【愚公系列】2023年12月 五大常用算法(一)-分治算法
原创
🏆 作者简介,愚公搬代码 🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,阿里云专家博主,腾讯云优秀博主,掘金优秀博主,51CTO博客专家等。 🏆《近期荣誉》:2022年CSDN博客之星TOP2,2022年华为云十佳博主等。 🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。 🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
五大常用算法的特点如下:
- 分治:将一个大问题拆分成若干个小问题,分别解决,然后将解决结果合并起来得到整个问题的解。分治算法的特点是递归,效率高,但对数据的规律要求比较高,需要较高的算法设计技巧。常见应用领域为排序、查找和统计等。
- 动态规划:将一个大问题分解成若干个小问题,通过寻找子问题之间的递推关系,求解小问题的最优解,然后将小问题的最优解组合起来解决整个大问题。动态规划的特点是可以解决具有重叠子问题的问题,但需要较高的时间和空间复杂度。常见应用领域为求解最大子序列、背包问题等。
- 贪心:在处理问题的过程中,每次做出局部最优的选择,希望通过局部最优的选择达到全局最优。贪心算法的特点是快速、简单,但是无法保证每个局部最优解会导致全局最优解。常见应用领域为最小生成树、活动安排等。
- 回溯:通过不断尝试局部的解,如果不满足要求就回溯返回,直到找到解为止。回溯算法的特点是可以解决多种类型的问题,但需要搜索所有可能的解,时间复杂度较高。常见应用领域为八皇后问题、排列组合问题等。
- 分支限界:与回溯算法相似,但是在搜索的过程中,通过剪枝操作来减少搜索的空间,提高算法效率。常见应用领域为旅行商问题、图着色问题等。
🚀一、分治算法
🔎1.基本思想
分治算法的基本思想是将一个大问题分解成若干个子问题,递归地解决每个子问题,然后将每个子问题的解合并起来得出整个问题的解。分治算法的基本步骤为:
