【教程】深度学习中的自动编码器Autoencoder是什么?

【教程】深度学习中的自动编码器Autoencoder是什么?

小锋学长生活大爆炸
发布于 2024-01-15 08:48:55
发布于 2024-01-15 08:48:55
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn]
引言
自动编码器已成为使计算机系统能够更有效地解决数据压缩问题的技术和技巧之一。它们成为减少嘈杂数据的流行解决方案。
简单的自动编码器提供与输入数据相同或相似的输出,只是经过压缩。对于变分自动编码器(通常在大型语言模型的上下文中讨论),输出是新生成的内容。
什么是自动编码器?
自动编码器是一种人工神经网络,用于以无监督的方式学习数据编码。自动编码器的目的是通过训练网络捕获输入图像的最重要部分来学习高维数据的低维表示(编码),通常用于降维。
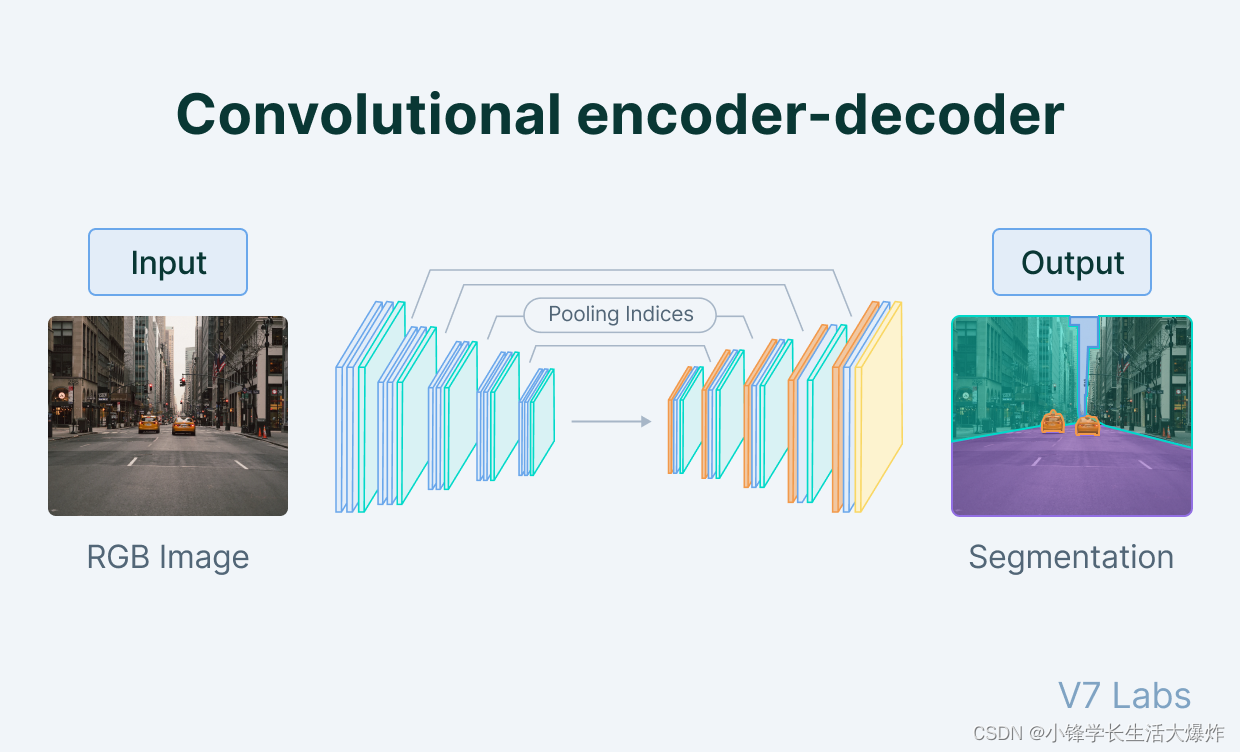
自动编码器的体系结构
自动编码器由 3 个部分组成:
1. 编码器Encoder:将训练-验证-测试集输入数据压缩为编码表示的模块,该编码表示通常比输入数据小几个数量级。
2. 瓶颈Bottleneck:包含压缩知识表示的模块,因此是网络中最重要的部分。
3. 解码器Decoder:帮助网络“解压缩”知识表示并从其编码形式中重建数据的模块。然后将输出与真实值进行比较。
整个架构如下所示:
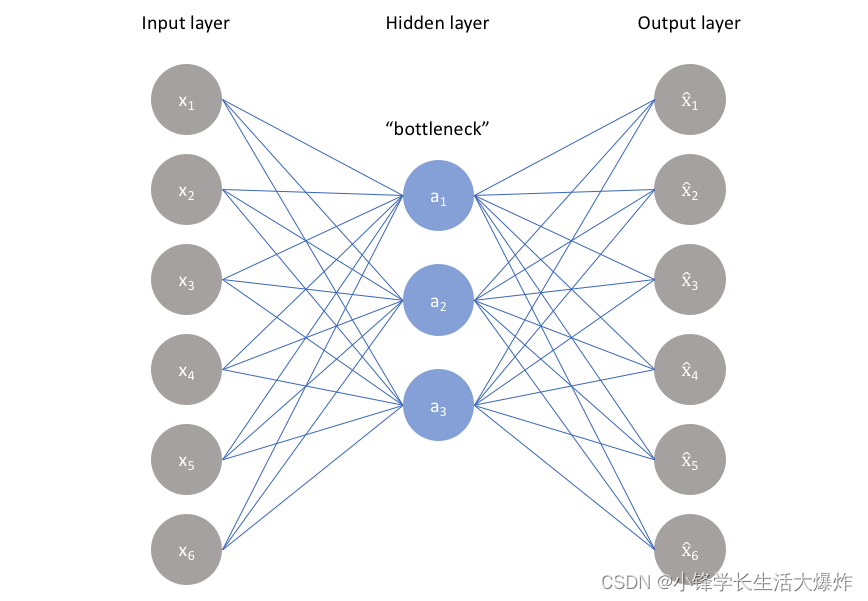
编码器、瓶颈和解码器之间的关系
编码器Encoder
编码器是一组卷积模块,后跟池化模块,这些模块将模型的输入压缩到称为瓶颈的紧凑部分。
瓶颈之后是解码器,它由一系列上采样模块组成,用于将压缩特征恢复为图像形式。在简单的自动编码器的情况下,输出应与输入数据相同,但噪声较低。
