阿里云Dataphin中如何使用python写代码

阿里云业务卖的这么好,但是文档的完整度上真是不太行,而且文档之间关联性差,作为一枚“技术人员”,最怕看到这种:你写了文档,但是跟没写一样…
基于
文章目录
- 0 更新日志
- 1 dataphin中python使用的坑点
- 2 如何通过资源上传python文件
- 2.1 资源上传的步骤
- 2.2 resource_reference 的调用:在python环境中
- 3 其他解读
- 3.1 解压zip
- 3.2 dataphin使用pyspark
0 更新日志
20240407日志
根据线人来报,Dataphin解决了当下文件夹权限问题,不会出现read only文图
@resource_reference{"XXX"}
os.system("mkdir -p ./tmp/chars")
os.system("cp -i XXX XXX.tar.gz")
os.system("pip install --no-deps -v --target=./tmp/chars XXX.tar.gz")同时,dataphin 4.0之前的版本,每次执行都要重复导入安装, dataphin 4.0开始一次安装永久生效
1 dataphin中python使用的坑点
唤起流程参考:创建PYTHON计算任务
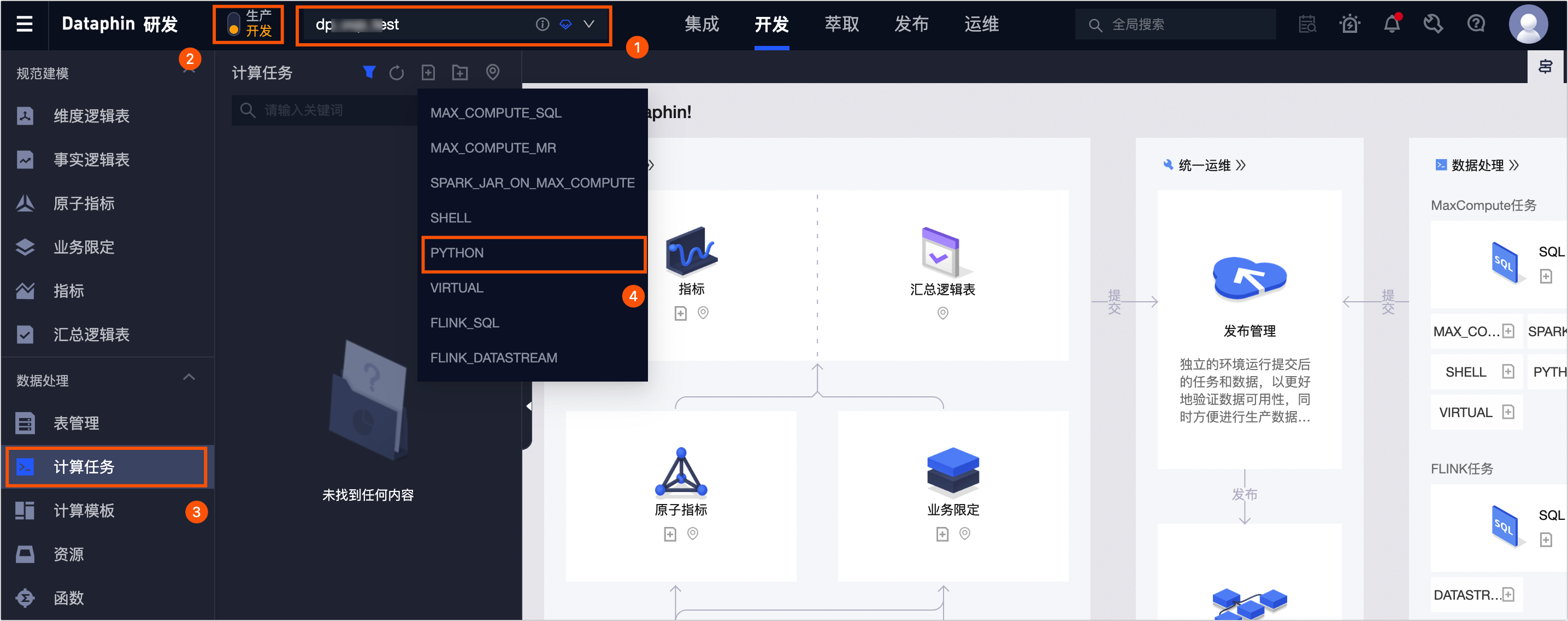
这里文档写的很差,就当每个用户都是开发工程师肚里的蛔虫,底层逻辑一点不交代。 笔者自己探索下来的几个观察:
- python目前有两个版本,py2.7 / py3.7,py3.7的版本其实有点低了
- python环境已经有的依赖(参考:https://help.aliyun.com/zh/dataphin/user-guide/built-in-python-packages)
- 图2 的计算底层逻辑,笔者猜测 ,不是固定在某一台机器,每次点击【运行】会重新定位一台新计算资源,然后执行,所以如果你要
pip install一些依赖,不是安装一次就行,每次都要安装 - 图2 ,执行代码的逻辑,跟普通的jupyter不一样,不是按照顺序一行一行,一些
os.system()的指令,执行运算的优先级会更高
