玩转 AIGC:Ubuntu 24.04 LTS 安装 Ollama, 体验大模型 Llama3 8B 和 Qwen 32B
原创
玩转 AIGC:Ubuntu 24.04 LTS 安装 Ollama, 体验大模型 Llama3 8B 和 Qwen 32B
原创
运维有术
发布于 2024-05-09 17:42:26
发布于 2024-05-09 17:42:26
玩转 AIGC:Ubuntu 24.04 LTS 安装 Ollama, 体验大模型 Llama3 8B 和 Qwen 32B
2024 年云原生运维实战文档 99 篇原创计划 第 016 篇 |玩转 AIGC「2024」系列 第 005 篇
你好,欢迎来到运维有术。
今天分享的内容是 玩转 AIGC「2024」 系列文档中的 Ubuntu 24.04 LTS 安装 Ollama, 体验大模型 Llama3 8B 和 Qwen 32B。
本文将详细介绍如何在 Ubuntu 24.04 LTS 中,采用 Docker 容器部署最流行的管理和运行大模型的工具 Ollama。
同时,我们会利用 Ollama 下载大模型 Llama3 8B 和 qwen 32B,体验探索两个开源大模型的问答效果。
1. 前置条件
1.1 硬件环境
- 虚拟化服务器: 科脑 X99-D3、128G DDR3 内存(4 * 32G)、Intel E5-2698Bv3 CPU
- 显卡:NVIDIA P106 16G 版 2 块
- AI 云主机:8C、32G、40G 系统盘、500G 数据盘(大模型比较大,直接分 500G 的精简模式的磁盘)
1.2 软件环境
- 虚拟化平台:Proxmox Virtual Environment 8.0.4
- AI 云主机系统: Ubuntu 24.04 LTS
- Docker:26.1.1
- NVIDIA Container Toolkit:1.15
- Ollama:0.1.34
1.3 操作系统配置
Ubuntu 24.04 LTS 系统安装配置,请参考文档打造 AI 大模型云主机,Ubuntu 24.04 LTS 安装 Docker 和 NVIDIA Container Toolkit。安装 NVIDIA 显卡驱动、NVIDIA Container Toolkit 和 Docker。
2. 安装 Ollama
我们采用 Docker Compose 的方式部署 Ollama,更有利于后期的管理、升级。
2.1 创建数据目录
mkdir -p /data/containers/ollama/data2.2 编辑 docker-compose.yml 文件
创建配置文件,vi /data/containers/ollama/docker-compose.yml
name: 'ollama'
services:
ollama:
restart: always
image: ollama/ollama
container_name: ollama
runtime: nvidia
environment:
- TZ=Asia/Shanghai
- NVIDIA_VISIBLE_DEVICES=all
networks:
- ai-tier
ports:
- "11434:11434"
volumes:
- ./data:/root/.ollama
networks:
ai-tier:
name: ai-tier
driver: bridge
ipam:
config:
- subnet: 172.22.1.0/24说明:
ipam 自定义
ai-tier网络的网络地址。 runtime: nvidia 使用 nvidia 的容器运行时 NVIDIA_VISIBLE_DEVICES=all 使用所有 GPU
2.3 创建并启动 Ollama 服务
- 启动服务
cd /data/containers/ollama
docker compose up -d- 正确执行后,输出结果如下
root@AI-LLM-Prod:/data/containers/ollama# docker compose up -d
[+] Running 4/4
✔ ollama Pulled 46.8s
✔ 3c645031de29 Pull complete 10.1s
✔ 2fc4741feb27 Pull complete 12.3s
✔ 8ce449dca7ea Pull complete 43.0s
[+] Running 2/2
✔ Network ai-tier Created 0.1s
✔ Container ollama Started 0.6s 注意: 第一次执行时会下载 ollama 镜像
2.4 验证容器状态
- 查看 Ollama 容器状态
root@AI-LLM-Prod:/data/containers/ollama# docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
ollama ollama/ollama "/bin/ollama serve" ollama About a minute ago Up About a minute 0.0.0.0:11434->11434/tcp, :::11434->11434/tcp- 查看 Ollama 服务日志
# 通过日志查看 Ollama 是否有异常
docker compose logs -f初始日志内容如下:
root@AI-LLM-Prod:/data/containers/ollama# docker compose logs -f
ollama | 2024/05/09 07:26:31 routes.go:989: INFO server config env="map[OLLAMA_DEBUG:false OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:*] OLLAMA_RUNNERS_DIR: OLLAMA_TMPDIR:]"
ollama | time=2024-05-09T07:26:31.408Z level=INFO source=images.go:897 msg="total blobs: 0"