然而,对于变分自动编码器来说,它是一个全新的图像,由模型作为输入提供的信息形成。
瓶颈Bottleneck
神经网络中最重要的部分,也是具有讽刺意味的最小部分,是瓶颈。瓶颈的存在是为了限制从编码器到解码器的信息流,因此只允许最重要的信息通过。
由于瓶颈的设计方式是将图像所拥有的最大信息捕获在其中,因此我们可以说瓶颈有助于我们形成输入的知识表示。
因此,编码器-解码器结构有助于我们从数据形式的图像中提取最多内容,并在网络内的各种输入之间建立有用的相关性。
作为输入的压缩表示的瓶颈进一步阻止了神经网络记忆输入和对数据的过拟合。
根据经验,请记住这一点:瓶颈越小,过拟合的风险就越低。然而,非常小的瓶颈会限制可存储的信息量,这增加了重要信息通过编码器的池化层滑出的机会。
解码器Decoder
最后,解码器是一组上采样和卷积块,用于重建瓶颈的输出。
由于解码器的输入是压缩的知识表示,因此解码器充当“解压缩器”,并从其潜在属性中重建图像。
如何训练自动编码器?
在训练自动编码器之前,需要设置 4 个超参数:
1. 代码大小Code size:代码大小或瓶颈大小是用于优化自动编码器的最重要的超参数。瓶颈大小决定了必须压缩的数据量。这也可以作为正则化术语。
2. 层数Number of layers:与所有神经网络一样,调整自动编码器的一个重要超参数是编码器和解码器的深度。虽然较高的深度会增加模型的复杂性,但较低的深度可以更快地处理。
3. 每层节点数Number of nodes per layer:每层节点数定义了我们每层使用的权重。通常,节点数会随着自动编码器中每个后续层的增加而减少,因为每个层的输入在各层之间变小。
4. 重建损失Reconstruction Loss:我们用于训练自动编码器的损失函数高度依赖于我们希望自动编码器适应的输入和输出类型。如果我们使用图像数据,最常用的重建损失函数是 MSE 损失和 L1 损失。如果输入和输出在 [0,1] 范围内,就像在 MNIST 中一样,我们也可以使用二元交叉熵作为重建损耗。
