面试真题分享-JVM允许不断创建线程吗?哪些命令进行限制?

MYSQL in写法有什么问题?什么场景下会导致索引失效?
IN 子句通常用于在WHERE子句中指定多个可能的值,但是不当的使用in会导致索引失效,具体有以下场景:
1、隐式类型转换
如果IN子句中的值与列的数据类型不匹配,MySQL可能会尝试进行隐式类型转换。这可能导致索引失效,因为MySQL可能无法使用索引来有效地查找这些值。
2、函数或表达式应用于列 如果你对列应用了一个函数或表达式,并且这个列上有索引,那么索引可能不会被使用。例如,WHERE YEAR(date_column) IN (2021, 2022) 这样的查询可能不会使用date_column上的索引。
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
3、索引列的选择性不足 如果IN子句中的值列表非常大,或者与表中的行数相比非常接近,MySQL可能会认为全表扫描比使用索引更快。
4、使用了OR 当IN子句与其他条件结合使用OR时,特别是当OR条件中的另一个条件没有使用索引时,索引可能会失效。
5、参数列表中包含null值
如果 IN() 函数的参数列表中包含 NULL 值,则 MySQL 将无法使用索引,因为索引不包含 NULL 值。
6、参数列表中包含太多的值
如果 IN() 函数的参数列表中包含太多的值,MySQL 将不会使用索引,而是执行全表扫描。这是因为索引需要在内存中存储,并且索引扫描需要消耗一定的 CPU 资源。
7、列的数据分布不均匀
如果 IN() 函数的参数列表中包含的值在索引列中的数据分布不均匀,MySQL 将不会使用索引。这是因为 MySQL 优化器认为全表扫描可能比使用索引更有效率。
为了优化涉及IN子句的查询,你可以考虑以下建议:
- 确保
IN子句中的值与列的数据类型匹配。 - 尽量避免在列上使用函数或表达式。
- 定期更新和优化MySQL的统计信息。
- 使用
EXPLAIN命令来查看查询的执行计划,并了解MySQL是如何使用索引的。 - 考虑使用覆盖索引(即索引包含查询所需的所有数据)来减少回表操作。
- 在适当的情况下,考虑使用连接(JOIN)而不是子查询来优化性能。
Redis分布式锁怎么实现可重入?
首先可重入锁就是指一条线程在获取锁之后,执行一段业务逻辑后再来请求获取同一个资源时可直接获得锁。不会因为之前已经获取过锁而导致锁的阻塞。
这种锁的优点是避免了因线程在获取锁的过程中阻塞,从而造成的死锁现象。即线程可以进入任何一个它已经拥有的锁所同步着的代码块。
Redis分布式锁如果采用Redission本身就是支持可重入的。Redisson 的分布式可重入锁 RLock 提供了与 java.util.concurrent.locks.Lock 接口类似的操作方式,实现了locak锁接口,使用者可以像使用 java 并发包中的 ReentrantLock 一样使用它。
重入锁也叫做递归锁,指的是在同一线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁。换一种说法:同一个线程再次进入同步代码时,可以使用自己已获取到的锁。可重入锁可以避免因同一线程中多次获取锁而导致死锁发生。像synchronized就是一个重入锁,它是通过moniter函数记录当前线程信息来实现的。
synchronized 和 Lock 可重入原理
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ;
对于synchronized而言,他在底层语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
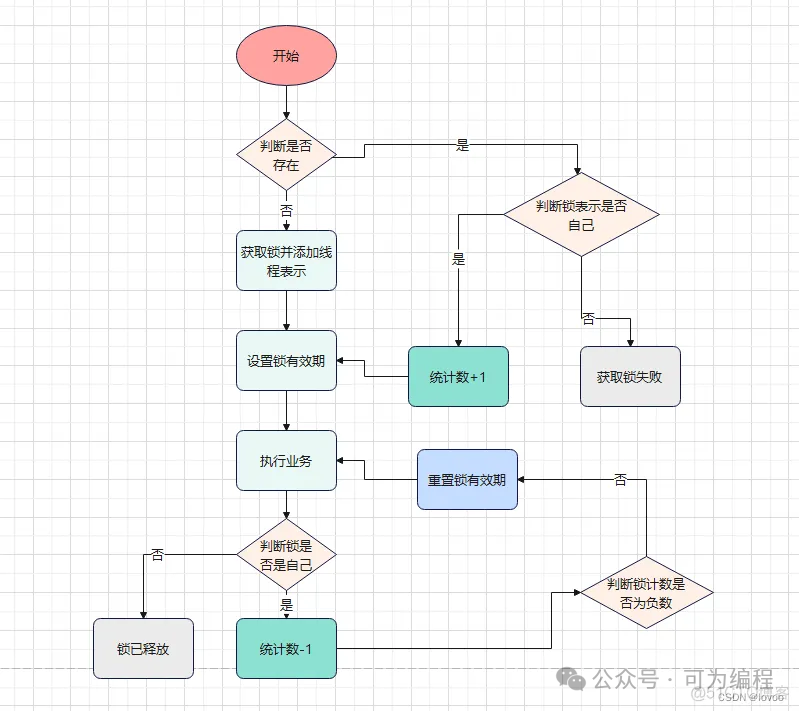
实现可重入锁需要考虑两点:
获取锁:首先尝试获取锁,如果获取失败,判断这个锁是否是自己的,如果是则允许再次获取, 而且必须记录重复获取锁的次数。
释放锁:释放锁不能直接删除了,因为锁是可重入的,如果锁进入了多次,在内层直接删除锁, 导致外部的业务在没有锁的情况下执行,会有安全问题。因此必须获取锁时累计重入的次数,释放时则减去重入次数,如果减到0,则可以删除锁。
下面我们假设锁的key为“ lock ”,hashKey是当前线程的id:“ threadId ”,锁自动释放时间假设为20
获取锁的步骤:
1、判断lock是否存在 EXISTS lock