- 分解问题:将原问题分解成若干个子问题,这些子问题应该是相互独立的。
- 解决子问题:递归地解决每个子问题,直到子问题可以直接求解为止。子问题的求解顺序不影响最终结果。
- 合并问题:将每个子问题的解合并起来,得出整个问题的解。
分治算法主要适用于具有重复性的问题,且子问题之间相互独立。常见的分治算法包括归并排序、快速排序、二分查找、最大子数组问题等。
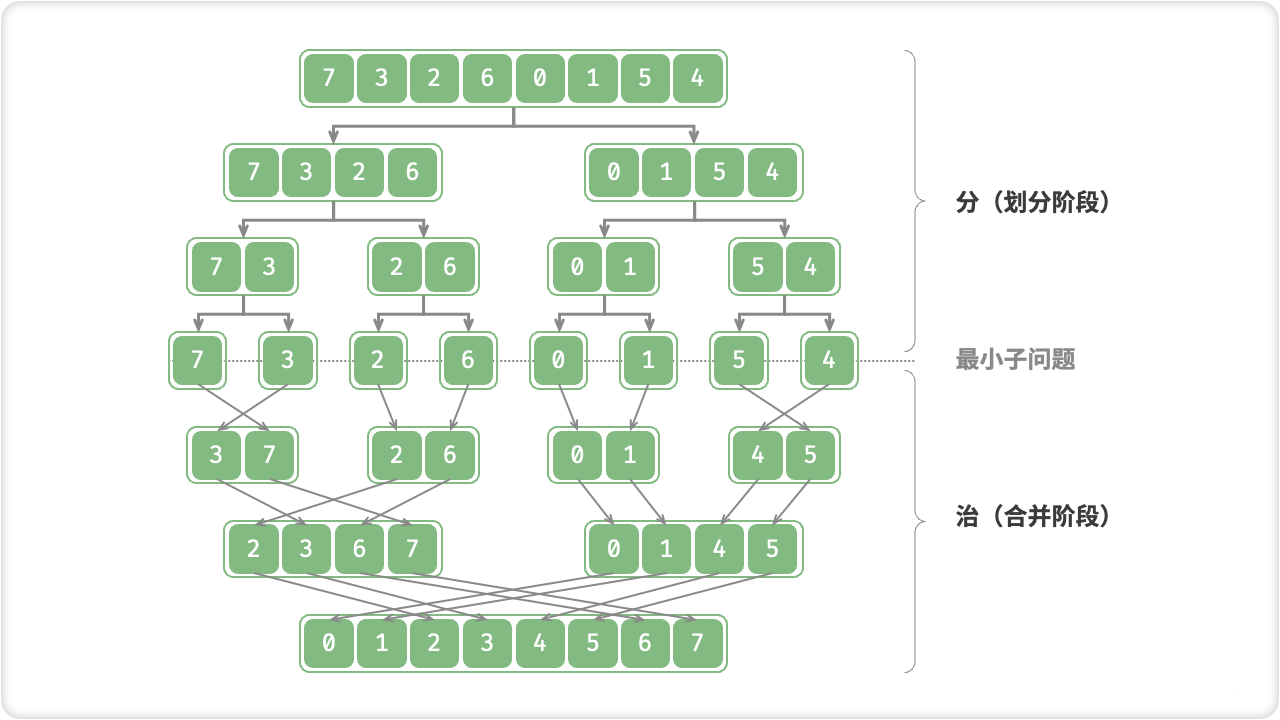
🦋1.1 分治问题特征
分治问题通常具有以下特征:
- 问题可分解为若干个子问题,且子问题与原问题类型相同或类似。
- 子问题之间相互独立,即解决一个子问题不影响其他子问题的解决。
- 子问题的解可以合并为原问题的解。
- 子问题规模能够逐步缩小,最终达到较小规模,可以使用直接求解的方法。
如果一个问题具备以上特征,那么就可以考虑采用分治算法来解决这个问题。
🦋1.2 通过分治提升效率
分治是一种常见的算法设计思想,它将一个大问题划分成多个小问题,递归地解决每个小问题,最终将它们合并成一个解。通过分治思想设计的算法能够提升效率,原因如下:
- 减少问题规模:将一个大问题分解成多个小问题,可以减少每个小问题的复杂度,进而降低算法的时间复杂度和空间复杂度。
- 利用并行处理:分治算法天然适合并行处理,可以将一个大问题划分给多个处理器,同时解决多个小问题,最终合并得到结果。这样可以节省计算时间,提高算法效率。
- 利用缓存:通过分治算法设计的算法可以有效地利用缓存。对于大问题,每次递归的过程中需要重复计算很多数据,如果能够将这些数据缓存下来,在后续递归的过程中直接使用,就可以减少重复计算,提高算法效率。
- 便于调试和维护:分治算法将大问题拆分为多个小问题,每个小问题都很清晰明了。这样便于调试和维护,可以快速定位问题并修改。
通过分治算法设计的算法能够有效地提升效率,减少时间复杂度和空间复杂度,利用并行处理和缓存等技术,适用于处理复杂的大问题。
☀️1.2.1 操作数量优化
分治算法是一种将问题划分为多个子问题,并将子问题递归地解决,最终将子问题的解合并成原问题解的算法。在操作数量优化方面,分治算法可以提高算法的效率。
