Transformers 4.37 中文文档(二)

Transformers 4.37 中文文档(二)

ApacheCN_飞龙
发布于 2024-06-26 14:22:20
发布于 2024-06-26 14:22:20
使用脚本进行训练
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/run_scripts
除了🤗 Transformers 的 notebooks 之外,还有示例脚本演示如何使用PyTorch、TensorFlow或JAX/Flax训练模型的方法。
您还会发现我们在研究项目和遗留示例中使用的脚本,这些脚本大多是社区贡献的。这些脚本目前没有得到积极维护,并且需要特定版本的🤗 Transformers,这很可能与库的最新版本不兼容。
示例脚本不是期望在每个问题上立即运行,您可能需要调整脚本以适应您要解决的问题。为了帮助您,大多数脚本完全暴露了数据预处理的方式,允许您根据需要进行编辑以适应您的用例。
对于您想在示例脚本中实现的任何功能,请在提交拉取请求之前在论坛或问题中讨论。虽然我们欢迎错误修复,但是我们不太可能合并增加更多功能但牺牲可读性的拉取请求。
本指南将向您展示如何在PyTorch和TensorFlow中运行一个示例摘要训练脚本。除非另有说明,所有示例都预计能够在两个框架中运行。
设置
要成功运行示例脚本的最新版本,您必须在新的虚拟环境中从源代码安装🤗 Transformers:
git clone https://github.com/huggingface/transformers
cd transformers
pip install .对于旧版本的示例脚本,请点击下面的切换:
Then switch your current clone of 🤗 Transformers to a specific version, like v3.5.1 for example:
git checkout tags/v3.5.1After you’ve setup the correct library version, navigate to the example folder of your choice and install the example specific requirements:
pip install -r requirements.txtRun a script
PytorchHide Pytorch content
The example script downloads and preprocesses a dataset from the 🤗 Datasets library. Then the script fine-tunes a dataset with the Trainer on an architecture that supports summarization. The following example shows how to fine-tune T5-small on the CNN/DailyMail dataset. The T5 model requires an additional source_prefix argument due to how it was trained. This prompt lets T5 know this is a summarization task.
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generateTensorFlowHide TensorFlow content
The example script downloads and preprocesses a dataset from the 🤗 Datasets library. Then the script fine-tunes a dataset using Keras on an architecture that supports summarization. The following example shows how to fine-tune T5-small on the CNN/DailyMail dataset. The T5 model requires an additional source_prefix argument due to how it was trained. This prompt lets T5 know this is a summarization task.
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_evalDistributed training and mixed precision
The Trainer supports distributed training and mixed precision, which means you can also use it in a script. To enable both of these features:
- Add the
fp16argument to enable mixed precision. - Set the number of GPUs to use with the
nproc_per_nodeargument.
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generateTensorFlow scripts utilize a MirroredStrategy for distributed training, and you don’t need to add any additional arguments to the training script. The TensorFlow script will use multiple GPUs by default if they are available.
Run a script on a TPU
PytorchHide Pytorch content
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. PyTorch supports TPUs with the XLA deep learning compiler (see here for more details). To use a TPU, launch the xla_spawn.py script and use the num_cores argument to set the number of TPU cores you want to use.
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generateTensorFlowHide TensorFlow content
Tensor Processing Units (TPUs) are specifically designed to accelerate performance. TensorFlow scripts utilize a TPUStrategy for training on TPUs. To use a TPU, pass the name of the TPU resource to the tpu argument.
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_evalRun a script with 🤗 Accelerate
🤗 Accelerate is a PyTorch-only library that offers a unified method for training a model on several types of setups (CPU-only, multiple GPUs, TPUs) while maintaining complete visibility into the PyTorch training loop. Make sure you have 🤗 Accelerate installed if you don’t already have it:
Note: As Accelerate is rapidly developing, the git version of accelerate must be installed to run the scripts
pip install git+https://github.com/huggingface/accelerate你需要使用run_summarization_no_trainer.py脚本,而不是run_summarization.py脚本。🤗 加速支持的脚本将在文件夹中有一个task_no_trainer.py文件。首先运行以下命令创建并保存一个配置文件:
accelerate config测试你的设置以确保配置正确:
accelerate test现在你已经准备好开始训练了:
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization使用自定义数据集
摘要脚本支持自定义数据集,只要它们是 CSV 或 JSON Line 文件。当你使用自己的数据集时,你需要指定几个额外的参数:
-
train_file和validation_file指定了你的训练和验证文件的路径。 -
text_column是要总结的输入文本。 -
summary_column是要输出的目标文本。
使用自定义数据集的摘要脚本将如下所示:
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate测试一个脚本
在承诺完整数据集之前,最好先在较少数量的数据集示例上运行你的脚本,以确保一切按预期工作。使用以下参数将数据集截断为最大样本数:
-
max_train_samples -
max_eval_samples -
max_predict_samples
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate并非所有示例脚本都支持max_predict_samples参数。如果你不确定你的脚本是否支持这个参数,添加-h参数进行检查:
examples/pytorch/summarization/run_summarization.py -h从检查点恢复训练
另一个有用的选项是从先前的检查点恢复训练。这将确保你可以在中断训练后继续进行,而不必重新开始。有两种方法可以从检查点恢复训练。
第一种方法使用output_dir previous_output_dir参数从output_dir中存储的最新检查点恢复训练。在这种情况下,你应该删除overwrite_output_dir:
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate第二种方法使用resume_from_checkpoint path_to_specific_checkpoint参数从特定检查点文件夹恢复训练。
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate分享你的模型
所有脚本都可以将你的最终模型上传到模型中心。确保在开始之前已经登录到 Hugging Face:
huggingface-cli login然后在脚本中添加push_to_hub参数。这个参数将创建一个存储库,其中包含你的 Hugging Face 用户名和output_dir中指定的文件夹名称。
给你的存储库起一个特定的名称,使用push_to_hub_model_id参数添加它。存储库将自动列在你的命名空间下。
以下示例展示了如何上传具有特定存储库名称的模型:
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate使用🤗 Accelerate 进行分布式训练
随着模型变得更大,并行性已经成为在有限硬件上训练更大模型并通过几个数量级加速训练速度的策略。在 Hugging Face,我们创建了🤗 Accelerate库,以帮助用户轻松地在任何类型的分布式设置上训练🤗 Transformers 模型,无论是在一台机器上的多个 GPU 还是跨多台机器的多个 GPU。在本教程中,了解如何自定义您的本地 PyTorch 训练循环以在分布式环境中进行训练。
设置
通过安装🤗 Accelerate 开始:
pip install accelerate然后导入并创建一个Accelerator对象。Accelerator将自动检测您的分布式设置类型,并初始化所有必要的组件进行训练。您不需要明确将模型放在设备上。
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()准备加速
下一步是将所有相关的训练对象传递给prepare方法。这包括您的训练和评估 DataLoaders,一个模型和一个优化器:
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )向后
最后一个补充是用🤗 Accelerate 的backward方法替换训练循环中典型的loss.backward():
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)如下面的代码所示,您只需要向训练循环中添加四行额外的代码即可启用分布式训练!
