GPU or CPU?在NLP与AI加持下的Elasticsearch搜索场景我们应该选择什么样的硬件
原创
GPU or CPU?在NLP与AI加持下的Elasticsearch搜索场景我们应该选择什么样的硬件
原创
点火三周
发布于 2023-06-16 12:06:00
发布于 2023-06-16 12:06:00

Generative AI时下的爆发,催生搜索场景进入一个新的范式,我们越来越多的使用全文检索+向量搜索的混合搜索用于召回多更相关的数据,使用NLP模型增强对数据理解、丰富数据的层次,甚至是使用ML模型来进行召回后的精排,或者是使用生成式AI来对结果进行生成式的输出,而非召回后的直接排序结果。
我们很高兴看到,在使用Elasticsearch作为主要技术栈的应用和环境中,用户可以无缝地支持以上所有的场景,无论是向量相似性搜索,混合搜索、NLP模型的推理,还是生成式AI的应用,开发者都可以根据自己的资源情况和预算情况挑选出最符合自己需求的技术组合,用于适应业务需求的变化。
虽然Elasticsearch已经提供了丰富的功能,但在具体的实施层面,开发者还需要在很多层面进行选择和决策,比如选择什么样的模型来进行embedding或者NLP任务的推理,模型的大小与计算资源的关系,数据大小与计算资源的关系,都会影响到最后应用的表现和用户体验,关于这个部分,我们可以通过阅读官方网站的How To,来了解更多需要进行配置与注意事项,特别是tune-knn-search与模型部署。
但另外一个非常基础的问题是,Elasticsearch有计划使用GPU来进行计算加速吗?其实我个人也有这样的疑问。因此,在本文中,我们将尝试探讨目前在Elasticsearch的场景中使用GPU是否是合适的?
CPU 和 GPU 的基础知识
中央处理器(CPU)和图形处理器(GPU)是计算机系统中的两种关键硬件组件,它们在设计和工作原理上存在显著差异。
