重磅好文!现场故障回顾:最新版Kafka数据过期未删除问题的源码深入剖析与终极解决方案总结
重磅好文!现场故障回顾:最新版Kafka数据过期未删除问题的源码深入剖析与终极解决方案总结

背景
周五晚上电话轰炸,驻场人员反映某公安厅数据上报业务故障。究其原因是数据域Kafka集群不可用。经过排查发现虽然Kafka集群设置了3天数据过期时间(且Topic级别未单独设置别的过期时间)。按道理来说,数据只会保留3天左右。实际情况是很早之前已经过期的数据并未正常删除,造成集群多个节点磁盘爆满。
遂有此文,本文从现场问题排查思路入手,结合Kafka源码,深入剖析Topic数据过期触发删除机制的流程。最后,通过本地场景复现进行论证、提供规避方法、给出终极解决方案。
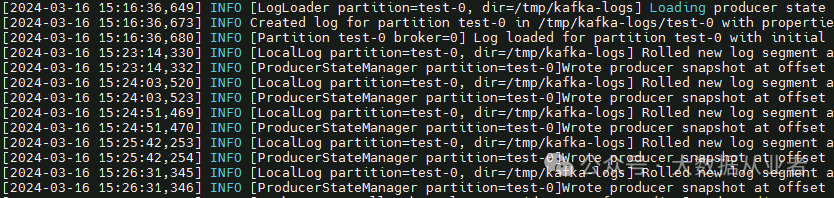
排查日志
查阅Kafka日志发现,在节点磁盘爆满之前,未见异常。换句话说,日志没有记录过期数据删除失败的信息,说明不是删除失败而是未触发删除。
源码剖析
阅读Kafka源码的朋友都知道,Kafka启动脚本(kafka-server-start.sh)的入口类为kafka.Kafka:
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"入口类Kafka调用server.startup()方法启动Kafka的所有内部服务:
try server.startup()该startup方法启动一个ScheduledThreadPoolExecutor类型线程池,线程数为参数background.threads值(默认10),名称为kafkaScheduler:
/* start scheduler */ kafkaScheduler = new KafkaScheduler(config.backgroundThreads) kafkaScheduler.startup()同时,该startup方法还实例化一个LogManager,并将上面的kafkaScheduler作为入参:
/* start log manager */
_logManager = LogManager(
config,
metaPropsEnsemble.errorLogDirs().asScala.toSeq,
configRepository,
kafkaScheduler,
time,
brokerTopicStats,
logDirFailureChannel,
config.usesTopicId)
_brokerState = BrokerState.RECOVERY
logManager.startup(zkClient.getAllTopicsInCluster())而LogManager类startup方法调用startupWithConfigOverrides方法,向kafkaScheduler提交调度任务:
/* Schedule the cleanup task to delete old logs */
if (scheduler != null) {
info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs))
scheduler.schedule("kafka-log-retention",
() => cleanupLogs(),
InitialTaskDelayMs,
retentionCheckMs)
info("Starting log flusher with a default period of %d ms.".format(flushCheckMs))
scheduler.schedule("kafka-log-flusher",
() => flushDirtyLogs(),
InitialTaskDelayMs,
flushCheckMs)
scheduler.schedule("kafka-recovery-point-checkpoint",
() => checkpointLogRecoveryOffsets(),
InitialTaskDelayMs,
flushRecoveryOffsetCheckpointMs)
scheduler.schedule("kafka-log-start-offset-checkpoint",
() => checkpointLogStartOffsets(),
InitialTaskDelayMs,
flushStartOffsetCheckpointMs)
scheduler.scheduleOnce("kafka-delete-logs", // will be rescheduled after each delete logs with a dynamic period
() => deleteLogs(),
InitialTaskDelayMs)
}其中第一个任务kafka-log-retention就是Kafka过期删除机制的具体实现。该任务延迟执行时间为InitialTaskDelayMs(即30*1000),任务执行周期为retentionCheckMs(即log.retention.check.interval.ms,默认5 minutes)。

