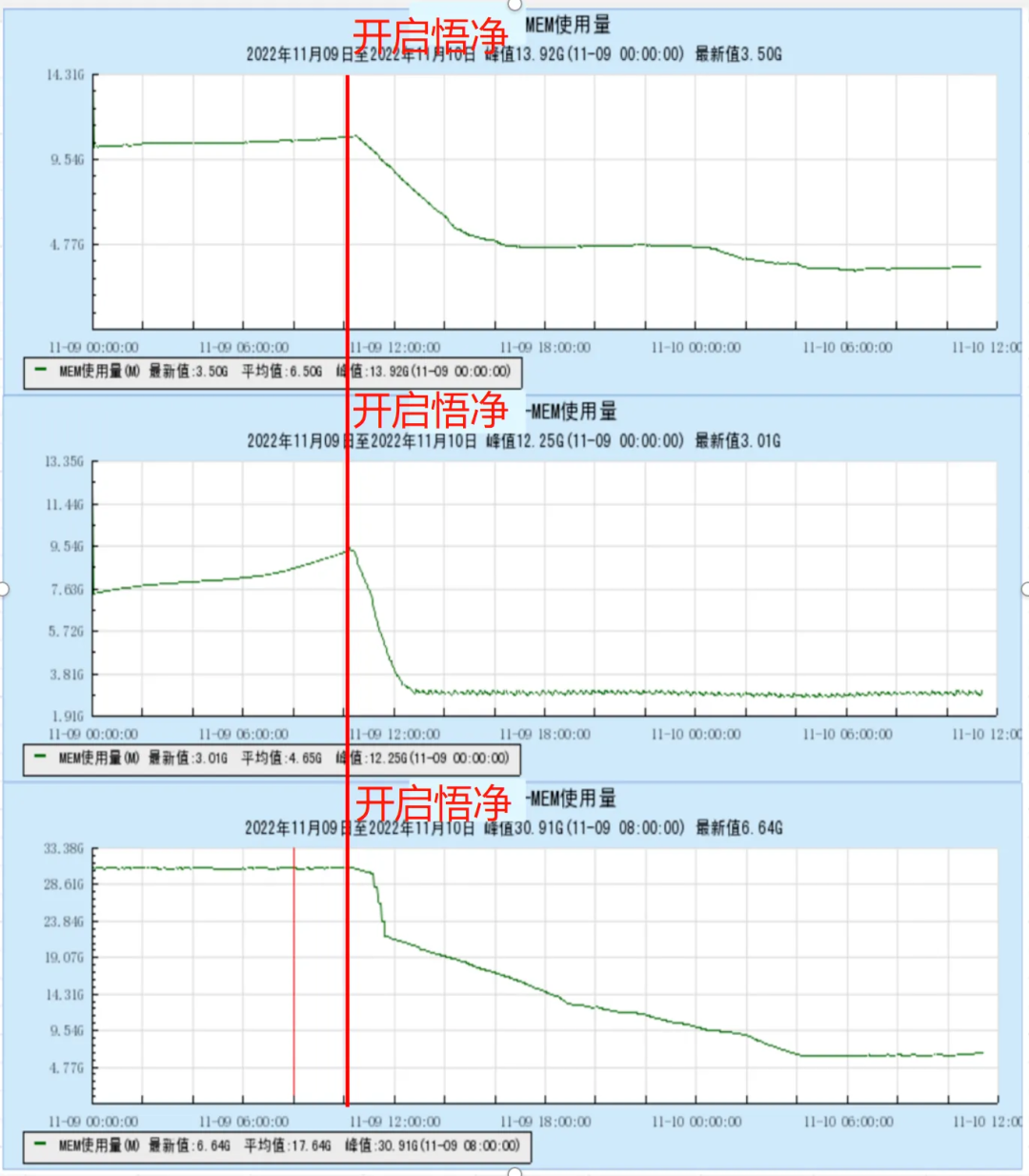
根据业务类型不同,内存可以压缩的比例、换出率等均有区别。悟净平衡了性能、系统负载与内存回收的关系,在绝大部分实际测试中,可以取得极佳的内存节省效果。
“悟净”经过多轮实际部署联动测试,可以全方位支持多种内存降本增效场景,其中典型的应用场景有:
应用场景 | 具体流程 |
|---|---|
平滑降配 | 业务可以通过部署“悟净”方案适度降低配置,在不损失性能的情况下降低配置成本。 |
内存超卖 | 同等资源可以释放更多可用内存,部署或售卖更多业务实例。 |
负载调压 | 自动进行业务画像,自适应进行内存负载调节,降低颠簸的同时节约成本。 |
悟净最大限度节省内存,兼容现有业务模型(TK4,CGroup V1,CGroupless...),同时对业务性能影响很小,全方位助力降本增效、商业增值。
4.3 业务影响
在外界连接中,除了直接开源社区贡献,在业界知名论坛也获得了同行的注意。在 2022 年的 CID (中国云基础架构开发者大会[5])与 CLK (中国 Linux 内核开发者大会[6])上,“悟净”项目均以多级内存卸载为题参会演讲。
05、总结
当前,“悟净”产品已在腾讯内部一些业务中进行多轮联动实测,在保证用户延迟、QPS性能且系统压力不超载的前提下,内存用量平均降低了30%,部分场景中甚至可节省一半以上内存(不同业务类型敏感度不一样),取得了不错的效果。后续我们会继续聚焦优化内存降本增效技术,提升内存资源利用率,通过技术手段助力业务商业增值。
本次分享到这里就结束啦!如果对我们后续内容感兴趣,欢迎收藏转发本片文章,期待与大家在评论区分享交流。
相关链接:
1. 关于内核交换策略的讨论:
https://lwn.net/Articles/690079/
2. TMO论文:
https://www.pdl.cmu.edu/ftp/NVM/tmo_asplos22.pdf
3. 社区psi cgroup v1支持方案:
psi: support cgroup v1 [LWN.net]
4. https://lwn.net/Articles/902883/
5.中国云计算基础架构开发者大会——性能优化:
https://lwn.net/Articles/902883/
6. 中国Linux内核开发者大会——内存管理与异构计算分论:
http://ckernel.org/




腾讯云开发者