首先,分治算法可以将一个大问题划分为多个小问题,从而减少每个子问题的规模。当问题的规模变小后,算法的复杂度也会降低。
其次,分治算法可以充分利用计算机的多核处理能力。由于每个子问题的解可以独立地计算,因此可以将不同的子问题分配给不同的处理器同时计算,从而加快算法的速度。
最后,分治算法还可以使用递归算法进行优化。由于分治算法本身就是递归地解决子问题,因此可以利用递归算法的特性来简化代码,使代码更加清晰易懂,并且可以降低算法的复杂度。
分治算法在操作数量优化方面具有明显的优势,可以提高算法的效率,减少计算时间和资源开销。
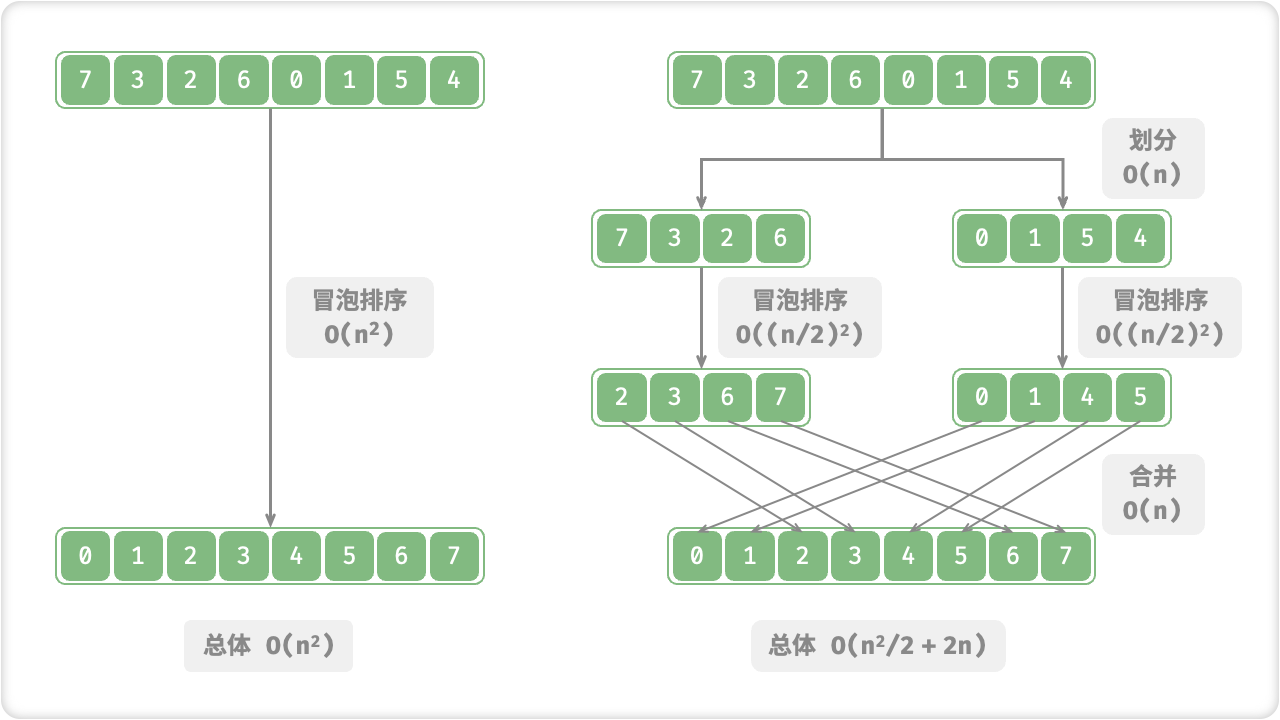
☀️1.2.2 并行计算优化
分治算法通常可以在并行计算中得到优化。由于分治算法的特点是将问题划分为更小的子问题,并且这些子问题是相互独立的,因此可以将这些子问题分配给不同的处理器或线程进行并行计算。这样可以有效地提高计算效率,缩短计算时间。
在并行计算中,有许多并行编程模型可以用来实现分治算法的并行化。例如,OpenMP和MPI都是常用的并行编程模型,可以用来实现并行分治算法。在这些模型中,可以使用一些技术来实现负载平衡、数据通信和同步等问题,以确保并行计算的正确性和效率。
此外,还有许多优化技术可以用于提高并行分治算法的效率。例如,可以使用内存池和缓存等技术来减少内存分配和访问的开销,从而提高算法的处理速度。还可以使用预取技术来减少计算时的等待时间,以及使用分支预测技术来优化递归算法的执行效率。
分治算法在并行计算中具有很好的优化潜力,可以通过多种技术来提高并行计算的效率和速度。
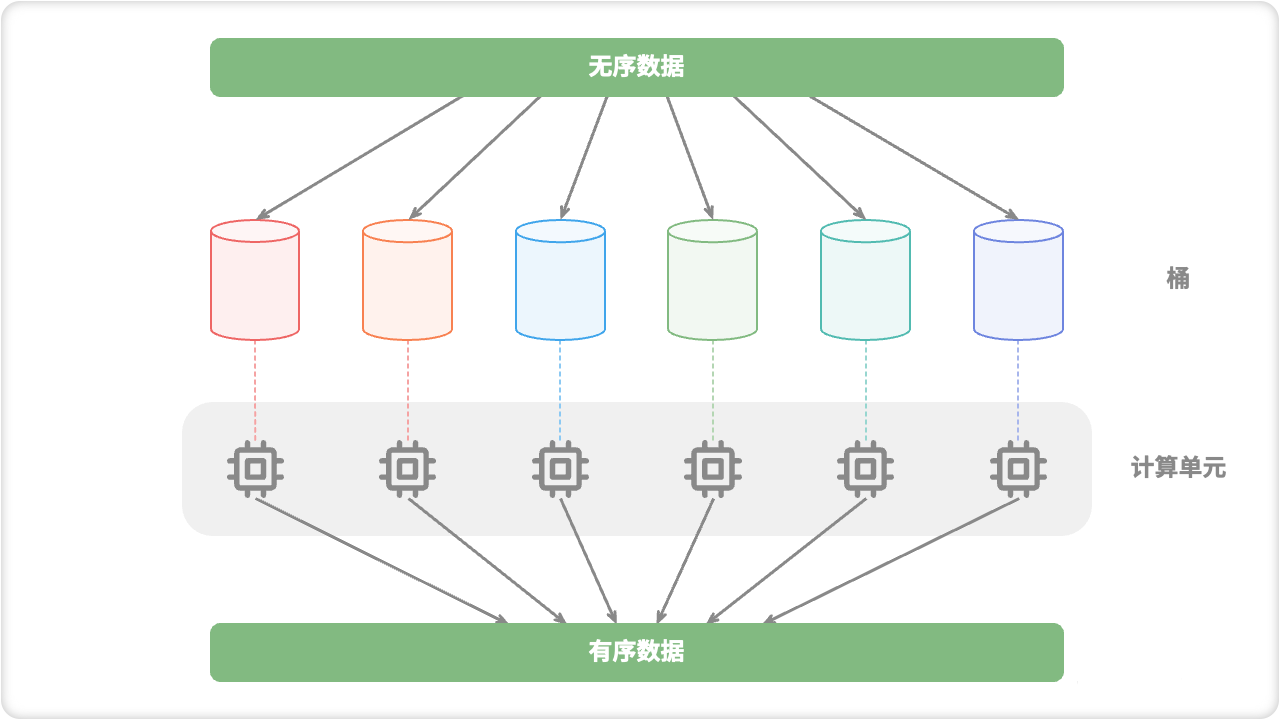
🦋1.3 分治常见应用
