K-Free社群检测算法|KDD2024
原创K-Free社群检测算法|KDD2024
原创
一、背景
游戏内的玩家和玩家间的交互关系构成了游戏社交网络,其中部分关系亲密的好友或者兴趣相近的玩家进一步组成了社交网络中的社群,例如游戏内的社团、俱乐部或者以某个大V玩家为枢纽的局部人群所构成的子网络。同时社群也是游戏内社交生态繁荣的一个表现,研究表明,社群内的玩家通常有着更高的社交度和活跃度,此外属于同一个社群内的玩家通常有着相近的活跃模式,因此对游戏内社群的挖掘和分析对于理解游戏内用户的社交和活跃模式意义重大。
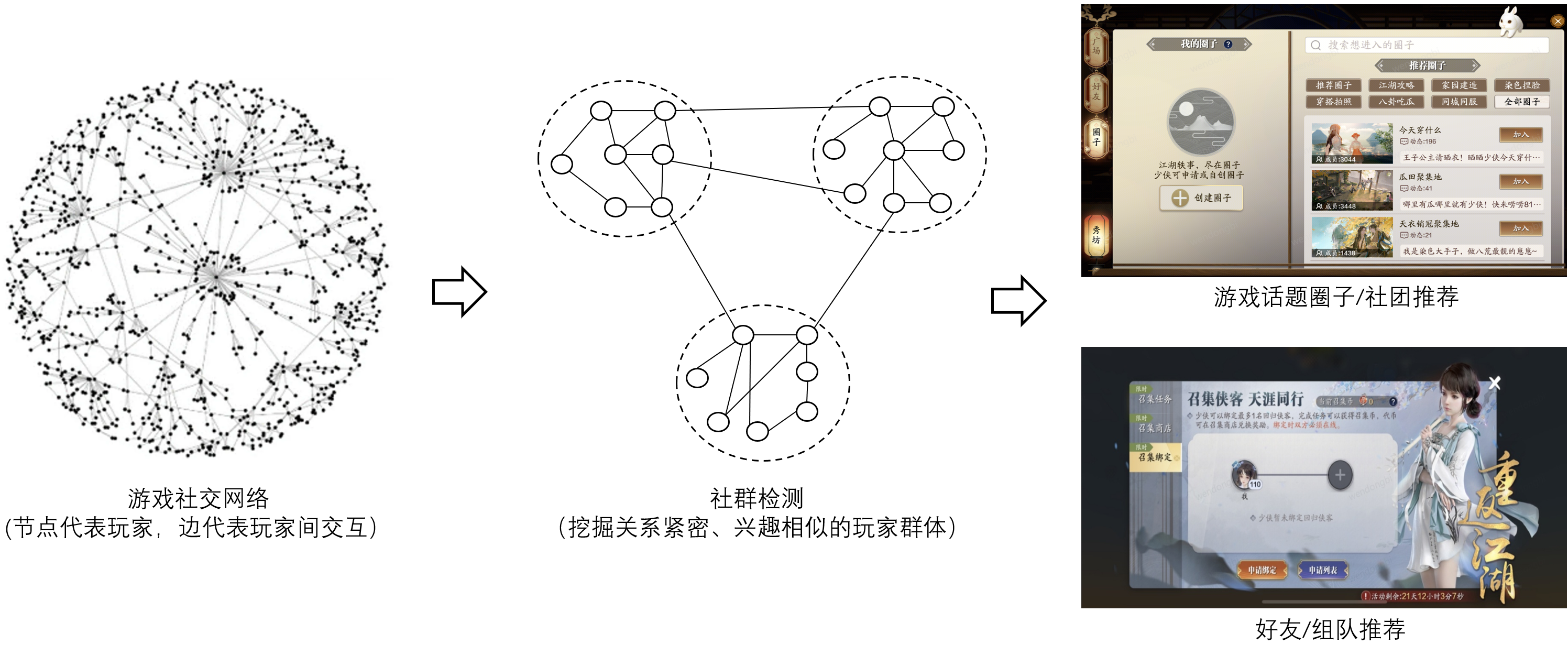
图1:游戏社群检测及其应用示意图
游戏社交网络具有网络规模巨大、语义特征丰富等特点,除了玩家之间海量的关系链数据(例如好友、情侣、师徒、组队等),还有丰富的玩家语义属性(例如玩家等级、战力、玩法偏好等),如何权衡社交网络的“结构”和“语义”信息从而充分挖掘游戏内趣味相投的用户群体是一项极具挑战性的任务。如图1所示,社群检测(community detection)旨在将社交网络划分为不同社群,以发现社交网络中兴趣相似的人,从而提升活动推广和资源投放的效率。传统的社群检测算法(例如Lovain等)大多只考虑社交网络的结构信息,将社群定义为社群内连接密集、社群间连接稀疏的人群,但其忽略了节点的语义信息;此外,已有的社群检测算法通常需要人为指定社群数量K,并将社交网络划分为K个社群,然而真实的业务场景中往往没有这样的先验知识,需要花费专家知识和大量人力来确定社群数量K。
基于上述挑战,我们提出了深度自适应生成式社群检测算法DAG,从数据生成的视角建模社交网络中社群的产生过程,在不需要人为指定社群数量K的情况下,自适应地将任意的社交网络划分成适当数量的社群,并通过图神经网络算法对社交网络中的结构和语义信息联合建模,从而充分挖掘社交网络中紧密连接并语义相似的社群。基于该算法,我们不仅可以挖掘社交网络中的潜在社群并加深对社群内玩家行为模式的理解,还可以实现对游戏内不同社群玩家的个性化资源投放,例如,我们可以为偏好特定玩法的社群投放他们更感兴趣的任务,并鼓励同一社群内的用户组队完成,以高活带低活的形式拉动社群内成员的整体活跃度,持续增加用户粘性。