5种类型的自动编码器
神经网络自动编码器的想法并不新鲜。事实上可追溯到1980年代。自动编码器概念最初用于降维和特征学习,经过多年的发展,现在广泛用于学习数据的生成模型。以下是我们将讨论的五种流行的自动编码器:
- 不完整的自动编码器 Undercomplete autoencoders
- 稀疏自动编码器 Sparse autoencoders
- 收缩式自动编码器 Contractive autoencoders
- 去噪自动编码器 Denoising autoencoders
- 变分自动编码器 Variational Autoencoders
不完整的自动编码器
不完整的自动编码器是最简单的自动编码器类型之一。它的工作方式非常简单:欠完整自动编码器接收图像并尝试预测与输出相同的图像,从而从压缩瓶颈区域重建图像。不完整的自动编码器是真正无监督的,因为它们不采用任何形式的标签,目标与输入相同。
像这样的自动编码器的主要用途是生成潜在空间或瓶颈,它形成了输入数据的压缩替代品,并且可以在需要时借助网络轻松解压缩回来。数据中的这种压缩形式可以建模为降维的一种形式。
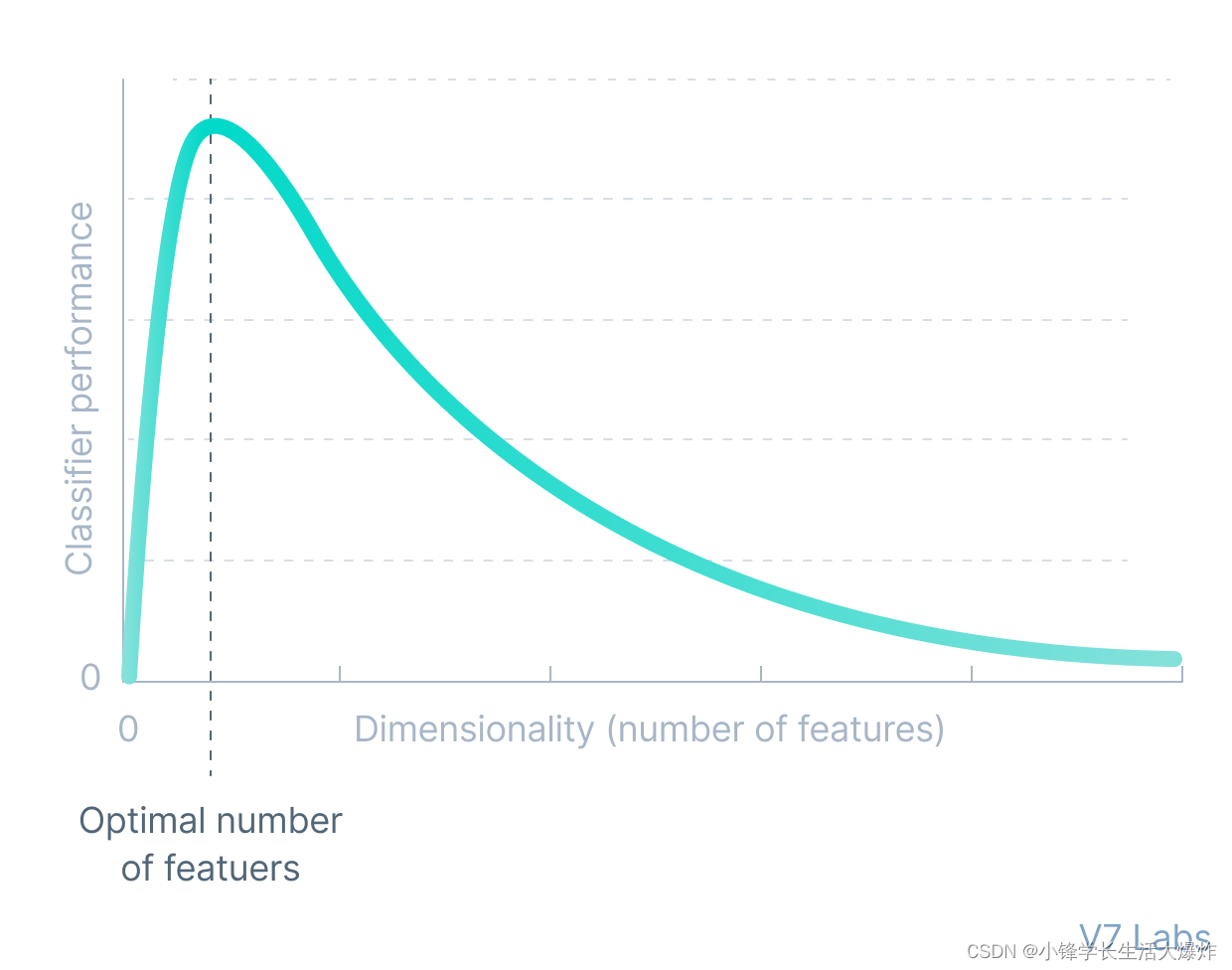
当我们想到降维时,我们往往会想到像 PCA(主成分分析)这样的方法,它们形成一个低维超平面,以高维形式表示数据而不会丢失信息。然而,PCA只能建立线性关系。因此,与不完全自编码器等方法可以学习非线性关系,因此在降维方面表现更好。
这种非线性降维形式,其中自动编码器学习非线性流形,也称为流形学习。
实际上,如果我们从不完整的自动编码器中删除所有非线性激活并仅使用线性层,我们将不完整的自动编码器简化为与 PCA 同等工作的东西。
