如何基于DataX做增量数据同步?

如何基于DataX做增量数据同步?

内容目录
一、DataX数据同步原理二、全量同步实现三、增量同步的思考四、增量同步实现方案五、关于DataX高可用参考
一、DataX数据同步原理
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
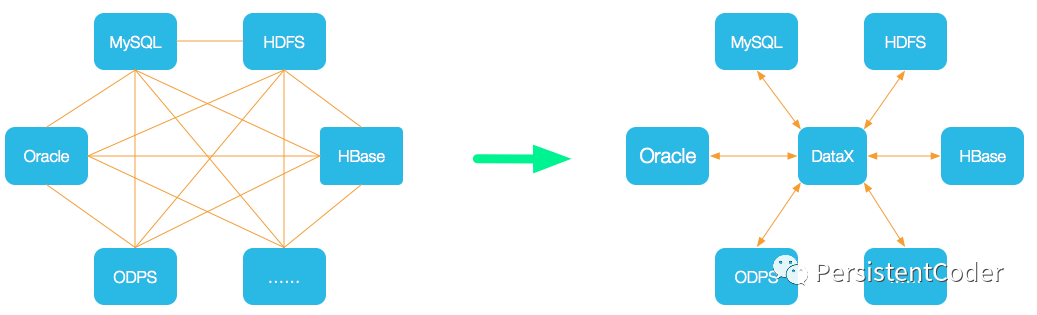
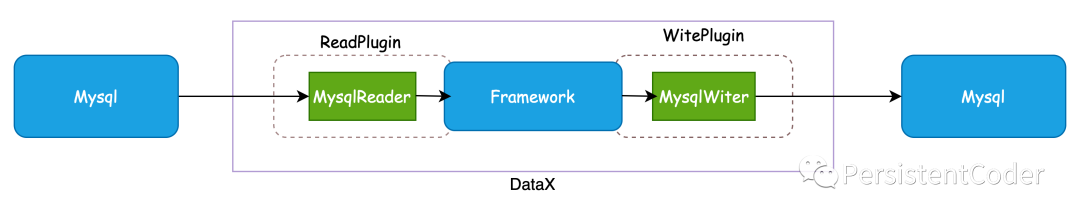
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer:Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,下图是一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
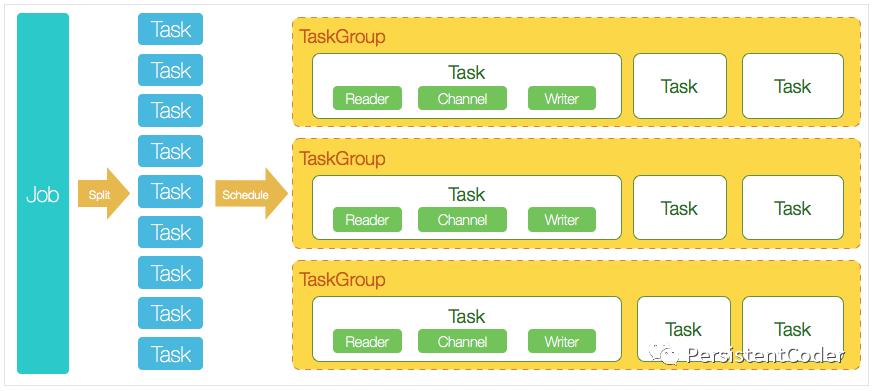
核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
二、全量同步实现
1.环境
Datax依赖python、java和maven环境,建议安装python2.7、jdk1.8和maven3.6,安装过程不细说。
2.安装Datax
mkdir -p /opt/tools/datax
cd /opt/tools/datax
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
tar zxf datax.tar.gz -C /usr/local/
rm -rf /usr/local/datax/plugin/*/._*3.编写同步脚本
查看同步模板:
python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter输出模板格式:
Please save the following configuration as a json file and use
python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": [],
"table": []
}
],
"password": "",
"username": "",
"where": ""
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [],
"connection": [
{
"jdbcUrl": "",
"table": []
}
],
"password": "",
"preSql": [],
"session": [],
"username": "",
"writeMode": ""
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}按照模板格式修改,替换数据源和目标表以及账密,在/usr/local/datax/script目录创建*.json脚本:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "source_user",
"password": "pwd",
"column": ["*"],
"splitPk": "ID",
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://sourceHost:port/database"
],
"table": ["source_table"]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": "jdbc:mysql://targetHost:port/database",
"table": ["target_table"]
}
],
"password": "pwd",
"preSql": [
"truncate target_table"
],
"session": [
"set session sql_mode='ANSI'"
],
"username": "target_user",
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "5",
"byte" : 5242880
}
}
}
}需要注意的是:
- datax机器对数据源机器和端口有访问权限,使用的账密对数据库和表有读权限。
