Uber CacheFront:每秒 40 M 的读取,延迟显著降低

Uber CacheFront:每秒 40 M 的读取,延迟显著降低

深度学习与Python
发布于 2024-03-07 16:40:51
发布于 2024-03-07 16:40:51
作者 | Eran Stiller
译者 | 平川
策划 | Tina
Uber 为其内部分布式数据库 Docstore 开发了一种创新性的缓存解决方案 CacheFront。CacheFront 可以实现每秒超过 40M 的在线存储读取,并实现了可观的性能提升,包括 P75 延迟减少 75%,P99.9 延迟减少 67%。这证明它在提高系统效率和可扩展性方面非常有效。
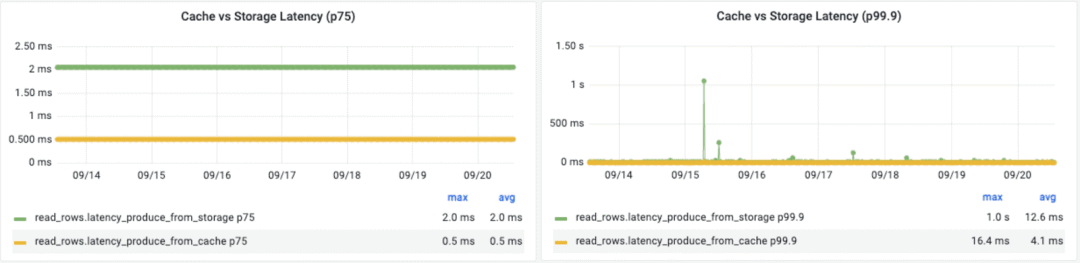
缓存与存储引擎延迟对比(图片来源 (https://www.uber.com/en-AU/blog/how-uber-serves-over-40-million-reads-per-second-using-an-integrated-cache/)
Uber 工程师 Preetham Narayanareddy、Eli Pozniansky、Zurab Kutsia、Afshin Salek 和 Piyush Patel 描述了他们开发 CacheFront 时所面临的挑战:
Uber 的大多数微服务都使用基于磁盘存储的数据库来持久化数据。然而,每个数据库都面临着为低读取延迟的高可扩展性应用程序提供服务的挑战。 当一个用例所需的读取吞吐量比我们现有的任何用户都要高时,就会到达“沸点”。Docstore 可以满足需求,因为它由 NVMe SSD 支持,可以提供低延迟和高吞吐量。然而,在上述场景中使用 Docstore 成本过高,并且会面临许多扩展和运营方面的挑战。
为了克服这些限制,Uber 的一些团队会使用 Redis 缓存来加快读访问速度。然而,每个团队都必须为各自的服务单独配置和维护 Redis 缓存。他们还必须针对自己的用例实现失效逻辑。在区域故障转移中,团队要么得维护缓存复制以保持热状态,要么就得承受在其他区域预热缓存时的高延迟。CacheFront 的目标之一就是集中实现并管理这些特性,使团队能够专注于他们的核心逻辑。
由于 Uber 想要从存储引擎中单独启用和扩展 Redis 缓存,同时保持 API 与之前的 Docstore 版本兼容,他们决定将其集成到 Docstore 的查询引擎中。查询引擎是一个无状态组件,充当基于 MySQL 的有状态存储引擎的前端。
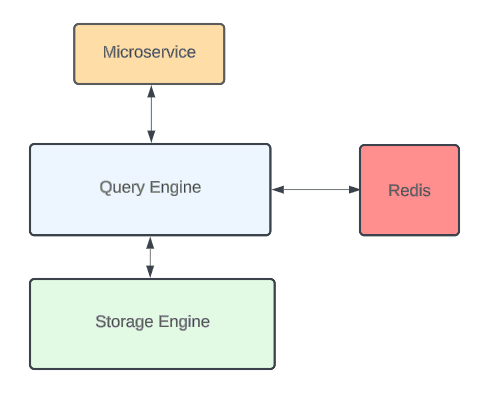
CacheFront 设计概览(图片来源 https://www.uber.com/en-AU/blog/how-uber-serves-over-40-million-reads-per-second-using-an-integrated-cache/)