CPU 是计算机的主要计算核心,设计用于处理复杂的逻辑和控制任务(顺序执行)。它的架构主要优化用于低延迟的任务,能够处理一小部分数据的复杂操作。CPU 通常拥有较少的核心(例如 2 到 32 核),但每个核心都能够独立处理任务,因此能够支持多并发。
相比之下,GPU 最初设计用于图形渲染,特别适合执行大量并行计算任务。GPU 拥有成百上千个较小、较弱的核心,这使得它们能够同时处理大量数据。因此,对于深度学习、图形渲染、科学计算等大规模并行计算任务,GPU 通常比 CPU 更有效率。
Elasticsearch 在 CPU 和 GPU 上的运行情况
就目前而已,Elasticsearch 所有的工作都是在 CPU 上运行的。它能够充分利用 CPU 的多核心特性,由于 Elasticsearch 的大部分工作是 I/O 密集型的,包括磁盘 I/O(读取和写入数据)和网络 I/O(数据复制和分发),CPU 的多核和多线程特性能够有效地支持这些任务。而在使用场景上,Elasticsearch也能充分利用CPU的多核能力为搜索请求提供并行处理能力。这其中也包括了向量搜索。这一特点确保了搜索请求能够以高效的方式和高水平的并发吞吐量得到处理。此外,通过集群模式、分片和副本机制,Elasticsearch 能进一步支持各种搜索场景下的并发需求。通过利用这些功能,Elasticsearch能够提供一个最佳的搜索性能和可扩展性水平。
同样的Elasticsearch上的机器学习节点也是使用CPU进行推理计算,通过配置推理管道-模型分配-线程之间的关系,Elasticsearch可将模型在内存中共享,并为不同的机器学习任务在多个CPU内核之间调度。
而目前,在Elasticsearch的使用场景中,可以使用GPU来加速的场景主要包括NLP模型的推理任务和向量搜索这两种。因此,探讨当使用Elasticsearch来执行大量的推理任务或者处理大量的向量数据时,利用GPU技术来加速这些计算密集型任务,是否可行,存在哪些难点,将是本文探讨的重点。
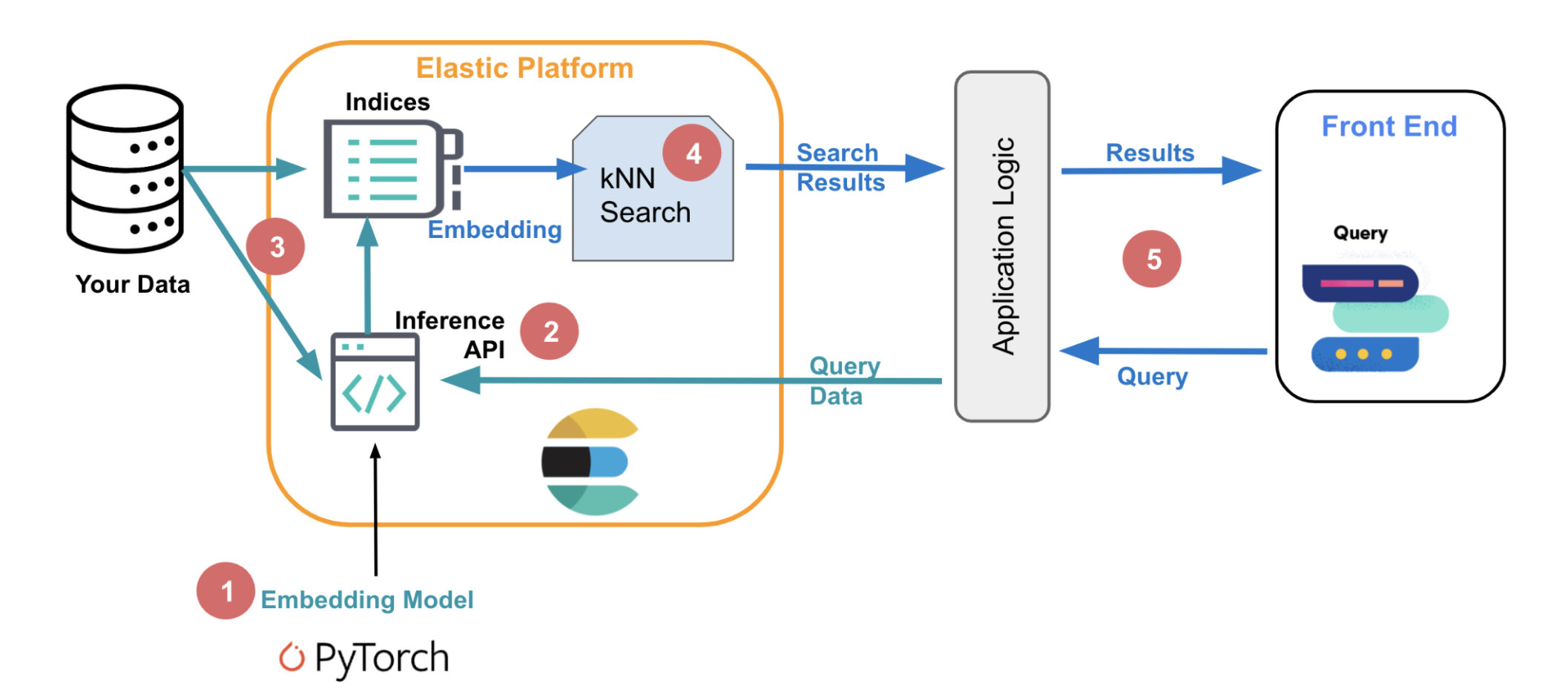
1、2、3、4可使用GPU加速
在 Elasticsearch 通过GPU来运行NLP推理任务