- Datax机器对目标机器和端口有访问权限,使用的账密对数据库和表有写权限。
4.执行同步
执行同步脚本:
python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json但是有个问题,该命令是同步的,执行过程中需要窗口一直活跃,并且客户端不能断开,否则任务会终止,由于执行日志是控制台输出,执行完成后也无法查看执行日志,所以我们需要换成命令非挂起执行,并且输出执行日志到指定目录,用以下命令替换:
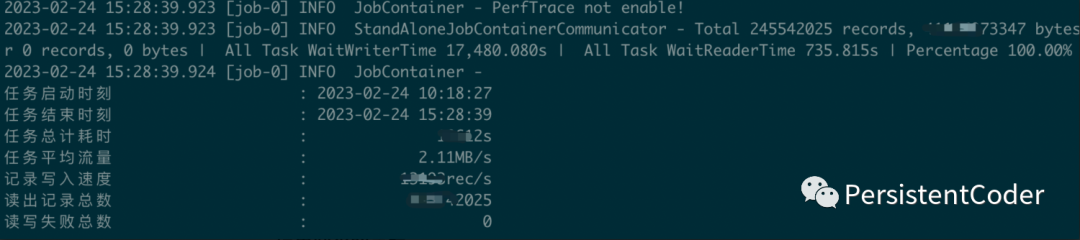
nohup python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json >> /var/log/datax/xxx.log 2>&1 &这样就不用一直阻塞窗口,也不会因为网络原因导致ssh客户端断开从而导致任务终止。从日志看到以下内容就代表同步任务执行成功:
三、增量同步的思考
当然,我们对数据的同步并不是每次都需要做全量同步,那么如果某些表已经做过一次存量同步之后,如何做增量同步呢?
首先Datax是单表同步,那么如果我们需要做增量同步,就需要知道增量的"量"是什么,度量规则是什么。
- 增量是指距离上一次同步(全量或者增量),增加的数据行数,也是本次需要同步的空间范围。
- 度量规则,当然我们会选用具有增长趋势的列作为度量规则,比如id自增主键,数据创建时间。
由于表的增长趋势不确定,所以无法确定增量同步的id开始值和结束值,无法使用id增长趋势作为度量规则,而对于时间是我们可以预期和确定的增量指标,比如T+1同步就是同步前一天24h的数据,5min同步一次等,这些我们都可以通过简单的计算可以确定开始和结束时间点。
当然增量同步不等于实时和近实时同步,更多的是用于数据备份和离线计算场景,Datax本身也不擅长做这些事情,如果有实时和近实时诉求可以使用其他方式,比如binlog解析工具canal等。所以我们这里所说的增量同步也可以理解为已经圈定为那些数据已经不会发生变更的数据场景,或者生命周期比较短的数据。
反向举例,对于电商的退货数据,本身业务场景的时间周期就比较长,那么从退货单的产生到退货入库出账,可能需要几天的时间,跨境可能需要十天半月甚至更长,那么在一定程度上或者在一定数据范围内,就不适合使用Datax做增量同步,因为T+1或者T+n同步过去的数据可能还会发生变更,如果不做处理那么就存在同步数据严谨性和准确定问题,如果做补偿处理反而把同步流程又变的及其复杂,所以这种还是考虑其他更好更适合的方案。
所以使用Datax通过离线的方式做数据增量同步更适合那种,数据生命周期比较短的场景,比如充值、提现和游戏订单等等,以及那些对边缘数据准确度不高的场景。
四、增量同步实现方案
之所以叫做增量同步,要么是实时触发,要么是固定频率触发,而Datax更适合使用固定频率的方式触发。固定频率那就逃不开调度,Datax是单机同步工具,那么我们可以考虑基于linux系统自带的调度crontab来做定时触发或者使用开源的调度平台来触发。
1.crontab+shell
使用linux系统自带调度能力crontab,比如一天同步一次,由shell脚本计算时间,再通过命令透传到Datax的json配置文件where条件中,对于mysql,where条件可以通过如下方式计算:
where create_time >= UNIX_TIMESTAMP(date_sub(curdate(),interval 1 day))
and create_time < UNIX_TIMESTAMP(curdate());同步脚本reader部分可以修改为:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "source_user",
"password": "pwd",
"column": ["*"],
"splitPk": "ID",
"where": "create_time >= UNIX_TIMESTAMP(date_sub(curdate(),interval 1 day))
and create_time < UNIX_TIMESTAMP(curdate())";
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://sourceHost:port/database"
],
"table": ["source_table"]
}
]
}
},
"writer": ...