Package Version
---------------------- ---------
bcrypt 3.2.0
certifi 2020.12.5
cffi 1.14.5
chardet 4.0.0
configparser 5.0.2
cryptography 3.4.6
cycler 0.10.0
DateTime 4.3
docopt 0.6.2
hdfs 2.6.0
idna 2.10
joblib 1.0.1
jumpssh 1.6.5
kiwisolver 1.3.1
matplotlib 3.3.4
mysql-connector-python 8.0.23
numpy 1.20.1
pandas 1.2.3
paramiko 2.7.2
Pillow 8.1.2
pip 21.0.1
protobuf 3.15.5
psycopg2 2.8.6
py4j 0.10.9
pycparser 2.20
PyHDFS 0.3.1
pyhs2 0.6.0
PyNaCl 1.4.0
pyodps 0.10.6
pyparsing 2.4.7
pyspark 3.1.1
python-dateutil 2.8.1
pytz 2021.1
requests 2.25.1
sasl 0.2.1
scikit-learn 0.24.1
scipy 1.6.1
setuptools 54.1.1
simplejson 3.17.2
six 1.15.0
threadpoolctl 2.1.0
thrift 0.13.0
urllib3 1.26.3
wheel 0.29.0
xgboost 1.1.1
yarn-api-client 1.0.2
zope.interface 5.2.0- python执行的环境的绝对路径是:
['/mnt/executor/sandbox', '/dataphin/python3/ENV3.7/lib/python37.zip', '/dataphin/python3/ENV3.7/lib/python3.7', '/dataphin/python3/ENV3.7/lib/python3.7/lib-dynload', '/usr/local/python3/lib/python3.7', '/dataphin/python3/ENV3.7/lib/python3.7/site-packages']2 