「最佳实践」腾讯云 ES 8 向量化语义混合检索测试指南
原创

说明
本文描述问题及解决方法同样适用于 腾讯云 Elasticsearch Service(ES)。
另外使用到:腾讯云 云服务器(Cloud Virtual Machine,CVM)
声明
本文使用的文本样本数据系混元大模型生成的商品数据。
环境配置
客户端环境
● 版本
CVM 镜像:CentOS 7.9 64位 | img-l8og963d | 20GiB
Linux环境:Centos 7.9
Python:3.9.12
Elasticsearch 服务端环境
● 版本
ES 版本:8.11.3(腾讯云 Elasticsearch Service(ES) 基础版)
1. 部署客户端环境
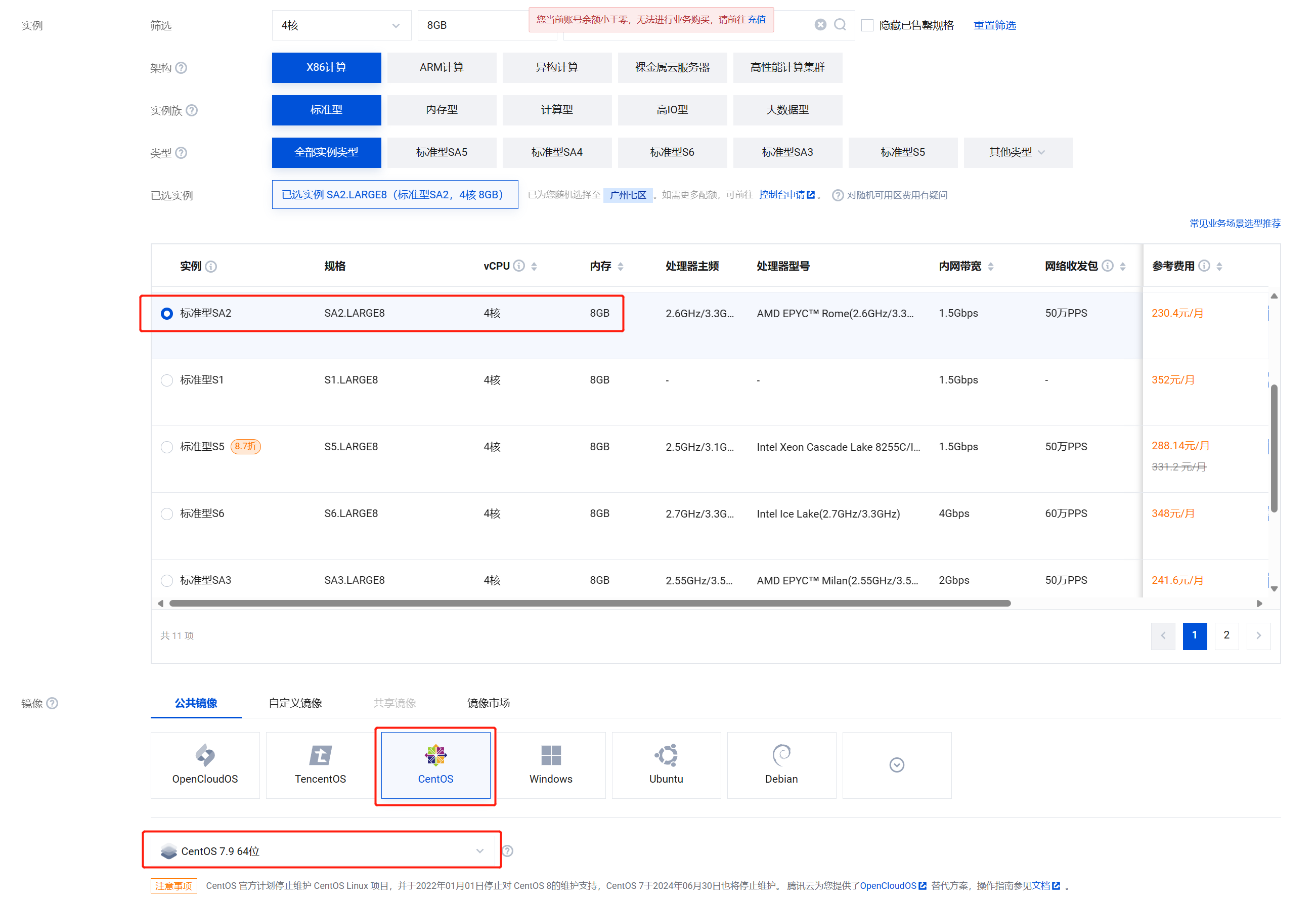
2. 创建 ES 集群
版本这里我们选择 8.11.3 基础版,也可以选择白金版,白金版有更多的 X-PACK 高级特性,可以根据实际需求选择基础版还是白金版:

配置建议至少选择(高IO型 16核64G)3个节点,也可以根据实际需求进行调整:

提交集群构建之后,大概需要20分钟左右可以完成。
集群创建完成之后,为了方便测试,需要移步 ES实例 > 访问快照 > 可视化访问控制 > 公网访问策略,将白名单修改为 0.0.0.0/0

注意:此操作是为了方便测试,生产环境还需谨慎操作。
3. 客户端准备工作
Python 环境部署
一键安装环境:
yum install conda -y; conda init; source ~/.bashrc; echo y | conda create -n es_vector python=3.9.12; conda activate es_vector
安装 Python 依赖包
pip install altair==5.2.0 attrs==23.2.0 blinker==1.7.0 cachetools==5.3.2 certifi==2023.11.17 charset-normalizer==3.3.2 click==8.1.7 elastic-transport==8.11.0 elasticsearch==8.11.1 filelock==3.13.1 fsspec==2023.12.2 gitdb==4.0.11 GitPython==3.1.41 huggingface-hub==0.20.2 idna==3.6 importlib-metadata==7.0.1 Jinja2==3.1.3 joblib==1.3.2 jsonschema==4.20.0 jsonschema-specifications==2023.12.1 markdown-it-py==3.0.0 MarkupSafe==2.1.3 mdurl==0.1.2 mpmath==1.3.0 networkx==3.2.1 nltk==3.8.1 numpy==1.26.3 nvidia-cublas-cu12==12.1.3.1 nvidia-cuda-cupti-cu12==12.1.105 nvidia-cuda-nvrtc-cu12==12.1.105 nvidia-cuda-runtime-cu12==12.1.105 nvidia-cudnn-cu12==8.9.2.26 nvidia-cufft-cu12==11.0.2.54 nvidia-curand-cu12==10.3.2.106 nvidia-cusolver-cu12==11.4.5.107 nvidia-cusparse-cu12==12.1.0.106 nvidia-nccl-cu12==2.18.1 nvidia-nvjitlink-cu12==12.3.101 nvidia-nvtx-cu12==12.1.105 packaging==23.2 pandas==2.1.4 pillow==10.2.0 