ollama | time=2024-05-09T07:26:31.409Z level=INFO source=images.go:904 msg="total unused blobs removed: 0"
ollama | time=2024-05-09T07:26:31.409Z level=INFO source=routes.go:1034 msg="Listening on [::]:11434 (version 0.1.34)"
ollama | time=2024-05-09T07:26:31.409Z level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama1747465736/runners
ollama | time=2024-05-09T07:26:35.670Z level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60002]"
ollama | time=2024-05-09T07:26:35.670Z level=INFO source=gpu.go:122 msg="Detecting GPUs"
ollama | time=2024-05-09T07:26:35.691Z level=INFO source=gpu.go:127 msg="detected GPUs" count=2 library=/usr/lib/x86_64-linux-gnu/libcuda.so.535.171.04
ollama | time=2024-05-09T07:26:35.691Z level=INFO source=cpu_common.go:11 msg="CPU has AVX2"3. 下载本地大模型
Ollama 采用的容器化的方式部署和运行。日常管理命令需要使用 docker 的方式,在正式的命令前面加上 docker exec -it ollama。
3.1 下载 Llama 3
Llama 3 开源了 8B 和 70B 两种参数大小的模型,由于我们双卡的显存只有 32G,70B 是肯定跑不起来的,所有只能体验 llama3:8b 模型。
执行下面的命令,下载 llama3:8b:
docker exec -it ollama ollama pull llama3:8b正确执行后,输出结果如下 :
root@AI-LLM-Prod:/data/containers/ollama# docker exec -it ollama ollama pull llama3:8b
pulling manifest
pulling 00e1317cbf74... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 12 KB
pulling 8ab4849b038c... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 254 B
pulling 577073ffcc6c... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 110 B
pulling ad1518640c43... 100% ▕████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
success整个模型 4.7 GB ,下载速度还是比较快的,我的网络能达到 70 MB/s 左右。
3.2 下载 qwen
Qwen 1.5 开源了 6 种大模型 , 包括 0.5B, 1.8B, 4B (default), 7B, 14B, 32B (new) and 72B。根据 32G 显存,我们体验一下 32B 的效果如何。
执行下面的命令,下载 qwen:32b(整个模型 18 GB):
docker exec -it ollama ollama pull qwen:32b正确执行后,输出结果如下 :
root@AI-LLM-Prod:/data/containers/ollama# docker exec -it ollama ollama pull qwen:32b
pulling manifest
pulling 936798ec2285... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 18 GB
pulling 6b53223f338a... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 6.9 KB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 182 B
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 59 B
pulling e8fe47255a86... 100% ▕█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ 484 B
verifying sha256 digest
writing manifest
removing any unused layers
success3.3 查看本地下载的大模型
root@AI-LLM-Prod:/data/containers/ollama# docker exec -it ollama ollama list
NAME ID SIZE MODIFIED
llama3:8b a6990ed6be41 4.7 GB 19 minutes ago
qwen:32b 26e7e8447f5d 18 GB About a minute ago4. Llama3 8B vs Qwen 32B
接下来我从自己关注的视角选择几个问题,对比一下 Llama3 8B 和 Qwen 32B 孰强孰弱,谁更符合自己的本地大模型选型需求。
测试问题比较简单,纯属娱乐。并不具备特殊的代表性,实际使用中还需根据需求进行充分的测试。
我习惯使用图形化的对话工具 ChatBox 来调用 Llama3 8B 和 Qwen 32B,进行问答对话测试。
4.1 弱智吧系列问题
问题 1: 我买了一斤藕,为什么半斤都是空的?
问题 2: 为什么我爸妈结婚的时候没邀请我参加婚礼?