如何通过资源上传python文件
通过上传资源,可以实现的几个功能:
- 调用自己写的python函数代码,可以在python调用,也可以写sh执行文件在shell里面跑批任务
- 一些重要依赖,通过代码里每次安装
pip install比较麻烦,可以直接上传固定在【资源】里面
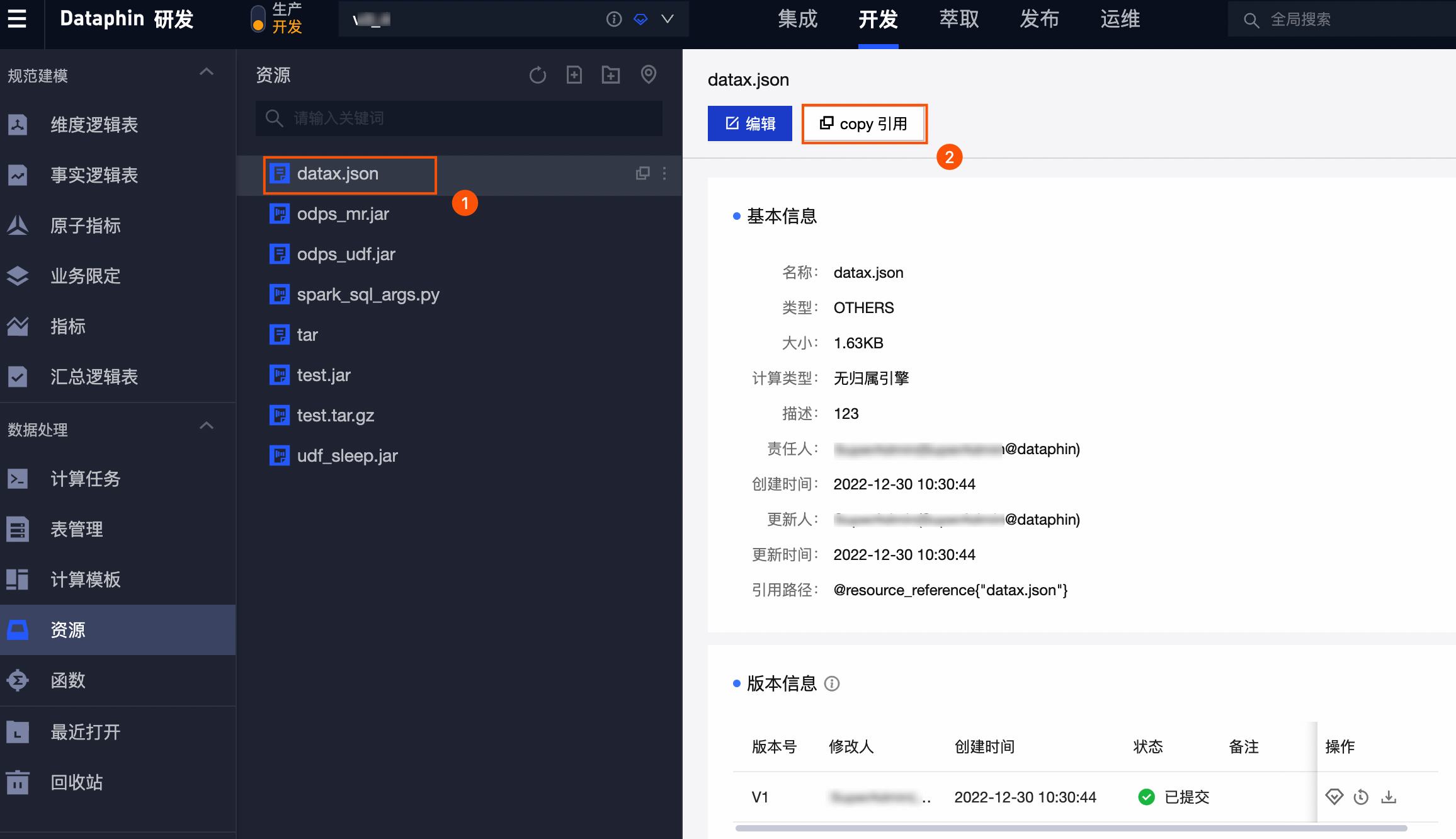
2.1 资源上传的步骤
参考:上传资源及引用
大致步骤:
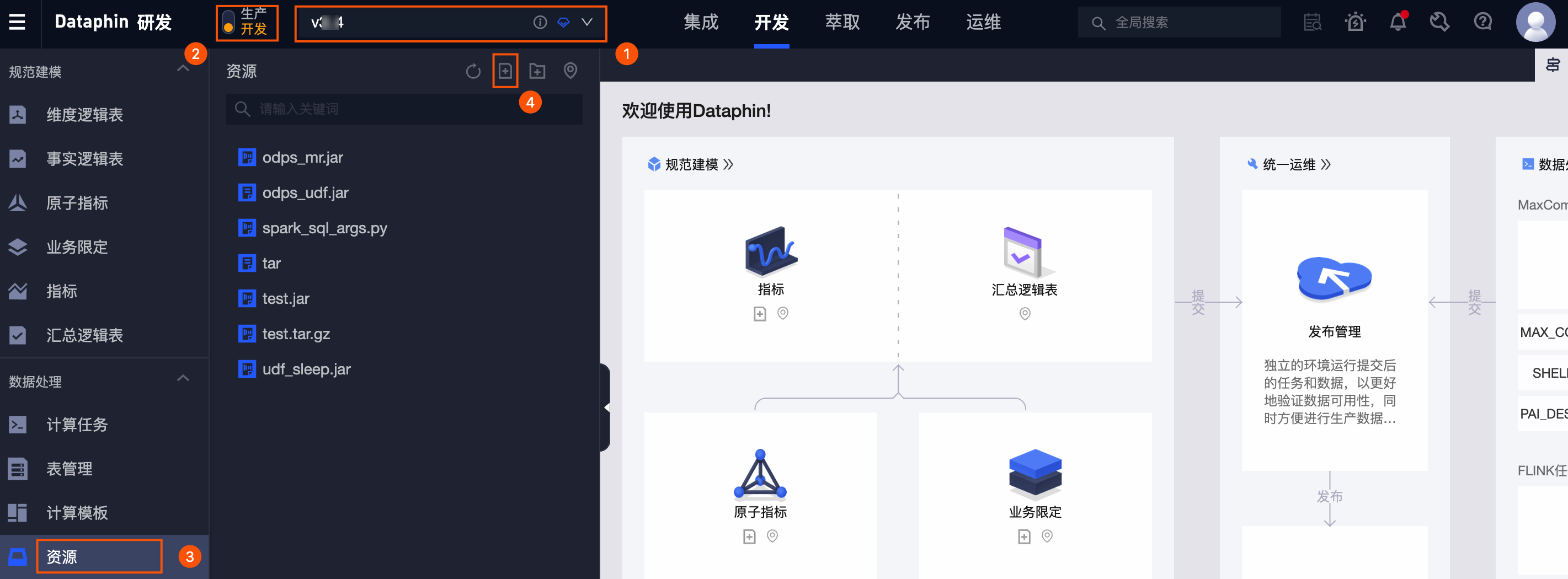
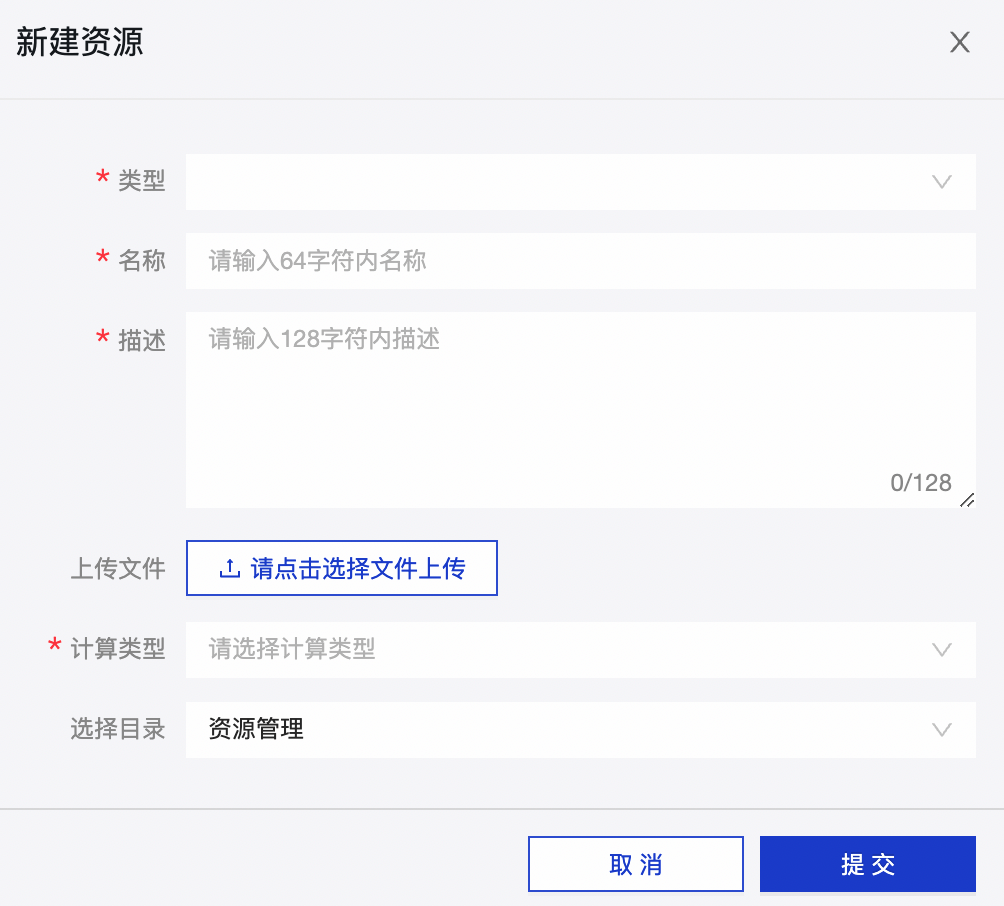
引用资源:
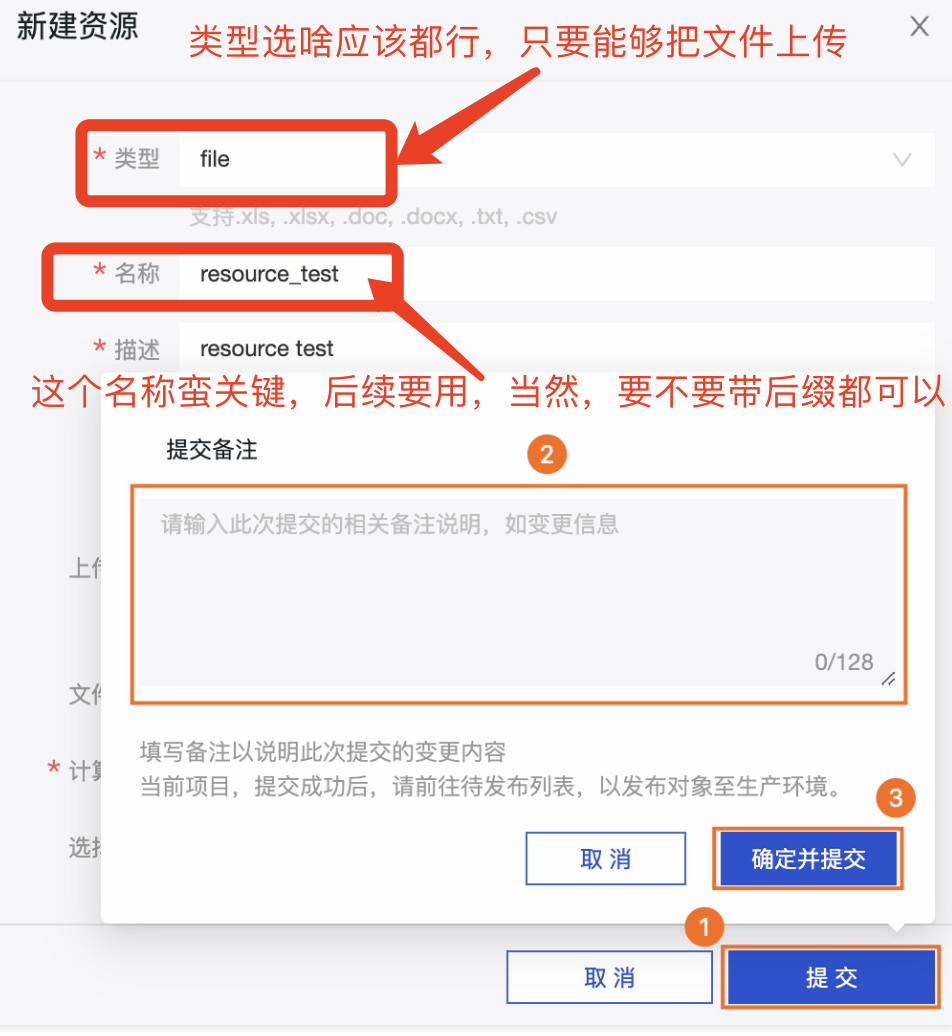
2.2 resource_reference 的调用:在python环境中
笔者自己的第一个疑问,
@resource_reference{"资源名称"} 这个语句背后到底是什么?
