谈JVM线程和内存参数合理性设置


Tech
/导读/
JVM启动参数中很多与线程、内存相关。在生产实践中,对这些参数随意设置或者采用默认值可能会有一些风险,特别是在JDK低版本的容器下,可能出现容器CPU过高,GC频繁等。文章列出了这些参数设置方法,并给出常用容器规格的推荐设置。
01
线程参数
在今年的敏捷团队建设中,我通过Suite执行器实现了一键自动化单元测试。Juint除了Suite执行器还有哪些执行器呢?由此我的Runner探索之旅开始了!
1.1 ParallelGCThreads
在讲这个参数之前,先谈谈JVM垃圾回收(GC)算法的两个优化标的:吞吐量和停顿时长。JVM会使用特定的GC收集线程,当GC开始的时候,GC线程会和业务线程抢占CPU时间,吞吐量定义为CPU用于业务线程的时间与CPU总消耗时间的比值。为了承接更大的流量,吞吐量越大越好。
为了安全的垃圾回收,在GC或者GC某个阶段,所有业务线程都会被暂停,也就是STW(Stop The World),STW持续时间就是停顿时长,停顿时长影响响应速度,因此越小越好。
这两个优化目标是有冲突的,不同的GC方法优化标的有所不同,并且在一定范围内,参与GC的线程数越多,停顿时长越小,但吞吐量也越小。生产实践中,需要根据业务特点选择合适的GC方法,并设置合理的GC线程数。
目前广泛使用的GC算法,包括PS MarkSweep/PS Scavenge, ConcurrentMarkSweep/ParNew, G1等,都可以通过ParallelGCThreads参数来指定JVM在并行GC时参与垃圾收集的线程数。该值设置过小,GC暂停时间变长影响RT,设置过大则影响吞吐量,从而导致CPU过高。
1. 参数设置
GC并发线程数可以通过JVM启动参数: -XX:ParallelGCThreads=[n]来指定。在未明确指定的情况下,JVM会根据逻辑核数ncpus,采用以下公式来计算默认值:
- 当ncpus小于8时,ParallelGCThreads = ncpus
- 否则 ParallelGCThreads = 8 + (ncpus - 8 ) ( 5/8 )
一般来说,在无特殊要求下,ParallelGCThreads参数使用默认值就可以了。但是在JDK版本1.8.0_131之前,JVM无法感知Docker的CPU限制,会使用宿主机的逻辑核数计算默认值。比如部署在128核物理机上的容器,JVM中默认ParallelGCThreads为83,远超过了容器的核数。过多的GC线程数抢占了业务线程的CPU时间,加上线程切换的开销,较大的降低了吞吐量。因此JDK 1.8.0_131之前的版本,未明确指定ParallelGCThreads会有较大的风险。
2. 参数实验
创建 8C12G 容器,宿主机是128C。模拟线上真实流量,采用相同QPS,观察及对比JVM Young GC,JVM CPU,容器CPU等监控数据。场景如下:
- 场景1: JVM ParallelGCThreads 默认值,QPS = 420,持续5分钟,CPU恒定在70%
- 场景2: JVM ParallelGCThreads=8,QPS = 420,持续5分钟,CPU恒定在65%
- 场景3: JVM ParallelGCThreads 默认值,QPS瞬时发压到420,前1min CPU持续100%
- 场景4: JVM ParallelGCThreads=8,QPS瞬时发压到420,前2s CPU持续100%,后面回落
从监控数据来看,各场景下CPU差距较明显,特别是场景3和场景4的对比。场景3由于GC线程过多,CPU持续100%时长达1分钟。可以得出以下两个结论:
- 修改 ParallelGCThreads = 8后,同等QPS情况下,CPU会降低5%左右
- 修改 ParallelGCThreads = 8后,瞬间发压且CPU打满情况下,CPU恢复较快
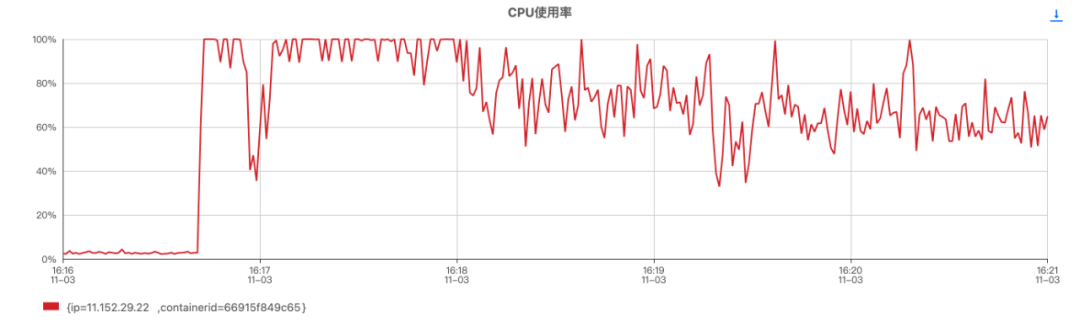
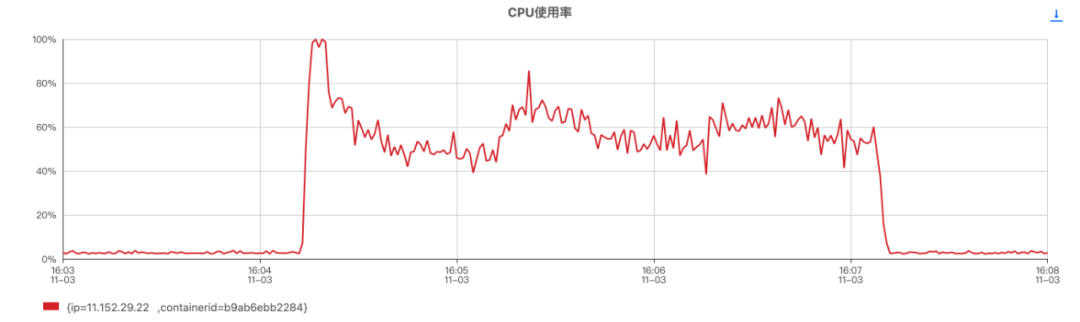
图1.容器CPU对比图:场景3(上)和场景4(下)
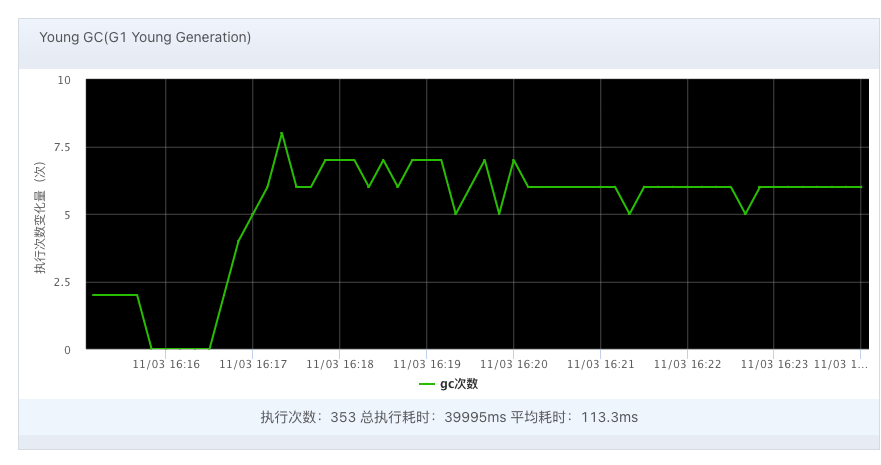
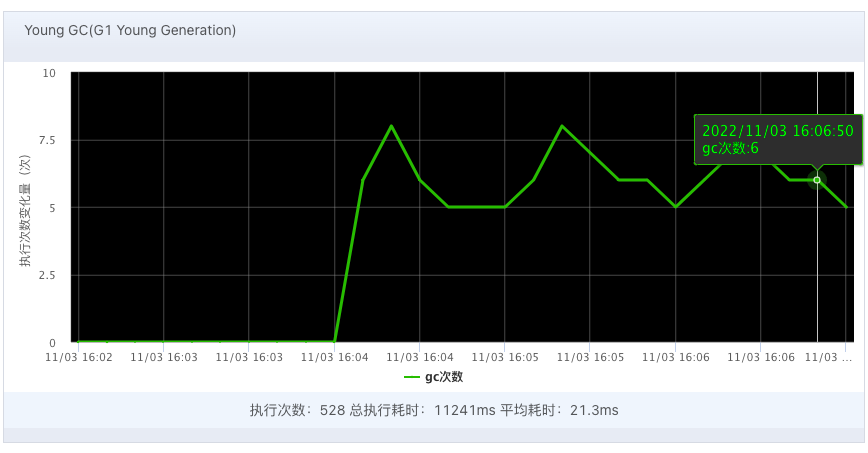
图2.JVM Young GC对比图:场景3(上)和场景4(下)
3. 修改建议
ParallelGCThreads配置存在风险的应用,修改方式为以下两种方案(任选一种):
- 升级JDK版本到1.8.0_131以上,推荐1.8.0_191以上
- 在JVM启动参数明确指定 -XX:ParallelGCThreads=[n],n为下表的推荐值: 容器核数248163264推荐值248132343建议上下界1~22~44~88~1616~3232~64
1.2 其他线程参数
除ParallelGCThreads外,还有两个和线程相关参数比较重要:ConcGCThreads,CICompilerCount。
ConcGCThreads一般称为并发标记线程数,为了减少GC的STW的时间,CMS和G1都有并发标记的过程,此时业务线程仍在工作,只是并发标记是CPU密集型任务,业务的吞吐量会下降,RT会变长。
ConcGCThreads的默认值不同GC策略略有不同,CMS下是(ParallelGCThreads + 3) / 4 向下取整,G1下是ParallelGCThreads / 4 四舍五入。一般来说采用默认值就可以了,但还是由于在JDK版本1.8.0_131之前,JVM无法感知Docker的资源限制的问题,ConcGCThreads的默认值会比较大(20左右),对业务会有影响。
CICompilerCount是JIT进行热点编译的线程数,和并发标记线程数一样,热点编译也是CPU密集型任务,默认值为2。在CICompilerCountPerCPU开启的时候(JDK7默认关闭,JDK8默认开启),手动指定CICompilerCount是不会生效的,JVM会使用系统CPU核数进行计算。所以当使用JDK8并且版本小于1.8.0_131,采用默认参数时,CICompilerCount会在20左右,对业务性能影响较大,特别是启动阶段。建议升级Java版本,特殊情况要使用老版本Java 8,请加上-XX:CICompilerCount=[n], 同时不能指定-XX:+CICompilerCountPerCPU ,下表给出了生产环境下常见规格的推荐值。
容器核数 | 1 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|---|
CICompilerCount手动指定推荐值 | 2 | 2 | 3 | 3 | 8 |
02
内存参数
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕
前面说到JVM垃圾回收算法的两个优化标的:吞吐量和停顿时长,并提到这两个优化目标是有冲突的。那么有没有可能提高吞吐量而不影响停顿时长,甚至缩短停顿时长呢?答案是有可能的,提高内存占用(Memory Footprint)就有可能同时优化这两个标的。
内存占用一般指应用运行需要的所有内存,包括堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)。