寻找最近点对:通过分治算法将点集分为左右两个部分,然后递归求解这两部分中的最近点对,最后考虑跨越两个部分的最近点对。大整数乘法:将两个大整数分别划分为较小的部分,然后递归计算每个部分的乘积,最后将这些部分的乘积合并起来。矩阵乘法:将两个矩阵分别划分为较小的部分,然后递归计算每个部分的乘积,最后将这些部分的乘积合并起来。汉诺塔问题:将 n 个盘子从原始柱子移动到目标柱子,需要将 n-1 个盘子从原始柱子移动到辅助柱子,然后将最后一个盘子从原始柱子移动到目标柱子,最后将 n-1 个盘子从辅助柱子移动到目标柱子,递归执行这个过程即可。求解逆序对:将数组划分为两个部分,递归计算每个部分的逆序对数,然后考虑跨越两个部分的逆序对数。可以使用归并排序的思想来实现。在归并的时候,统计两个有序子数组之间的逆序对数,将逆序对数加到最终结果中。
🔎2.分治搜索策略
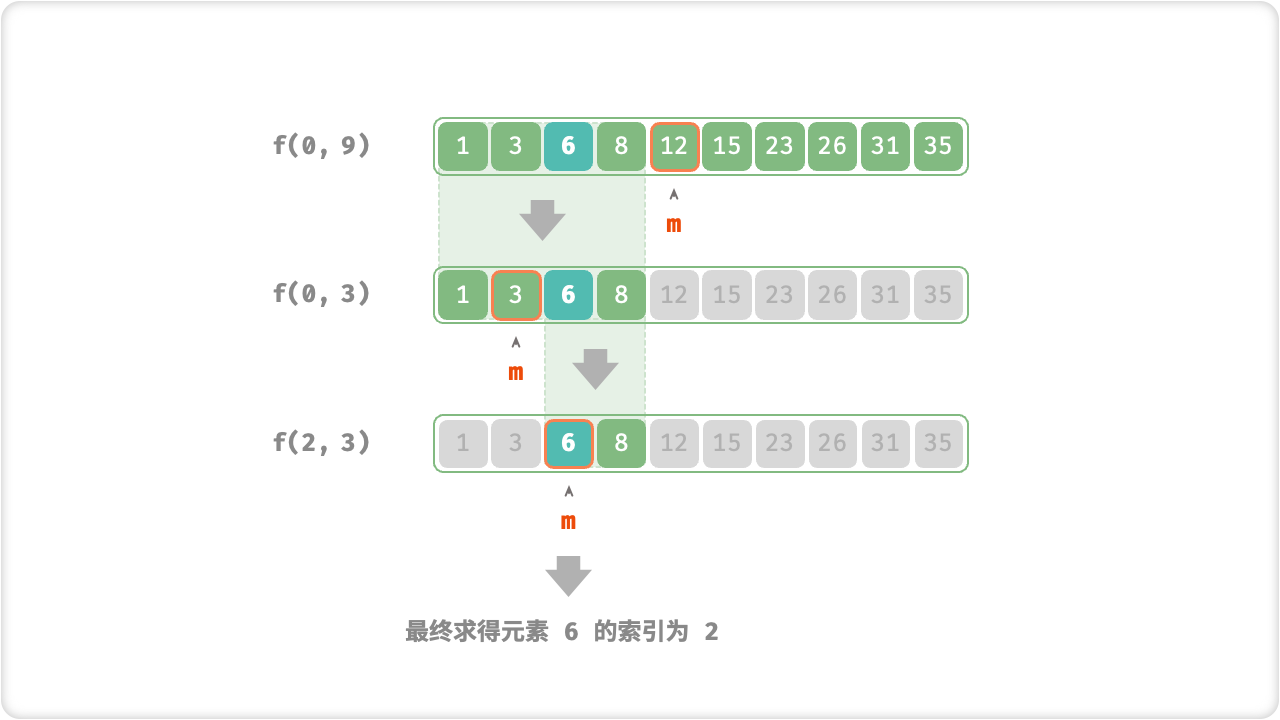
二分查找也称为折半查找,是一种常用的查找算法,它的优点是查找速度快,时间复杂度为O(logn)。基于分治算法实现二分查找的步骤如下:
- 将数组或列表按照中间元素分为两部分,如果中间元素等于目标元素,则查找成功。
- 如果中间元素大于目标元素,则在左半部分继续查找,否则在右半部分继续查找。
- 重复以上步骤,直到目标元素被找到或查找区间为空。
下面给出一个基于分治算法实现二分查找的Python代码示例:
/**
* File: binary_search_recur.cs
* Created Time: 2023-07-18
* Author: hpstory (hpstory1024@163.com)
*/
namespace hello_algo.chapter_divide_and_conquer;
public class binary_search_recur {
/* 二分查找:问题 f(i, j) */
public int dfs(int[] nums, int target, int i, int j) {
// 若区间为空,代表无目标元素,则返回 -1
if (i > j) {
return -1;
}
// 计算中点索引 m
int m = (i + j) / 2;
if (nums[m] < target) {
// 递归子问题 f(m+1, j)
