进击大数据系列(十四)Hadoop 数据分析引擎 Apache Pig

进击大数据系列(十四)Hadoop 数据分析引擎 Apache Pig

民工哥
发布于 2023-08-22 13:32:57
发布于 2023-08-22 13:32:57
Pig 简介
Pig 是一个基于 Apache Hadoop 的大规模数据分析平台,它提供的 SQL-LIKE 语言叫 Pig Latin,该语言的编译器会把类 SQL 的数据分析请求转换为一系列经过优化处理的 MapReduce 运算。Pig 为复杂的海量数据并行计算提供了一个简单的操作和编程接口,使用者可以透过 Python 或者 JavaScript 编写 Java,之后再重新转写。
Apache Pig 是用Java语言开发的。Pig 的核心组件是由 Java 编写的,这些组件负责将 Pig Latin 脚本转换为 MapReduce 作业,并在 Hadoop 集群上运行这些作业。Pig Latin 语言本身也是由 Java 编写的,并且在 Pig 的执行引擎中被解释和执行。虽然开发人员使用 Pig Latin 来编写数据流查询,但这些查询在底层仍然被转换为Java代码并在 Hadoop 上执行。因此,虽然 Pig Latin 是一个独立的脚本语言,但 Pig 本身是一个基于 Java 的平台。
Apache Pig 优点
- 简化数据处理:Apache Pig 可以将复杂的数据流操作转换为简单的 Pig Latin 脚本,使得数据处理变得更加简单和直观。
- 扩展性:Pig 具有很好的可扩展性,可以轻松地与其他 Hadoop 生态系统中的工具和技术集成。
- 并行处理:Pig 支持在分布式环境中运行,可以利用 Hadoop 集群中的多台计算机来并行处理大规模数据。
- 可重用性:Pig 脚本是可重用的,可以通过简单的修改来适应新的数据集,而不必从头开始编写新的程序。
- 社区支持:Pig 是 Apache 开源项目的一部分,有一个活跃的社区支持和开发。
Apache Pig 缺点
- 学习曲线较陡峭:Pig 语言虽然类似于SQL,但仍需要一定的学习曲线,特别是对于那些没有 Hadoop 经验的开发人员来说。
- 性能问题:Pig 对于一些复杂的查询可能性能较差,并且可能会产生一些不必要的开销,如多余的数据复制、排序等。
- 不支持事务:Pig 不支持 ACID 事务,因此在某些场景下可能不适用。
- 不适用于实时数据:Pig 是一种批处理框架,不适合用于处理实时数据。
Apache Pig与MapReduce
下面列出的是Apache Pig和MapReduce之间的主要区别。
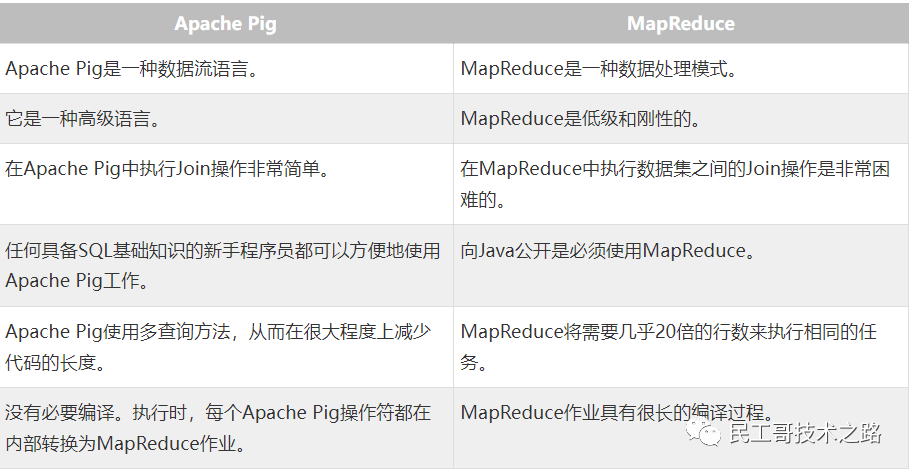
Apache Pig 架构
用于使用Pig分析Hadoop中的数据的语言称为 Pig Latin ,是一种高级数据处理语言,它提供了一组丰富的数据类型和操作符来对数据执行各种操作。
要执行特定任务时,程序员使用Pig,需要用Pig Latin语言编写Pig脚本,并使用任何执行机制(Grunt Shell,UDFs,Embedded)执行它们。执行后,这些脚本将通过应用Pig框架的一系列转换来生成所需的输出。
在内部,Apache Pig将这些脚本转换为一系列MapReduce作业,因此,它使程序员的工作变得容易。Apache Pig的架构如下所示。
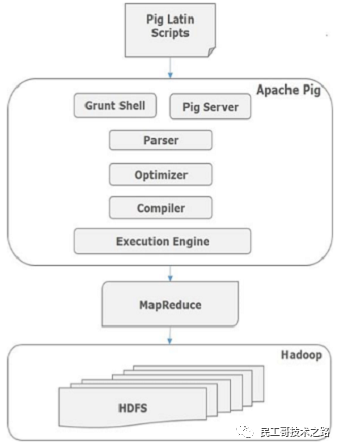
Apache Pig组件
如图所示,Apache Pig框架中有各种组件。让我们来看看主要的组件。
Parser(解析器)
最初,Pig脚本由解析器处理,它检查脚本的语法,类型检查和其他杂项检查。解析器的输出将是DAG(有向无环图),它表示Pig Latin语句和逻辑运算符。在DAG中,脚本的逻辑运算符表示为节点,数据流表示为边。