用于训练不完全自动编码器的损失函数称为重建损失,因为它检查了图像从输入数据中重建的程度。尽管重建损耗可以是任何值,具体取决于输入和输出,但我们将使用 L1 损耗来描述术语(也称为范数损耗),表示为:
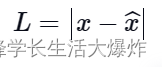
其中 x^ 表示预测输出,x 表示基本事实。
由于损失函数没有明确的正则化项,因此确保模型不记忆输入数据的唯一方法是调节瓶颈的大小和网络这一部分(架构)中隐藏层的数量。
稀疏自动编码器
稀疏自动编码器与不完整的自动编码器类似,因为它们使用相同的图像作为输入和真实值。然而,调节信息编码的手段有很大不同。
虽然通过调节瓶颈的大小来调节和微调不完整的自动编码器,但稀疏自动编码器是通过改变每个隐藏层的节点数量来调节的。由于不可能设计出在其隐藏层上具有灵活节点数量的神经网络,因此稀疏自动编码器通过惩罚隐藏层中某些神经元的激活来工作。换句话说,损失函数有一个项,用于计算已激活的神经元数量,并提供与该数量成正比的惩罚。这种惩罚称为稀疏函数,可防止神经网络激活更多神经元,并充当正则化器。
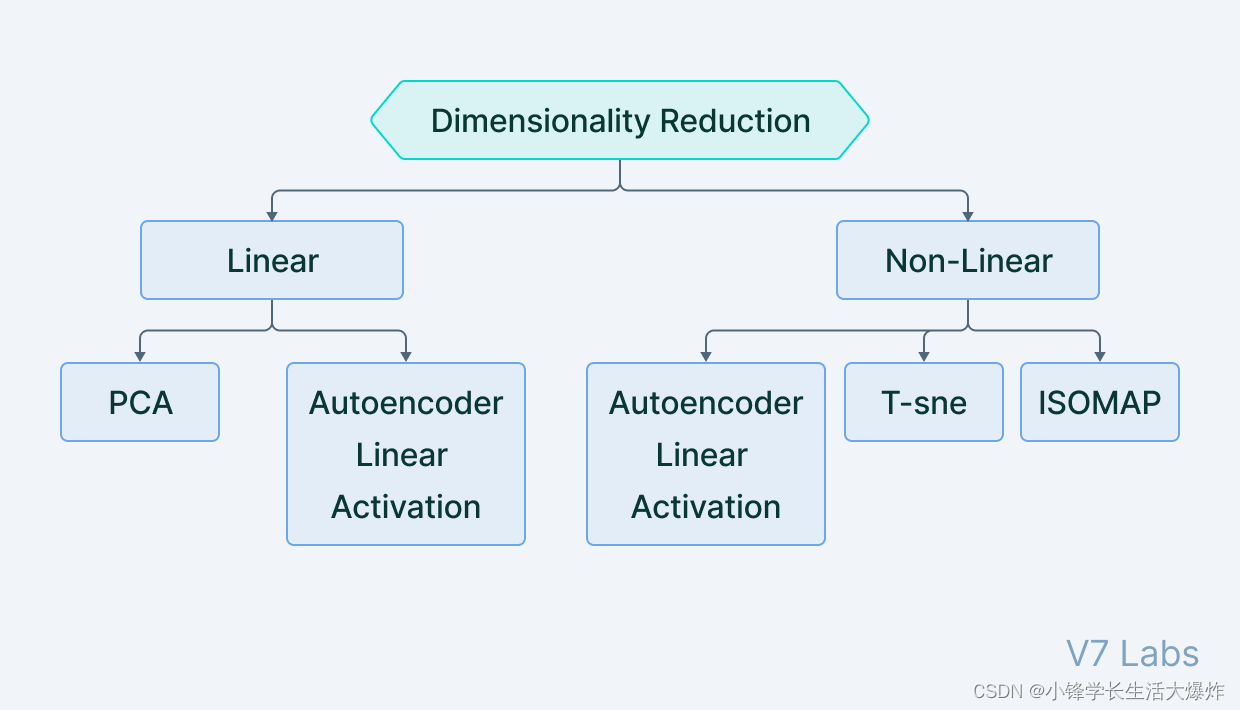
典型的正则化器通过对节点处的权重大小进行惩罚来工作,而稀疏性正则化器通过对激活的节点数进行惩罚来工作。这种形式的正则化允许网络在隐藏层中具有节点,专门用于在训练期间查找图像中的特定特征,并将正则化问题视为独立于潜在空间问题的问题。因此,我们可以在瓶颈处设置潜在空间维数,而不必担心正则化。
有两种主要方法可以将稀疏性正则化器项合并到损失函数中:
- L1 损失:在这里,我们添加稀疏正则化器的大小,就像我们对一般正则化器所做的那样:
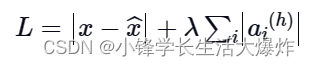
其中 h 表示隐藏层,i 表示小批量中的图像,a 表示激活。