protobuf==4.25.2 pyarrow==14.0.2 pydeck==0.8.1b0 Pygments==2.17.2 python-dateutil==2.8.2 pytz==2023.3.post1 PyYAML==6.0.1 referencing==0.32.1 regex==2023.12.25 requests==2.31.0 rich==13.7.0 rpds-py==0.17.1 safetensors==0.4.1 scikit-learn==1.3.2 scipy==1.11.4 sentence-transformers==2.2.2 sentencepiece==0.1.99 six==1.16.0 smmap==5.0.1 streamlit==1.30.0 sympy==1.12 tenacity==8.2.3 threadpoolctl==3.2.0 tokenizers==0.15.0 toml==0.10.2 toolz==0.12.0 torch==2.1.2 torchvision==0.16.2 tornado==6.4 tqdm==4.66.1 transformers==4.36.2 triton==2.1.0 typing_extensions==4.9.0 tzdata==2023.4 tzlocal==5.2 urllib3==2.1.0 validators==0.22.0 watchdog==3.0.0 zipp==3.17.0 pypinyin==0.51.0这一步需要下载很多依赖,安装时间会比较久,需要耐心等待。
4. 下载整合包
已将依赖模型及脚本打包成 整合包,可下载后上传至客户端服务器家目录:/root

解压整合包
已将整合包压缩成 了 ZSTD 格式,该格式的好处是压缩/解压缩性能极高,所以解压也需要使用 ZSTD 算法解压。
安装 zstd 命令:
yum install -y zstd执行解压:
zstd -T0 -d tencent-es_vector.tzst && tar -xvf tencent-es_vector.tar && rm -rf tencent-es_vector.tar一键复制命令进行:解压 -> 解档 -> 删除归档包 ,然后我们可以得到一个整合包目录:
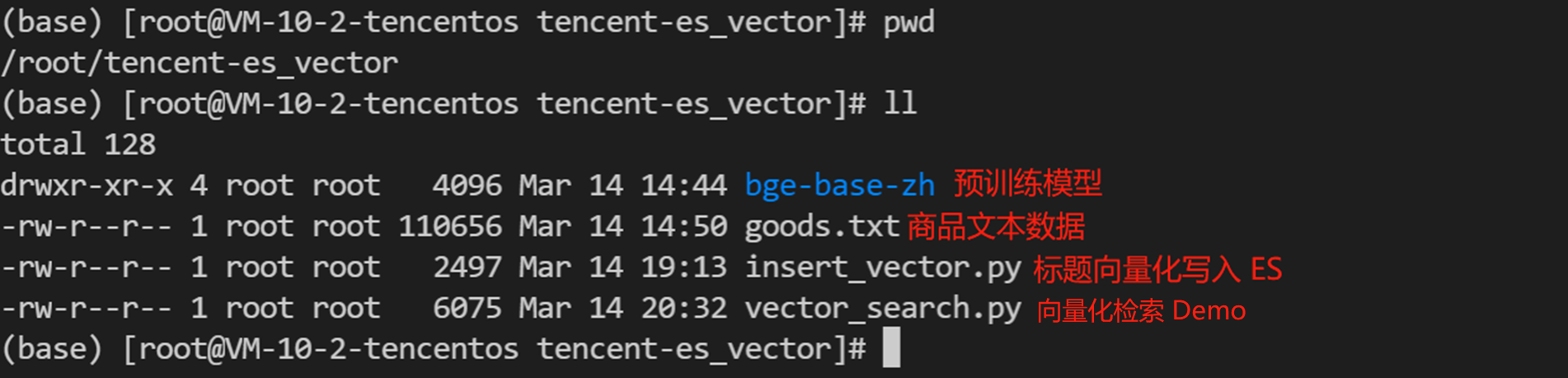
一共1个目录,3个文件:
● bge-base-zh:预训练 Embedding 中文推理模型
● goods.txt:商品数据
● insert_vector.py:通过预训练模型进行推理,生成向量化数据写入 ES
● vector_search.py:将查询的关键词推理转化成向量,然后对 ES 发起向量检索
5. Elasticsearch 准备工作
定义模板
执行模板创建:
PUT _template/goods_vector
{
"index_patterns": [
"goods_vector*"
],
"settings": {
"number_of_shards": 6
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"price": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"specs": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"colors": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"versions": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"title_vector": {
"type": "dense_vector",
"similarity": "cosine",