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)训练
添加了相关代码行后,可以在脚本或类似 Colaboratory 的笔记本中启动训练。
使用脚本进行训练
如果您从脚本中运行训练,请运行以下命令以创建并保存配置文件:
accelerate config然后启动您的训练:
accelerate launch train.py使用笔记本进行训练
🤗 Accelerate 也可以在笔记本中运行,如果您计划使用 Colaboratory 的 TPU。将负责训练的所有代码包装在一个函数中,并将其传递给notebook_launcher:
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)有关🤗 Accelerate 及其丰富功能的更多信息,请参考文档。
使用🤗 PEFT 加载适配器
参数高效微调(PEFT)方法在微调期间冻结预训练模型参数,并在其上添加少量可训练参数(适配器)。适配器被训练以学习特定任务的信息。这种方法已被证明在使用更低的计算资源的同时产生与完全微调模型相媲美的结果时非常节省内存。
使用 PEFT 训练的适配器通常比完整模型小一个数量级,这样方便分享、存储和加载。
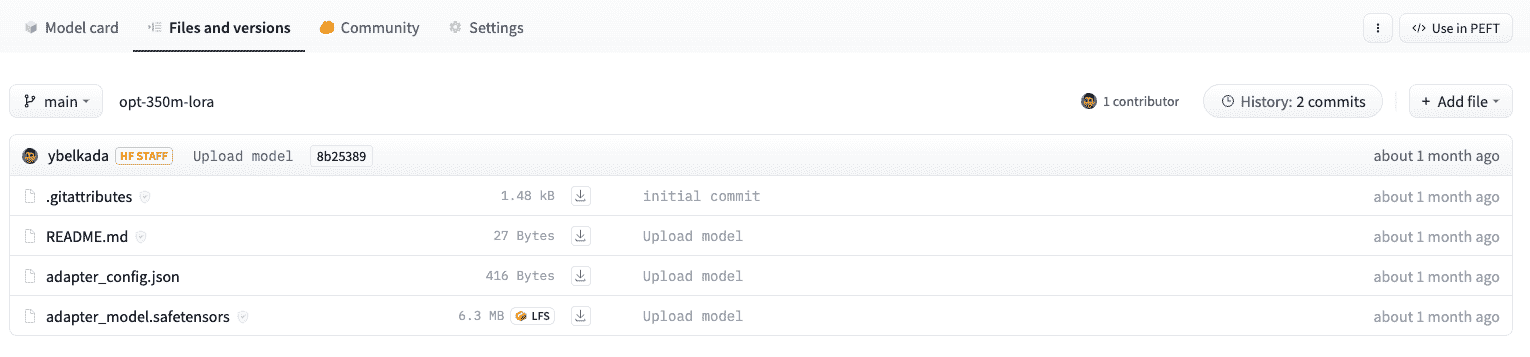
存储在 Hub 上的 OPTForCausalLM 模型的适配器权重仅约为 6MB,而模型权重的完整大小可能约为 700MB。
如果您想了解更多关于🤗 PEFT 库的信息,请查看文档。
设置
通过安装🤗 PEFT 来开始:
pip install peft如果您想尝试全新的功能,您可能会对从源代码安装库感兴趣:
pip install git+https://github.com/huggingface/peft.git支持的 PEFT 模型
🤗 Transformers 原生支持一些 PEFT 方法,这意味着您可以加载本地或 Hub 上存储的适配器权重,并使用几行代码轻松运行或训练它们。支持以下方法:
如果您想使用其他 PEFT 方法,如提示学习或提示调整,或者了解🤗 PEFT 库的一般信息,请参考文档。
加载 PEFT 适配器
加载和使用🤗 Transformers 中的 PEFT 适配器模型时,请确保 Hub 存储库或本地目录包含一个adapter_config.json文件和适配器权重,如上面的示例图所示。然后,您可以使用AutoModelFor类加载 PEFT 适配器模型。例如,要加载用于因果语言建模的 PEFT 适配器模型:
- 指定 PEFT 模型 ID
- 将其传递给 AutoModelForCausalLM 类
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)您可以使用AutoModelFor类或基本模型类(如OPTForCausalLM或LlamaForCausalLM)加载 PEFT 适配器。
您还可以通过调用load_adapter方法加载 PEFT 适配器:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)以 8 位或 4 位加载
bitsandbytes集成支持 8 位和 4 位精度数据类型,对于加载大型模型很有用,因为它节省内存(请参阅bitsandbytes集成指南以了解更多)。将load_in_8bit或load_in_4bit参数添加到 from_pretrained()中,并设置device_map="auto"以有效地将模型分配到您的硬件:
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, device_map="auto", load_in_8bit=True)添加一个新适配器
您可以使用~peft.PeftModel.add_adapter将一个新适配器添加到具有现有适配器的模型中,只要新适配器与当前适配器的类型相同。例如,如果您有一个已经连接到模型的现有 LoRA 适配器:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")添加一个新适配器:
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")现在您可以使用~peft.PeftModel.set_adapter来设置要使用的适配器:
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))启用和禁用适配器
一旦您向模型添加了适配器,您可以启用或禁用适配器模块。要启用适配器模块:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)要禁用适配器模块:
model.disable_adapters()
output = model.generate(**inputs)训练一个 PEFT 适配器
PEFT 适配器受 Trainer 类支持,因此您可以为特定用例训练一个适配器。只需要添加几行代码。例如,要训练一个 LoRA 适配器:
如果您不熟悉使用 Trainer 微调模型,请查看微调预训练模型教程。
- 使用任务类型和超参数定义您的适配器配置(有关超参数的详细信息,请参阅
~peft.LoraConfig)。
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)- 将适配器添加到模型中。
model.add_adapter(peft_config)- 现在您可以将模型传递给 Trainer!
trainer = Trainer(model=model, ...)
trainer.train()保存您训练过的适配器并加载回来:
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)向 PEFT 适配器添加额外的可训练层
您还可以通过在 PEFT 配置中传递modules_to_save来在已附加适配器的模型顶部微调额外的可训练适配器。例如,如果您想在具有 LoRA 适配器的模型顶部也微调 lm_head:
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
modules_to_save=["lm_head"],
)
model.add_adapter(lora_config)分享模型
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_sharing
最后两个教程展示了如何使用 PyTorch、Keras 和🤗加速进行分布式设置对模型进行微调。下一步是与社区分享您的模型!在 Hugging Face,我们相信公开分享知识和资源,以使人人都能民主化人工智能。我们鼓励您考虑与社区分享您的模型,以帮助他人节省时间和资源。
在本教程中,您将学习两种在模型中心上分享经过训练或微调模型的方法:
- 通过程序将文件推送到 Hub。
- 通过 Web 界面将文件拖放到 Hub 中。
www.youtube.com/embed/XvSGPZFEjDY
要与社区分享模型,您需要在huggingface.co上拥有一个帐户。您还可以加入现有组织或创建一个新组织。
存储库功能
模型中心上的每个存储库的行为类似于典型的 GitHub 存储库。我们的存储库提供版本控制、提交历史记录和可视化差异的功能。