2.1 堆内内存
堆内内存是分配给JVM的部分内存,用来存放所有Java Class对象实例和数组,JVM GC操作的就是这部分内容。我们先来回顾一下堆内内存的模型:
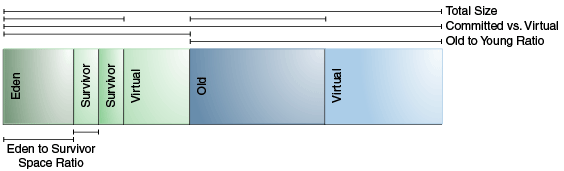
图3.堆内内存
堆内内存包括年轻代(浅绿色),老年代(浅蓝色),在JDK7或者更老的版本,图中右边还有个永久代(永久代在逻辑上位于JVM的堆区,但又被称为非堆内存,在JDK8中被元空间取代)。JVM有动态调整内存策略,通过-Xms,-Xmx 指定堆内内存动态调整的上下限。在JVM初始化时实际只分配部分内存,可通过-XX:InitialHeapSize指定初始堆内存大小,未被分配的空间为图中virtual部分。年轻代和老年代在每次GC的时候都有可能调整大小,以保证存活对象占用百分比在特定阈值范围内,直到达到Xms指定的下限或Xms指定的上限。(阈值范围通过-XX:MinHeapFreeRatio, XX:MaxHeapFreeRatio指定,默认值分别为40, 70)。
GC调优中还有个的重要参数是老年代和年轻代的比例,通过-XX:NewRatio设定,与此相关的还有-XX:MaxNewSize和-XX:NewSize,分别设定年轻代大小的上下限,-Xmn则直接指定年轻代的大小。
1.参数默认值
-Xmx: Xmx的默认值比较复杂,官方文档上有时候写的是1GB,但实际值跟JDK版本、JVM 模式(client, server)和系统(平台类型,32位,64位)等都有关。经过查阅源码和实验,确定在生产环境下(server模式,64位Centos,JDK 8),Xmx的默认值可以采用以下规则计算:
- 容器内存小于等于2G:默认值为容器内存的1/2,最小16MB, 最大512MB。
- 容器内存大于2G:默认值为容器内存的1/4, 最大可到达32G。 -Xms: 默认值为容器内存的1/64, 最小8MB,如果明确指定了Xmx并且小于容器内存1/64, Xms默认值为Xmx指定的值。
3)-NewRatio: 默认2,即年轻代和年老代的比例为1:2, 年轻代大小为堆内内存的1/3。
补充说明:在JDK版本1.8.0_131之前,JVM无法感知Docker的资源限制,Xmx, Xms未明确指定时,会使用宿主机的内存计算默认值。
2.最佳实践
由于每次Eden区满就会触发YGC,而每次YGC的时候,晋升到老年代的对象大小超过老年代剩余空间的时候,就会触发FGC。所以基本来说,GC频率和堆内内存大小是成反比的,也就是说堆内内存越大,吞吐量越大。
如果Xmx设置过小,不仅浪费了容器资源,在大流量下会频繁GC,导致一系列问题,包括吞吐量降低,响应变长,CPU升高,java.lang.OutOfMemoryError异常等。当然Xmx也不建议设置过大,否则会导致内存分配失败或者使用容器Swap。所以合理设置Xmx非常重要,特别是对于1.8.0_131之前的版本,一定要明确指定Xmx。推荐设置为容器内存的50%,不能超过容器内存的80%。
JVM的动态内存策略不太适合服务使用,因为每次GC需要计算Heap是否需要伸缩,内存抖动需要向系统申请或释放内存,特别是在服务重启的预热阶段,内存抖动会比较频繁。另外,容器中如果有其他进程还在消费内存,JVM内存抖动时可能申请内存失败,导致OOM。因此建议服务模式下,将Xms设置Xmx一样的值。
NewRatio建议在2~3之间,最优选择取决于对象的生命周期分布。一般先确定老年代的空间(足够放下所有live data,并适当增加10%~20%),其余是年轻代,年轻代大小一定要小于老年代。