2、不存在,则自己获取锁,记录重入层数为1.
2、存在,说明有人获取锁了,下面判断是不是自己的锁,即判断当前线程id作为hashKey是否存在:HEXISTS lock threadId
3、不存在,说明锁已经有了,且不是自己获取的,锁获取失败.
3、存在,说明是自己获取的锁,重入次数+1: HINCRBY lock threadId 1 ,最后更新锁自动释放时间, EXPIRE lock 20
释放锁的步骤:
1、判断当前线程id作为hashKey是否存在:HEXISTS lock threadId
2、不存在,说明锁已经失效,不用管了
2、存在,说明锁还在,重入次数减1: HINCRBY lock threadId -1 ,
3、获取新的重入次数,判断重入次数是否为0,为0说明锁全部释放,删除key:DEL lock因此,存储在锁中的信息就必须包含:key、线程标识、重入次数。不能再使用简单的key-value结构, 这里推荐使用hash结构。
获取锁的脚本(注释删掉,不然运行报错)
local key = KEYS[1]; -- 第1个参数,锁的key
local threadId = ARGV[1]; -- 第2个参数,线程唯一标识
local releaseTime = ARGV[2]; -- 第3个参数,锁的自动释放时间
if(redis.call('exists', key) == 0) then -- 判断锁是否已存在
redis.call('hset', key, threadId, '1'); -- 不存在, 则获取锁
redis.call('expire', key, releaseTime); -- 设置有效期
return 1; -- 返回结果
end;
if(redis.call('hexists', key, threadId) == 1) then -- 锁已经存在,判断threadId是否是自己
redis.call('hincrby', key, threadId, '1'); -- 如果是自己,则重入次数+1
redis.call('expire', key, releaseTime); -- 设置有效期
return 1; -- 返回结果
end;
return 0; -- 代码走到这里,说明获取锁的不是自己,获取锁失败释放锁的脚本(注释删掉,不然运行报错)
local key = KEYS[1]; -- 第1个参数,锁的key
local threadId = ARGV[1]; -- 第2个参数,线程唯一标识
if (redis.call('HEXISTS', key, threadId) == 0) then -- 判断当前锁是否还是被自己持有
return nil; -- 如果已经不是自己,则直接返回
end;
local count = redis.call('HINCRBY', key, threadId, -1); -- 是自己的锁,则重入次数-1
if (count == 0) then -- 判断是否重入次数是否已经为0
redis.call('DEL', key); -- 等于0说明可以释放锁,直接删除
return nil;
end;完整代码
import java.util.Collections;
import java.util.UUID;
import org.springframework.core.io.ClassPathResource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.scripting.support.ResourceScriptSource;
/**
* Redis可重入锁
*/
public class RedisLock {
private static final StringRedisTemplate redisTemplate = SpringUtil.getBean(StringRedisTemplate.class);
private static final DefaultRedisScript<Long> LOCK_SCRIPT;
private static final DefaultRedisScript<Object> UNLOCK_SCRIPT;
static {
// 加载释放锁的脚本
LOCK_SCRIPT = new DefaultRedisScript<>();