"index": true,
"dims": 768,
"element_type": "float",
"index_options": {
"type": "hnsw",
"m": 16,
"ef_construction": 128
}
}
}
}
}
返回 "acknowledged": true 即提交成功。
6. 数据生成
这里我们使用预训练模型进行推理,并将数据写入到ES
cd /root/tencent-es_vector/
vim insert_vector.py修改配置信息:es_password es_host
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
from sentence_transformers import SentenceTransformer
from elasticsearch.helpers import BulkIndexError
import torch
from datetime import datetime
import json
es_username = 'elastic'
es_password = '******' # 修改ES密码
es_host = '10.0.2.217' # 修改ES HOST
es_port = 9200
# 加载模型
model = SentenceTransformer(r'bge-base-zh') # 模型相对路径
if torch.cuda.is_available():
model = model.to(torch.device("cuda"))
es = Elasticsearch(
hosts=[{'host': es_host, 'port': es_port, 'scheme': 'http'}],
basic_auth=(es_username, es_password),
)
# 读取文本
file_path = 'goods.txt'
index_name = 'goods_vector'
def gen_vector(sentences):
embeddings = model.encode(sentences, normalize_embeddings=True)
return embeddings
def parse_date(date_str):
return datetime.strptime(date_str, "%Y 年 %m 月").isoformat()
def read_data(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
data = json.loads(line.strip())
specs = data["规格参数"]
product_id = data["商品ID"]
brand = specs["主体"]["品牌"]
title = data["标题"]
price = data["商品价格"]
launch_date = specs["主体"]["上市时间"]
colors = data["商品颜色"]
versions = data["商品版本"]
product_type = data["类型"]
yield {
'_index': index_name,
# '_id': product_id,
'_source': {
'id': product_id,
'brand': brand,
'title': title,
'price': price,
'specs': str(specs),
'launch_date': parse_date(launch_date),
'colors': colors,
'versions': versions,
'type': product_type,
'title_vector': gen_vector(title)