另外,以上建议都是基于一个容器部署一个JVM实例的使用情况。有个别需求,需要在一个容器内启用多个JVM,或者包含其他语言的,研发需要按业务需求在推荐值范围内分配JVM的Xmx。
2.2 堆外内存
和堆内内存对应的就是堆外内存。堆外内存包括很多部分,比如Code Cache, Memory Pool,Stack Memory,Direct Byte Buffers, Metaspace等等,其中我们需要重点关注的是Direct Byte Buffers和Metaspace。
1.Direct Byte Buffers
Metaspace Direct Byte Buffers是系统原生内存,不位于JVM里,狭义上的堆外内存就是指的Direct Byte Buffers。为什么要使用系统原生内存呢? 为了更高效的进行Socket I/O或文件读写等内核态资源操作,会使用JNI(Java原生接口),此时操作的内存需要是连续和确定的。而Heap中的内存不能保证连续,且GC也可能导致对象随时移动。因此涉及Output操作时,不直接使用Heap上的数据,需要先从Heap上拷贝到原生内存,Input操作则相反。因此为了避免多余的拷贝,提高I/O效率,不少第三方包和框架使用Direct Byte Buffers,如Netty。
Direct Byte Buffers虽然有上述优点,但使用起来也有一定风险。常见的Direct Byte Buffers使用方法是用java.nio.DirectByteBuffer的unsafe.allocateMemory方法来创建,DirectByteBuffer对象只保存了系统分配的原生内存的大小和启始位置,这些原生内存的释放需要等到DirectByteBuffer对象被回收。有些特殊的情况下(比如JVM一直没有FGC,设置-XX:+DisableExplicitGC禁用了System.gc),这部分对象会持续增加,直到堆外内存达到-XX:MaxDirectMemorySize 指定的大小或者耗尽所有的系统内存。
MaxDirectMemorySize不明确指定的时候,默认值为0,在代码中实际为Runtime.getRuntime().maxMemory(),略小于-Xmx指定的值(堆内内存的最大值减去一个Survivor区大小)。此默认值有点过大,MaxDirectMemorySize未设置或设置过大,有可能发生堆外内存泄露,导致进程被系统Kill。
由于存在一定风险,建议在启动参数里明确指定-XX:MaxDirectMemorySize的值,并满足下面规则:
- Xmx * 110% + MaxDirectMemorySize + 系统预留内存 <= 容器内存
- Xmx * 110% 中额外的10%是留给其他堆外内存的,是个保守估计,个别业务运行时线程较多,需自行判断,上式中左侧还需加上Xss * 线程数
- 系统预留内存512M到1G,视容器规格而定
- I/O较多的业务适当提高MaxDirectMemorySize比例
2.Metaspace
Metaspace(元空间)是JDK8关于方法区新的实现,取代之前的永久代,用来保存类、方法、数据结构等运行时信息和元信息的。很多研发在老版本时可能遇到过java.lang.OutOfMemoryError: PermGen Space,这说明永久代的空间不够用了,可以通过-XX:PermSize,-XX:MaxPermSize来指定永久代的初始大小和最大大小。Metaspace取代永久代,位置由JVM内存变成系统原生内存,也取消默认的最大空间限制。与此有关的参数主要有下面两个:
- -XX:MaxMetaspaceSize 指定元空间的最大空间,默认为容器剩余的所有空间