kafka-log-retention任务的cleanupLogs()方法遍历所有logs,依次判断是否需要删除:
deletableLogs.foreach {
case (topicPartition, log) =>
debug(s"Garbage collecting '${log.name}'")
total += log.deleteOldSegments()
val futureLog = futureLogs.get(topicPartition)
if (futureLog != null) {
// clean future logs
debug(s"Garbage collecting future log '${futureLog.name}'")
total += futureLog.deleteOldSegments()
}
}其中,deleteOldSegments方法中基于保留大小和保留时间两个维度判断是否删除。
/**
* If topic deletion is enabled, delete any local log segments that have either expired due to time based retention
* or because the log size is > retentionSize.
*
* Whether or not deletion is enabled, delete any local log segments that are before the log start offset
*/
def deleteOldSegments(): Int = {
if (config.delete) {
deleteLogStartOffsetBreachedSegments() +
deleteRetentionSizeBreachedSegments() +
deleteRetentionMsBreachedSegments()
} else {
deleteLogStartOffsetBreachedSegments()
}
}本文先不关注基于大小的deleteRetentionSizeBreachedSegments方法,只关注基于过期时间的deleteRetentionMsBreachedSegments方法,该方法内通过shouldDelete方法来判断是否触发删除:
private def deleteRetentionMsBreachedSegments(): Int = {
val retentionMs = localRetentionMs(config, remoteLogEnabled())
if (retentionMs < 0) return 0
val startMs = time.milliseconds
def shouldDelete(segment: LogSegment, nextSegmentOpt: Option[LogSegment]): Boolean = {
startMs - segment.largestTimestamp > retentionMs
}
deleteOldSegments(shouldDelete, RetentionMsBreach(this, remoteLogEnabled()))
}其中,startMs为当前时间,retentionMs为设置的保留时间。segment.largestTimestamp就很关键了,直接决定shouldDelete返回true还是false,具体是什么呢?
/**
* The largest timestamp this segment contains.
*/
public long largestTimestamp() throws IOException {
long maxTimestampSoFar = maxTimestampSoFar();
if (maxTimestampSoFar >= 0)
return maxTimestampSoFar;
return lastModified();
}可以看出来,如果能够找到每条数据中的maxTimestamp(找不到默认-1),则返回maxTimestamp;否则,使用segment文件的最近修改时间。很显然,使用segment文件的最近修改时间的话,历史segment肯定会过期触发删除。而maxTimestamp就不一定了。至此,Topic数据过期触发删除机制的流程梳理完成。
经过上述排查剖析,我们可以得出该问题的基本结论:客户producer写到Kafka的数据携带了timestamp且timestamp的值属于未来时间(其实还可能是未携带timestamp,但是producer的主机时间为未来时间,后续会说明)。一个segment中的数据一旦携带了未来时间的timestamp,就会出现该segment过期未触发删除的现象。
场景复现
以最新版本Kafka3.7.0为例,关键参数设置如下:
log.retention.minutes=1
log.retention.check.interval.ms=1000说明:上述参数仅为方便测试,快速见到效果。
kafka-console-producer.sh入口类ConsoleProducer。从源码看,该类并不支持写数据到Kafka时指定timestamp:
/**
* read byte array from input stream and then generate an iterator of producer record
* @param {@link InputStream} of messages. the implementation does not need to close the input stream.
* @return an iterator of producer record. It should implement following rules. 1) the hasNext() method must be idempotent.
* 2) the convert error should be thrown by next() method.
*/
Iterator<ProducerRecord<byte[], byte[]>> readRecords(InputStream inputStream);这里使用Java写个producer示例,完整代码见github:
https://github.com/felixzh2020/felixzh-learning-kafka/tree/master/TimeStampCase/src/main/java/com/felixzh/learning创建测试Topic,名称为test:

场景1:不携带timestamp
关键代码:
ProducerRecordproducerRecordWithOutTimeStamp = new ProducerRecord<>("test", "hello felixzh");观察Kafka日志两分钟可以看到数据过期正常删除,具体如下:

场景2:携带正常timestamp(即非未来时间)
关键代码:
ProducerRecordproducerRecordWithTimeStamp = new ProducerRecord<>("test", null, 1000L, null, "hello felixzh");观察Kafka日志两分钟可以看到数据过期正常删除,具体如下:

场景3:携带非正常timestamp(即未来时间)
关键代码:
ProducerRecordproducerRecordWithTimeStamp = new ProducerRecord<>("test", null, 1742299840000L, null, "hello felixzh");
将timestamp设置为一年后的今天。观察Kafka日志可以看到数据并没有过期正常删除。继续发送正常的timestamp数据或者不携带timestamp数据都不可能触发过期删除。除非Kafka主机时间超过了上述未来时间+过期时间。很显然,现场是不可能随便调整服务器时间的。
那么,遇到这种情况怎么处理呢?
规避方法
方法1: 删除该topic,重新创建。
方法2:删除segment。如果不允许删除topic,可以手动清理segment文件及关联文件,然后重启kafka服务。
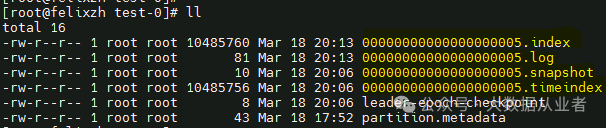
注意:规避处理之后,一定要强调让所有producer写入时候携带正确的timestamp或者不要携带timestamp,禁止携带未来时间的timestamp。PS:如果需要传递timestamp值完全可以放在数据value值中。
那么,如果producer屡教不改或者屡禁不止怎么办??
终极措施
1. 参数详解
集群级别参数log.message.timestamp.type=LogAppendTime

Topic级别参数message.timestamp.type=LogAppendTime

上述参数可选值为CreateTime, LogAppendTime,决定了segment文件存储数据时候的timestamp值的来源:
CreateTime表示使用prodcuer写数据时携带的timestamp;
LogAppendTime表示使用Kafka写文件时候的系统timestamp;说明一点:如果producer未显示设置timestamp,默认会使用producer所在主机的机器时间,Kafkaproducer调用send方法然后dosend方法:
long timestamp = record.timestamp() == null ? nowMs : record.timestamp(); 2. 参数源码剖析
上述参数的实际作用,结合具体源码分析如下:
kafka\core\src\main\scala\kafka\log\UnifiedLog.scala其中,append方法就是Kafka将数据写入到segment文件的入口,如下:
/**
* Append this message set to the active segment of the local log, rolling over to a fresh segment if necessary.
*/
private def append(records: MemoryRecords,
origin: AppendOrigin,
interBrokerProtocolVersion: MetadataVersion,
validateAndAssignOffsets: Boolean,
leaderEpoch: Int,
requestLocal: Option[RequestLocal],
verificationGuard: VerificationGuard,
ignoreRecordSize: Boolean): LogAppendInfoappend方法调用validateMessagesAndAssignOffsets方法,如下:
public ValidationResult validateMessagesAndAssignOffsets(PrimitiveRef.LongRef offsetCounter,
MetricsRecorder metricsRecorder,
BufferSupplier bufferSupplier) {
if (sourceCompression == CompressionType.NONE && targetCompression == CompressionType.NONE) {
// check the magic value
if (!records.hasMatchingMagic(toMagic))
return convertAndAssignOffsetsNonCompressed(offsetCounter, metricsRecorder);
else
// Do in-place validation, offset assignment and maybe set timestamp
return assignOffsetsNonCompressed(offsetCounter, metricsRecorder);
} else
return validateMessagesAndAssignOffsetsCompressed(offsetCounter, metricsRecorder, bufferSupplier);
}该方法通过判断是否压缩,分别调用assignOffsetsNonCompressed方法和validateMessagesAndAssignOffsetsCompressed方法。
两个方法中关键逻辑概述如下:
long maxTimestamp = RecordBatch.NO_TIMESTAMP;
if (record.timestamp() > maxTimestamp)
maxTimestamp = record.timestamp();
if (timestampType == TimestampType.LOG_APPEND_TIME)
maxTimestamp = now;segment文件的时间戳初始值为RecordBatch.NO_TIMESTAMP(即-1),如果数据携带了timestamp,使用数据携带的。然后继续判断如果参数设置为LOG_APPEND_TIME,则直接用本地机器时间取代之前所有设置。
3. 实践演示
可以通过对segment文件dump说明一切,如下:
/home/myHadoopCluster/kafka_2.12-3.7.0/bin/kafka-dump-log.sh --files 00000000000000000005.log
也可以通过消费topic数据说明一切,如下:
./kafka-console-consumer.sh --bootstrap-server felixzh:9092 --topic test --from-beginning --property print.timestamp=true
至此,相信你一定掌握了Kafka Topic数据过期删除机制的全部内容!
腾讯云开发者