}
}
# 执行批量插入
def bulk_insert(file_path, chunk_size=5000):
data = read_data(file_path)
try:
success, _ = bulk(es, data, chunk_size=chunk_size, stats_only=True)
print(f"Successfully indexed {success} documents.")
except BulkIndexError as e:
print(f"{len(e.errors)} document(s) failed to index.")
for error in e.errors:
print("Error details:", error)
bulk_insert(file_path)执行文本导入:
cd /root/tencent-es_vector/
python insert_sentence.py导入完成后可以在 kibana 中检索到数据:
GET goods_vector/_search
{
"_source": {
"excludes": "title_vector"
}
}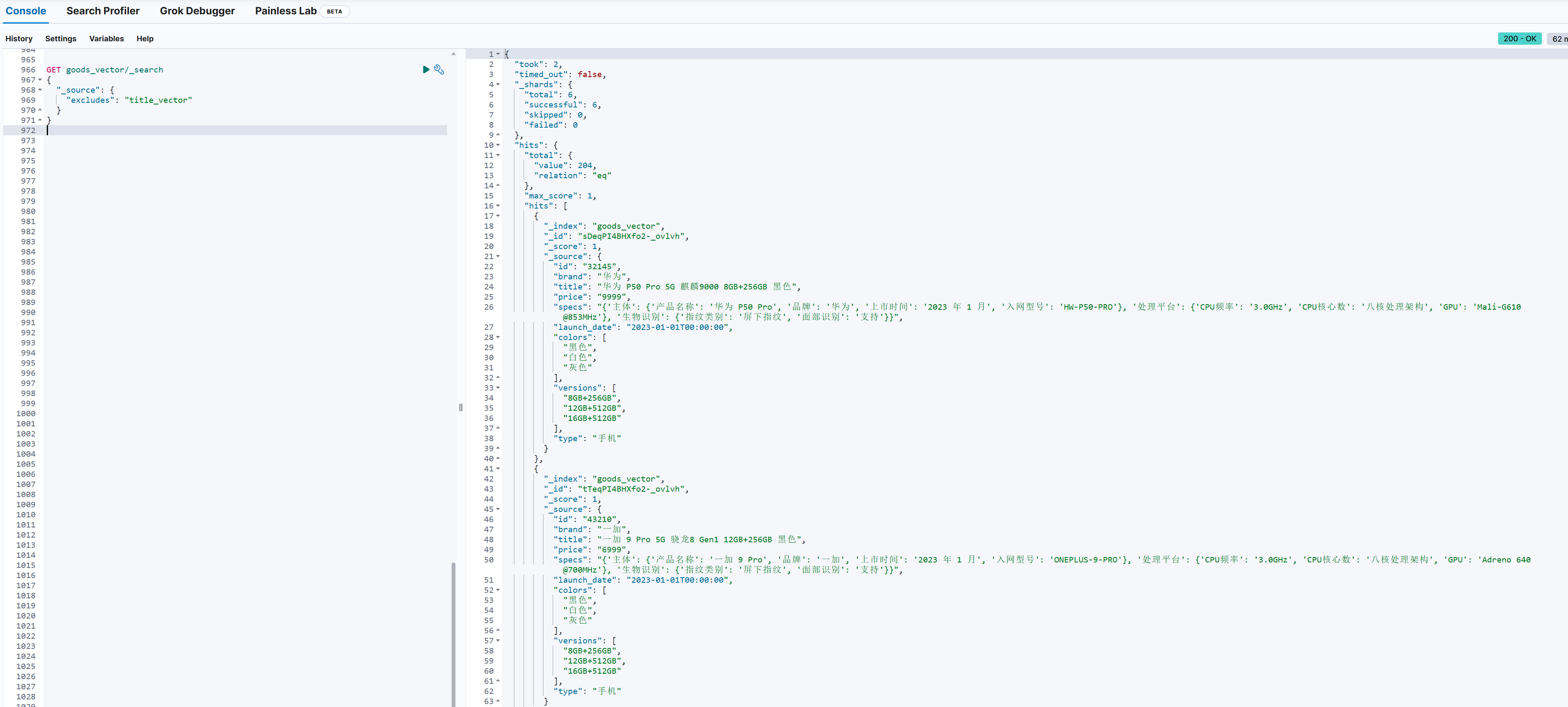
查询有返回则说明数据已经开始导入。
7. 语义检索
所有准备工作就绪,下面将演示向量检索,我们分别用向量检索和分词检索测试两者的检索效果:
cd /root/tencent-es_vector/
vim vector_search.py修改配置信息:password host
import torch, streamlit as st
from sentence_transformers import SentenceTransformer
from elasticsearch import Elasticsearch
from collections import OrderedDict
import json
from datetime import datetime
from pypinyin import lazy_pinyin
username = 'elastic'
password = '******' # 修改为ES密码
host = 'http://10.0.2.217:9200' # 修改为ES URL
index = 'goods_vector'
# 加载模型
model = SentenceTransformer(r'bge-base-zh') # 模型相对路径
if torch.cuda.is_available():
# 使用GPU推理
model = model.to(torch.device("cuda"))
def parse_date(date_str):
date = datetime.strptime(date_str, "%Y-%m-%dT%H:%M:%S")
return date.strftime("%Y年%m月")
# 使用k-NN搜索
def knn_search(es, index_name, vector):
knn = [{
"field": "title_vector",
"query_vector": vector,
"k": 40,
"num_candidates": 200
}]
resp = es.search(
index=index_name,
knn=knn,
source={"excludes": "title_vector"})
return resp
# 使用混合搜索
def mix_search(es, index_name, query_text, query_pinyin, knn):
resp = es.search(
index=index_name,
knn=knn,
size=10,
source={"excludes": "title_vector"})