- KL-散度:在本例中,我们一次考虑一组样本的激活,而不是像 L1 损失法那样对它们求和。我们限制了每个神经元在这个集合上的平均激活。将理想分布视为伯努利分布,我们将KL散度包括在损失中,以减少激活的当前分布与理想(伯努利)分布之间的差异:
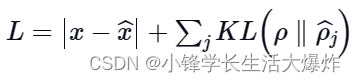

收缩式自动编码器
与其他自动编码器类似,收缩自动编码器执行学习图像表示的任务,同时将其传递到瓶颈并在解码器中重建它。收缩自动编码器还具有正则化项,以防止网络学习恒等式函数并将输入映射到输出中。
收缩型自动编码器的工作原理是,相似的输入应该具有相似的编码和相似的潜在空间表示。这意味着潜在空间不应因输入的微小变化而变化很大。为了训练一个与此约束一起工作的模型,我们必须确保隐藏层激活的导数相对于输入数据很小。

其中 h 表示隐藏层,x 表示输入。
在损失函数(由导数和重构损失的范数形成)中需要注意的重要一点是,这两个项相互矛盾。虽然重建损失希望模型能够分辨两个输入之间的差异并观察数据的变化,但导数的 frobenius 范数表明模型应该能够忽略输入数据的变化。将这两个相互矛盾的条件放入一个损失函数中,使我们能够训练一个网络,其中隐藏层现在只捕获最基本的信息。此信息对于分离图像和忽略本质上非歧视性的信息是必要的,因此并不重要。
总损失函数在数学上可以表示为:
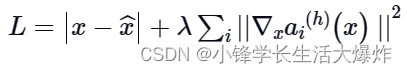
其中 h> 是计算梯度的隐藏层。
对所有训练样本的梯度求和,并取相同的弗罗贝尼乌斯范数。
去噪自动编码器
顾名思义,去噪自动编码器是从图像中去除噪声的自动编码器。与我们已经介绍过的自动编码器相反,这是同类产品中第一个没有输入图像作为其真实值的编码器。
在对自动编码器进行去噪处理时,我们输入图像的嘈杂版本,其中噪声是通过数字更改添加的。噪声图像被馈送到编码器-解码器架构,并将输出与真值图像进行比较。