模型中心内置的版本控制基于 git 和git-lfs。换句话说,您可以将一个模型视为一个存储库,实现更大的访问控制和可扩展性。版本控制允许修订,这是通过提交哈希、标签或分支固定模型的特定版本的方法。
因此,您可以使用revision参数加载特定模型版本:
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="v2.0.1" # tag name, or branch name, or commit hash
... )文件也可以在存储库中轻松编辑,您还可以查看提交历史记录以及差异:
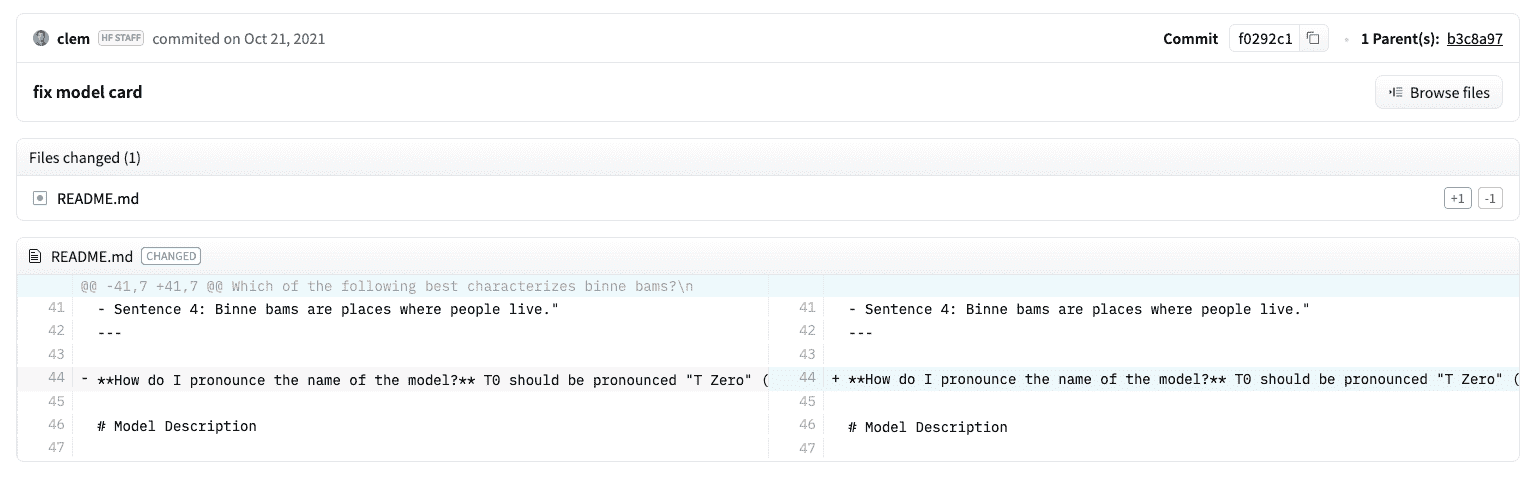
vis_diff
设置
在将模型分享到 Hub 之前,您将需要您的 Hugging Face 凭据。如果您可以访问终端,请在安装🤗 Transformers 的虚拟环境中运行以下命令。这将在您的 Hugging Face 缓存文件夹(默认为~/.cache/)中存储您的访问令牌:
huggingface-cli login如果您正在使用 Jupyter 或 Colaboratory 等笔记本,请确保已安装huggingface_hub库。该库允许您以编程方式与 Hub 进行交互。
pip install huggingface_hub然后使用notebook_login登录到 Hub,并按照链接此处生成一个令牌以登录:
>>> from huggingface_hub import notebook_login
>>> notebook_login()将模型转换为所有框架
为确保您的模型可以被使用不同框架的人使用,我们建议您将您的模型转换并上传为 PyTorch 和 TensorFlow 检查点。虽然用户仍然可以从不同框架加载您的模型,如果您跳过此步骤,加载速度会较慢,因为🤗 Transformers 需要即时转换检查点。
将另一个框架的检查点转换为另一个框架很容易。确保您已安装 PyTorch 和 TensorFlow(请参阅此处获取安装说明),然后在另一个框架中找到适合您任务的特定模型。
Pytorch 隐藏 Pytorch 内容
指定from_tf=True以将 TensorFlow 的检查点转换为 PyTorch:
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")TensorFlow 隐藏 TensorFlow 内容
指定from_pt=True以将 PyTorch 的检查点转换为 TensorFlow:
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)然后,您可以使用新的检查点保存您的新 TensorFlow 模型:
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")JAX 隐藏 JAX 内容
如果一个模型在 Flax 中可用,您也可以将 PyTorch 的检查点转换为 Flax:
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )在训练期间推送模型
Pytorch 隐藏 Pytorch 内容
www.youtube-nocookie.com/embed/Z1-XMy-GNLQ
将模型共享到 Hub 就像添加一个额外的参数或回调一样简单。请记住来自微调教程中,TrainingArguments 类是您指定超参数和额外训练选项的地方。其中一个训练选项包括直接将模型推送到 Hub 的能力。在您的 TrainingArguments 中设置push_to_hub=True:
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)像往常一样将您的训练参数传递给 Trainer:
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )在微调您的模型后,调用 push_to_hub()在 Trainer 上将训练好的模型推送到 Hub。🤗 Transformers 甚至会自动将训练超参数、训练结果和框架版本添加到您的模型卡中!
>>> trainer.push_to_hub()TensorFlow 隐藏 TensorFlow 内容
使用 PushToHubCallback 将模型共享到 Hub。在 PushToHubCallback 函数中,添加:
- 一个用于您的模型的输出目录。
- 一个分词器。
-
hub_model_id,即您的 Hub 用户名和模型名称。
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )将回调添加到fit,🤗 Transformers 将推送训练好的模型到 Hub:
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)使用push_to_hub函数
您还可以直接在您的模型上调用push_to_hub来将其上传到 Hub。
在push_to_hub中指定您的模型名称:
>>> pt_model.push_to_hub("my-awesome-model")这将在您的用户名下创建一个名为my-awesome-model的模型存储库。用户现在可以使用from_pretrained函数加载您的模型:
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")如果您属于一个组织,并希望将您的模型推送到组织名称下,只需将其添加到repo_id中:
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")push_to_hub函数也可以用于向模型存储库添加其他文件。例如,向模型存储库添加一个分词器:
>>> tokenizer.push_to_hub("my-awesome-model")或者您可能想要添加您微调的 PyTorch 模型的 TensorFlow 版本:
>>> tf_model.push_to_hub("my-awesome-model")现在当您导航到您的 Hugging Face 个人资料时,您应该看到您新创建的模型存储库。点击文件选项卡将显示您上传到存储库的所有文件。
有关如何创建和上传文件到存储库的更多详细信息,请参考 Hub 文档这里。
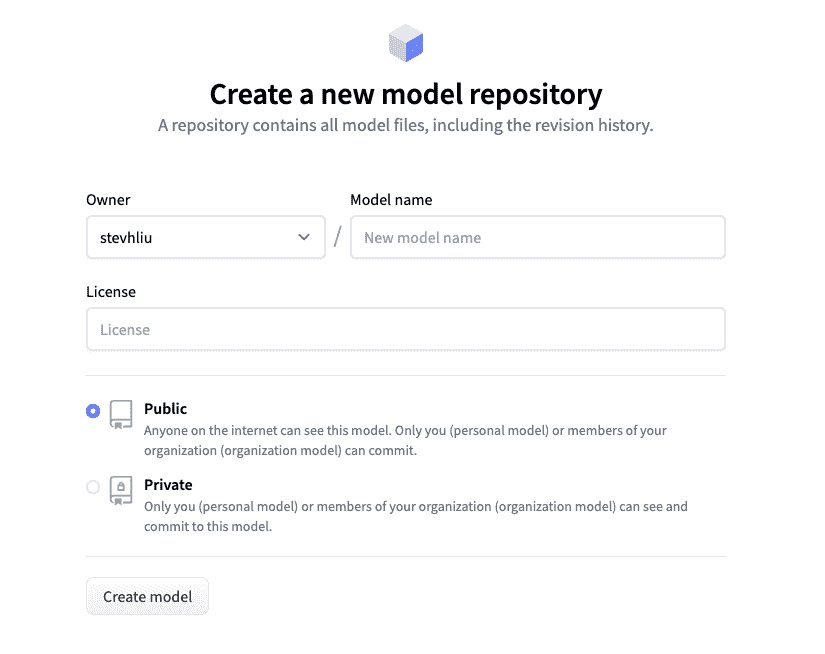
使用 Web 界面上传
喜欢无代码方法的用户可以通过 Hub 的 Web 界面上传模型。访问huggingface.co/new创建一个新存储库:
new_model_repo
在这里,添加有关您的模型的一些信息:
- 选择存储库的所有者。这可以是您自己或您所属的任何组织。
- 为您的模型选择一个名称,这也将是存储库名称。
- 选择您的模型是公开的还是私有的。
- 为您的模型指定许可证使用情况。
现在点击文件选项卡,然后点击添加文件按钮将新文件上传到您的存储库。然后拖放文件进行上传并添加提交消息。
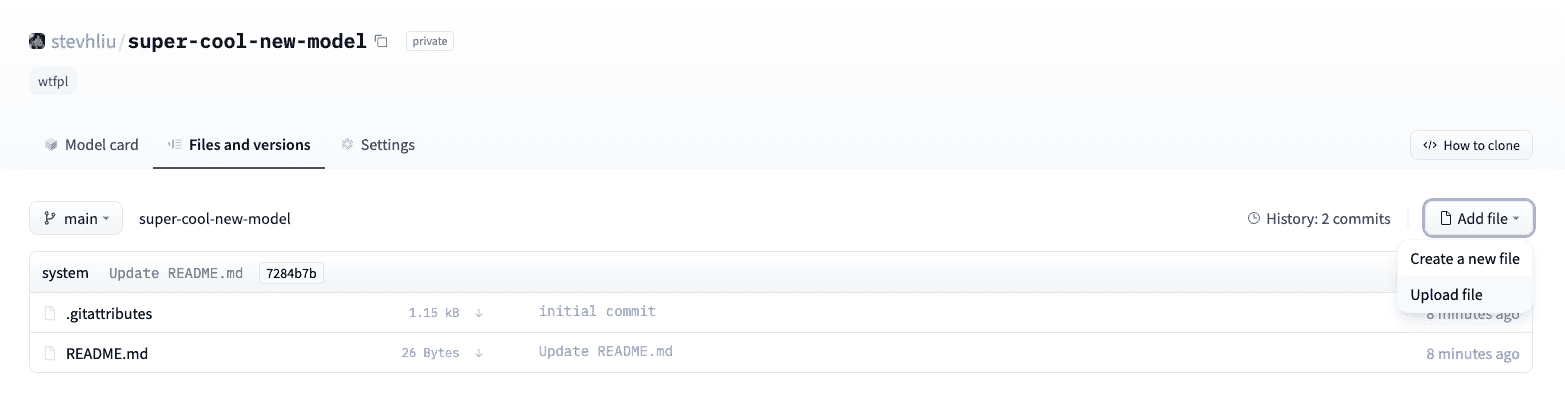
upload_file
添加一个模型卡
为确保用户了解您的模型的功能、限制、潜在偏见和道德考虑,请向您的存储库添加一个模型卡。模型卡在README.md文件中定义。您可以通过以下方式添加模型卡:
- 手动创建和上传
README.md文件。 - 点击您的模型存储库中的编辑模型卡按钮。
查看 DistilBert 的模型卡片,这是模型卡片应包含的信息类型的一个很好的例子。有关您可以在README.md文件中控制的其他选项的更多详细信息,例如模型的碳足迹或小部件示例,请参考此处的文档。
Transformers Agents
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/transformers_agents
Transformers Agents 是一个实验性 API,随时可能会发生变化。由代理返回的结果可能会有所不同,因为 API 或基础模型容易发生变化。
Transformers 版本 v4.29.0,构建在工具和代理的概念之上。您可以在此 colab中进行操作。
简而言之,它提供了一个自然语言 API,基于 transformers:我们定义了一组精心策划的工具,并设计了一个代理来解释自然语言并使用这些工具。它是可扩展的设计;我们策划了一些相关工具,但我们将向您展示系统如何轻松扩展以使用社区开发的任何工具。
让我们从几个示例开始,展示这个新 API 可以实现的功能。当涉及多模态任务时,它特别强大,因此让我们试一试生成图像并大声朗读文本。
agent.run("Caption the following image", image=image)输入 | 输出 |
|---|---|
一只海狸正在水中游泳 |

agent.run("Read the following text out loud", text=text)输入 | 输出 |
|---|---|
一只海狸正在水中游泳 |
您的浏览器不支持音频元素。 |
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)输入 | 输出 |
|---|---|
舞厅门厅 |
快速开始
在能够使用agent.run之前,您需要实例化一个代理,这是一个大型语言模型(LLM)。我们支持 openAI 模型以及来自 BigCode 和 OpenAssistant 的开源替代方案。openAI 模型表现更好(但需要您拥有 openAI API 密钥,因此不能免费使用);Hugging Face 为 BigCode 和 OpenAssistant 模型提供免费访问端点。
首先,请安装agents额外组件以安装所有默认依赖项。
pip install transformers[agents]要使用 openAI 模型,您需要在安装openai依赖项后实例化 OpenAiAgent:
pip install openaifrom transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")要使用 BigCode 或 OpenAssistant,请先登录以访问推理 API:
from huggingface_hub import login
login("<YOUR_TOKEN>")然后,实例化代理
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")这是目前 Hugging Face 免费提供的推理 API。如果您有自己的推理端点用于此模型(或其他模型),可以用您的 URL 端点替换上面的 URL。
StarCoder 和 OpenAssistant 是免费使用的,并在简单任务上表现出色。但是,在处理更复杂的提示时,检查点无法保持。如果您遇到此类问题,我们建议尝试 OpenAI 模型,尽管遗憾的是,它不是开源的,但在当前时间表现更好。
现在您可以开始了!让我们深入了解您现在可以使用的两个 API。
单次执行(运行)
单次执行方法是使用代理的 run()方法:
agent.run("Draw me a picture of rivers and lakes.")
它会自动选择适合您要执行的任务的工具(或工具),并适当运行它们。它可以在同一指令中执行一个或多个任务(尽管您的指令越复杂,代理失败的可能性就越大)。
agent.run("Draw me a picture of the sea then transform the picture to add an island")
每个 run()操作都是独立的,因此您可以连续运行多次,执行不同的任务。
请注意,您的代理只是一个大型语言模型,因此提示中的细微变化可能会产生完全不同的结果。尽可能清楚地解释您想要执行的任务是很重要的。我们在这里更深入地讨论如何编写良好的提示这里。
如果您想在执行过程中保持状态或向代理传递非文本对象,可以通过指定您希望代理使用的变量来实现。例如,您可以生成河流和湖泊的第一幅图像,并要求模型更新该图片以添加一个岛屿,方法如下:
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)当模型无法理解您的请求并混合工具时,这可能会有所帮助。一个例子是:
agent.run("Draw me the picture of a capybara swimming in the sea")在这里,模型可以以两种方式解释:
- 让
text-to-image生成一只在海里游泳的水豚 - 或者,让
text-to-image生成水豚,然后使用image-transformation工具让它在海里游泳
如果您想强制执行第一个场景,可以通过将提示作为参数传递给它来实现:
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")基于聊天的执行(chat)
代理还采用了基于聊天的方法,使用 chat()方法:
agent.chat("Generate a picture of rivers and lakes")
agent.chat("Transform the picture so that there is a rock in there")
当您想要跨指令保持状态时,这是一种有趣的方法。这对于实验很有帮助,但往往更擅长单个指令,而不是复杂指令(run()方法更擅长处理)。
如果您想传递非文本类型或特定提示,这种方法也可以接受参数。
⚠️ 远程执行
出于演示目的,以便可以与所有设置一起使用,我们已经为代理可以访问的默认工具的几个远程执行器创建了。这些是使用inference endpoints创建的。
我们现在已经关闭了这些,但为了看到如何设置远程执行工具,我们建议阅读自定义工具指南。
这里发生了什么?什么是工具,什么是代理?
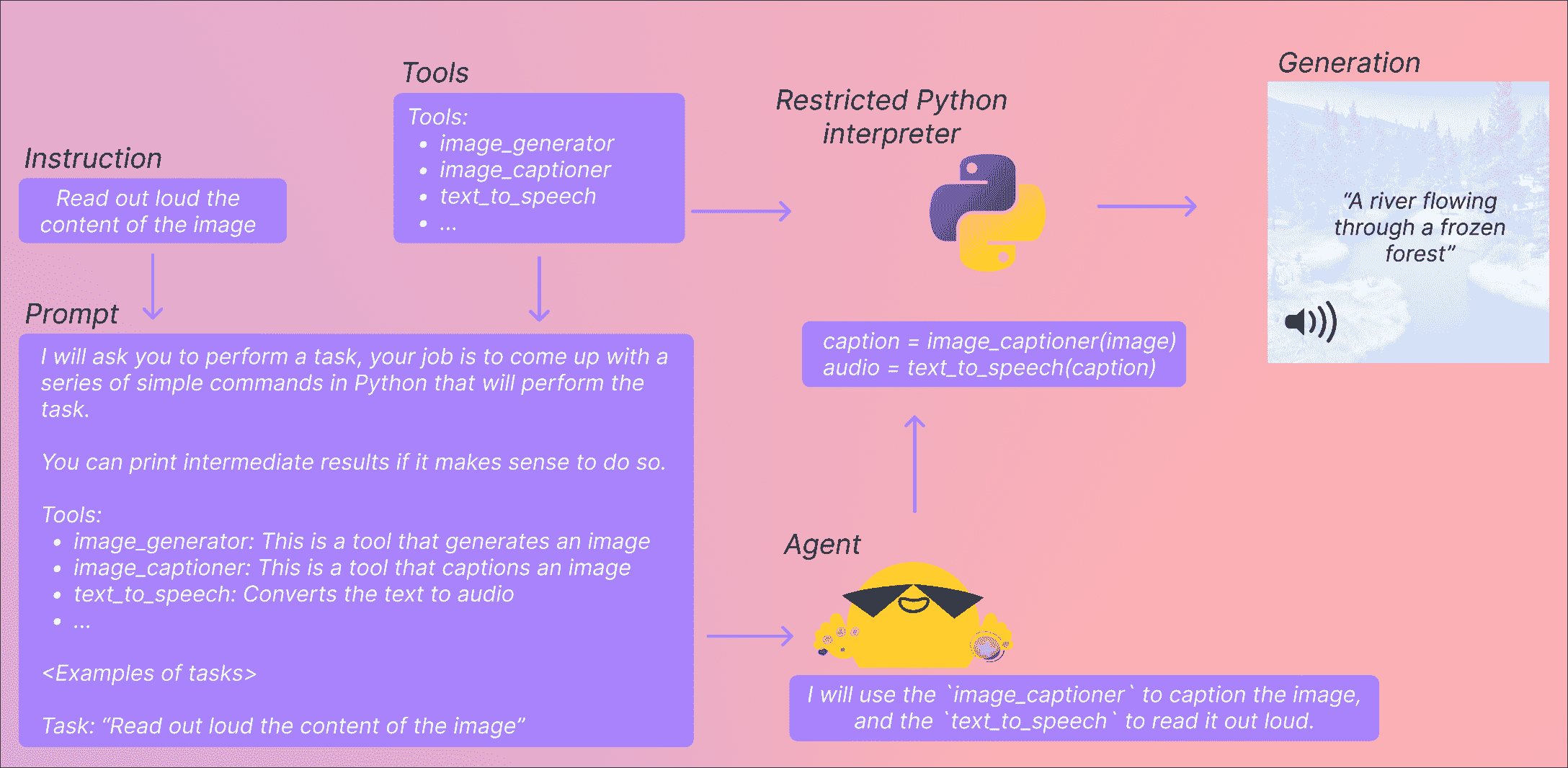
代理
这里的“代理”是一个大型语言模型,我们正在提示它,以便它可以访问特定的一组工具。
LLMs 在生成小样本代码方面表现得相当不错,因此这个 API 利用 LLM 的这一特点,通过提示 LLM 给出执行任务的一组工具的小样本代码。然后,您给代理的任务和您给它的工具描述完成这个提示。这样它就可以访问您正在使用的工具的文档,特别是它们的预期输入和输出,并生成相关的代码。
工具
工具非常简单:它们是一个函数,带有名称和描述。然后我们使用这些工具的描述来提示代理。通过提示,我们向代理展示如何利用工具执行查询中请求的任务。
这里使用全新的工具而不是流水线,因为代理使用非常原子化的工具编写更好的代码。流水线更加重构,通常将多个任务合并为一个。工具旨在专注于一个非常简单的任务。
代码执行?!