按照上图的数据流程,我们先来分析,目前是否值得或适合在 Elasticsearch 中使用GPU来运行推理任务。
首先,我们知道Elasticsearch的NLP以transformer为主的BERT派生模型(可以参考以前的系列文章:在Elasticsearch中使用NLP技术,提升搜索相关性, Elastic进阶教程:构建一个基于NLP的财经热点分析系统),包括:
这些NLP任务都是基于transform的计算任务,主要在BERT模型上派生。将模型部署到Elasticsearch中之后,这些模型将被用于执行推理任务,而深度学习模型transform的训练和推理任务都包含了大量矩阵运算的任务,比如:
- 自注意力机制:Transformer 中的自注意力机制需要计算输入序列的每个元素与其他所有元素的关联性。这个过程需要进行大量的矩阵运算,如矩阵乘法和矩阵加法。
- 全连接层:Transformer 中的全连接层(Feed Forward Neural Network)也需要进行大量的矩阵运算,如矩阵乘法。
- word embedding:在进行词嵌入时,我们通常使用一个嵌入矩阵将输入的词或者词序列映射到一个连续的向量空间。这个过程也需要进行矩阵运算。
因此,这部分内容原则上是可以被GPU所优化的。但是否应该使用GPU优化,还需要看多方面的因素。
首先是投资回报率,因为相对来说,GPU的价格比CPU要贵了很多。另外,需要注意的是,并非所有的深度学习任务都对GPU友好。有些任务可能计算量较小,或者模型本身较小,此时使用GPU可能无法带来明显的性能提升。
以下是目前Elasticsearch测试过兼容性的NLP的模型的大小,可以看到模型普遍不是特别大,因为笔者没有做过测试,因此,不确定使用GPU是否就比CPU要有非常明显的提升。
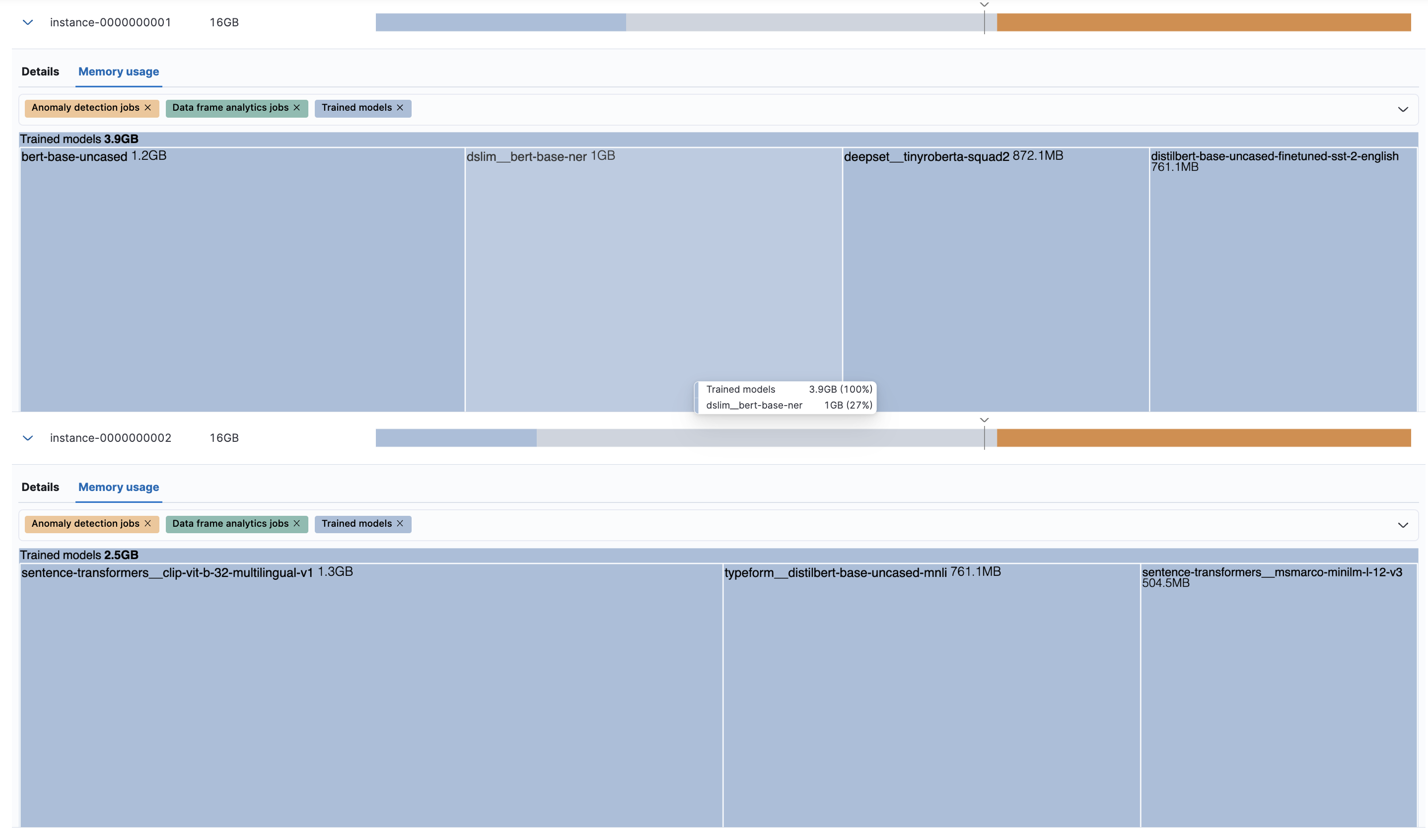