Optimizer(优化器)
逻辑计划(DAG)传递到逻辑优化器,逻辑优化器执行逻辑优化,例如投影和下推。
Compiler(编译器)
编译器将优化的逻辑计划编译为一系列MapReduce作业。
Execution engine(执行引擎)
最后,MapReduce作业以排序顺序提交到Hadoop。这些MapReduce作业在Hadoop上执行,产生所需的结果。
Pig Latin数据模型
Pig Latin的数据模型是完全嵌套的,它允许复杂的非原子数据类型,例如 map 和 tuple 。下面给出了Pig Latin数据模型的图形表示。

Atom(原子)
Pig Latin中的任何单个值,无论其数据类型,都称为 Atom 。它存储为字符串,可以用作字符串和数字。int,long,float,double,chararray和bytearray是Pig的原子值。一条数据或一个简单的原子值被称为字段。例:“raja“或“30"
Tuple(元组)
由有序字段集合形成的记录称为元组,字段可以是任何类型。元组与RDBMS表中的行类似。例:(Raja,30)
Bag(包)
一个包是一组无序的元组。换句话说,元组(非唯一)的集合被称为包。每个元组可以有任意数量的字段(灵活模式)。包由“{}"表示。它类似于RDBMS中的表,但是与RDBMS中的表不同,不需要每个元组包含相同数量的字段,或者相同位置(列)中的字段具有相同类型。
例:{(Raja,30),(Mohammad,45)}
包可以是关系中的字段;在这种情况下,它被称为内包(inner bag)。
例:{Raja,30, {9848022338,raja@gmail.com,} }
Map(映射)
映射(或数据映射)是一组key-value对。key需要是chararray类型,且应该是唯一的。value可以是任何类型,它由“[]"表示,
例:[name#Raja,age#30]
Relation(关系)
一个关系是一个元组的包。Pig Latin中的关系是无序的(不能保证按任何特定顺序处理元组)。
Apache Pig 安装
先决条件
在你运行Apache Pig之前,必须在系统上安装好Hadoop和Java。
下载Apache Pig
首先,从以下网站下载最新版本的Apache Pig:https://pig.apache.org/
解压
tar -zxvf pig-0.17.0.tar.gz -C ~/training/
配置环境变量
PIG_HOME=/root/training/pig-0.17.0
export PIG_HOME
# 本地模式不需要,但是集群模式需要的变量
PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
export PIG_CLASSPATH
验证安装
通过键入version命令验证Apache Pig的安装。如果安装成功,你将获得Apache Pig的正式版本,如下所示。
$ pig –version
Apache Pig version 0.17.0 (r1682971)
compiled Jun 01 2023, 11:44:35
本地模式
启动
pig -x local
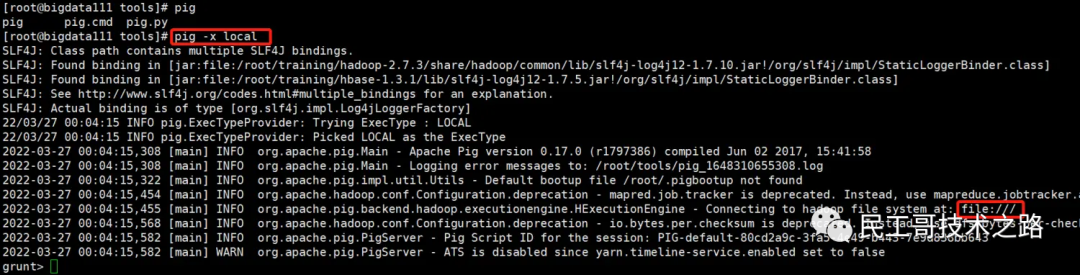
可以看到配置好环境变量之后,在命令行中输入 pig 按 tab 键会自动提示可执行的命令或脚本,以本地模式启动后,可以看到 Pig 连接到的是本地文件系统。
集群模式
集群模式需要先启动 hadoop,再启动 pig
pig
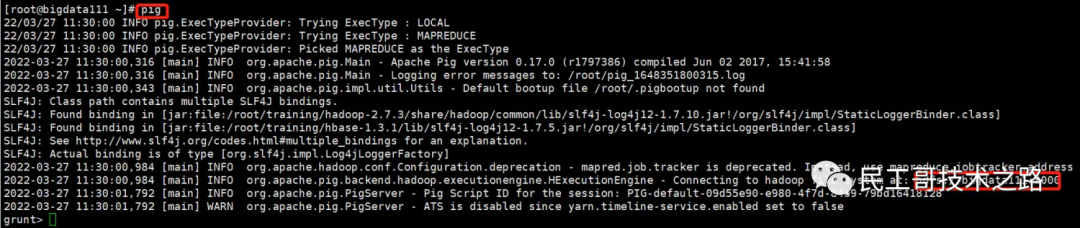
可以看到集群模式启动后,pig 连接到的是 hadoop 文件系统。