然后,这段代码将在我们的小型 Python 解释器上执行,同时传递您的工具和输入集。我们听到您在后面尖叫“任意代码执行!”,但让我们解释为什么情况并非如此。
只能调用您提供的工具和打印函数,因此可以执行的内容已经受到限制。如果限制在 Hugging Face 工具上,那么您应该是安全的。
然后,我们不允许任何属性查找或导入(对于传递输入/输出到一小组函数来说,这些都不应该是必要的),因此所有最明显的攻击(无论如何,您需要提示 LLM 输出它们)都不应该是问题。如果您想更加安全,可以执行带有额外参数 return_code=True 的 run()方法,这样代理将只返回要执行的代码,您可以决定是否执行。
如果尝试执行非法操作或代码生成的 Python 错误时,执行将停止。
精心挑选的工具
我们确定了一组可以增强这些代理的工具。以下是我们在transformers中集成的工具的更新列表:
- 文档问答:给定一个文档(如 PDF)的图像格式,回答关于该文档的问题(Donut)
- 文本问答:给定一段长文本和一个问题,在文本中回答问题(Flan-T5)
- 无条件图像字幕:给图像加上字幕!(BLIP)
- 图像问答:给定一幅图像,在这幅图像上回答一个问题(VILT)
- 图像分割:给定一幅图像和一个提示,输出该提示的分割蒙版(CLIPSeg)
- 语音转文本:给定一个人说话的音频录音,将语音转录为文本(Whisper)
- 文本转语音:将文本转换为语音(SpeechT5)
- 零样本文本分类:给定一个文本和一个标签列表,确定文本对应于哪个标签最多(BART)
- 文本摘要:将长文本总结为一句或几句话(BART)
- 翻译:将文本翻译成指定语言(NLLB)
这些工具已经在 transformers 中集成,也可以手动使用,例如:
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")自定义工具
虽然我们确定了一组精心挑选的工具,但我们坚信这个实现提供的主要价值是快速创建和共享自定义工具的能力。
通过将工具的代码推送到 Hugging Face Space 或模型存储库,您就能直接利用代理。我们已经向huggingface-tools组织添加了一些transformers-agnostic工具:
- 文本下载器:从网址下载文本
- 文本转图像:根据提示生成一幅图像,利用稳定的扩散
- 图像转换:根据初始图像和提示修改图像,利用指导 pix2pix 稳定扩散
- 文本到视频:根据提示生成一个小视频,利用 damo-vilab
我们从一开始就在使用的文本到图像工具是一个远程工具,位于huggingface-tools/text-to-image!我们将继续在这个和其他组织上发布这样的工具,以进一步增强这个实现。
默认情况下,代理可以访问位于huggingface-tools上的工具。我们将解释如何编写和共享您的工具,以及如何利用存储在 Hub 上的任何自定义工具的以下指南。
代码生成
到目前为止,我们已经展示了如何使用代理来为您执行操作。然而,代理只是生成代码,然后我们使用一个非常受限的 Python 解释器来执行。如果您想在不同的环境中使用生成的代码,可以提示代理返回代码,以及工具定义和准确的导入。
例如,以下指令
agent.run("Draw me a picture of rivers and lakes", return_code=True)返回以下代码
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")然后您可以修改并自行执行。
LLMs 的生成
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/llm_tutorial
LLMs,或大型语言模型,是文本生成背后的关键组件。简而言之,它们由大型预训练的变压器模型组成,训练用于预测给定一些输入文本的下一个单词(或更准确地说,令牌)。由于它们一次预测一个令牌,因此您需要做一些更复杂的事情来生成新的句子,而不仅仅是调用模型 - 您需要进行自回归生成。
自回归生成是在推理时迭代调用模型以生成输出的过程,给定一些初始输入。在🤗 Transformers 中,这由 generate()方法处理,适用于所有具有生成能力的模型。
本教程将向您展示如何:
- 使用 LLM 生成文本
- 避免常见陷阱
- 帮助您充分利用 LLM 的下一步
在开始之前,请确保您已安装所有必要的库:
pip install transformers bitsandbytes>=0.39.0 -q生成文本
进行因果语言建模训练的语言模型将文本令牌序列作为输入,并返回下一个令牌的概率分布。
“LLM 的前向传递”
LLMs 进行自回归生成的一个关键方面是如何从这个概率分布中选择下一个令牌。在这一步中可以采取任何方法,只要最终得到下一次迭代的令牌即可。这意味着它可以简单地从概率分布中选择最可能的令牌,也可以在从结果分布中抽样之前应用十几种转换。
“自回归生成通过从概率分布中迭代选择下一个令牌来生成文本”
上述过程会重复迭代,直到达到某个停止条件。理想情况下,停止条件由模型决定,该模型应该学会何时输出一个终止序列(EOS)令牌。如果不是这种情况,当达到某个预定义的最大长度时,生成会停止。
正确设置令牌选择步骤和停止条件对于使您的模型在任务上表现如您期望的方式至关重要。这就是为什么我们为每个模型关联一个 GenerationConfig 文件,其中包含一个良好的默认生成参数设置,并且与您的模型一起加载。
让我们谈谈代码!