另一方面,目前Elasticsearch机器学习节点上并没有运行python解析器,这些Pytorch的模型都需要导出为script模型,在C++环境下的Libtorch运行。而在当前的C++代码中,并没有去判断device是否支持CUDA,然后针对不同的硬件,使用不同的模型配置。
同时,对于一个应用于搜索生产环境的管道,稳定性和灵活性会异常重要。是否能够灵活分配同一个管道中,不同任务所获得的资源、执行的优先级。会是一个非常重要的功能,而GPU的资源很难做到像CPU一样清晰的隔离和配置。无论是计算核心和内存资源,GPU都只能在显卡之间进行分配,而无法在更细粒度进行分配和调度。因此,在整个管道中可能涉及到多种NLP任务,并且任务支持多并发,多类型的情况下,CPU拥有用GPU无法匹配的灵活性。即CPU更适合多而杂的环境,GPU会更适合专而精的环境。
再者,在各种公有云和私有云环境中,CPU核心和内存资源更适合切割为合适的大小。而GPU的计算核心和显存则是不可切割的。这也使得使用CPU时,我们能够更灵活的控制成本,不仅可以根据需求,选择跟吞吐匹配的资源,还可以开启自动扩容,来灵活的应对流量的潮汐变化。而GPU则很难做到这一点。
在 Elasticsearch 通过GPU来运行向量搜索
Elasticsearch 最初是作为一个全文搜索引擎设计的,它的主要功能是处理文本数据,而不是向量数据。全文搜索主要是 I/O 密集型的任务,而不是计算密集型的任务,因此 CPU 的特性(如多核心、多线程)很适合这种任务。但是,由chatGPT带来的生成式AI的全面爆发, 让我们进入了混合搜索的时代,我们不再仅仅是处理文本数据,向量数据也将出现在非常多的场合。那么在向量相似性的搜索,适合使用GPU来进行计算吗?这取决于您的数据量、维度、精度和速度的需求。一般来说,GPU可以提供更高的并行性和计算能力,从而加速向量相似性的搜索。但是,GPU也有一些限制和开销,例如内存容量、数据传输、功耗等。因此,并不是所有的向量相似性搜索场景都适合使用GPU。
而因为目前Elasticsearch主要支持的是HNSW这个向量索引算法,所以,我们会主要集中在这块探讨。
在使用GPU来加速HNSW的时候,对HNSW的索引大小有限制吗?