def funcion_for_dataphin(num):
return num + 1假如笔者在资源里新建了一个名字叫local_func_matt_test.py的任务名称,上传了一个python函数代码,如上代码块,只有一个简单的函数funcion_for_dataphin
@resource_reference{"local_func_matt_test.py"}
import sys
print('资源存储位置每次执行任务都会更新,本次为:',os.path.dirname(os.path.abspath("local_func_matt_test.py")))
# /mnt/executor/sandbox/resources/0000062240288
print('资源存储位置每次执行任务都会更新,本次为:',os.path.abspath("local_func_matt_test.py"))
# /mnt/executor/sandbox/resources/0000062240289/resource.local_func_matt_test.py- 首先,
@resource_reference()在python环境中 是 这个文件的 路径 !!! 并不是一个函数,也不是一个文件,只是这个上传文件的路径 - 其次,如果你在【资源】上传,其实叫啥,选啥类型,笔者认为都是没所谓的
回到【计算任务】中的python编译空间:
如果我要引用我上传的local_func_matt_test.py文件,该如何正确应用:
from local_func_matt_test import funcion_for_dataphin
from local_func_matt_test.py import funcion_for_dataphin以上两种都是不行的,因为按照之前说的local_func_matt_test.py是一个路径,而且这个实际文件的路径是 /mnt/executor/sandbox/resources/0000062240289/resource.local_func_matt_test.py,
理论上笔者感觉可以正常调用的方式应该是:
import os
sys.path.append(os.path.dirname(os.path.abspath("local_func_matt_test.py")))
from local_func_matt_test.py import funcion_for_dataphin
from local_func_matt_test import funcion_for_dataphin # 或者这样我先将local_func_matt_test.py这个路径的上级目录加到sys.path中,然后就可以直接调用了,但实际很坑,还是不行
笔者,第二次尝试,将这个文件挪到某一个可被访问到的路径
# os.system("mv local_func_matt_test.py /mnt/executor/sandbox/resources/000006224029/test_matt.py")
# 不可用,这个文件夹没有访问权限,只读
os.system("cp local_func_matt_test.py /tmp/chars/test_matt.py")
from test_matt import funcion_for_dataphin
print('函数计算:',funcion_for_dataphin(10))以上就是可用的版本,先把@resource_reference()资源挪到一个方便访问的地方,然后在sys.path新增路径名称,这样就可以顺利请求到了
3 其他解读