- Llama3 8B 回答结果
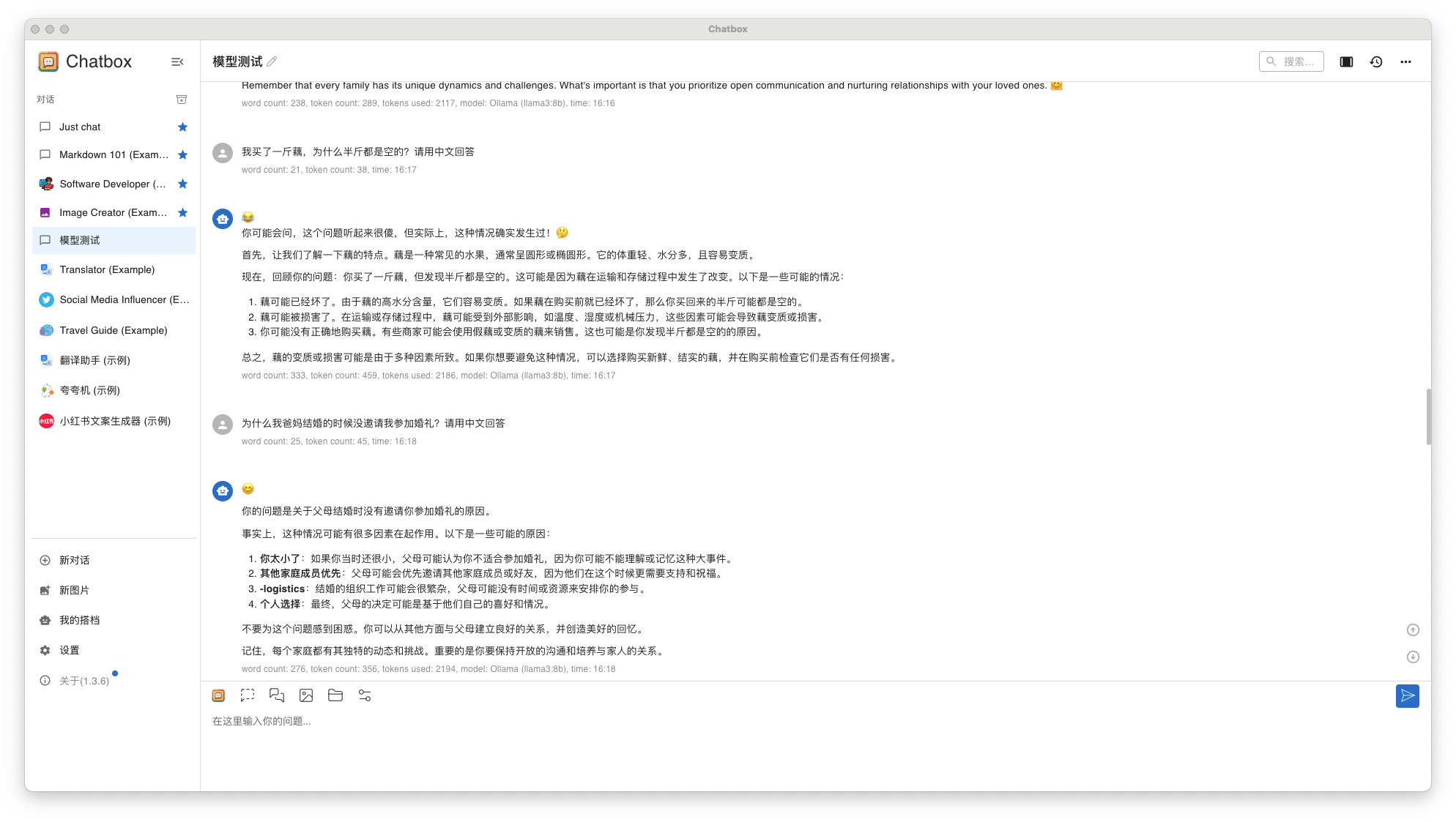
llama38b-qa-1
想得到中文回答,提问时请加上 "请用中文回答"。而且,这两个问题回答的都不让人满意。
- Qwen 32B 回答结果
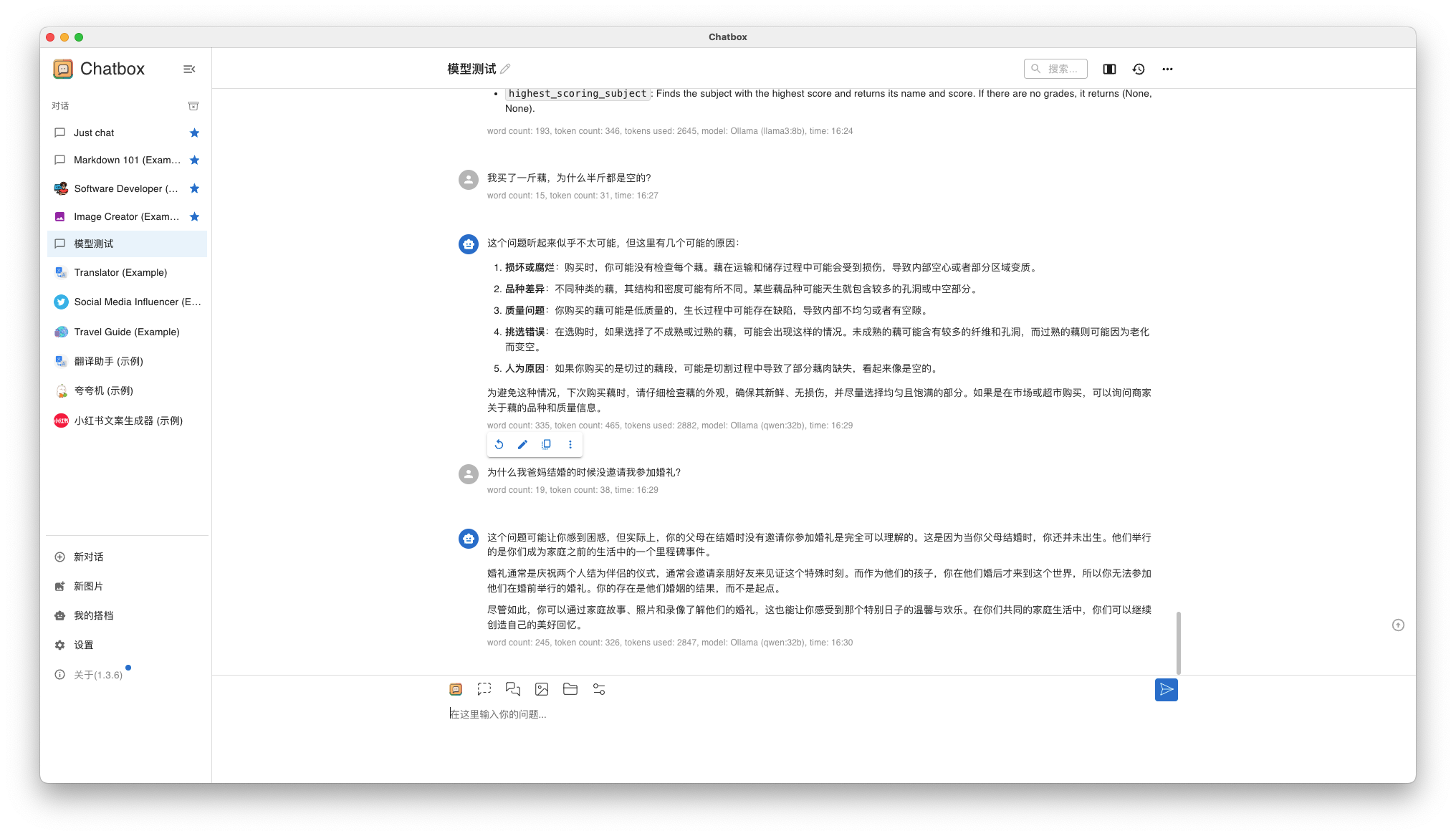
qwen32b-qa-1
第一个问题回答的跟 Llama3 8B 差不多,第二个问题回答的还算令人满意。