我们围绕社交网络挖掘、图神经网络、组合优化等技术,持续优化社群挖掘和推荐算法,并与游戏业务团队紧密合作,共同探索促进用户活跃度的运营模式,截至目前我们团队自研的社群挖掘、社群推荐算法已经在好友组队推荐、圈子推荐、战队推荐等多个腾讯游戏业务场景成功落地,并取得了显著的效果提升。
下面将重点介绍DAG算法及其在实际业务场景中的效果。
二、相关工作和挑战
社群检测的方法主要分为传统的社区检测以及深度图聚类算法,然而这些算法各自又存在不同的问题,即难以权衡图结构和语义属性,以及无法自适应寻找社群数目。
痛点一:难以权衡的拓扑结构和语义相似性
社区检测算法,如 Louvain,通过最大化模块度的方法来进行优化,模块度可以简单理解为“同社群内的边数与不同社群间社群的边数之差”。Louvain的好处在于简单高效,而且可以自适应地找出社群的数目。
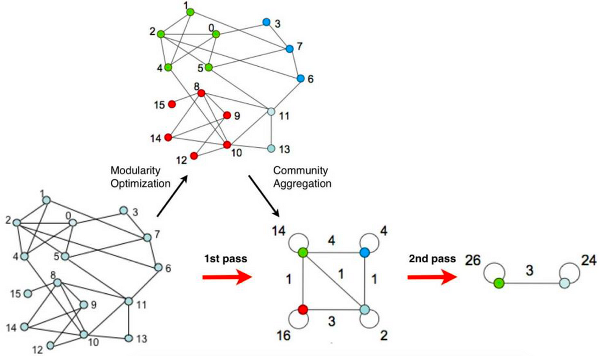
图2:传统社区检测算法示意图
然而,由于传统算法的优化目标通常只局限于拓扑结构(边的数目),同样重要的语义相似性会被忽视,这使得传统算法找到的社群结构往往是有偏的。在实验中,我们发现通过传统社群算法(如 Louvain)检测出的社群往往具有很高的模块度,但语义相似性却偏低。在游戏社交场景中,这意味着检测出的社群内部玩家缺乏语义上的共性和可解释性,这阻碍了我们将其应用到推荐或者用户分析等下游任务中。
痛点二:未知的先验社群数目 K
深度图聚类(Deep Graph Clustering,简称 DGC)算法通过图神经网络来对图上的节点嵌入进行训练,并将训练目标与聚类算法(如K-means)结合起来。DGC 方法虽然能够在图的拓扑结构和语义属性中取得良好的权衡,但是需要一个先验的社群数目 K 作为训练的超参数,社群数目 K 的选取极大影响了最终社群检测的结果。然而业务需求中,我们对潜在的社群结构往往没有先验知识,很难找到一个准确的社群数目 K 。这就是所谓的“第二十二条军规”困境——现有的方法需要一个无法获得的输入才能得到靠谱的输出。

图3:DGC的“第二十二条军规”
DGC方法之所以需要先验的社群数目 K ,是因为其训练目标和 K-Means 聚类是相互耦合的,DGC 方法会在训练中不断地进行 K-Means 聚类,并根据聚类结果不断地修正训练的目标。K-Means 本身必须要有一个 K 作为参数,因此这个先验知识便不可或缺。
这个时候,可能有的朋友们要问:
Q1. 能否换个不需要指定K的聚类算法?
