Linkerd服务网格中重试与超时和金丝雀发布


Linkerd服务网格中重试与超时和金丝雀发布
王先森2024-01-122024-01-12
重试与超时
在构建分布式系统时,保证可靠性是一项关键任务。Linkerd 是一个功能强大的服务网格工具,通过其重试与超时机制,可以帮助应对临时错误和延迟问题,从而提高系统的可靠性。本文将深入探讨 Linkerd 中的重试与超时特性,以及它们如何帮助应对故障和提升用户体验。
重试是一种处理失败请求的机制。当一个请求失败时,Linkerd 的重试机制可以自动重试请求,以期获得成功的响应。当特定实例上的特定路由返回错误时,Linkerd 可以简单地重试该请求,从而增加请求成功的可能性。这对于处理临时性的网络问题非常有用,例如网络拥塞或服务暂时不可用。通过重试,可以增加请求成功的机会,并提高系统的可靠性。然而,在实践中,实现重试可能会面临一些挑战。可能会给系统增加额外的负载,这个负载可能会让事情变得更糟糕。一种常见的故障场景就是重试风暴,为了避免重试风暴的发生,Linkerd 使用重试预算来设置重试参数。重试预算是可以重试的请求总数的百分比,Linkerd 默认允许对失败的请求进行 20% 的重试,并每秒额外允许 10 个请求的重试。这种方式可以有效地降低重试风暴的风险,确保系统的稳定性。
超时 是通过在路由上设置最长时间来限制请求处理时间的一种机制。在该限制内,如果请求没有得到响应,Linkerd将终止请求并返回错误。超时可以防止长时间等待造成的资源浪费,并提高系统的性能和可用性。举例来说,如果一个名为 getValue 的路由在大多数情况下能够在 10 毫秒内返回结果,但偶尔需要花费 10 分钟,那么设置一个适当的超时时间可以确保调用者不会等待过长时间。超时机制与重试和负载均衡相结合时,可以自动将请求发送到其他可用实例,从而提高系统的可用性和性能。
重试与超时的综合应用: 重试和超时机制是为了应对部分、暂时性故障而设计的,防止这些故障升级为全局中断。然而,它们并不是万能的解决方案,的应用程序仍然需要能够处理错误。通过在 Linkerd 中综合应用重试和超时机制,可以提升系统的可靠性和用户体验。当一个服务实例出现问题时,重试机制可以尝试将请求发送到其他实例,避免长时间的等待和失败。超时机制可以限制请求处理的最长时间,并确保调用者具有更可预测的性能。这两个机制的结合使用,可以使我们的系统更加稳定和可靠。
使用 Per-Route Metrics 来确定何时重试和超时
首先,将查看 emojivoto 命名空间中所有 Deployments 的统计信息,然后再深入研究不健康的服务。直接使用 linkerd viz stat 命令即可,如下所示:
$ linkerd viz stat deploy -n emojivoto
NAME MESHED SUCCESS RPS LATENCY_P50 LATENCY_P95 LATENCY_P99 TCP_CONN
emoji 1/1 100.00% 2.2rps 1ms 1ms 1ms 3
vote-bot 1/1 100.00% 0.2rps 1ms 1ms 1ms 1
voting 1/1 83.78% 1.2rps 1ms 1ms 5ms 3
web 1/1 87.69% 2.2rps 1ms 4ms 7ms 3stat 命令向我们展示了黄金指标,包括成功率和延迟,可以注意到 voting 和 web 服务的成功率低于 100%,接下来可以通过 linkerd viz edges 命令来了解服务之间的关系。
linkerd viz edges deploy -n emojivoto
SRC DST SRC_NS DST_NS SECURED
vote-bot web emojivoto emojivoto √
web emoji emojivoto emojivoto √
web voting emojivoto emojivoto √ 当然也可以通过 Linkerd Dashboard 来查看图去了解服务之间的关系。
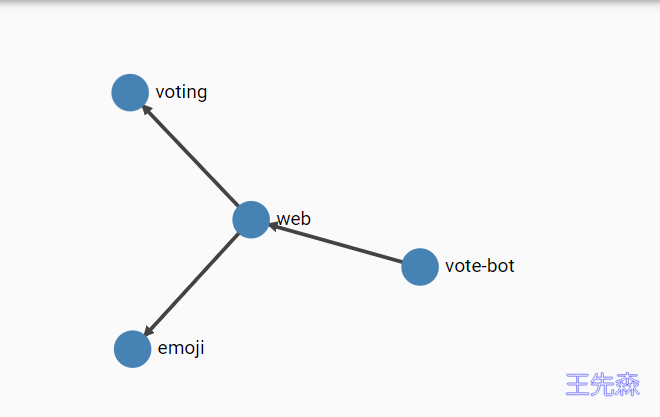
从上面的结果可以看出 web 服务中的 Pods 对 voting 服务的 Pods 进行了调用,所以可以猜测是 voting 服务导致了 web 服务的错误,可以通过 linkerd viz routes 命令去了解 voting 服务的路由指标情况,如下命令所示:
$ linkerd viz routes deploy/voting -n emojivoto
# ......
VoteDog voting-svc - - - - -
VoteDoughnut voting-svc 0.00% 0.1rps 1ms 1ms 1ms
VoteFax voting-svc - - - - -
VoteFire voting-svc 100.00% 0.0rps 1ms 1ms 1ms
VoteFlightDeparture voting-svc - - - - -
# ......同样也可以通过 Linkerd Dashboard 去查看 voting 服务的 ROUTE METRICS 信息,如下图所示:
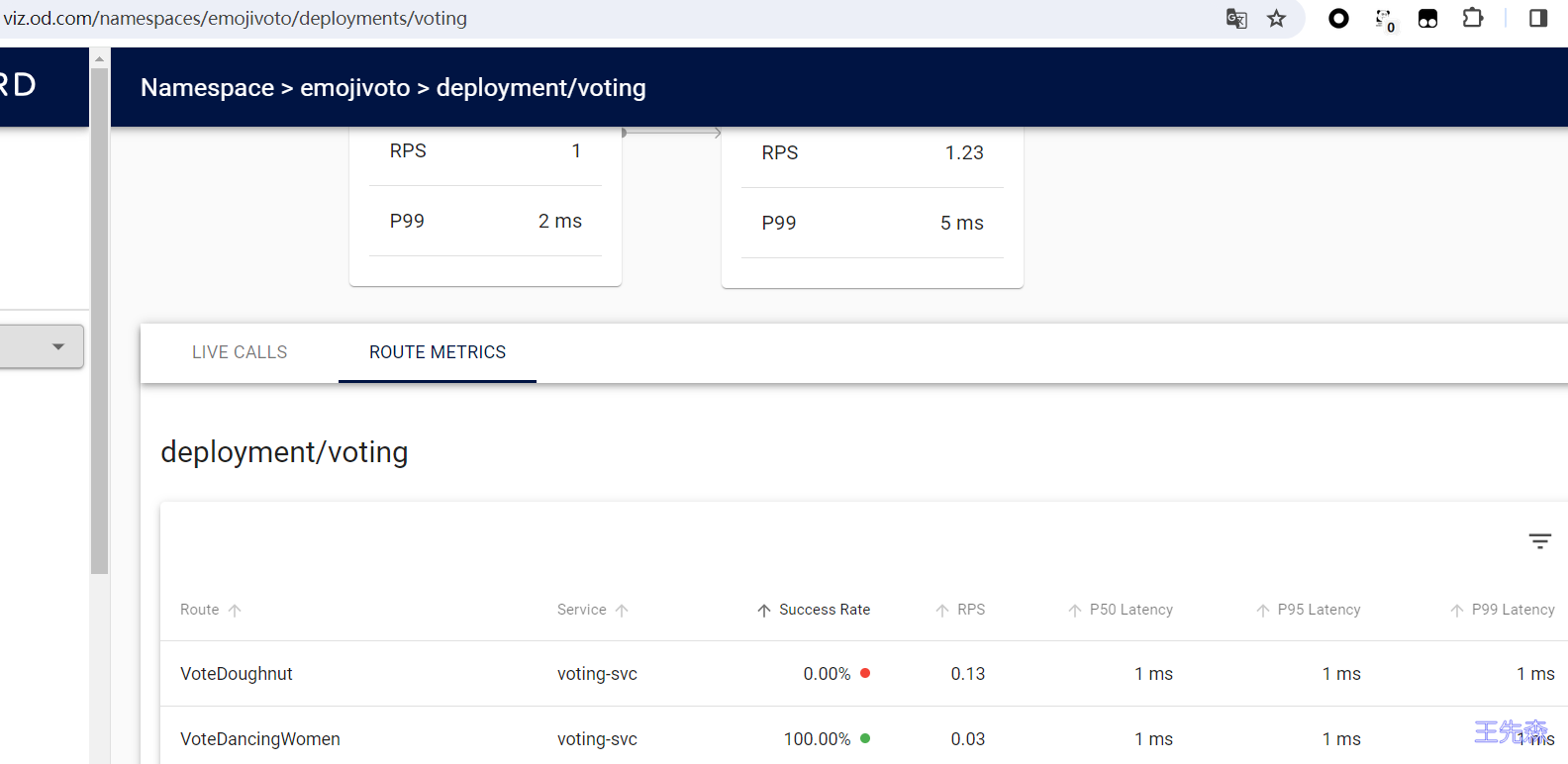
最终可以定位到是 VoteDoughnut 这条是请求失败的路由。现在不仅知道 web 服务和 voting 服务之间发生了错误,而且也知道了 VoteDoughnut 路由发生了错误。接下来可以使用重试来尝试解决错误,同时也可以要求开发人员进行代码调试。
配置重试
在开始为 VotingDoughnut 路由配置重试之前,首先仔细查看 web 和 voting 服务的指标,因为这将帮助真正了解应用重试是否可以解决问题。这里将只使用 Linkerd CLI,因为它可以用通过使用 -o wide 标志向显示实际和有效的请求量和成功率,Linkerd 仪表盘会显示整体成功率和 RPS,但不显示实际和有效的指标。实际指标和有效指标之间的区别是:
- 实际值来自接收请求的服务器的角度
- 有效值是从发送请求的客户端的角度来看的
在没有重试和超时的情况下,显然这两个数据是相同的。但是,一旦配置了重试或超时,它们就可能会不一样了。例如,重试会使实际的 RPS 高于有效的 RPS,因为从服务器的角度来看,重试是另一个请求,但从客户端的角度来看,它是同一个请求。重试可以使实际成功率低于有效成功率,因为失败的重试调用也发生在服务器上,但不会暴露给客户端。而超时可能会产生相反的效果:这取决于具体的返回时间,一个最终成功返回的超时请求可能会使实际成功率高于有效成功率,因为服务器将其视为成功,而客户端只看到失败。
总的来说就是 Linkerd 的实际和有效指标在重试或超时的情况下可能会有所不同,但实际数字代表实际命中服务器的情况,而有效数字代表了在 Linkerd 的可靠性逻辑完成其职责后,客户端有效地得到了对其请求的响应。
比如通过下面的命令来查看 vote-bot 服务的路由指标情况:
$ linkerd viz routes deploy/vote-bot -n emojivoto --to deploy/web -owide
ROUTE SERVICE EFFECTIVE_SUCCESS EFFECTIVE_RPS ACTUAL_SUCCESS ACTUAL_RPS LATENCY_P50 LATENCY_P95 LATENCY_P99
GET /api/list web-svc 100.00% 1.0rps 100.00% 1.0rps 2ms 4ms 4ms
GET /api/vote web-svc 79.31% 1.0rps 79.31% 1.0rps 3ms 4ms 5ms
[DEFAULT] web-svc - - - - - - -上面的命令中我们添加了一个 -o wide 的标志,这样输出结果会包含实际和有效的成功和 RPS 指标。从 vote-bot 服务来看,web 服务的 /api/vote 路由的有效成功率和实际成功率都低于 100%,这是因为现在我们还没有配置重试。而且我们不能假设所有请求都是可重试的,重试请求对于 Linkerd 来说,是有非常具体的条件的:
- 现在,使用 HTTP POST 方法的请求在 Linkerd 中不可重试。因为 POST 请求几乎总是在请求
body中包含数据,重试请求意味着代理必须将该数据存储在内存中。因此,为了保持最小的内存使用,代理不存储 POST 请求body,并且它们不能被重试。 - 正如我们前面提到过的,Linkerd 仅将响应中的
5XX状态码视为错误,而2XX和4XX都被识别为成功状态码。4XX状态码表示服务器查看但找不到资源,这属于服务器的正确行为,而5XX状态码表示服务器在处理请求时遇到了错误,这是不正确的行为。
现在我们通过在 web 服务的 /api/vote 路由中添加重试功能来验证下前面的知识。我们再次查看下 web 服务的 ServiceProfile 对象,内容如下所示:
# vim web-sp.yaml
apiVersion: linkerd.io/v1alpha2
kind: ServiceProfile
metadata:
creationTimestamp: null
name: web-svc.emojivoto.svc.cluster.local
namespace: emojivoto
spec:
routes:
- condition:
method: GET
pathRegex: /api/list
name: GET /api/list
- condition:
method: GET
pathRegex: /api/vote
name: GET /api/vote
isRetryable: true # 在这个路由中添加重试选项应用后我们可以观察 vote-bot 服务的路由指标变化情况:
$ linkerd viz routes deploy/vote-bot -n emojivoto --to deploy/web -owide
ROUTE SERVICE EFFECTIVE_SUCCESS EFFECTIVE_RPS ACTUAL_SUCCESS ACTUAL_RPS LATENCY_P50 LATENCY_P95 LATENCY_P99
GET /api/list web-svc 100.00% 0.9rps 100.00% 0.9rps 2ms 6ms 9ms
GET /api/vote web-svc 85.71% 0.9rps 7.25% 11.0rps 3ms 353ms 391ms
[DEFAULT] web-svc - - - - - - -可以看到实际成功率(ACTUAL_SUCCESS)变得非常底了,因为重试的结果可能还是错误。上面提到了 Linkerd 的重试行为是由重试预算配置的,当配置 isRetryable: true 的时候,默认情况下,重试最多可能会额外增加 20% 的请求负载(加上每秒额外的 10 次免费重试)。可以通过在您 service profile 设置来调整这些设置retryBudget :
spec:
retryBudget:
retryRatio: 0.2
minRetriesPerSecond: 10
ttl: 10s其中 retryBudget 参数是具有三个主要的字段:
retryRatio:重试率,表示重试请求与原始请求的最大比率,retryRatio为 0.2 表示重试最多会增加 20% 的请求负载。minRetriesPerSecond:这是在retryRatio允许的重试之外,每秒允许的重试次数(这允许在请求率很低时进行重试),默认为 10 RPS。ttl:表示在计算重试率时应考虑多长时间的请求,一个较大的值会考虑一个较大的窗口,因此允许更多的重试。默认为 10 秒。
配置超时
除了重试和重试预算外,Linkerd 还提供超时功能,允许你确保对指定路由的请求永远不会超过指定的时间。