return dfs(nums, target, m + 1, j);
} else if (nums[m] > target) {
// 递归子问题 f(i, m-1)
return dfs(nums, target, i, m - 1);
} else {
// 找到目标元素,返回其索引
return m;
}
}
/* 二分查找 */
public int binarySearch(int[] nums, int target) {
int n = nums.Length;
// 求解问题 f(0, n-1)
return dfs(nums, target, 0, n - 1);
}
[Test]
public void Test() {
int target = 6;
int[] nums = { 1, 3, 6, 8, 12, 15, 23, 26, 31, 35 };
// 二分查找(双闭区间)
int index = binarySearch(nums, target);
Console.WriteLine("目标元素 6 的索引 = " + index);
}
}
🔎3.构建二叉树问题
分治算法可以用来构建二叉树,具体步骤如下:
- 找到子问题:将给定的序列分成两个部分,分别构建二叉树。
- 解决子问题:对于每个子问题,递归地调用该算法,直到子问题不能再进一步分割。
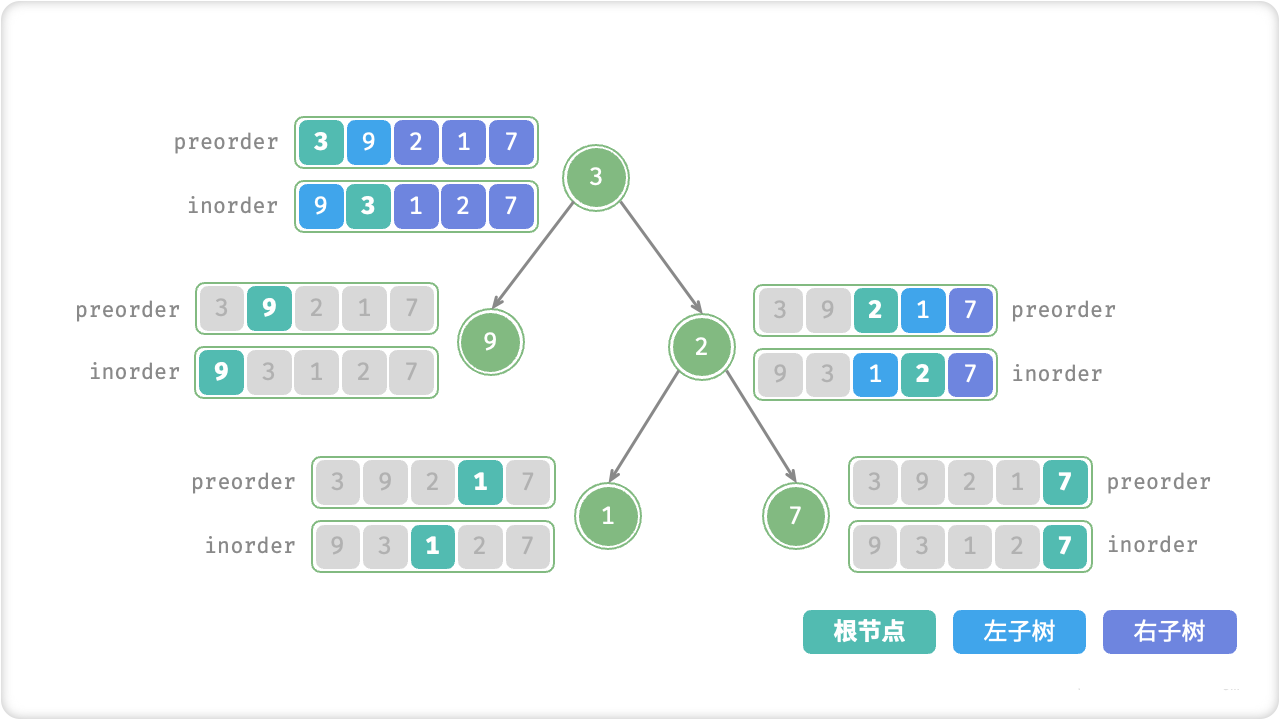
- 合并子问题的解:将子问题的解合并成整个问题的解。对于左右两个子问题,我们可以将左半部分的序列的中间节点作为根节点,右半部分的序列的中间节点作为其右孩子节点,然后递归地构建左子树和右子树。
- 返回结果:返回构建好的二叉树。
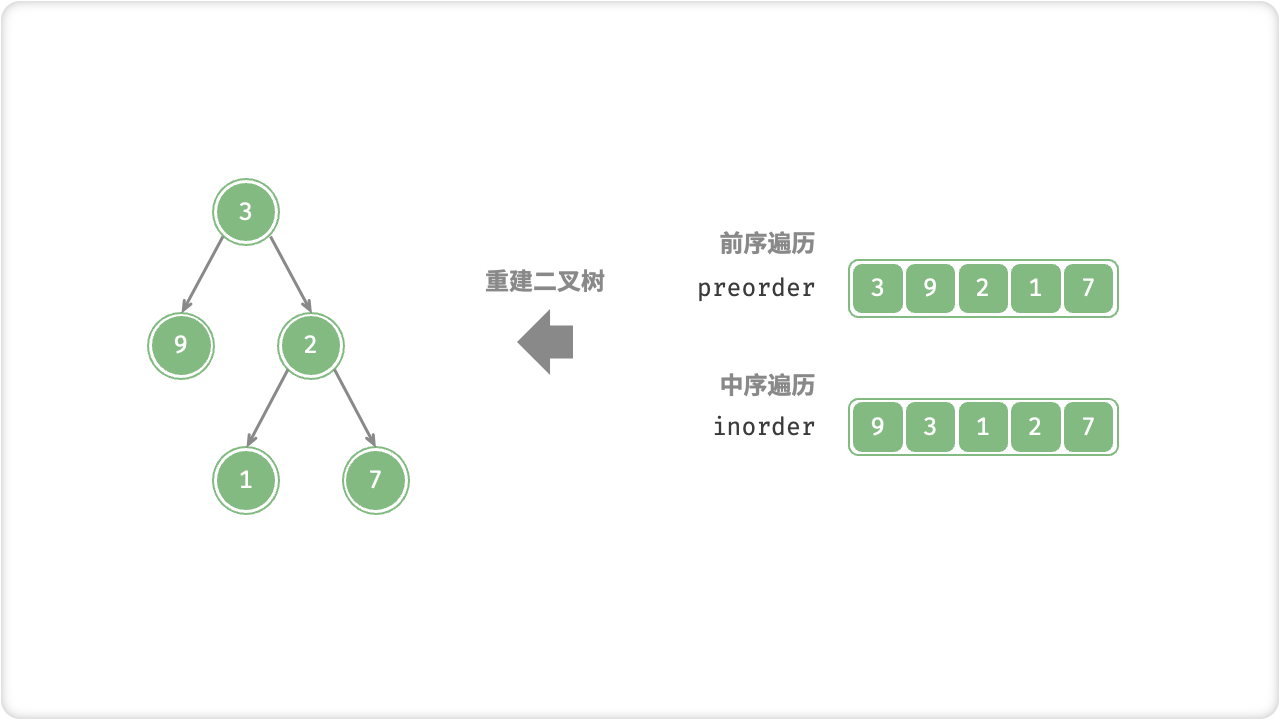
代码实现如下(假设给定的序列是有序的)
public class build_tree {
/* 构建二叉树:分治 */