Apache Pig执行机制
Apache Pig脚本可以通过三种方式执行,即交互模式,批处理模式和嵌入式模式。
- 交互模式(Grunt shell) - 你可以使用Grunt shell以交互模式运行Apache Pig。在此shell中,你可以输入Pig Latin语句并获取输出(使用Dump运算符)。
- 批处理模式(脚本) - 你可以通过将Pig Latin脚本写入具有 .pig 扩展名的单个文件中,以批处理模式运行Apache Pig。
- 嵌入式模式(UDF) - Apache Pig允许在Java等编程语言中定义我们自己的函数(UDF用户定义函数),并在我们的脚本中使用它们。
Apache Pig Grunt Shell
调用 Grunt shell 后,可以在 shell 中运行 Pig 脚本。除此之外,还有由 Grunt shell 提供的一些有用的 shell 和实用程序命令。本章讲解的是 Grunt shell 提供的 shell 和实用程序命令。
Shell 命令
Apache Pig的Grunt shell主要用于编写Pig Latin脚本。在此之前,我们可以使用 sh 和 fs 来调用任何shell命令。
sh 命令
使用 sh 命令,我们可以从Grunt shell调用任何shell命令,但无法执行作为shell环境( ex - cd)一部分的命令。
- sh 命令的语法。
grunt> sh shell command parameters
- 示例
我们可以使用 sh 选项从Grunt shell中调用Linux shell的 ls 命令,如下所示。在此示例中,它列出了 /pig/bin/ 目录中的文件。
grunt> sh ls
pig
pig_1444799121955.log
pig.cmd
pig.py
fs命令
使用 fs 命令,我们可以从Grunt shell调用任何FsShell命令。
- fs 命令的语法。
grunt> sh File System command parameters
- 示例
我们可以使用fs命令从Grunt shell调用HDFS的ls命令。在以下示例中,它列出了HDFS根目录中的文件。
grunt> fs –ls
Found 3 items
drwxrwxrwx - Hadoop supergroup 0 2015-09-08 14:13 Hbase
drwxr-xr-x - Hadoop supergroup 0 2015-09-09 14:52 seqgen_data
drwxr-xr-x - Hadoop supergroup 0 2015-09-08 11:30 twitter_data
实用程序命令
Grunt shell提供了一组实用程序命令。这些包括诸如clear,help,history,quit和set等实用程序命令;以及Grunt shell中诸如 exec,kill和run等命令来控制Pig。下面给出了Grunt shell提供的实用命令的描述。
clear命令
clear 命令用于清除Grunt shell的屏幕。
你可以使用 clear 命令清除grunt shell的屏幕,如下所示。
grunt> clear
help命令
help 命令提供了Pig命令或Pig属性的列表。
你可以使用 help 命令获取Pig命令列表,如下所示。
grunt> help
Commands: <pig latin statement>; - See the PigLatin manual for details:
http://hadoop.apache.org/pig
File system commands:fs <fs arguments> - Equivalent to Hadoop dfs command:
http://hadoop.apache.org/common/docs/current/hdfs_shell.html
Diagnostic Commands:describe <alias>[::<alias] - Show the schema for the alias.
Inner aliases can be described as A::B.
explain [-script <pigscript>] [-out <path>] [-brief] [-dot|-xml]
[-param <param_name>=<pCram_value>]
[-param_file <file_name>] [<alias>] -
Show the execution plan to compute the alias or for entire script.
-script - Explain the entire script.
-out - Store the output into directory rather than print to stdout.
-brief - Don't expand nested plans (presenting a smaller graph for overview).
-dot - Generate the output in .dot format. Default is text format.
-xml - Generate the output in .xml format. Default is text format.
-param <param_name - See parameter substitution for details.
-param_file <file_name> - See parameter substitution for details.
alias - Alias to explain.
dump <alias> - Compute the alias and writes the results to stdout.
Utility Commands: exec [-param <param_name>=param_value] [-param_file <file_name>] <script> -
Execute the script with access to grunt environment including aliases.
-param <param_name - See parameter substitution for details.
-param_file <file_name> - See parameter substitution for details.
script - Script to be executed.
run [-param <param_name>=param_value] [-param_file <file_name>] <script> -
Execute the script with access to grunt environment.
-param <param_name - See parameter substitution for details.
-param_file <file_name> - See parameter substitution for details.
script - Script to be executed.
sh <shell command> - Invoke a shell command.
kill <job_id> - Kill the hadoop job specified by the hadoop job id.