是的,使用GPU来加速HNSW的时候,需要考虑GPU的内存容量。因为HNSW是一种基于图的索引方法,它需要存储每个向量的邻居信息。这些信息会占用额外的内存空间,而且随着向量维度、向量数和邻居数(M值)的增加而增加。如果您的数据集太大或者您的M值太高,那么您可能无法在GPU上建立或搜索HNSW索引。
通常来说,HNSW的索引大小与向量维度、向量数和M值有关。根据HNSW论文,向量维度和向量数决定了原始数据的大小,而M值决定了图结构的大小。算法的内存消耗情况,主要由图连接的存储所决定。每个元素的平均内存消耗可以计算为 (Mmax0 + mL Mmax) bytes_per_link。当最大总元素数量限制在约40亿时,使用四字节的无符号整数来存储连接。文章还提到测试表明,最优的M值(表示连接数量)通常在6到48之间。因此,索引的典型内存需求(不包括数据本身的大小)估计为每个对象约60-450字节。
如果我们做 10 亿个文档,每个文档是 128 个维度(客户可能会使用更高的维度,例如 256、512 或 2048)。我们使用 HNSW 来支持 ANN。HNSW 需要存储两个东西,第一个是原始嵌入,第二个是图。原始嵌入大小为 512GB(1 10⁹ 128 4 = 512 10⁹ 字节 = 512GB),而图形大小为 160G(1 10⁹ 40 * 4 = 160G,假设每个节点有 40 个邻居)。如果我们需要存储元数据,那么总大小可以是 1TB。
在使用HNSW的时候,需要把整个索引加载到内存中吗?
是的,使用HNSW的时候,需要把整个索引加载到内存中,包括原始数据和图结构。这是因为HNSW是一种基于图的索引方法,它需要在内存中访问每个向量的邻居信息和距离信息。如果您将索引保存到磁盘上,那么在加载或搜索时,您需要从磁盘上读取数据,这会降低性能。
为什么需要把原始数据也放在索引中?这是因为HNSW是一种近似的相似性搜索方法,它不能保证返回最精确的结果。为了提高搜索质量,HNSW会在搜索过程中对候选结果进行重新排序(re-ranking),即使用原始数据和距离函数来计算更准确的相似度得分。如果没有原始数据,那么HNSW无法进行重新排序,可能会返回不准确的结果。
使用GPU的情况下,向量搜索是如何执行的
而在Elasticsearch当中,HNSW索引会被拆分到多个分片当中并存储于多个data节点上。结合以上的内容,如果使用GPU来进行向量计算:
- 首先我们得需要在所有包含了HNSW索引分片的data节点上配备GPU显卡。成本相对会非常的高,相比于只专注于执行机器学习和推理任务的机器学习节点,data节点上还执行了其他的主要的搜索和分析任务,任务多而杂,如果为每data个节点配备一个甚至是多个GPU显卡,在成本核算上会非常困难和挣扎。而且如NLP任务一样,因为GPU显卡资源的不可切割性,我们很难做到按需扩缩容。
- 向量搜索和NLP推理最大的区别在于,NLP推理任务加载到GPU显存的模型,而向量搜索加载到GPU显存中的是数据。而HNSW索引是包含了原始嵌入和图索引的,如上面提到的10 亿个128维的文档, 对于内存的消耗是非常夸张的。好几百G的memory需求,别说是GPU的显存,即便是内存可能是问题。考虑到一个GPU的显存通常也就是几个G,高端点的GPU有几十个G。要把很大的向量索引加载到显存当中,显然是一个非常不经济的选项。
- 当然,我们可以通过编程,让向量索引可以支持部分加载或者混合存储的方式,即只将一部分索引数据加载到内存中,而将其他数据存储在磁盘上。这样可以节省内存空间,或者对原始数据进行压缩或者编码,从而减少索引大小。但是,这些方案都会可能会牺牲搜索性能和搜索精度,并且增加复杂度。这与我们用GPU来提升计算速度的最终期望有点背道而驰。
总结
总的来说,Generative AI的发展对搜索场景带来了新的可能性。通过结合全文检索、向量搜索和NLP模型,我们能够更准确地检索和理解数据,并实现更丰富的搜索结果。在Elasticsearch的应用中,我们可以灵活选择适合自己需求的技术组合,从而满足不同业务场景的要求。然而,对于是否在Elasticsearch中引入GPU加速,目前还没有明确的答案。尽管GPU在NLP模型推理和向量搜索等任务中能够提供加速,但需要根据实际情况评估资源和性能的权衡。对于开发者来说,在选择合适的硬件和配置方案时,应该综合考虑计算需求、预算限制和性能要求。随着技术的不断演进,未来可能会有更多的选择和改进,以提升搜索场景的效率和用户体验。
希望本文对您有所帮助,如果您有任何问题或建议,请在评论区留言。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号