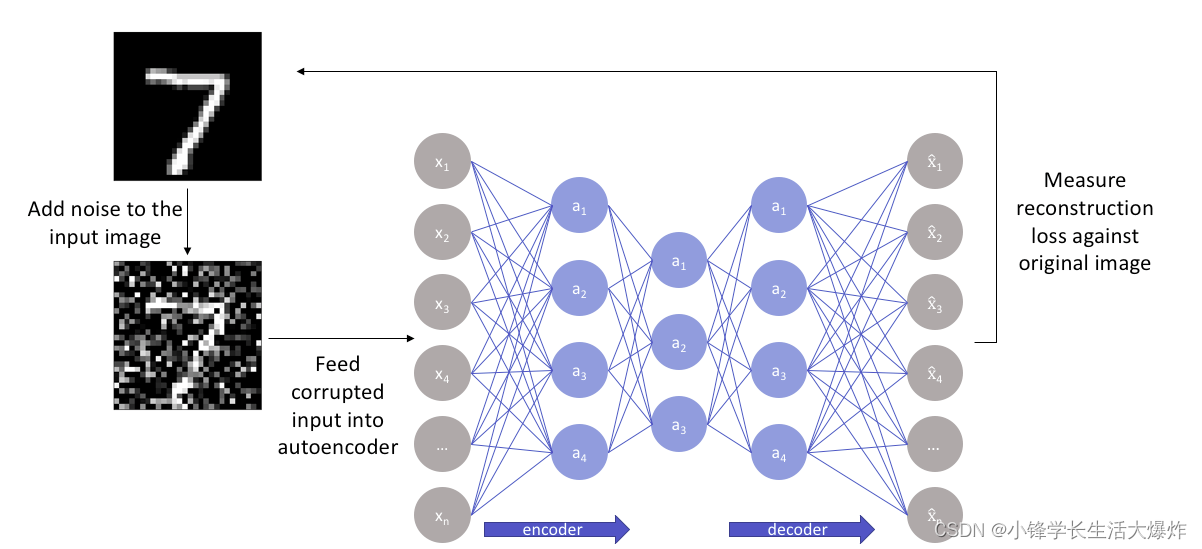
去噪自动编码器通过学习输入的表示来消除噪声,其中噪声可以很容易地被滤除。虽然直接从图像中去除噪声似乎很困难,但自动编码器通过将输入数据映射到低维流形(如在不完整的自动编码器中)来执行此操作,其中噪声滤波变得更加容易。
从本质上讲,去噪自动编码器是在非线性降维的帮助下工作的。这些类型的网络中通常使用的损耗函数是 L2 或 L1 损耗。
变分自动编码器
标准和变分自动编码器学习以称为潜在空间或瓶颈的压缩形式表示输入。因此,训练模型后形成的潜在空间不一定是连续的,实际上可能不容易插值。
例如,这是变分自动编码器从输入中学习的内容:
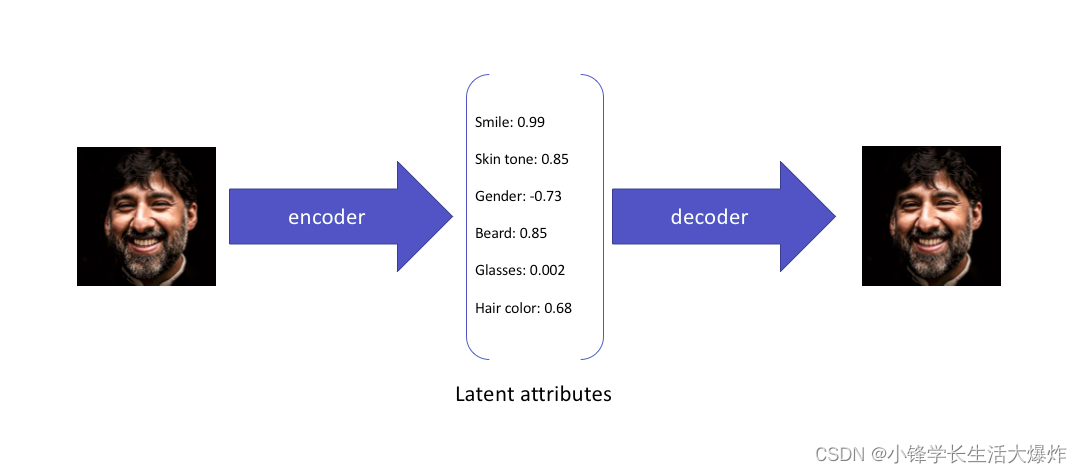
虽然这些属性解释了图像,并可用于从压缩的潜在空间重建图像,但它们不允许以概率方式表达潜在属性。
变分自动编码器处理这个特定主题,并将其潜在属性表示为概率分布,从而形成一个可以轻松采样和插值的连续潜在空间。当输入相同的输入时,变分自动编码器将按以下方式构造潜在属性:
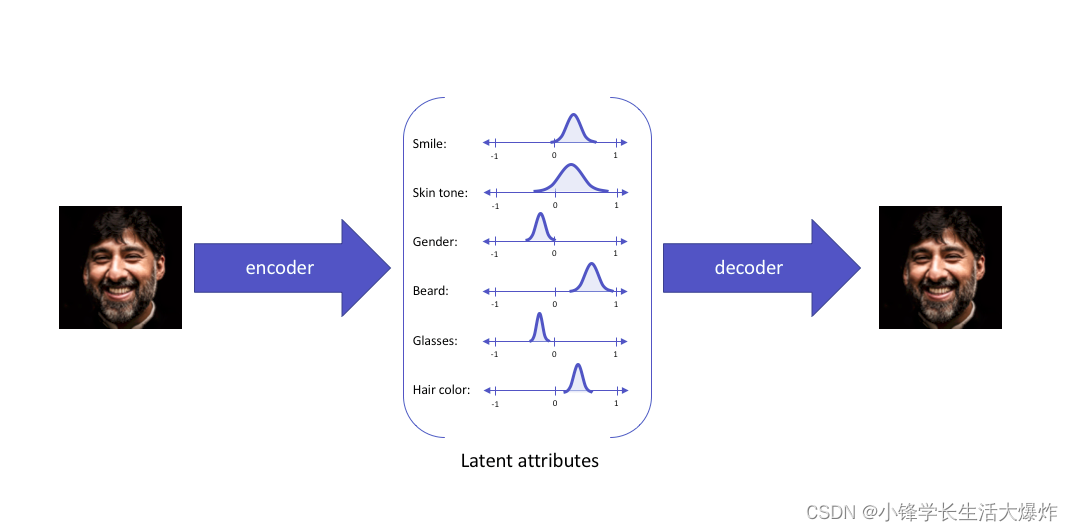
然后从形成的潜在分布中采样潜在属性并馈送到解码器,从而重建输入。将潜在属性表示为概率分布的动机可以通过统计表达式非常容易地理解。
这是如何工作的:我们的目标是确定潜在向量 z 的特征,该向量 z 在给定特定输入的情况下重建输出。实际上,我们想研究给定特定输出 x[p(z|x)] 的潜在向量的特征。虽然在数学上估计分布是不可能的,但一个更简单、更容易的选择是构建一个参数化模型,可以为我们估计分布。它通过最小化原始分布和参数化分布之间的 KL 散度来实现这一点。将参数化分布表示为 q,我们可以推断出图像重建中使用的可能潜在属性。假设前一个 z 是一个多变量高斯模型,我们可以将参数化分布构建为包含两个参数(均值和方差)的分布。然后对相应的分布进行采样并馈送到解码器,然后解码器继续从采样点重建输入。但是,虽然这在理论上看起来很容易,但实现起来是不可能的,因为在将数据馈送到解码器之前,无法为执行的随机采样过程定义反向传播。