4.2 编程问题
问题 1:
题目描述
设计一个名为 Student 的类,用于存储学生的信息。每个学生有姓名(name)、年龄(age)、成绩列表(grades)。你需要实现以下功能:
初始化: 构造函数接受姓名、年龄和一个初始成绩列表(可选,默认为空列表)。
添加成绩: 实现一个方法 add_grade(grade: int),允许向学生的成绩列表中添加一个新的成绩。
计算平均分: 实现一个方法 calculate_average(),返回所有成绩的平均分。如果成绩列表为空,则返回0。
最高分科目: 实现一个方法 highest_scoring_subject(),返回一个元组,包含最高分及其对应的科目名称。假设科目的名称和分数通过字典形式一起存储在成绩列表中,例如 {'Math': 90, 'English': 85}。如果成绩列表为空,返回 (None, None)。- Llama3 8B 回答结果
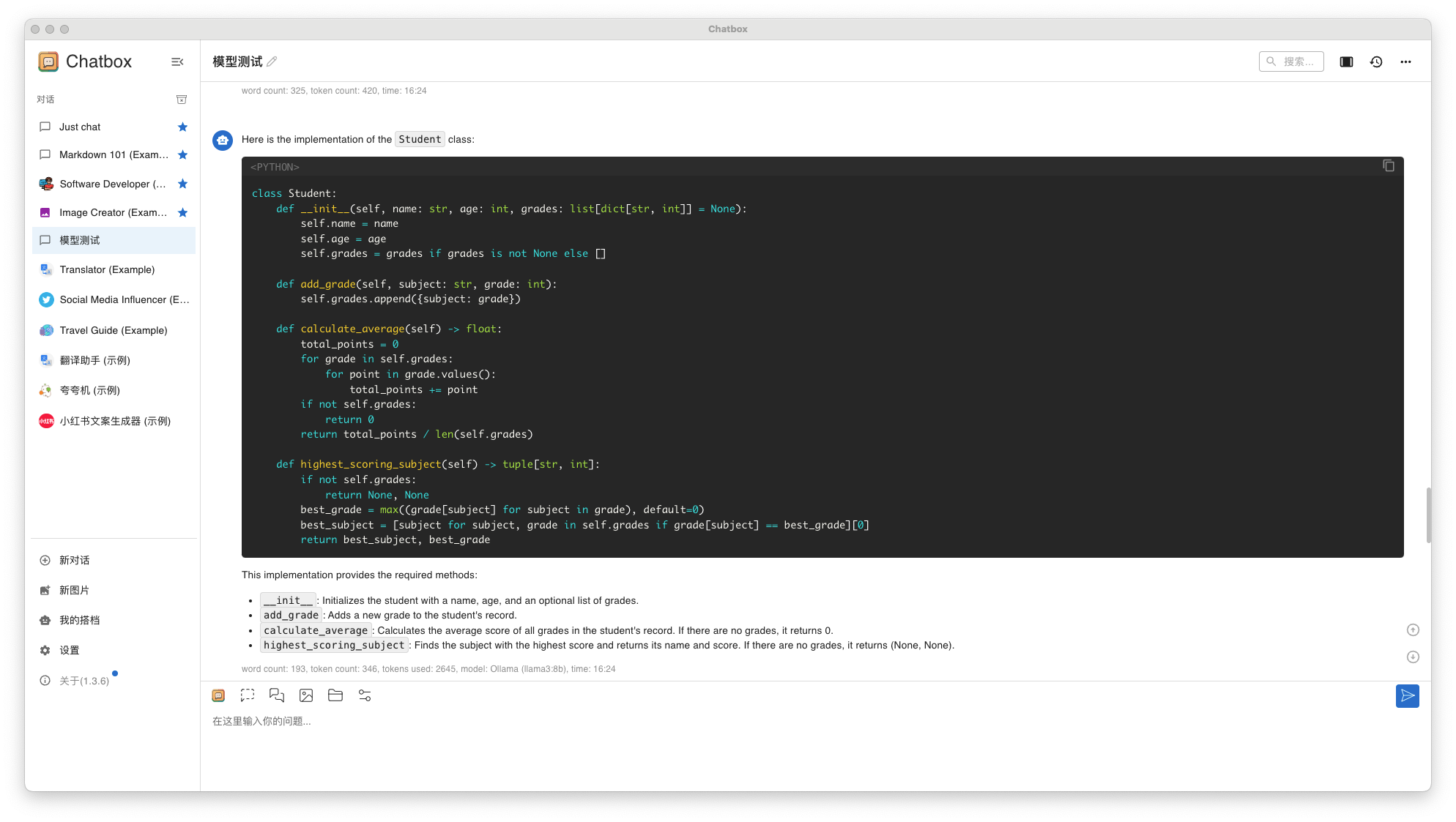
llama38b-qa-2
- Qwen 32B 回答结果
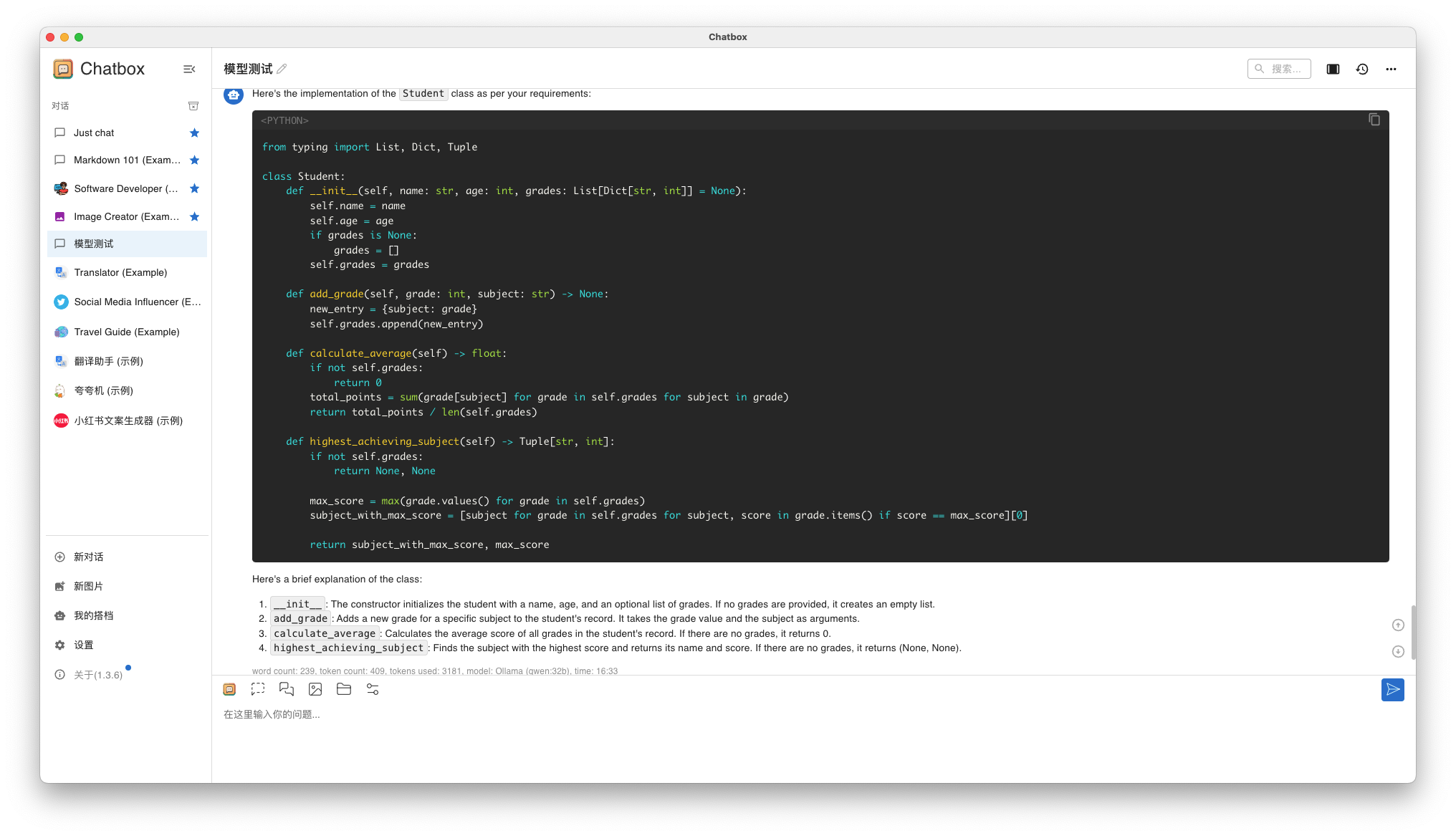
qwen32b-qa-2
两个人回答结果都是用英文,Llama3 这么回答到是没问题,可是 Qwen 32B 也这么回答就令我无法接受了。而且两者的回答也是高度相似。
4.3 综合提问
问题 1: 鲁迅为什么打周树人?