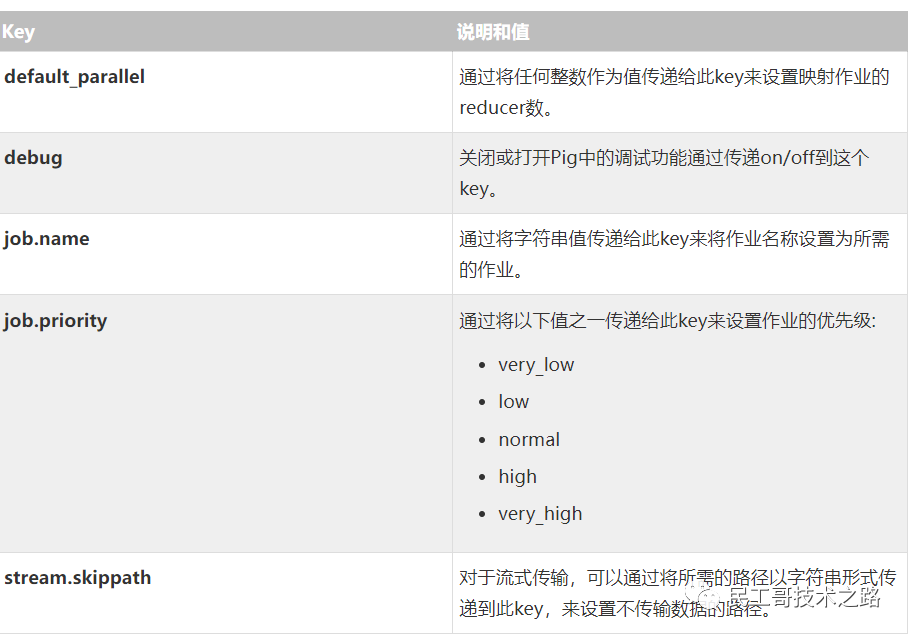
set <key> <value> - Provide execution parameters to Pig. Keys and values are case sensitive.
The following keys are supported:
default_parallel - Script-level reduce parallelism. Basic input size heuristics used
by default.
debug - Set debug on or off. Default is off.
job.name - Single-quoted name for jobs. Default is PigLatin:<script name>
job.priority - Priority for jobs. Values: very_low, low, normal, high, very_high.
Default is normal stream.skippath - String that contains the path.
This is used by streaming any hadoop property.
help - Display this message.
history [-n] - Display the list statements in cache.
-n Hide line numbers.
quit - Quit the grunt shell.
history命令
此命令显示自Grunt shell被调用以来执行/使用的语句的列表。
假设我们自打开Grunt shell之后执行了三个语句。
grunt> customers = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',');
grunt> orders = LOAD 'hdfs://localhost:9000/pig_data/orders.txt' USING PigStorage(',');
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',');
然后,使用 history 命令将产生以下输出。
grunt> history
customers = LOAD 'hdfs://localhost:9000/pig_data/customers.txt' USING PigStorage(',');
orders = LOAD 'hdfs://localhost:9000/pig_data/orders.txt' USING PigStorage(',');
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',');
set命令
set 命令用于向Pig中使用的key显示/分配值。
使用此命令,可以将值设置到以下key。
quit命令
你可以使用此命令从Grunt shell退出。
从Grunt shell中退出,如下所示。
grunt> quit
现在让我们看看从Grunt shell控制Apache Pig的命令。
exec命令
使用 exec 命令,我们可以从Grunt shell执行Pig脚本。
- exec 的语法。
grunt> exec [–param param_name = param_value] [–param_file file_name] [script]
- 示例
我们假设在HDFS的 /pig_data/ 目录中有一个名为 student.txt 的文件,其中包含以下内容。
Student.txt
001,Rajiv,Hyderabad
002,siddarth,Kolkata
003,Rajesh,Delhi
并且,假设我们在HDFS的 /pig_data/ 目录中有一个名为 sample_script.pig 的脚本文件,并具有以下内容。
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING PigStorage(',')
as (id:int,name:chararray,city:chararray);
Dump student;
现在,让我们使用 exec 命令从Grunt shell中执行上面的脚本,如下所示。
grunt> exec /sample_script.pig
- 输出
exec 命令执行 sample_script.pig 中的脚本。按照脚本中的指示,它会将 student.txt 文件加载到Pig中,并显示Dump操作符的结果,显示以下内容。
(1,Rajiv,Hyderabad)
(2,siddarth,Kolkata)
(3,Rajesh,Delhi)
kill命令