为了说明这一点,让我们重新来看一看 web 和 voting 服务的每个路由指标。
$ linkerd viz routes deploy/vote-bot -n emojivoto --to deploy/web -o wide
$ linkerd viz routes deploy/web -n emojivoto --to deploy/voting -o wide在前面我们已经了解到 web 和 voting 之间的延迟接近 1ms,为了演示超时,我们将 /api/vote 路由超时时间设置为 0.5ms,这样基本上都无法满足要求就超时了,Linkerd 会将错误发送会客户端,成功率变为 0 了。
修改 web 服务的 ServiceProfile 对象,添加 timeout 属性,如下所示:
# vim web-sp.yaml
apiVersion: linkerd.io/v1alpha2
kind: ServiceProfile
metadata:
name: web-svc.emojivoto.svc.cluster.local
namespace: emojivoto
spec:
routes:
- condition:
method: GET
pathRegex: /api/list
name: GET /api/list
- condition:
method: GET
pathRegex: /api/vote
name: GET /api/vote
timeout: 0.5ms
isRetryable: true应用上面的对象后,服务的有效和实际成功率就会都下降到 0,因为 /api/vote 在 0.5ms 内都会超时,所以成功率变为 0。
linkerd viz routes deploy/vote-bot -n emojivoto --to deploy/web -o wide
ROUTE SERVICE EFFECTIVE_SUCCESS EFFECTIVE_RPS ACTUAL_SUCCESS ACTUAL_RPS LATENCY_P50 LATENCY_P95 LATENCY_P99
GET /api/list web-svc 100.00% 1.0rps 100.00% 1.0rps 2ms 4ms 4ms
GET /api/vote web-svc 0.00% 0.7rps 0.00% 0.0rps 0ms 0ms 0ms
[DEFAULT] web-svc - - - - - - -达到超时的请求将被取消,返回 504 Gateway Timeout 响应,并出于有效成功率的目的计为失败。由于请求在收到任何实际响应之前被取消,超时根本不会计入实际请求量。这意味着当配置超时时,有效请求率可能高于实际请求率。此外,如果在超过超时时收到响应,则请求可能被视为实际成功但有效失败。这会导致有效成功率低于实际成功率。
金丝雀发布
流量拆分
Linkerd 的流量拆分 (traffic split) 功能允许您在服务之间动态转移流量。这可用于实施低风险部署策略,如蓝绿(blue-green)部署和金丝雀(canaries)。
这项功能允许你根据可动态配置的权重,将请求分配给不同的 Kubernetes 服务对象。虽然流量分割可以适用于任意的 Service 对象,但一般情况下是将一个 Service 的传入流量分给不同版本的 Service。我们可以将流量拆分与 Linkerd 的自动黄金指标(golden metrics)检测相结合, 并根据观察到的指标推动流量决策。例如,我们可以逐渐将流量从旧部署转移到新部署, 同时持续监控其成功率。如果在任何时候成功率下降, 我们可以将流量转移回原始部署并退出发布。理想情况下,我们的用户始终保持快乐(remain happy),没有注意到任何事情!