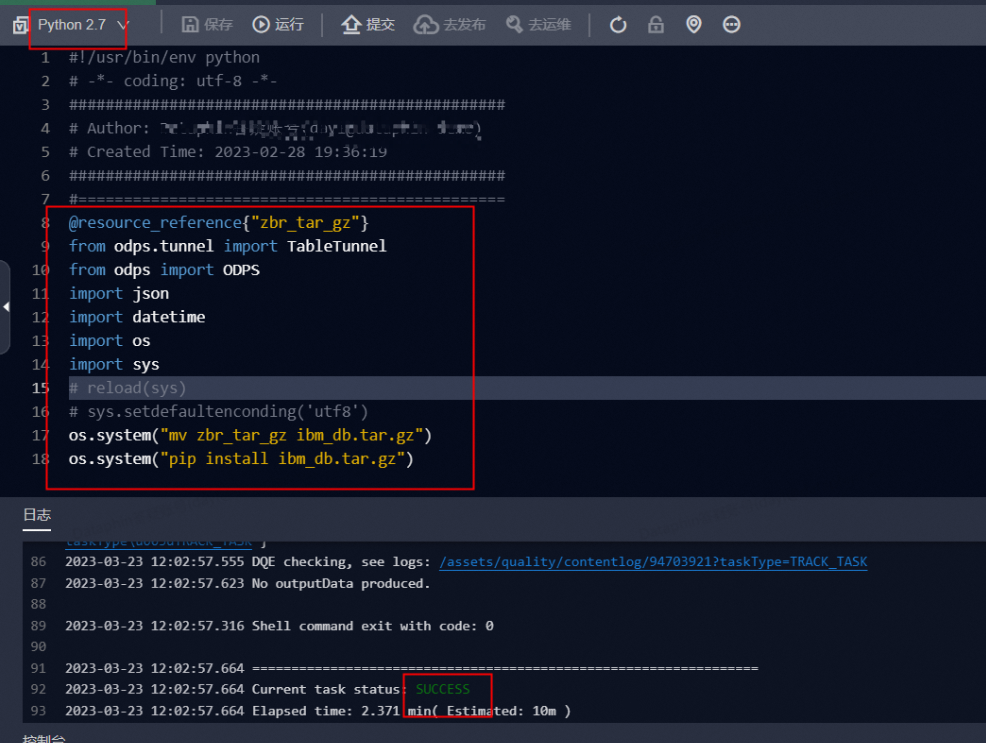
3.1 解压zip
文章【Dataphin计算任务python脚本如何执行资源包】,有这么一段: Dataphin计算任务python执行资源包的脚本如下所示。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
@resource_reference{"zbr_tar_gz"}
from odps.tunnel import TableTunnel
from odps import ODPS
import json
import datetime
import os
import sys
os.system("mv zbr_tar_gz ibm_db.tar.gz")
os.system("pip install ibm_db.tar.gz")这个文档写的,好像懂代码的,都可以看懂,一点注释也不给,厉害厉害的!
来解读一下:
@resource_reference{"zbr_tar_gz"},导入资源名为zbr_tar_gz文件路径os.system("mv zbr_tar_gz ibm_db.tar.gz")将该文件重命名 ,我就纳闷,你开发者当然有读写文件夹的权限,我这没有啊。。- 上述tar.gz进行
pip install安装
3.2 dataphin使用pyspark
#coding=utf-8
import sys
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("spark sql").config("spark.hadoop.odps.project.name", "your_project_name").config("spark.hadoop.odps.access.id", "your_id").config("spark.hadoop.odps.access.key", "your_key").config("spark.hadoop.odps.end.point", "your_odps_end_point").config("spark.sql.catalogImplementation", "odps").getOrCreate()
rdf = spark.sql("select * from table limit 10 ")
print("success")
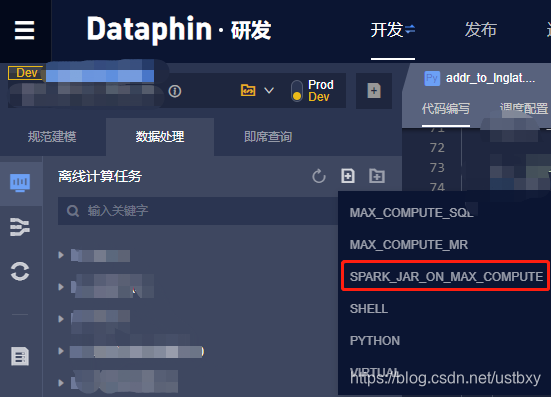
print(rdf)写好pyspark.py脚本,上传为资源并发布
新建spark_jar_on_max_compute任务,配置账号密码参数,调用pyspark.py脚本
@resource_reference{"pyspark.py"}
spark-submit
--deploy-mode cluster
--conf spark.hadoop.odps.task.major.version=cupid_v2
--conf spark.hadoop.odps.end.point=http://service.cn.maxcompute.aliyun.com/api
--conf spark.hadoop.odps.runtime.end.point=http://service.cn.maxcompute.aliyun-inc.com/api
--master yarn
pyspark.py类似在shell中记sh代码,@resource_reference{"pyspark.py"}导入文件路径,
直到pyspark.py 执行代码
不过,不确定这段代码,是否可以直接访问到?
腾讯云开发者