你可以使用此命令从Grunt shell中终止一个作业。
- kill 命令的语法。
grunt> kill JobId
- 示例
假设有一个具有id Id_0055 的正在运行的Pig作业,使用 kill 命令从Grunt shell中终止它,如下所示。
grunt> kill Id_0055
run命令
你可以使用run命令从Grunt shell运行Pig脚本
- run 命令的语法。
grunt> run [–param param_name = param_value] [–param_file file_name] script
- 示例
假设在HDFS的 /pig_data/ 目录中有一个名为 student.txt 的文件,其中包含以下内容。
Student.txt
001,Rajiv,Hyderabad
002,siddarth,Kolkata
003,Rajesh,Delhi
并且,假设我们在本地文件系统中有一个名为 sample_script.pig 的脚本文件,并具有以下内容。
Sample_script.pig
student = LOAD 'hdfs://localhost:9000/pig_data/student.txt' USING
PigStorage(',') as (id:int,name:chararray,city:chararray);
现在,让我们使用run命令从Grunt shell运行上面的脚本,如下所示。
grunt> run /sample_script.pig
你可以使用Dump操作符查看脚本的输出,如下所示。
grunt> Dump;
(1,Rajiv,Hyderabad)
(2,siddarth,Kolkata)
(3,Rajesh,Delhi)
Pig 数据模型
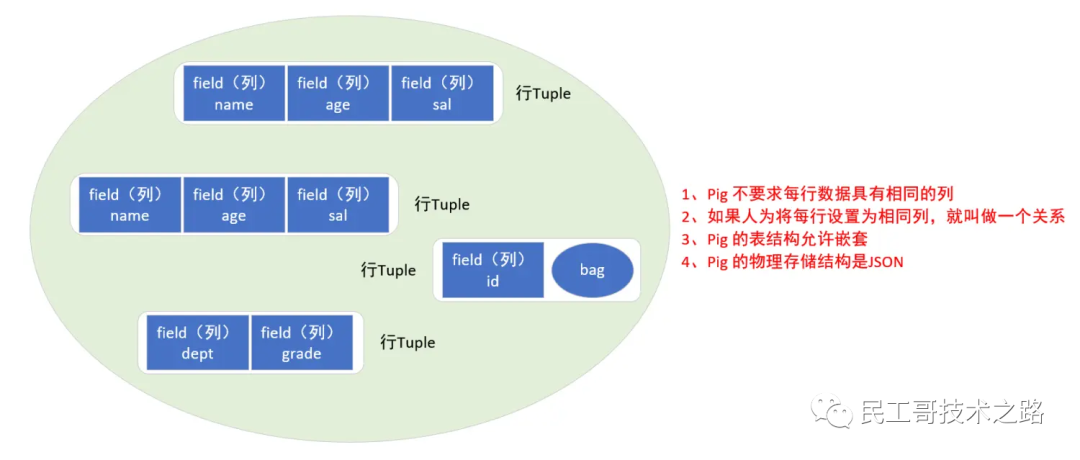
pig 的表不是矩形的(即每一行都有相同的列),pig 的表被称为包(bag),包中存在行(Tuple)准确地说叫元组,每个元组中存在多个列,表允许不同的元组有完全不相同的列。
列可以是基本类型int,long,float,double,chararray(string:注意以单引号),bytearray(byte[]),也可以嵌套 map,type,bag 等复杂类型。
如果人为把每一行都设置成具有相同的列,则叫做一个关系;Pig 的物理存储结构是 JSON 格式。
Pig Latin 语句
在使用Pig Latin处理数据时,语句是基本结构。
- 这些语句使用关系(relation),它们包括表达式(expression)和模式(schema)。
- 每个语句以分号(;)结尾。
- 我们将使用Pig Latin提供的运算符通过语句执行各种操作。
- 除了LOAD和STORE,在执行所有其他操作时,Pig Latin语句采用关系作为输入,并产生另一个关系作为输出。
- 只要在Grunt shell中输入 Load 语句,就会执行语义检查。要查看模式的内容,需要使用 Dump 运算符。只有在执行 dump 操作后,才会执行将数据加载到文件系统的MapReduce作业。
Pig Latin语法介绍
下面,将通过与Mysql对比,介绍Pig Latin的常用语法。
导入文件数据
- Mysql
create table tmp_table(name varchar(32), age int, is_child boolean);
create table tmp_table2(age int, user varchar(50), is_child boolean);
load data local infile'/tmp/data_file1' into table tmp_table;
load data local infile'/tmp/data_file2' into table tmp_table2;
- Pig
tmp_table = load'/tmp/data_file1' using PigStorage('\t') as(name:chararray, age:int, is_child:int);
tmp_table2 = load'/tmp/data_file2' using PigStorage('\t') as(age:int, user:chararray, is_child:int);
查询固定行数据
- Mysql
select * from tmp_table limit 50;
- Pig
tmp_table_limit = limit tmp_table 50;
dump tmp_table_limit;
查询指定列数据
- Mysql
select name from tmp_table;
- Pig
tmp_table_name = foreach tmp_table generate name;
dump tmp_table_name;
给列取别名