return resp
# 使用混合搜索聚合
def mix_aggs_search(es, index_name, query_text, query_pinyin, knn):
aggs = {
"count_group_by": {
"terms": {
"field": "brand"
}
}
}
resp = es.search(
index=index_name,
knn=knn,
aggs=aggs,
size=0,
source={"excludes": "title_vector"})
return resp
# 生成句子向量
def gen_vector(sentences):
embeddings = model.encode(sentences, normalize_embeddings=True)
return embeddings
# 创建界面
st.set_page_config(layout="wide")
st.markdown("<h1 style='text-align:center;'>腾讯云 Elaticsearch 8 向量检索</h1>", unsafe_allow_html=True)
with st.form("chat_form"):
query = st.text_input("请输入文本:")
submit_button = st.form_submit_button("查询")
# 连接ES
es = Elasticsearch(hosts=[host],
basic_auth=(username, password))
def find_keyword_in_text(text, keywords):
for keyword in keywords:
if keyword in text:
return keyword
return ""
keywords = [
"华为", "苹果", "小米", "OPPO", "vivo", "三星", "一加", "诺基亚", "Realme", "荣耀",
"谷歌", "锤子科技", "HUAWEI", "LG", "ONEPLUS", "SAMSUNG", "VIVO", "XIAOMI",
"MOTOROLA", "NOKIA", "Redmi", "SONY", "魅族"
]
# 当点击查询按钮时
if submit_button:
vectors = gen_vector(query)
found_keyword = find_keyword_in_text(query, keywords)
query_pinyin = ''.join(lazy_pinyin(found_keyword))
knn = [
{
"field": "title_vector",
"query_vector": vectors,
"k": 40,
"num_candidates": 200,
"filter": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"specs": {
"query": found_keyword
}
}
},
{
"match": {
"specs": {
"query": query_pinyin
}
}
}
]
}
}
]
}
},
"boost": 0.6
}
]
# 调用knn检索
knn_resp = knn_search(es, index, vectors)
# 调用混合检索
mix_resp = mix_search(es, index, query, query_pinyin, knn)
# 调用混合聚合检索
mix_aggs_resp = mix_aggs_search(es, index, query, query_pinyin, knn)
# 创建三列
col1, col2, col3 = st.columns(3)
counter = 1