为了克服这个障碍,我们使用了重新参数化技巧——一种巧妙定义的方法,可以绕过神经网络的采样过程。这到底是怎么回事?在重参数化技巧中,我们从单位高斯随机采样一个值ε,然后通过潜在分布方差进行缩放,并将其平移到相同的均值μ。现在,我们抛弃了采样过程,将其视为在反向传播管道处理之外完成的工作,采样值ε就像模型的另一个输入一样,在瓶颈处馈送。
我们所获得的图解可以表示为:
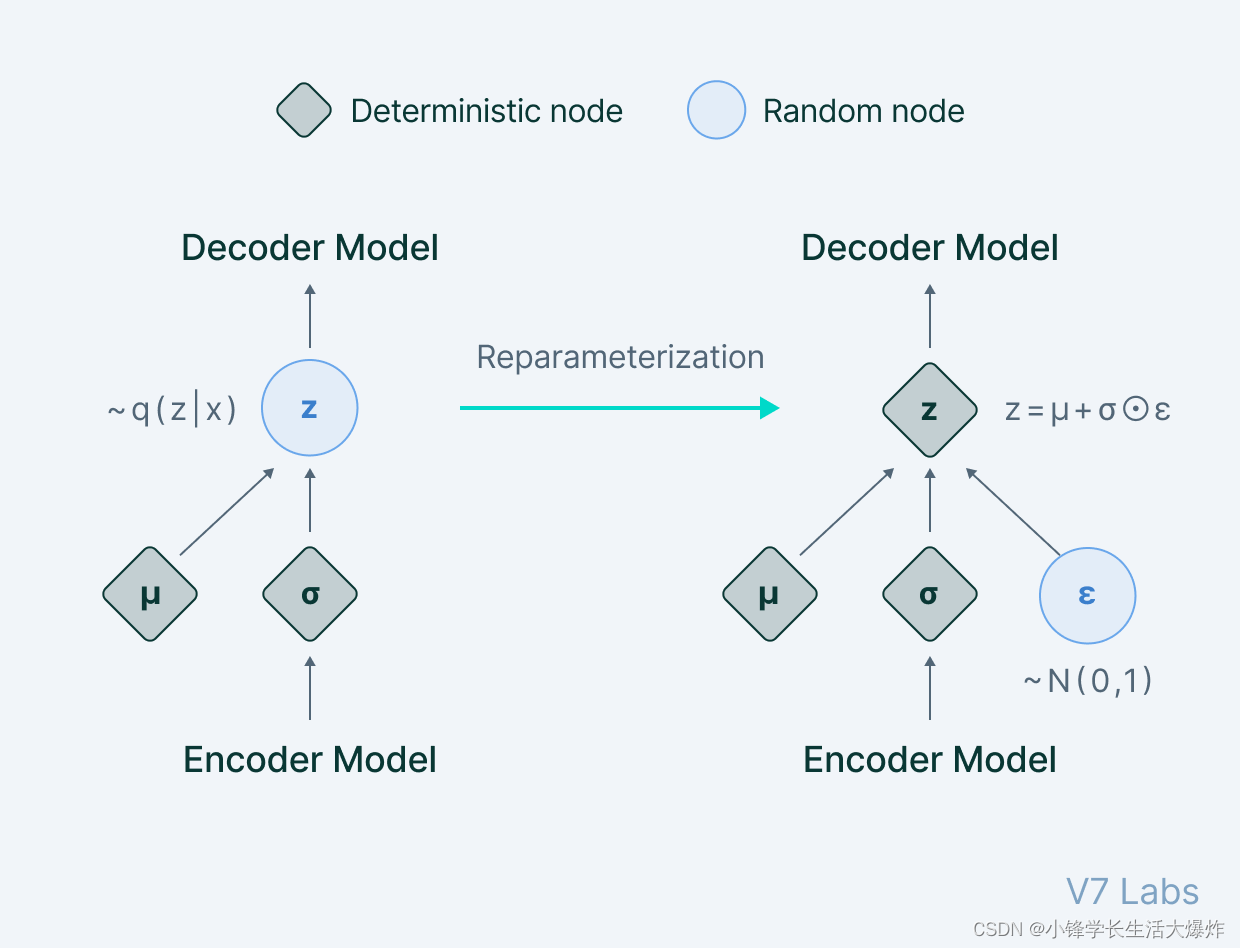
因此,变分自动编码器允许我们学习输入数据的平滑潜伏状态表示。为了训练 VAE,我们使用两个损失函数:重建损失和另一个是 KL 散度。虽然重建损失使分布能够正确描述输入,但通过只关注最小化重建损失,网络学习的分布非常窄,类似于离散的潜在属性。KL 散度损失阻止网络学习窄分布,并试图使分布更接近单位正态分布。
总结的损失函数可以表示为:
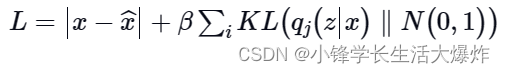
其中 N 表示正态单位分布, B 表示加权因子。
变分自动编码器的主要用途可以在生成建模中看到。从训练的潜在分布中采样并将结果提供给解码器可能会导致在自动编码器中生成数据。
通过训练变分自动编码器生成的 MNIST 数字示例如下所示:

自动编码器的应用
1. 降维
欠完全自动编码器是用于降维的自动编码器。这些可以用作降维的预处理步骤,因为它们可以执行快速准确的降维而不会丢失太多信息。
此外,虽然像 PCA 这样的降维过程只能执行线性降维,但不完整的自动编码器可以执行大规模的非线性降维。
2. 图像去噪