如果您对基本 LLM 用法感兴趣,我们的高级Pipeline接口是一个很好的起点。然而,LLMs 通常需要高级功能,如量化和对令牌选择步骤的精细控制,最好通过 generate()来实现。LLMs 的自回归生成也需要大量资源,并且应该在 GPU 上执行以获得足够的吞吐量。
首先,您需要加载模型。
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )您会注意到from_pretrained调用中有两个标志:
-
device_map确保模型被移动到您的 GPU 上 -
load_in_4bit应用 4 位动态量化以大幅减少资源需求
还有其他初始化模型的方法,但这是一个很好的基准,可以开始使用 LLM。
接下来,您需要使用 tokenizer 对文本输入进行预处理。
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")model_inputs变量保存了标记化的文本输入,以及注意力掩码。虽然 generate()会尽力推断注意力掩码,但我们建议尽可能在生成时传递它以获得最佳结果。
在对输入进行标记化后,您可以调用 generate()方法返回生成的标记。然后应将生成的标记转换为文本后打印。
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'最后,您不需要一次处理一个序列!您可以对输入进行批处理,这将大大提高吞吐量,同时延迟和内存成本很小。您只需要确保正确填充输入即可(下文有更多信息)。
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']就是这样!在几行代码中,您就可以利用 LLM 的强大功能。
常见陷阱
有许多生成策略,有时默认值可能不适合您的用例。如果您的输出与您的预期不符,我们已经创建了一个关于最常见陷阱以及如何避免它们的列表。
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )生成的输出过短/过长
如果在 GenerationConfig 文件中未指定,generate默认返回最多 20 个标记。我们强烈建议在generate调用中手动设置max_new_tokens以控制它可以返回的最大新标记数量。请记住,LLMs(更准确地说,仅解码器模型)还会将输入提示作为输出的一部分返回。
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'生成模式不正确
默认情况下,除非在 GenerationConfig 文件中指定,generate在每次迭代中选择最可能的标记(贪婪解码)。根据您的任务,这可能是不希望的;像聊天机器人或写作文章这样的创造性任务受益于抽样。另一方面,像音频转录或翻译这样的输入驱动任务受益于贪婪解码。通过do_sample=True启用抽样,您可以在此博客文章中了解更多关于这个主题的信息。
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'填充方向错误
LLMs 是仅解码器架构,意味着它们会继续迭代您的输入提示。如果您的输入长度不同,就需要进行填充。由于 LLMs 没有经过训练以从填充标记继续,因此您的输入需要进行左填充。确保不要忘记传递注意力掩码以生成!
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'提示错误
一些模型和任务期望特定的输入提示格式才能正常工作。如果未应用此格式,您将获得沉默的性能下降:模型可能会运行,但不如按照预期提示那样好。有关提示的更多信息,包括哪些模型和任务需要小心,可在此指南中找到。让我们看一个聊天 LLM 的示例,它使用聊天模板:
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
... )
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
... {
... "role": "system",
... "content": "You are a friendly chatbot who always responds in the style of a thug",
... },
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎更多资源
虽然自回归生成过程相对简单,但充分利用您的 LLM 可能是一项具有挑战性的努力,因为其中有许多要素。为了帮助您深入了解 LLM 的使用和理解,请继续以下步骤:
高级生成用法
- 指南关于如何控制不同的生成方法,如何设置生成配置文件,以及如何流式传输输出;
- 指南关于聊天 LLM 的提示模板;
- 指南如何充分利用提示设计;
- GenerationConfig 上的 API 参考,generate(),以及 generate-related classes。大多数类,包括 logits 处理器,都有使用示例!
LLM 排行榜
- Open LLM Leaderboard,专注于开源模型的质量;
- Open LLM-Perf Leaderboard,专注于 LLM 吞吐量。
延迟、吞吐量和内存利用率
- Guide 如何优化 LLMs 的速度和内存;
- Guide 关于量化,如 bitsandbytes 和 autogptq,展示了如何大幅减少内存需求。
相关库
-
text-generation-inference,一个为 LLMs 准备的生产就绪服务器; -
optimum,一个 🤗 Transformers 的扩展,针对特定硬件设备进行优化。
任务指南
自然语言处理
文本分类
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/tasks/sequence_classification
www.youtube-nocookie.com/embed/leNG9fN9FQU
文本分类是一项常见的 NLP 任务,它为文本分配标签或类别。一些最大的公司在生产中运行文本分类,用于各种实际应用。文本分类中最流行的形式之一是情感分析,它为一系列文本分配标签如🙂积极,🙁消极或😐中性。
本指南将向您展示如何:
- 在IMDb数据集上对DistilBERT进行微调,以确定电影评论是积极的还是消极的。
- 使用您的微调模型进行推理。
本教程中演示的任务由以下模型架构支持:
ALBERT, BART, BERT, BigBird, BigBird-Pegasus, BioGpt, BLOOM, CamemBERT, CANINE, CodeLlama, ConvBERT, CTRL, Data2VecText, DeBERTa, DeBERTa-v2, DistilBERT, ELECTRA, ERNIE, ErnieM, ESM, Falcon, FlauBERT, FNet, Funnel Transformer, GPT-Sw3, OpenAI GPT-2, GPTBigCode, GPT Neo, GPT NeoX, GPT-J, I-BERT, LayoutLM, LayoutLMv2, LayoutLMv3, LED, LiLT, LLaMA, Longformer, LUKE, MarkupLM, mBART, MEGA, Megatron-BERT, Mistral, Mixtral, MobileBERT, MPNet, MPT, MRA, MT5, MVP, Nezha, Nyströmformer, OpenLlama, OpenAI GPT, OPT, Perceiver, Persimmon, Phi, PLBart, QDQBert, Qwen2, Reformer, RemBERT, RoBERTa, RoBERTa-PreLayerNorm, RoCBert, RoFormer, SqueezeBERT, T5, TAPAS, Transformer-XL, UMT5, XLM, XLM-RoBERTa, XLM-RoBERTa-XL, XLNet, X-MOD, YOSO
在开始之前,请确保您已安装所有必要的库:
pip install transformers datasets evaluate accelerate我们鼓励您登录您的 Hugging Face 账户,这样您就可以上传和与社区分享您的模型。在提示时,输入您的令牌以登录:
>>> from huggingface_hub import notebook_login
>>> notebook_login()加载 IMDb 数据集
首先从🤗数据集库中加载 IMDb 数据集:
>>> from datasets import load_dataset
>>> imdb = load_dataset("imdb")然后看一个例子:
>>> imdb["test"][0]
{
"label": 0,
"text": "I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn't match the background, and painfully one-dimensional characters cannot be overcome with a 'sci-fi' setting. (I'm sure there are those of you out there who think Babylon 5 is good sci-fi TV. It's not. It's clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It's really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it's rubbish as they have to always say \"Gene Roddenberry's Earth...\" otherwise people would not continue watching. Roddenberry's ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.",
}这个数据集中有两个字段:
-
text: 电影评论文本。 -
label: 一个值,要么是0表示负面评价,要么是1表示正面评价。
预处理
下一步是加载 DistilBERT 标记器来预处理 text 字段:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")创建一个预处理函数来对 text 进行标记化,并截断序列,使其不超过 DistilBERT 的最大输入长度:
>>> def preprocess_function(examples):
... return tokenizer(examples["text"], truncation=True)应用预处理函数到整个数据集,使用🤗 Datasets map 函数。您可以通过设置 batched=True 来加速 map,以一次处理数据集的多个元素:
tokenized_imdb = imdb.map(preprocess_function, batched=True)现在使用 DataCollatorWithPadding 创建一个示例批次。在整理过程中,动态填充句子到批次中的最长长度比整个数据集填充到最大长度更有效。
Pytorch 隐藏 Pytorch 内容
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer)TensorFlow 隐藏 TensorFlow 内容
>>> from transformers import DataCollatorWithPadding
>>> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")评估
在训练过程中包含一个度量通常有助于评估模型的性能。您可以使用 🤗 Evaluate 库快速加载一个评估方法。对于这个任务,加载 accuracy 度量(查看 🤗 Evaluate 快速导览 以了解如何加载和计算度量):
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")然后创建一个函数,将您的预测和标签传递给 compute 来计算准确率:
>>> import numpy as np
>>> def compute_metrics(eval_pred):
... predictions, labels = eval_pred
... predictions = np.argmax(predictions, axis=1)
... return accuracy.compute(predictions=predictions, references=labels)您的 compute_metrics 函数现在已经准备就绪,当您设置训练时会返回到它。
训练
在开始训练模型之前,使用 id2label 和 label2id 创建预期 id 到标签的映射:
>>> id2label = {0: "NEGATIVE", 1: "POSITIVE"}
>>> label2id = {"NEGATIVE": 0, "POSITIVE": 1}Pytorch 隐藏 Pytorch 内容
如果您不熟悉如何使用 Trainer 对模型进行微调,请查看这里的基本教程!