}
],
"setting": {
"speed": {
"channel": "5",
"byte" : 5242880
}
}
}
}然后编写crontab调度:
crontab -e
0 0 1 * * ? * nohup python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json >> /var/log/datax/xxx.log 2>&1 &每天凌晨1点执行任务,同步前一天的数据,从而实现增量同步。另外需要注意的是增量同步使用的条件需要有索引,不然很容易把数据库实例的cpu打满。
2.分布式调度+shell
同样我们可以使用业内比较成熟的调度方案来触发同步命令来做增量同步,比如xxl-job支持shell调度方式的任务。
到Datax机器编写shell脚本:
#!/bin/bash
nohup python /usr/local/datax/bin/datax.py /usr/local/datax/script/xxx.json >> /var/log/datax/xxx.log 2>&1 &创建shell任务:
编写执行器shell脚本:

脚本任务的源码托管在调度中心,脚本逻辑在执行器运行。当触发脚本任务时,执行器会加载脚本源码在执行器机器上生成一份脚本文件,然后通过Java代码调用该脚本;并且实时将脚本输出日志写到任务日志文件中,从而在调度中心可以实时监控脚本运行情况。
需要注意的是,即便你只想调度shell,执行器还是要的(具体原因可以参考xxl-job shell任务的执行原理),可以参考xxl-job-executor-sample-springboot写一个简单的执行器。
但是这种方式有点不伦不类,我为了执行脚本还要部署一套java服务?主要利用的是xxl-job的调度频率,然后到了执行时间节点后直接远程执行shell脚本就可以了,解决好内网机器间的免密登录和执行权限就可以了。
五、关于DataX高可用
Datax本身是一个离线同步工具,具备天然单机性,那么如何保证像微服务或者分布式调度那样保证高可用呢?
当然我们可以考虑像xxl-job调度实现那样,执行器集群部署时,会把节点都注册到admin,然后任务触发时会根据策略选址执行器执行,如果报错或者执行失败会换一台执行,同样执行Datax同步命令也可以通过这种方式实现,可以想象我们把部署了DataX同步工具的机器都注册到xxl-job调度平台,配置好调度策略,任务触发时发送远程shell脚本命令执行同步,如果执行失败则换一台执行。
幸运的是已经有人做了这件事情,基于DataX写了DataX-web工具,其集成并二次开发xxl-job实现了根据时间、自增主键增量同步数据。任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。
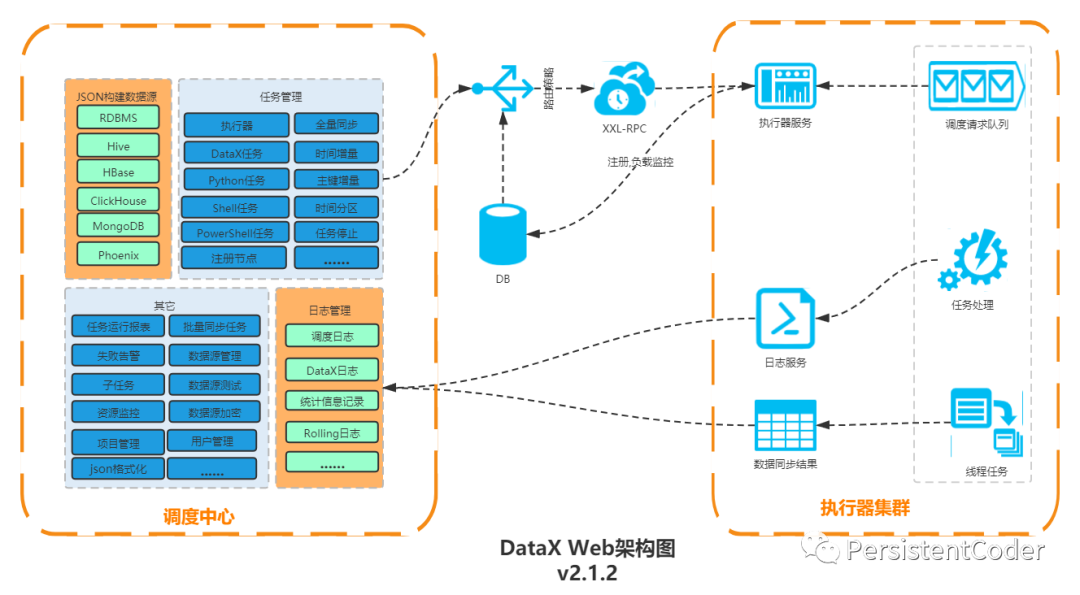
具体详细内容可以参考文档:
https://github.com/WeiYe-Jing/datax-web
参考
https://github.com/alibaba/DataX/blob/master/introduction.md
https://blog.csdn.net/zhuyu19911016520/article/details/124143716
https://github.com/WeiYe-Jing/datax-web
本文分享自 PersistentCoder 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
腾讯云开发者