Linkerd 支持两种不同的方式来配置流量拆分:您可以使用Linkerd SMI 扩展和 TrafficSplit 资源,也可以使用Linkerd 本身支持的HTTPRoute资源。虽然某些集成(例如 Flagger)依赖于 SMI 和TrafficSplit方法,但使用 HTTPRoute是未来的首选方法。
更新服务
接下来我们还是以 Emojivoto 应用为例来更新版本的 web 服务资源对象如下所示
# vim emoji-web-2.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: web-2
namespace: emojivoto
---
apiVersion: v1
kind: Service
metadata:
name: web-svc-2
namespace: emojivoto
spec:
ports:
- name: http
port: 80
targetPort: 8080
selector:
app: web-svc-2
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: web-svc-2
app.kubernetes.io/part-of: emojivoto
app.kubernetes.io/version: linux-training-v2
name: web-svc-2
namespace: emojivoto
spec:
selector:
matchLabels:
app: web-svc-2
version: linux-training-v2
template:
metadata:
annotations:
linkerd.io/inject: enabled # 设置自动注入的注解
labels:
app: web-svc-2
version: linux-training-v2
spec:
containers:
- env:
- name: WEB_PORT
value: "8080"
- name: EMOJISVC_HOST
value: emoji-svc.emojivoto:8080
- name: VOTINGSVC_HOST
value: voting-svc.emojivoto:8080
- name: INDEX_BUNDLE
value: dist/index_bundle.js
- name: MESSAGE_OF_THE_DAY # 输入你想在web显示文字
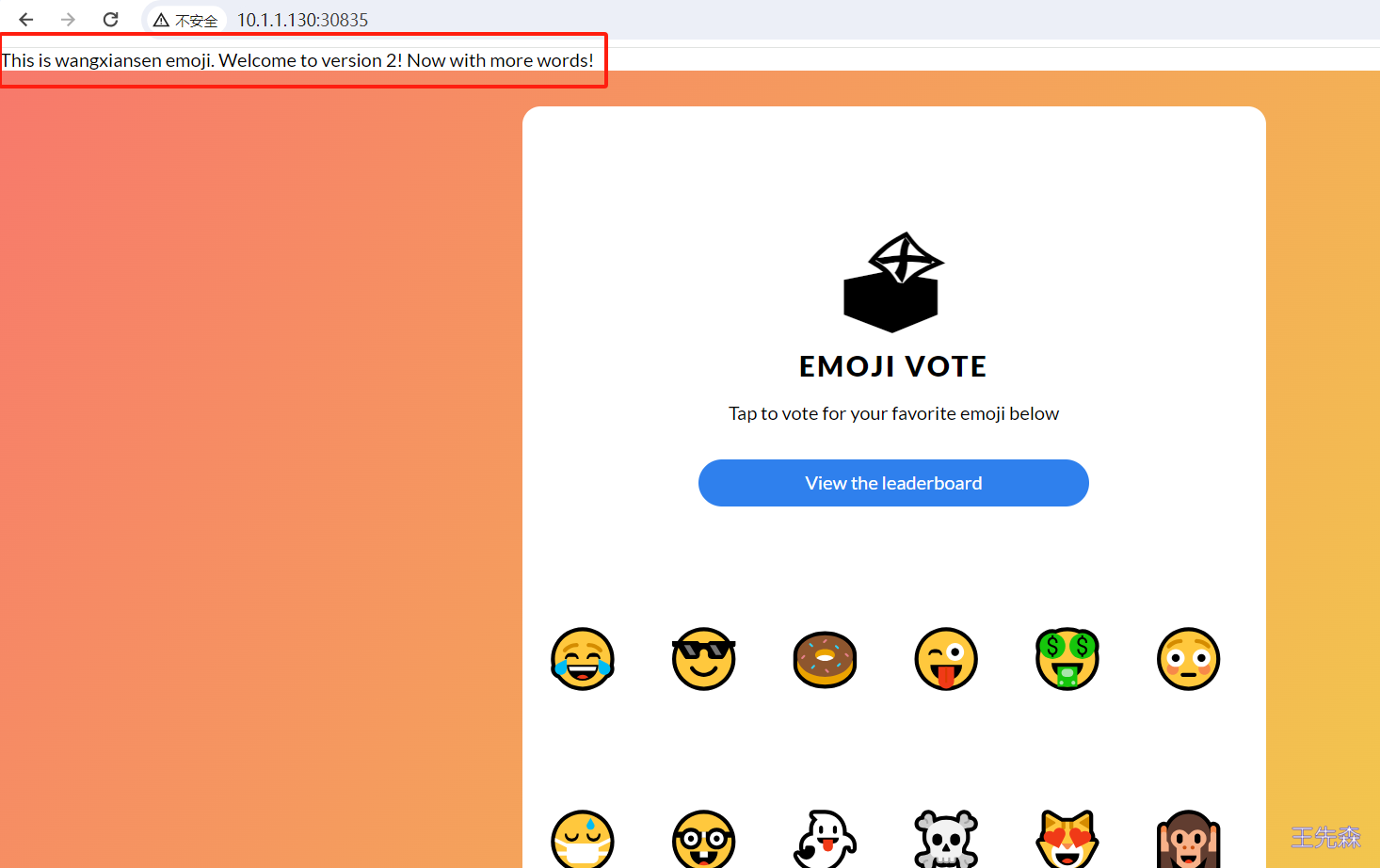
value: 'This is wangxiansen emoji. Welcome to version 2! Now with more words!'
image: docker.l5d.io/buoyantio/emojivoto-web:v12
name: web-svc-2
ports:
- containerPort: 8080
name: http
resources:
requests:
cpu: 100m