- -XX:MetaspaceSize 指定元空间首次扩充的大小,默认为20.8M
由于MaxMetaspaceSize未指定时,默认无上限,所以需要特别关注内存泄露的问题,如果程序动态的创建了很多类,建议明确指定-XX:MaxMetaspaceSize。另外Metaspace实际分配的大小是随着需要逐步扩大的,每次扩大需要一次FGC,-XX:MetaspaceSize默认的值比较小,需要频繁GC扩充到需要的大小。通过下面的日志可以看到Metaspace引起的FGC:
[Full GC (Metadata GC Threshold) ...]
为减少预热影响,可以将-XX:MetaspaceSize,-XX:MaxMetaspaceSize指定成相同的值。另外不少应用由JDK7升级到了JDK8,但是启动参数中仍有-XX:PermSize,-XX:MaxPermSize,这些参数是不生效的,建议修改成-XX:MetaspaceSize,-XX:MaxMetaspaceSize。
03
配置建议
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。从设计稿出发,提升页面搭建效率,亟需解决的核心问题有:
1. 建议升级JDK版本到1.8.0_191及以上;
2. 启动参数中包含以下几项(方括号中的值根据文中推荐选取):
-server -Xms[8192m] -Xmx[8192m] -XX:MaxDirectMemorySize=[409如果特殊原因要使用1.8.0_131以下版本, 则同时需要加上以下参数(方括号中的值根据文中推荐选取):
-XX:ParallelGCThreads=[8] -XX:ConcGCThreads=[2] -XX:CICompilerCount=[2]下面的项建议测试后使用,需自行确定具体大小,建议不小于256m(特别是使用JDK8但仍配置-XX:PermSize,-XX:MaxPermSize的应用):
-XX:MaxMetaspaceSize=256m -XX:MetaspaceSize=256m另外,为了更好排查堆内存相关问题,建议开启OOM堆文件导出,-XX:+HeapDumpOnOutOfMemoryError,这样每次发生OOM时会导出相关堆信息到文件。文件保存位置通过-XX:HeapDumpPath=<path>指定,path可以是文件也可以是目录。
环境变量设置如下例子:
export JAVA_OPTS="-Djava.library.path=/usr/local/lib -server -Xms4096m -Xmx4096m -XX:MaxMetaspaceSize=512m -XX:MetaspaceSize=512m -XX:MaxDirectMemorySize=2048m -XX:ParallelGCThreads=8 -XX:ConcGCThreads=2 -XX:CICompilerCount=2 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/export/Logs -XX:+UseG1GC [other_options...] -jar jarfile [args...]04
结束语
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将目标页面展示到屏幕。
以上给出的仅是推荐值,由于各系统的业务特征差异,最佳配置还需要针对性的调整。另外调整后需要进行压测,根据监控查看各种资源使用率和接口性能情况,确定有改进才能上线。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号