public TreeNode dfs(int[] preorder, Dictionary<int, int> inorderMap, int i, int l, int r) {
// 子树区间为空时终止
if (r - l < 0)
return null;
// 初始化根节点
TreeNode root = new TreeNode(preorder[i]);
// 查询 m ,从而划分左右子树
int m = inorderMap[preorder[i]];
// 子问题:构建左子树
root.left = dfs(preorder, inorderMap, i + 1, l, m - 1);
// 子问题:构建右子树
root.right = dfs(preorder, inorderMap, i + 1 + m - l, m + 1, r);
// 返回根节点
return root;
}
/* 构建二叉树 */
public TreeNode buildTree(int[] preorder, int[] inorder) {
// 初始化哈希表,存储 inorder 元素到索引的映射
Dictionary<int, int> inorderMap = new Dictionary<int, int>();
for (int i = 0; i < inorder.Length; i++) {
inorderMap.TryAdd(inorder[i], i);
}
TreeNode root = dfs(preorder, inorderMap, 0, 0, inorder.Length - 1);
return root;
}
[Test]
public void Test() {
int[] preorder = { 3, 9, 2, 1, 7 };
int[] inorder = { 9, 3, 1, 2, 7 };
Console.WriteLine("前序遍历 = " + string.Join(", ", preorder));
Console.WriteLine("中序遍历 = " + string.Join(", ", inorder));