现在您已经准备好开始训练您的模型了!加载 DistilBERT 与 AutoModelForSequenceClassification 以及预期标签的数量和标签映射:
>>> from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
>>> model = AutoModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
... )此时,只剩下三个步骤:
- 在 TrainingArguments 中定义您的训练超参数。唯一必需的参数是
output_dir,指定保存模型的位置。通过设置push_to_hub=True将此模型推送到 Hub(您需要登录 Hugging Face 以上传您的模型)。在每个 epoch 结束时,Trainer 将评估准确率并保存训练检查点。 - 将训练参数传递给 Trainer,以及模型、数据集、标记器、数据整理器和
compute_metrics函数。 - 调用 train() 来微调您的模型。
>>> training_args = TrainingArguments(
... output_dir="my_awesome_model",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=2,
... weight_decay=0.01,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_imdb["train"],
... eval_dataset=tokenized_imdb["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()当您将 tokenizer 传递给 Trainer 时,默认情况下会应用动态填充。在这种情况下,您不需要显式指定数据整理器。
训练完成后,使用 push_to_hub() 方法将您的模型分享到 Hub,这样每个人都可以使用您的模型:
>>> trainer.push_to_hub()TensorFlow 隐藏 TensorFlow 内容
如果您不熟悉如何使用 Keras 对模型进行微调,请查看这里的基本教程!
要在 TensorFlow 中微调模型,请首先设置优化器函数、学习率调度和一些训练超参数:
>>> from transformers import create_optimizer
>>> import tensorflow as tf
>>> batch_size = 16
>>> num_epochs = 5
>>> batches_per_epoch = len(tokenized_imdb["train"]) // batch_size
>>> total_train_steps = int(batches_per_epoch * num_epochs)
>>> optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)然后,您可以加载 DistilBERT 与 TFAutoModelForSequenceClassification,以及预期标签的数量和标签映射:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id
... )将您的数据集转换为tf.data.Dataset格式,使用 prepare_tf_dataset():
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_imdb["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_imdb["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )使用compile为训练配置模型。请注意,Transformers 模型都有一个默认的与任务相关的损失函数,因此除非您想要,否则不需要指定一个:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!在开始训练之前设置的最后两件事是从预测中计算准确率,并提供一种将模型推送到 Hub 的方法。这两个都可以通过使用 Keras callbacks 来完成。
将您的compute_metrics函数传递给 KerasMetricCallback:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)指定在 PushToHubCallback 中推送模型和分词器的位置:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_model",
... tokenizer=tokenizer,
... )然后将您的回调捆绑在一起:
>>> callbacks = [metric_callback, push_to_hub_callback]最后,您已经准备好开始训练您的模型了!使用您的训练和验证数据集、时代数和回调来微调模型调用fit:
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)训练完成后,您的模型会自动上传到 Hub,以便每个人都可以使用它!
有关如何为文本分类微调模型的更深入示例,请查看相应的PyTorch 笔记本或TensorFlow 笔记本。
推理
很好,现在您已经对模型进行了微调,可以用它进行推理!
获取一些您想要进行推理的文本:
>>> text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."尝试使用您微调的模型进行推理的最简单方法是在 pipeline()中使用它。用您的模型实例化一个情感分析的pipeline,并将文本传递给它:
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis", model="stevhliu/my_awesome_model")
>>> classifier(text)
[{'label': 'POSITIVE', 'score': 0.9994940757751465}]如果您愿意,也可以手动复制pipeline的结果:
Pytorch 隐藏 Pytorch 内容
对文本进行标记化并返回 PyTorch 张量:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
>>> inputs = tokenizer(text, return_tensors="pt")将您的输入传递给模型并返回logits:
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits获取具有最高概率的类,并使用模型的id2label映射将其转换为文本标签:
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
'POSITIVE'TensorFlow 隐藏 TensorFlow 内容
对文本进行标记化并返回 TensorFlow 张量:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_model")
>>> inputs = tokenizer(text, return_tensors="tf")将您的输入传递给模型并返回logits:
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("stevhliu/my_awesome_model")
>>> logits = model(**inputs).logits获取具有最高概率的类,并使用模型的id2label映射将其转换为文本标签:
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
>>> model.config.id2label[predicted_class_id]
'POSITIVE'标记分类
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/tasks/token_classification
www.youtube-nocookie.com/embed/wVHdVlPScxA
标记分类为句子中的每个单词分配一个标签。最常见的标记分类任务之一是命名实体识别(NER)。NER 试图为句子中的每个实体找到一个标签,比如人名、地点或组织。
本指南将向您展示如何:
- 在 WNUT 17 数据集上对DistilBERT进行微调,以检测新实体。
- 使用您微调的模型进行推断。
本教程中演示的任务由以下模型架构支持:
ALBERT, BERT, BigBird, BioGpt, BLOOM, BROS, CamemBERT, CANINE, ConvBERT, Data2VecText, DeBERTa, DeBERTa-v2, DistilBERT, ELECTRA, ERNIE, ErnieM, ESM, Falcon, FlauBERT, FNet, Funnel Transformer, GPT-Sw3, OpenAI GPT-2, GPTBigCode, GPT Neo, GPT NeoX, I-BERT, LayoutLM, LayoutLMv2, LayoutLMv3, LiLT, Longformer, LUKE, MarkupLM, MEGA, Megatron-BERT, MobileBERT, MPNet, MPT, MRA, Nezha, Nyströmformer, Phi, QDQBert, RemBERT, RoBERTa, RoBERTa-PreLayerNorm, RoCBert, RoFormer, SqueezeBERT, XLM, XLM-RoBERTa, XLM-RoBERTa-XL, XLNet, X-MOD, YOSO
在开始之前,请确保已安装所有必要的库:
pip install transformers datasets evaluate seqeval我们鼓励您登录您的 Hugging Face 账户,这样您就可以上传和分享您的模型给社区。在提示时,输入您的令牌以登录:
>>> from huggingface_hub import notebook_login
>>> notebook_login()加载 WNUT 17 数据集
首先从🤗数据集库中加载 WNUT 17 数据集:
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17")然后看一个例子:
>>> wnut["train"][0]
{'id': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
}ner_tags中的每个数字代表一个实体。将数字转换为它们的标签名称,以找出这些实体是什么:
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> label_list
[
"O",
"B-corporation",
"I-corporation",
"B-creative-work",
"I-creative-work",
"B-group",
"I-group",
"B-location",
"I-location",
"B-person",
"I-person",
"B-product",
"I-product",
]每个ner_tag前缀的字母表示实体的标记位置:
-
B-表示一个实体的开始。 -
I-表示一个单词包含在同一个实体中(例如,State单词是Empire State Building这样一个实体的一部分)。 -
0表示该标记不对应任何实体。
预处理
www.youtube-nocookie.com/embed/iY2AZYdZAr0
下一步是加载一个 DistilBERT 分词器来预处理tokens字段:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")正如您在上面的示例 tokens 字段中看到的,看起来输入已经被标记化了。但实际上输入还没有被标记化,您需要设置 is_split_into_words=True 将单词标记化为子词。例如:
>>> example = wnut["train"][0]
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
>>> tokens
['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']然而,这会添加一些特殊标记 [CLS] 和 [SEP],子词标记化会导致输入和标签之间的不匹配。现在,一个对应于单个标签的单词可能会被拆分为两个子词。您需要通过以下方式重新对齐标记和标签:
- 使用
word_ids方法将所有标记映射到它们对应的单词。 - 将标签
-100分配给特殊标记[CLS]和[SEP],以便它们被 PyTorch 损失函数忽略(参见 CrossEntropyLoss)。 - 仅标记给定单词的第一个标记。将其他来自同一单词的子标记分配为
-100。
以下是如何创建一个函数来重新对齐标记和标签,并截断序列,使其不超过 DistilBERT 的最大输入长度:
>>> def tokenize_and_align_labels(examples):
... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
... labels = []
... for i, label in enumerate(examples[f"ner_tags"]):
... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
... previous_word_idx = None
... label_ids = []
... for word_idx in word_ids: # Set the special tokens to -100.
... if word_idx is None:
... label_ids.append(-100)
... elif word_idx != previous_word_idx: # Only label the first token of a given word.