我们知道,除了 K-Means 这样的基于均值的聚类方法外,还有些可以自适应找到聚类个数的算法,例如DBSCAN这类基于密度的聚类方法。我们尝试将 DGC 方法的 K-Means聚类部分替换为了 DBSCAN聚类,在公开数据集 Cora 上进行训练,并将训练完的节点嵌入向量通过 T-SNE 降维并可视化。

图4:深度图聚类(DGC)算法结合不同聚类模型的结果(左:K-means聚类;右:DBSCAN聚类)
如图4所示,K-means算法(左图)会将网络中的节点划分为预设好的K个社群,这类基于强先验知识的聚类算法对超参数社群数量K的设置是非常敏感的。然而替换为 DBSCAN (右图)之后,模型训练出现了崩溃,所有的节点嵌入都处于同一个连续的流形上,因而无法得到明显的社群关系。
Q2. 可否穷举所有的K并选一个最优解?
一种暴力解法是首先指定一个社群数量K的候选范围,然后算法遍历得到一个“最佳的K”。然而在真实的业务中,社群数目K的范围往往无法预知,而且社群检测是一个无监督任务,我们很难找到有用的监督指标,下游任务需要进行 A/B Test 来收集用户反馈,本身既耗时也充满不确定性;此外,每尝试一个新的K 都需要重新训练整个模型,这使得模型训练成本骤增。
为了进一步说明,我们使用社群检测中最流行的指标——模块度,作为衡量社群质量好坏的无监督指标,以公开数据集Cora上的实验为例,已知该数据集右7个真实的社群类别,我们使用了四个不同的 DGC 模型将 K 从 2 遍历到 14,并记录模块度的变化情况。
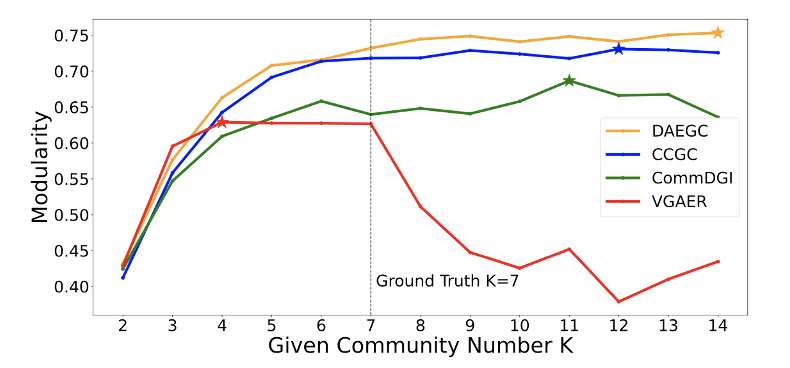
图5:不同的社群数量超参数K对已有社群检测算法的影响
如图5所示,对所有的社群检测算法来说,无监督指标最高的地方都不是先验的数字7,大部分的方法随着社群数目提高,模块度有更高的趋势。遍历 K 取最高指标的方案既低效,效果也不太令人满意。
三、方法介绍
在本工作中,我们将上述业务问题抽象化为科学问题,首次提出并定义了K-Free社群检测任务:在不需要指定社群数量K的情况下将社交网络划分为合适数量的社群。为了解决这一问题,我们提出了深度自适应社群检测算法 DAG(Deep Adaptive and Generative),从数据生成的视角对社群数量K和社群检测任务进行联合学习。DAG 首先用 Mask AutoEncoder (MAE) 作为节点嵌入的预训练,让节点嵌入同时包含自身拓扑邻居的语义信息(痛点一);进一步DAG使用社群隶属网络(CAN)建模社交网络的生成过程,这样无需聚类,可以直接通过模型读出每个节点的社群ID。在此基础上,DAG 将搜索 K 转化为了一个可微分的社群选择问题。这个转化使得 DAG 可以端到端同时学习社群的数量和节点的社群隶属(痛点二)。
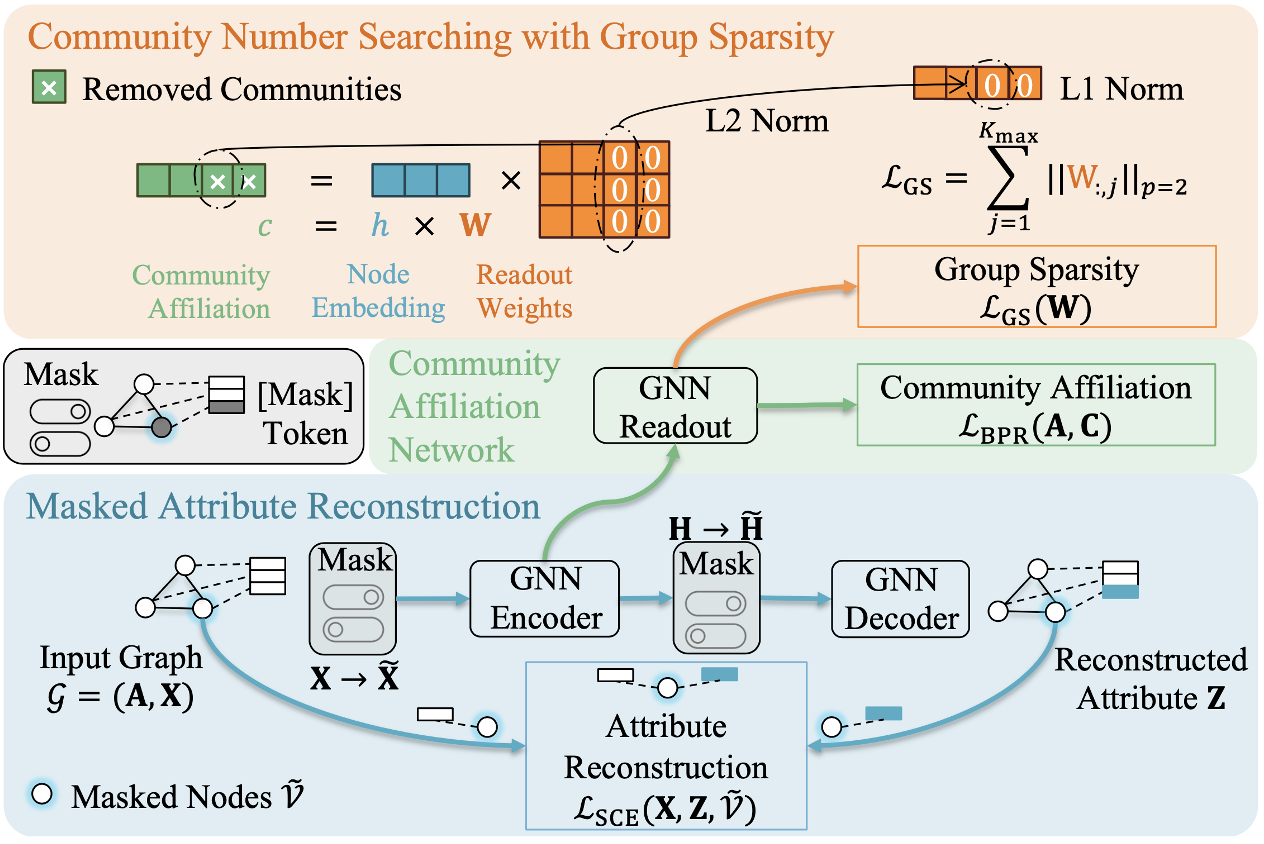