serviceAccountName: web-2直接应用上面的资源对象:
$ kubectl apply -f linkerd/emoji-web-2.yaml 部署后先验证更新版本的服务是否已经正确部署了。
$ kubectl get po --selector app=web-svc-2 -n emojivoto
NAME READY STATUS RESTARTS AGE
web-svc-2-6b64fd9876-txwcg 2/2 Running 0 4m36s
$ kubectl get svc web-svc-2 -n emojivoto
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
web-svc-2 NodePort 192.168.173.54 <none> 80:30835/TCP 45h可以在浏览器中通过 10.1.1.130:30835 访问新版本的应用。
创建 HTTPRoute
现在让我们创建一个 HTTPRoute 并将 10% 的流量分配给 v2 后端:
# vim web-ts.yaml
apiVersion: policy.linkerd.io/v1beta2
kind: HTTPRoute
metadata:
name: emoji-route
namespace: emojivoto
spec:
parentRefs:
- name: web-svc
kind: Service
group: core
port: 80
rules:
- backendRefs:
- name: web-svc
port: 80
weight: 90
- name: web-svc-2
port: 80
weight: 10在此 HTTPRoute 中,是parentRef中的web-svc正在与之通信的服务资源。这意味着每当网状客户端与web-svc服务通信时,它将使用此 HTTPRoute。您可能还注意到,该web-svc 服务再次出现在列表中,backendRefs权重为 90。这意味着发送到该web-svc服务的 90% 的流量将继续发送到该服务的端点。另外 10% 的请求将被路由到 web-svc-2服务。
我们可以通过查看流量统计信息来了解这一点(请记住,该stat 命令查看 1 分钟窗口内的指标,因此可能需要长达 1 分钟的时间才能看到统计信息):
$ linkerd viz -n emojivoto stat --from deploy/vote-bot deployment
NAME MESHED SUCCESS RPS LATENCY_P50 LATENCY_P95 LATENCY_P99 TCP_CONN
web 1/1 92.86% 1.9rps 3ms 4ms 7ms 1
web-svc-2 1/1 100.00% 0.1rps 2ms 4ms 4ms 1本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-01-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号