- Llama3 8B 回答结果
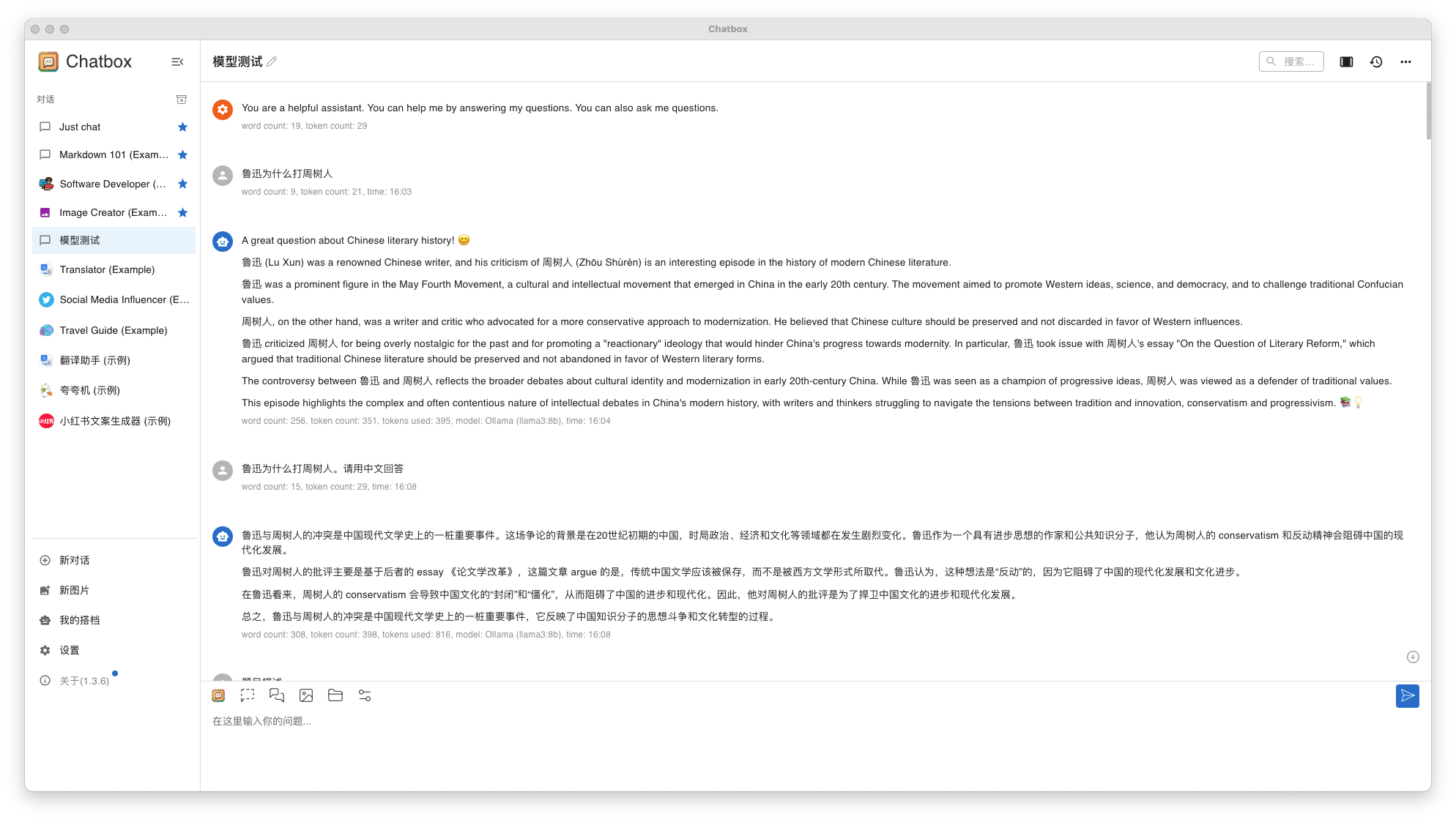
llama38b-qa-3
- Qwen 32B 回答结果
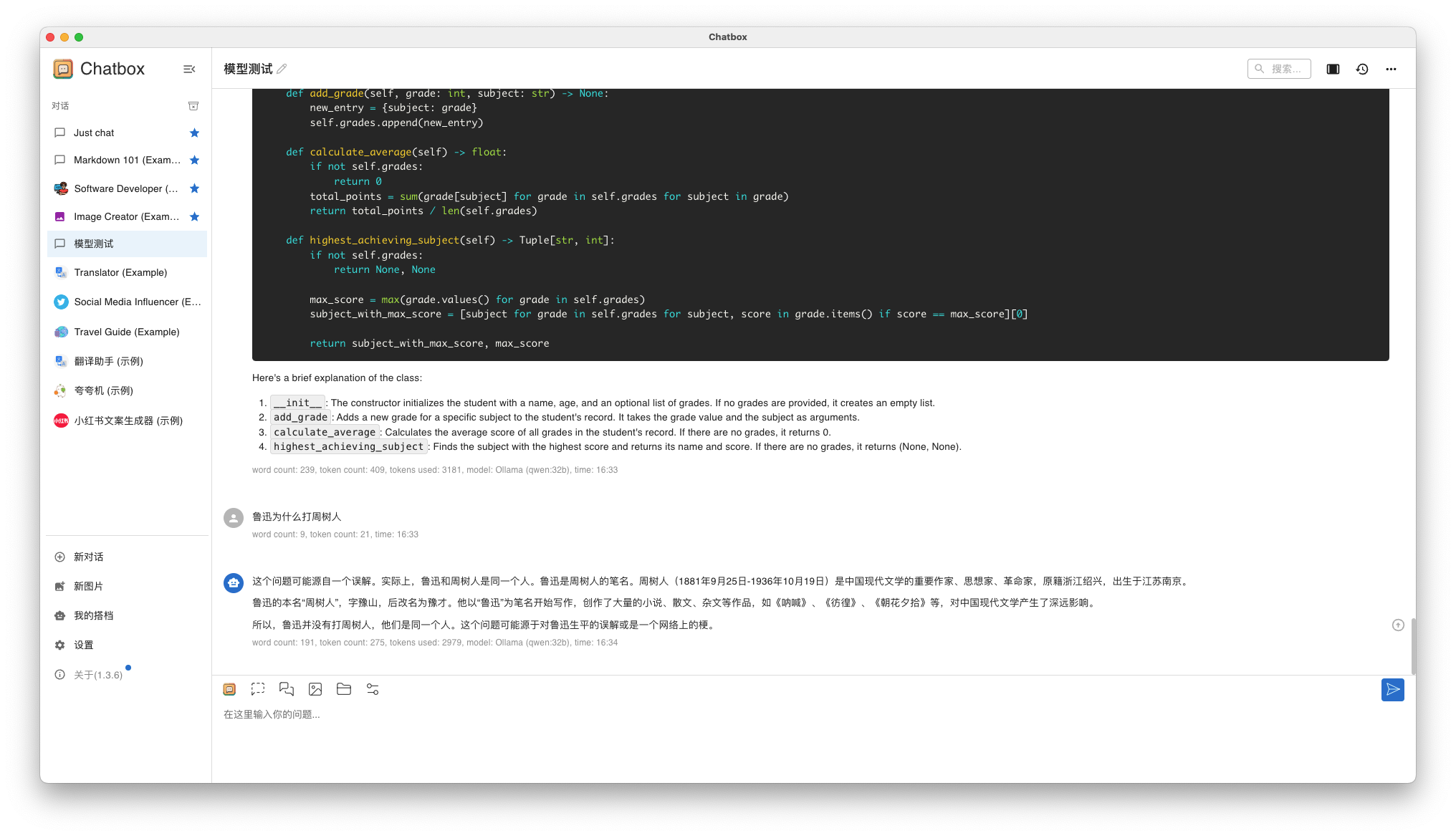
qwen32b-qa-3
测试总结:
- Llama3 8B 和 Qwen 32B 都可以正常运行,Qwen 32B 问答速度略慢,但是可以接受
- Llama3 8B 回答效果一般,Qwen 32B 略胜一筹
- Qwen 中文支持理论上肯定是更好的,我后期大概率会选择 Qwen 体系深度使用
以上,就是我今天分享的全部内容。下一期我会分享如何安装部署 Stable Diffusion ,并体验我这台 AI 云主机的绘图效果。敬请持续关注!!!
免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!
Get 本文实战视频(请注意,文档视频异步发行,请先关注)
如果你喜欢本文,请分享、收藏、点赞、评论! 请持续关注 @ 运维有术,及时收看更多好文!
欢迎加入 「知识星球|运维有术」 ,获取更多的 KubeSphere、Kubernetes、云原生运维、自动化运维、AI 大模型等实战技能。未来运维生涯始终有我坐在你的副驾。
版权声明
- 所有内容均属于原创,感谢阅读、收藏,转载请联系授权,未经授权不得转载。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号