图6. 本文提出的DAG社群检测算法示意图
接下来分别介绍DAG的每一个模块:
1. 掩码属性重建模块
该模块我们使用一个图自编码器(Graph AutoEncoder)对节点特征进行重建。首先我们在图上随机采样一组点,并对采样出的点的属性特征进行掩码,然后将经过掩码的图输入图神经网络(GNN)编码器进行编码,生成图上节点的嵌入 H,并对之前随机采样点的嵌入进行二次掩码(替换成和嵌入等长的 mask token),最后我们使用一个GNN解码器对图上的嵌入进行解码,复原那些被掩码点的原始特征。
训练的损失函数如下式所述:
\mathcal{L}_{\mathrm{SCE}}(\mathrm{X}, \mathrm{Z}, \widetilde{\mathcal{V}})=\frac{1}{|\widetilde{\mathcal{V}}|} \sum_{v_i \in \widetilde{\mathcal{V}}}\left(1-\frac{x_i^T z_i}{\left\|x_i\right\| \cdot\left\|z_i\right\|}\right)^3
2. 社群隶属Readout模块
接下来,我们以掩码属性重建模块学习到的节点嵌入作为输入进行社群检测。我们设计了一个无需任何聚类的读出(Readout)模块,其直接输出节点属于每一个社群的概率。
C=\operatorname{Readout}(\mathbf{A}, \mathbf{H})
具体讲,我们通过一个基于稀疏约束的社群隶属网络(Community Affiliation Network, CAN)来进行社群数量和社群隶属的联合学习。
如图7所示 ,图中的矩形节点是游戏社交网络中的玩家,他们的好友关系构成了真实的社交网络。CAN 的假设在于,现实社交网络中的节点之所以存在好友关系,是因为他们有类似的社群关系。如图7左上角所示,我们假设存在虚拟的社群节点(圆点),和社交网络的成员节点形成了一个带权二部图,而每个社交网络成员节点和社群节点的边权显示了玩家对于该社群的隶属概率。
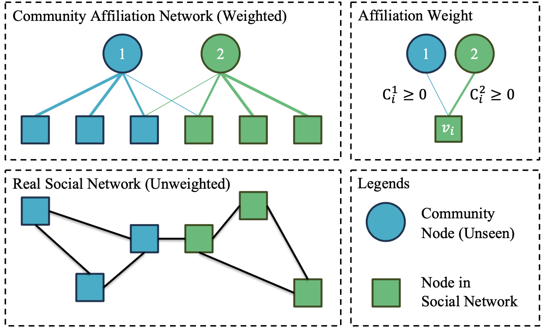
图7. DAG社群隶属模块示意图
假设有 K 个社群和 N 个节点,那么每个节点都有个长度为 K 的社群隶属向量 c,所有节点的社群隶属则可描述为一个 N × K 的社群隶属矩阵 C,对于第 i 个节点,它所属于的社群 id 就是对应社群隶属概率最大的维度:
I_i=\underset{j}{\arg \max } \mathbf{C}_{i, j}
而基于 CAN 的假设,两个社交网络的成员节点是否有好友关系则取决于社群隶属关系的相似度。因此,我们可以使用 BPR loss 对网络进行训练,这可以视作一个链路预测任务:
\mathcal{L}_{\mathrm{BPR}}=-\sum_{i=1}^{|\mathcal{E}|} \ln \sigma\left(\mathbf{C}_i \cdot \mathbf{C}_j^T-\mathbf{C}_i \cdot \mathbf{C}_u^T\right)
其中点 i 和 点 j 之间存在好友关系,而点 i 和点 u 之间不存在好友关系,我们为每一条边 (i, j) 随机采样了一组不存在边的节点对 (i, u)作为负样本。
3. 基于组稀疏约束的社群数目搜索
最后我们基于社群隶属模块的输出实现端到端的社群数目搜索。在此,我们做了一步问题转化,DAG 将原始的社群数目搜索问题转化为该合并(删除)多少多余社群的问题,而这种删除是通过对参数矩阵的列进行稀疏化约束实现的。我们使用组稀疏(Group Sparsity)约束来实现自适应的冗余社群删除,组稀疏也叫L_{2,1}范数,定义为:
\mathcal{L}_{\mathrm{GS}}=\left\|\mathbf{W}^T\right\|_{2,1}=\sum_{j=1}^{k_{\max }}\left\|\mathbf{W}_{:, j}\right\|_{p=2}=\sum_{j=1}^{k_{\max }}\left(\sum_{i=1}^d \mathbf{w}_{i, j}^2\right)^{1 / 2}
通过组稀疏约束,我们可以将权重矩阵的列数设置为一个较大的数值 kmax,在训练过程中,由于组稀疏会让一些权重列变为零向量,因此模型的输出范围将从 kmax 种可能社群逐步缩小并收敛到一个“最佳K值”。
四、实验结果
我们在腾讯某MMORPG游戏的好友推荐模块中部署了我们的算法,我们将游戏中的日活玩家看作图上的一个节点,并将任意的好友关系视作一个无权的边,构建了游戏好友的关系网络。在好友推荐模块中,每当某玩家点击推荐模块,模块将返回给玩家一个排序后的好友列表;当玩家点击了某个好友后,好友会受到邀请,并选择是否同意组队;若好友同意组队,玩家和该好友将解锁特定的组队玩法任务以获取奖励。根据推荐模块的设计,我们使用了三个评价指标:
undefined 点击率:玩家点击了推荐模块后,点击好友发送邀请的比率。
undefined 组队率:当好友收到邀请后,好友同意组队的比率。
undefined 总体成功率:当玩家点击推荐模块后,最终与好友组成队伍的比率。可以视作前两者的乘积。
我们使用 DAG 模型对模型进行训练,并获取每个玩家的社群标签。除此之外,我们也对比了DAG跟其他两种算法,包括业务基线Intimacy(基于好友亲密度排序)和最先进的 DGC 方法 CCGC 两种算法的效果。我们进行了时长为一周的线上A/B实验,并汇总了三种方法的各项指标,其中各算法的效果如表1所示。