- Mysql
select name as username, age as userage from tmp_table;
- Pig
tmp_table_column_alias = foreach tmp_table generate name as username, age as userage;
dump tmp_table_column_alias;
按某列排序
- Mysql
select * from tmp_table order by age;
- Pig
tmp_table_order = order tmp_table by age asc;
dump tmp_table_order;
条件查询
- Mysql
select * from tmp_table where age > 18;
- Pig
tmp_table_where = filter tmp_table by age > 18;
dump tmp_table_where;
内连接inner join
- Mysql
select * from tmp_table A join tmp_table2 B on A.age = B.age;
- Pig
tmp_table_inner_join = join tmp_table by age, tmp_table2 by age;
dump tmp_table_inner_join;
左连接left join
- Mysql
select * from tmp_table A left join tmp_table2 B on A.age = B.age;
- Pig
tmp_table_left_join = join tmp_table by age left outer, tmp_table2 by age;
dump tmp_table_left_join;
右链接right join
- Mysql
select * from tmp_table A right join tmp_table2 B on A.age = B.age;
- Pig
tmp_table_right_join = join tmp_table by age right outer,tmp_table2 by age;
dump tmp_table_right_join;
全连接full join
- Mysql
select * from tmp_table A join tmp_table2 B on A.age = B.age Union select * from tmp_table A left join tmp_table2 B on A.age = B.age;
- Pig
tmp_table_full_join = join tmp_table by age full outer,tmp_table2 by age;
dump tmp_table_full_join;
交叉查询多张表
- Mysql
select * from tmp_table,tmp_table2;
- Pig
tmp_table_cross = cross tmp_table,tmp_table2;
dump tmp_table_cross ;
分组group by
- Mysql
select * from tmp_table group by is_child;
- Pig
tmp_table_group = group tmp_table by is_child;
dump tmp_table_group;
分组并统计
- Mysql
select is_male, count(*) from tmp_table group by is_child;
- Pig
tmp_table_group_count = group tmp_table by is_child;
tmp_table_group_count = foreach tmp_table_group_count generate group,count($1);
dump tmp_table_group_count;
查询去重
- Mysql
select distinct is_child from tmp_table;
- Pig
tmp_table_distinct = foreach tmp_table generate is_child;
tmp_table_distinct = distinct tmp_table_distinct;
dump tmp_table_distinct;
参考文章:https://www.w3cschool.cn/apache_pig/apache_pig _architecture.html https://jianshu.com/p/b54ff6ec1b99
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号