CacheFront 使用 cache aside 策略来实现缓存读取。查询引擎接收一个读取一行或多行的请求。如果缓存已启用,它就会尝试从 Redis 中获取行并将响应流发送给用户。它从存储引擎中检索剩余的行(如果有的话),并将剩余的行异步填充到 Redis 中,同时将它们以流的方式传输给用户。
Uber 工程师利用 Docstore 集成的 变更数据捕获(CDC)引擎来处理缓存失效。当 CDC 识别到数据库更新时,则 Redis 中相关的行要么更新,要么失效。因此,借助标准的生存时间(TTL)机制,Uber 可以在数据库更新后的几秒钟内(而不是几分钟)实现缓存一致。此外,CDC 还可以避免未提交的事务污染缓存。
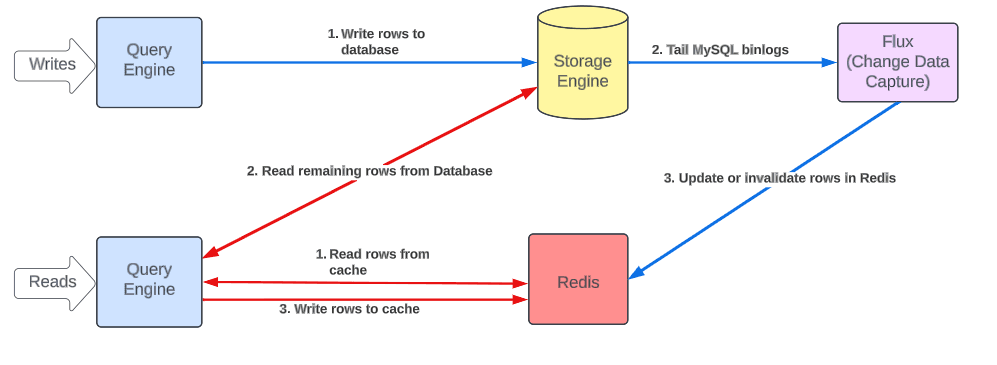
缓存失效时 CacheFront 的读写路径(图片来源 https://www.uber.com/en-AU/blog/how-uber-serves-over-40-million-reads-per-second-using-an-integrated-cache/)
为了度量缓存与数据库的一致性水平,Uber 工程师添加了一种特殊的模式,将读请求投射到缓存中。当读回数据时,它会将缓存数据和数据库数据进行比较并验证它们是否相同。任何不匹配都会被记录下来并作为指标发出。使用基于 CDC 的缓存失效机制,他们测得的缓存一致性为 99.99%。
为了确保高可用性和容错性,Uber Docstore 采用两地双活部署。然而,这种设置给 CacheFront 带来了挑战,特别是要在两个区域维持“热”缓存以防止因故障转移期间缓存丢失而导致的数据库负载增加。为了解决这个问题,Uber 工程师跟踪 Redis 写入流,并将数据行的键(而非值)复制到远程区域。在远程区域中,复制引擎会在缓存未命中时从存储中获取最新值。
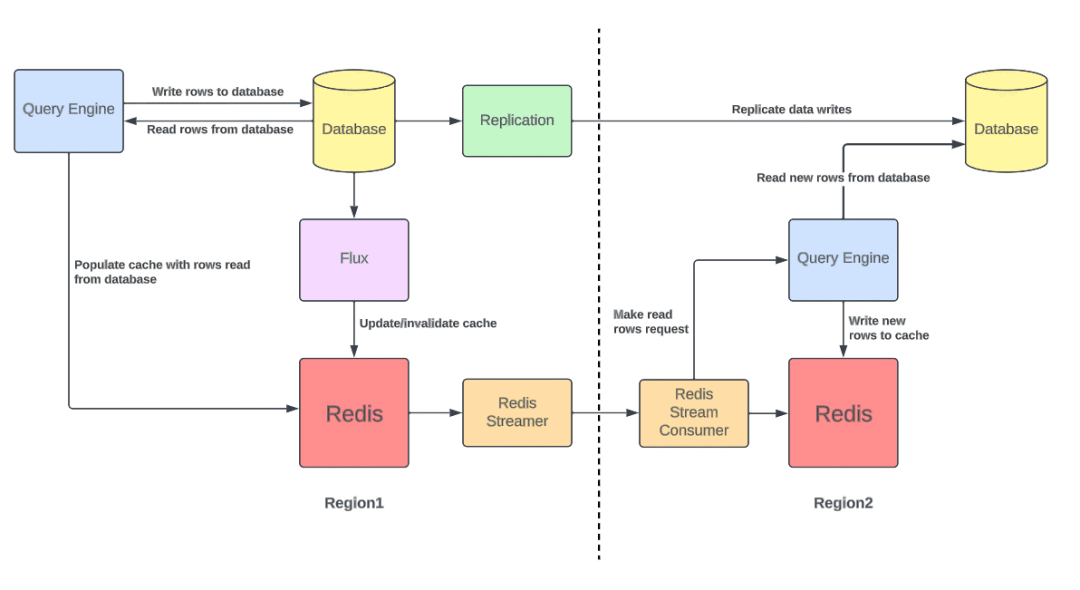
缓存预热(图片来源 https://www.uber.com/en-AU/blog/how-uber-serves-over-40-million-reads-per-second-using-an-integrated-cache/)
Uber 在为 Redis 操作设置最佳超时时间时遇到了挑战。时间过短可能会导致请求失败过早以及不必要的数据库负载,而时间过长可能会对延迟产生不利影响。为了解决这个问题,Uber 实现了自适应超时,可以自动基于性能数据动态调整 Redis 操作超时时间。
这种方法可以确保绝大多数请求(99.99%)从缓存中得到快速服务,并提供了一种机制,可以及时取消少数超时的请求并将其重定向到数据库,从而避免手动调整以及优化缓存效率和数据库负载管理的工作。
原文链接:
https://www.infoq.com/news/2024/02/uber-cachefront/
声明:本文为 InfoQ 翻译,未经许可禁止转载。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号