TreeNode root = buildTree(preorder, inorder);
Console.WriteLine("构建的二叉树为:");
PrintUtil.PrintTree(root);
}
}
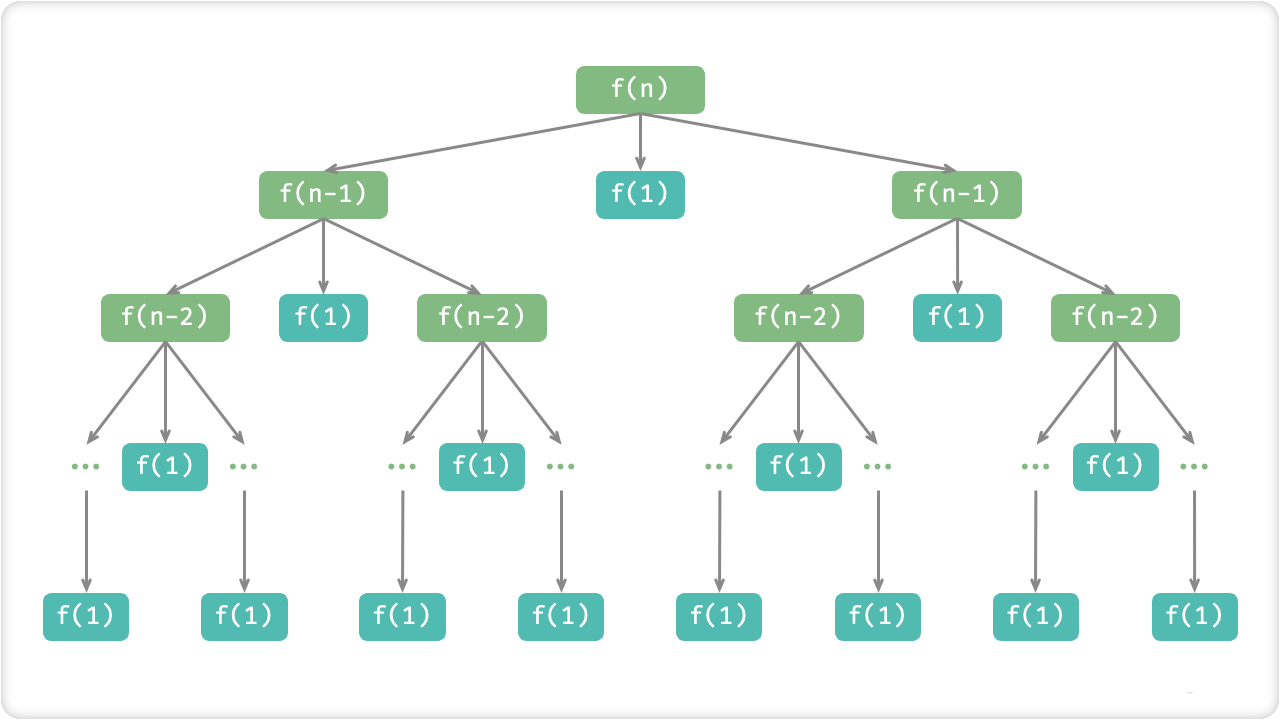
🔎4.汉诺塔问题
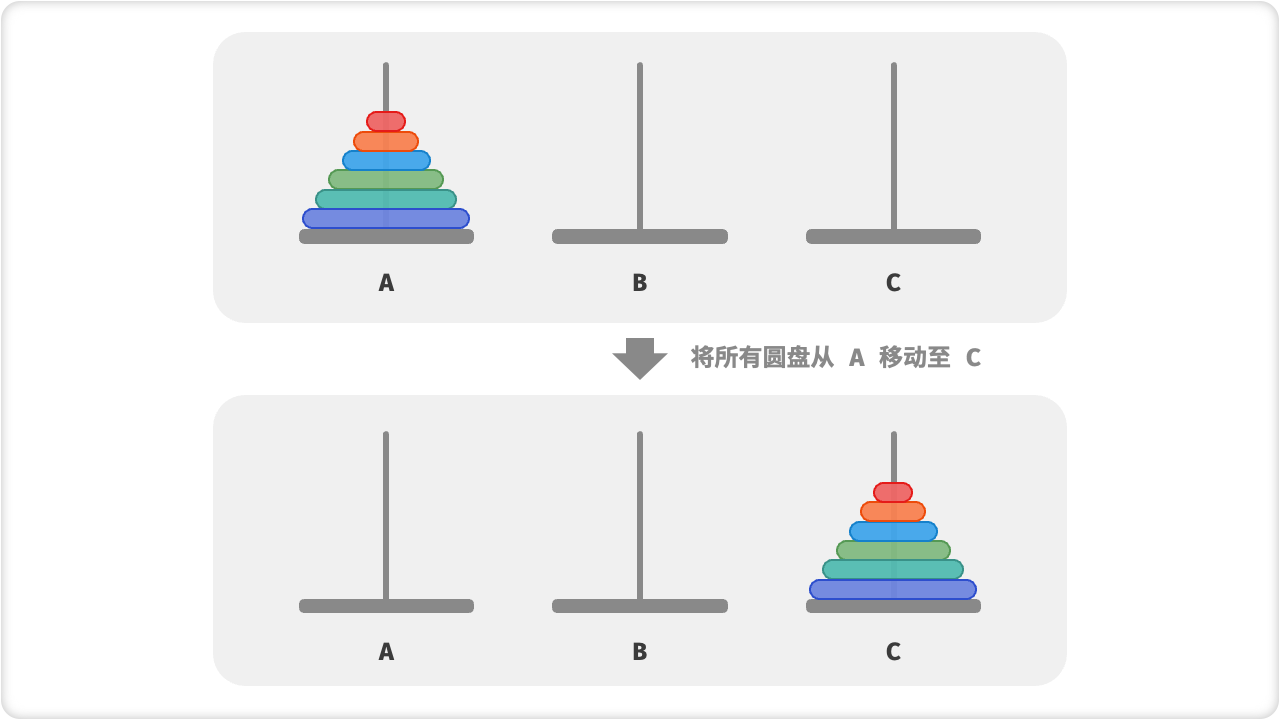
汉诺塔问题可以通过分治算法来解决。分治算法是将问题分解成若干个小的子问题来解决,最后将子问题的结果合并起来得到最终的解决方案。
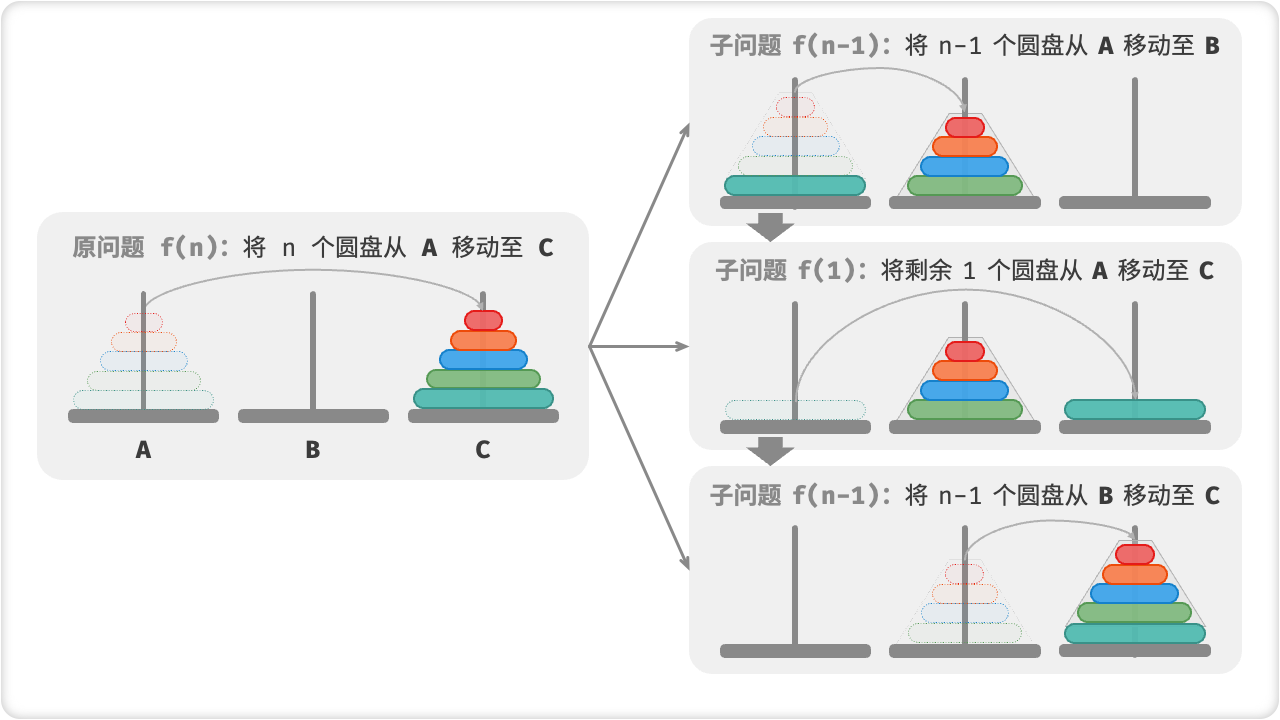
在汉诺塔问题中,我们可以将塔分解为三个部分,分别为起始塔、中转塔和目标塔。
- 将起始塔的前n-1个盘子移动到中转塔上。
- 将起始塔上的第n个盘子移动到目标塔上。
- 将中转塔上的n-1个盘子移动到目标塔上。
这个过程可以看做是一个递归过程。我们可以使用递归函数来将问题不断分解为更小的子问题,直到子问题变得简单明了,并求出其解决方案,然后再将子问题的解合并为原问题的解。
下面是使用分治算法来解决汉诺塔问题的代码:
public class hanota {
/* 移动一个圆盘 */
public void move(List<int> src, List<int> tar) {
// 从 src 顶部拿出一个圆盘
int pan = src[^1];
src.RemoveAt(src.Count - 1);
// 将圆盘放入 tar 顶部
tar.Add(pan);
}
/* 求解汉诺塔:问题 f(i) */
public void dfs(int i, List<int> src, List<int> buf, List<int> tar) {
// 若 src 只剩下一个圆盘,则直接将其移到 tar
if (i == 1) {
move(src, tar);
return;
}
// 子问题 f(i-1) :将 src 顶部 i-1 个圆盘借助 tar 移到 buf
dfs(i - 1, src, tar, buf);
// 子问题 f(1) :将 src 剩余一个圆盘移到 tar
move(src, tar);
// 子问题 f(i-1) :将 buf 顶部 i-1 个圆盘借助 src 移到 tar
dfs(i - 1, buf, src, tar);
}
/* 求解汉诺塔 */
public void solveHanota(List<int> A, List<int> B, List<int> C) {
int n = A.Count;
// 将 A 顶部 n 个圆盘借助 B 移到 C
dfs(n, A, B, C);
}
[Test]
public void Test() {
// 列表尾部是柱子顶部
List<int> A = new List<int> { 5, 4, 3, 2, 1 };
List<int> B = new List<int>();
List<int> C = new List<int>();
Console.WriteLine("初始状态下:");
Console.WriteLine("A = " + string.Join(", ", A));
Console.WriteLine("B = " + string.Join(", ", B));
Console.WriteLine("C = " + string.Join(", ", C));
solveHanota(A, B, C);
Console.WriteLine("圆盘移动完成后:");
Console.WriteLine("A = " + string.Join(", ", A));
Console.WriteLine("B = " + string.Join(", ", B));
Console.WriteLine("C = " + string.Join(", ", C));
}
}
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