去噪自动编码器等自动编码器可用于执行高效且高精度的图像降噪。与传统的去噪方法不同,自动编码器不会搜索噪声,而是通过学习图像的表示从输入到它们的噪声数据中提取图像。然后对表示进行解压缩以形成无噪声图像。因此,去噪自动编码器可以对传统方法无法去噪的复杂图像进行去噪。
3. 图像和时间序列数据的生成
变分自动编码器可用于生成图像和时间序列数据。可以对自动编码器瓶颈处的参数化分布进行随机采样,生成潜在属性的离散值,然后转发给解码器,从而生成图像数据。VAE 还可用于对时间序列数据(如音乐)进行建模。
4. 异常检测
不完整的自动编码器也可用于异常检测。例如,考虑一个在特定数据集 P 上训练的自动编码器。对于为训练数据集采样的任何图像,自动编码器必然会提供较低的重建损失,并且应该按原样重建图像。
但是,对于训练数据集中不存在的任何图像,自动编码器无法执行重建,因为潜在属性不适用于网络从未见过的特定图像。因此,异常值图像会发出非常高的重建损失,并且借助适当的阈值可以很容易地识别为异常。
自动编码器简介:关键要点
让我们快速回顾一下您在本指南中学到的所有内容:
- 自动编码器是一种用于神经网络的无监督学习技术,它通过训练网络忽略信号“噪声”来学习有效的数据表示(编码)。
- 自动编码器可用于图像去噪、图像压缩,在某些情况下,甚至可用于生成图像数据。
- 虽然自动编码器乍一看似乎很容易(因为它们具有非常简单的理论背景),但让它们学习有意义的输入表示是相当困难的。
- 与 VAE 和 DAE 相比,像不完整的自动编码器和稀疏自动编码器这样的自动编码器在计算机视觉中没有大规模的应用,自 2013 年提出以来仍在工作中使用(由 Kingmaet 等人提出)。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-01-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号