... label_ids.append(label[word_idx])
... else:
... label_ids.append(-100)
... previous_word_idx = word_idx
... labels.append(label_ids)
... tokenized_inputs["labels"] = labels
... return tokenized_inputs要在整个数据集上应用预处理函数,请使用 🤗 Datasets map 函数。您可以通过设置 batched=True 来加速 map 函数,以一次处理数据集的多个元素:
>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)现在使用 DataCollatorWithPadding 创建一批示例。在整理过程中,将句子动态填充到批次中的最大长度,而不是将整个数据集填充到最大长度。
PytorchHide Pytorch 内容
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)TensorFlowHide TensorFlow 内容
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")评估
在训练过程中包含一个指标通常有助于评估模型的性能。您可以使用 🤗 Evaluate 库快速加载评估方法。对于这个任务,加载 seqeval 框架(查看 🤗 Evaluate 快速入门 了解如何加载和计算指标)。Seqeval 实际上会生成几个分数:精确度、召回率、F1 和准确度。
>>> import evaluate
>>> seqeval = evaluate.load("seqeval")首先获取 NER 标签,然后创建一个函数,将您的真实预测和真实标签传递给 compute 来计算分数:
>>> import numpy as np
>>> labels = [label_list[i] for i in example[f"ner_tags"]]
>>> def compute_metrics(p):
... predictions, labels = p
... predictions = np.argmax(predictions, axis=2)
... true_predictions = [
... [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... true_labels = [
... [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... results = seqeval.compute(predictions=true_predictions, references=true_labels)
... return {
... "precision": results["overall_precision"],
... "recall": results["overall_recall"],
... "f1": results["overall_f1"],
... "accuracy": results["overall_accuracy"],
... }您的 compute_metrics 函数现在已经准备就绪,当您设置训练时会返回到它。
训练
在开始训练模型之前,使用 id2label 和 label2id 创建预期 id 到标签的映射:
>>> id2label = {
... 0: "O",
... 1: "B-corporation",
... 2: "I-corporation",
... 3: "B-creative-work",
... 4: "I-creative-work",
... 5: "B-group",
... 6: "I-group",
... 7: "B-location",
... 8: "I-location",
... 9: "B-person",
... 10: "I-person",
... 11: "B-product",
... 12: "I-product",
... }
>>> label2id = {
... "O": 0,
... "B-corporation": 1,
... "I-corporation": 2,
... "B-creative-work": 3,
... "I-creative-work": 4,
... "B-group": 5,
... "I-group": 6,
... "B-location": 7,
... "I-location": 8,
... "B-person": 9,
... "I-person": 10,
... "B-product": 11,
... "I-product": 12,
... }PytorchHide Pytorch 内容
如果您不熟悉使用 Trainer 对模型进行微调,请查看这里的基本教程 here!
现在您已经准备好开始训练您的模型了!使用 AutoModelForTokenClassification 加载 DistilBERT,以及预期标签数和标签映射:
>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
>>> model = AutoModelForTokenClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )此时,只剩下三个步骤:
- 在 TrainingArguments 中定义您的训练超参数。唯一必需的参数是
output_dir,指定保存模型的位置。通过设置push_to_hub=True将此模型推送到 Hub(您需要登录 Hugging Face 以上传模型)。在每个时代结束时,Trainer 将评估 seqeval 分数并保存训练检查点。 - 将训练参数传递给 Trainer,以及模型、数据集、分词器、数据整理器和
compute_metrics函数。 - 调用 train()来微调您的模型。
>>> training_args = TrainingArguments(
... output_dir="my_awesome_wnut_model",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=2,
... weight_decay=0.01,
... evaluation_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
... tokenizer=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()培训完成后,使用 push_to_hub()方法将您的模型共享到 Hub,以便每个人都可以使用您的模型:
>>> trainer.push_to_hub()隐藏 TensorFlow 内容
如果您不熟悉使用 Keras 微调模型,请查看基本教程这里!
要在 TensorFlow 中微调模型,请首先设置优化器函数、学习率调度和一些训练超参数:
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 3
>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=2e-5,
... num_train_steps=num_train_steps,
... weight_decay_rate=0.01,
... num_warmup_steps=0,
... )然后,您可以加载 DistilBERT 与 TFAutoModelForTokenClassification 以及预期标签的数量和标签映射:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained(
... "distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )使用 prepare_tf_dataset()将数据集转换为tf.data.Dataset格式:
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_wnut["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_wnut["validation"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )使用compile配置模型进行训练。请注意,Transformers 模型都有一个默认的与任务相关的损失函数,因此除非您想要指定一个,否则不需要指定:
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!在开始训练之前设置的最后两件事是从预测中计算 seqeval 分数,并提供一种将您的模型推送到 Hub 的方法。这两者都可以使用 Keras callbacks 来完成。
将您的compute_metrics函数传递给 KerasMetricCallback:
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)在 PushToHubCallback 中指定要推送模型和分词器的位置:
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_wnut_model",
... tokenizer=tokenizer,
... )然后将您的回调捆绑在一起:
>>> callbacks = [metric_callback, push_to_hub_callback]最后,您已经准备好开始训练您的模型了!使用您的训练和验证数据集、时代数和回调调用fit来微调模型:
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)一旦训练完成,您的模型将自动上传到 Hub,以便每个人都可以使用它!
要了解如何为标记分类微调模型的更深入示例,请查看相应的PyTorch 笔记本或TensorFlow 笔记本。
推理
很好,现在您已经微调了一个模型,可以用它进行推理了!
获取一些您想要运行推理的文本:
>>> text = "The Golden State Warriors are an American professional basketball team based in San Francisco."尝试使用您微调的模型进行推理的最简单方法是在 pipeline()中使用它。用您的模型实例化一个 NER 的pipeline,并将文本传递给它:
>>> from transformers import pipeline
>>> classifier = pipeline("ner", model="stevhliu/my_awesome_wnut_model")
>>> classifier(text)
[{'entity': 'B-location',
'score': 0.42658573,
'index': 2,
'word': 'golden',
'start': 4,
'end': 10},
{'entity': 'I-location',
'score': 0.35856336,
'index': 3,
'word': 'state',
'start': 11,
'end': 16},
{'entity': 'B-group',
'score': 0.3064001,
'index': 4,
'word': 'warriors',
'start': 17,
'end': 25},
{'entity': 'B-location',
'score': 0.65523505,
'index': 13,
'word': 'san',
'start': 80,
'end': 83},
{'entity': 'B-location',
'score': 0.4668663,
'index': 14,
'word': 'francisco',
'start': 84,
'end': 93}]如果您愿意,您也可以手动复制pipeline的结果:
隐藏 Pytorch 内容
对文本进行标记化并返回 PyTorch 张量:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="pt")将您的输入传递给模型并返回logits:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits获取具有最高概率的类,并使用模型的id2label映射将其转换为文本标签:
>>> predictions = torch.argmax(logits, dim=2)
>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']隐藏 TensorFlow 内容
对文本进行标记化并返回 TensorFlow 张量:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="tf")将您的输入传递给模型并返回logits:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> logits = model(**inputs).logits获取具有最高概率的类,并使用模型的id2label映射将其转换为文本标签:
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']olden’, ‘start’: 4, ‘end’: 10}, {‘entity’: ‘I-location’, ‘score’: 0.35856336, ‘index’: 3, ‘word’: ‘state’, ‘start’: 11, ‘end’: 16}, {‘entity’: ‘B-group’, ‘score’: 0.3064001, ‘index’: 4, ‘word’: ‘warriors’, ‘start’: 17, ‘end’: 25}, {‘entity’: ‘B-location’, ‘score’: 0.65523505, ‘index’: 13, ‘word’: ‘san’, ‘start’: 80, ‘end’: 83}, {‘entity’: ‘B-location’, ‘score’: 0.4668663, ‘index’: 14, ‘word’: ‘francisco’, ‘start’: 84, ‘end’: 93}]
如果您愿意,您也可以手动复制`pipeline`的结果:
隐藏 Pytorch 内容
对文本进行标记化并返回 PyTorch 张量:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="pt")将您的输入传递给模型并返回logits:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits获取具有最高概率的类,并使用模型的id2label映射将其转换为文本标签:
>>> predictions = torch.argmax(logits, dim=2)
>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']隐藏 TensorFlow 内容
对文本进行标记化并返回 TensorFlow 张量:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="tf")将您的输入传递给模型并返回logits:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> logits = model(**inputs).logits获取具有最高概率的类,并使用模型的id2label映射将其转换为文本标签:
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-06-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号