with col1:
st.write("### 向量检索结果")
for hit in knn_resp['hits']['hits']:
fields = hit['_source']
ordered_fields = OrderedDict()
ordered_fields['title'] = fields['title']
ordered_fields['price'] = fields['price']
ordered_fields['launch_date'] = parse_date(fields['launch_date'])
ordered_fields['type'] = fields['type']
ordered_fields['versions'] = fields['versions']
ordered_fields['specs'] = fields['specs']
json_output = json.dumps(ordered_fields, ensure_ascii=False)
with st.container():
st.text(f"{counter}. {json_output}")
counter += 1
counter = 1
with col2:
st.write("### 混合检索结果")
for hit in mix_resp['hits']['hits']:
fields = hit['_source']
ordered_fields = OrderedDict()
ordered_fields['title'] = fields['title']
ordered_fields['price'] = fields['price']
ordered_fields['launch_date'] = parse_date(fields['launch_date'])
ordered_fields['type'] = fields['type']
ordered_fields['versions'] = fields['versions']
ordered_fields['specs'] = fields['specs']
json_output = json.dumps(ordered_fields, ensure_ascii=False)
with st.container():
st.text(f"{counter}. {json_output}")
counter += 1
counter = 1
with col3:
st.write("### 混合检索聚合结果")
for bucket in mix_aggs_resp['aggregations']['count_group_by']['buckets']:
key = bucket['key']
doc_count = bucket['doc_count']
with st.container():
st.text(f"{counter}. {key}: {doc_count} 条")
counter += 1启动 streamlit 页面服务:
cd /root/tencent-es_vector/
streamlit run vector_search.py
访问返回的公网地址,进行向量测试。
检索效果测试

我们模拟用户在商城搜索栏输入一个手机型号:小米 12 pro max
● 向量检索结果可能会召回不相关的内容
● 而使用 ES 的混合检索,利用前置过滤,在提高效率的同时,可以大幅提升召回率
● ES 也支持在在混合检索场景使用聚合查询
8. 总结
从检索效果可以直观看出,使用纯向量检索,往往是达不到业务需求的。如果想提升召回率,则需要配合混合检索,不仅可以提前过滤一些不相关的内容,对性能有一定提升。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号