FINAL: 扩展MLP为因子化交互层用于CTR预测


标题: FINAL: Factorized Interaction Layer for CTR Prediction 地址:https://dl.acm.org/doi/10.1145/3539618.3591988 公司:华为 会议:SIGIR 2023 代码:https://github.com/reczoo/FuxiCTR
1. 导读
本文所提方法为ctr预估方向,针对如何进行高效,有效的特征交互提出FINAL模型,整体模型比较简单,所以这里的导读就省略了,直接看方法部分即可。
2.方法

alt text
2.1 FINAL块
如何以最小的模型深度实现足够高的交互阶数对性能和效率都很重要。基于快速幂算法思想,作者设计了一种分层特征交互机制来实现指数级增长。在每个层次结构中,使用因子交互层通过多次乘法运算来提高特征交互度。
为第
层的输入,则从图2中也可以很清晰的得出计算逻辑,后一个块会和前一个计算得到的结果进行element-wise乘法进行特征交互,最后做sum pooling得到最终的输出。
2.2 知识迁移
通常可以使用多个FINAL块(比如2个)来学习来自不同视角的特征交互。使用不同的linear层将block的输出转换为logits(图2中的
)。求均值再经过sigmoid后得到
,然后对应是否转化标签可以构建交叉熵损失函数
同时,为了促进不同FINAL块之间的知识共享,采用自知识蒸馏(self-knowledged distillation),看着名字很神奇,执行起来很简单。使用前面得到的聚合分数
来知道两个block,得到对应的交叉熵损失函数,
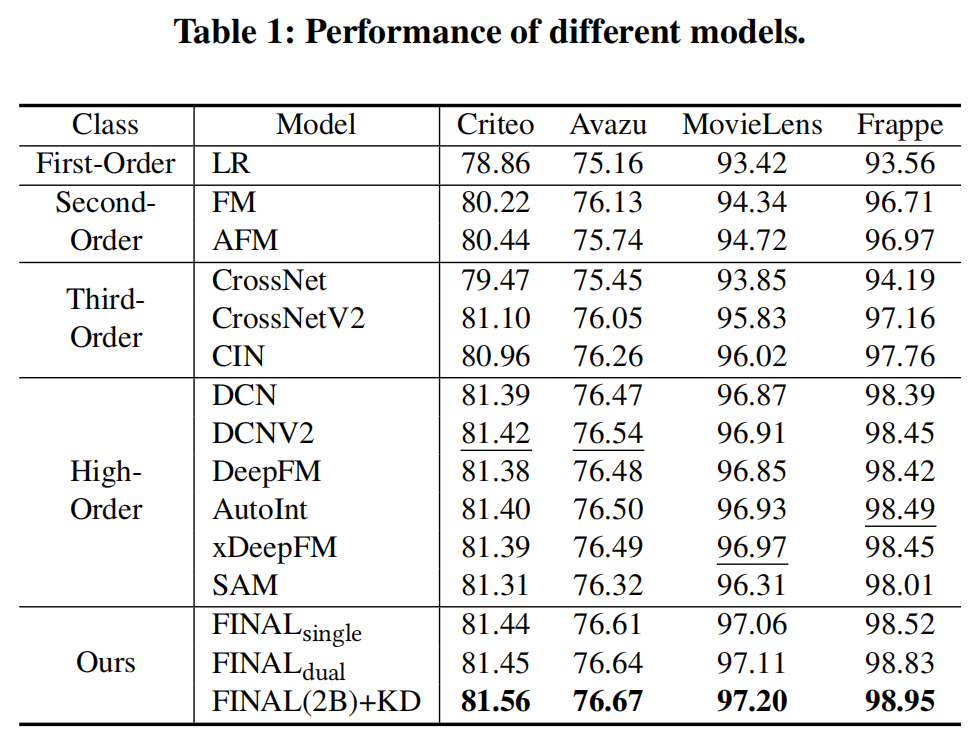
3. 结果

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