方法 | 点击率 | 组队率 | 总体成功率 |
|---|---|---|---|
Intimacy | 2.59% | 76.72% | 2.00% |
CCGC | 2.66% (+2.93%) | 76.08% (-0.83%) | 2.03% (+2.08%) |
DAG(本方法) | 2.72% (+4.90%) | 80.10% (+4.41%) | 2.18% (+9.44%) |
表1:各社群推荐算法线上AB实验对比(括号内表示CCGC和DAG算法相比Intimacy算法的效果相对提升)
可以看出,我们的方法相比基线算法在点击率、组队率、总体成功率指标上分别提升了4.9%,4.4%,9.44%。这意味着我们的算法挖掘出了更有意义的社群,并再次验证了同社群内的玩家将有更高的活跃度和社交度。
五、总结
本文将腾讯游戏真实业务场景中的痛点问题形式为K-Free社群检测问题,并设计了深度自适应生成式社群检测算法DAG,基于图神经网络技术挖掘游戏社交网络中的用户语义信息和社交结构信息,并设计了基于组稀疏约束社群隶属和搜索算法对社群数量K和社群隶属任务进行联合学习。
此外,本文介绍了该算法在社交推荐类业务中的应用案例和算法对提升用户点击率、组队率等核心业务指标的实际效果,也希望本文的内容能为大家解决实际业务问题带来一些帮助。
六、 团队信息
腾讯互娱社交算法团队(https://socialalgo.github.io/)致力于研发高效的社交网络智能算法和分析技术,挖掘海量丰富的图数据,构建高性能的图模型,服务于大量腾讯产品的多样社交场景,旨在提升用户留存和产品收益。团队负责的场景包括好友推荐、社群推荐、社交传播、社交营销、社交分析等围绕大规模社交网络的应用。团队研发的技术已落地应用于20+款腾讯互娱产品,获得多项腾讯公司级荣誉奖项,包括卓越运营奖、业务突破奖、腾讯专利奖、腾讯代码奖、犀牛鸟精英人才计划优秀导师等,并且已在国际前沿学术会议和期刊上发表了20+篇论文。
七、 参考文献
1. Chang Liu, et al. "DAG: Deep Adaptive and Generative K-Free Community Detection on Attributed Graphs." Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2024.
2. Zhang, Xingyi, et al. "Constrained social community recommendation." Proceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining. 2023.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。