LOCK_SCRIPT.setScriptSource(new ResourceScriptSource(new ClassPathResource("lock.lua")));
LOCK_SCRIPT.setResultType(Long.class);
// 加载释放锁的脚本
UNLOCK_SCRIPT = new DefaultRedisScript<>();
UNLOCK_SCRIPT.setScriptSource(new ResourceScriptSource(new ClassPathResource("unlock.lua")));
}
/**
* 获取锁
* @param lockName 锁名称
* @param releaseTime 超时时间(单位:秒)
* @return key 解锁标识
*/
public static String tryLock(String lockName,String releaseTime) {
// 存入的线程信息的前缀,防止与其它JVM中线程信息冲突
String key = UUID.randomUUID().toString();
// 执行脚本
Long result = redisTemplate.execute(
LOCK_SCRIPT,
Collections.singletonList(lockName),
key + Thread.currentThread().getId(), releaseTime);
// 判断结果
if(result != null && result.intValue() == 1) {
return key;
}else {
return null;
}
}
/**
* 释放锁
* @param lockName 锁名称
* @param key 解锁标识
*/
public static void unlock(String lockName,String key) {
// 执行脚本
redisTemplate.execute(
UNLOCK_SCRIPT,
Collections.singletonList(lockName),
key + Thread.currentThread().getId(), null);
}
}
关注公众号【可为编程】回复【面试】领取年度最新面试题大全!!!
Redission就是上面的可重入锁实现机制。
补充: setNX的缺陷 setnx 琐最大的缺点就是它加锁时只作用在一个 Redis 节点上,即使 Redis 通过 Sentinel(哨岗、哨兵) 保证高可用,如果这个 master 节点由于某些原因发生了主从切换,那么就会出现锁丢失的情况,下面是个例子: 1、在 Redis 的 master 节点上拿到了锁; 2、但是这个加锁的 key 还没有同步到 slave 节点; 3、master 故障,发生故障转移,slave 节点升级为 master节点; 4、上边 master 节点上的锁丢失。 有时甚至不单单是锁丢失这么简单,新选出来的 master 节点可以重新获取同样的锁,出现一把锁被拿两次的场景。
大流量接口会做缓存吗?
流量峰值给系统带来的主要危害在于,它会瞬间产生大量对磁盘数据的读取和搜索,通常数据源是数据库或文件系统,当数据访问次数增大时,过多的磁盘读取可能会最终成为整个系统的性能瓶颈,甚至压垮整个数据库,导致系统卡死、服务不可用等严重后果。

当数据量较大时,需要减少对数据库磁盘的读写操作,因此通常都会选择在业务系统和数据库之间加入一层缓存(Cache),从而减少数据库的访问压力,结构如下。

一般我们都用redis来做缓存,这就需要考虑缓存和数据库数据的一致性问题。有以下几种情况:
缓存命中、缓存失效、缓存更新
1、缓存命中:缓存有数据,数据库有数据,直接走缓存查询,不去查询数据库,节省数据库的IO操作。
2、缓存失效:缓存没有数据,数据库有数据,查询时先检查缓存,如果没有就查询数据库再回填给缓存。
3、缓存更新:当数据库中来了新的数据,需要在写入完数据库之后让缓存数据失效,然后将数据同步到缓存中。
这就会出现问题,如果在缓存失效的情况下,线程一查询数据库准备回写数据到缓存中,线程二又新增了几条数据到数据库中,最后线程1同步到缓存中的数据都是老数据,造成数据不一致。
这也是高并发环境下的缓存数据不一致问题,可以在更新数据之前,先删除一下缓存,等到更新完数据库之后,再删一下缓存,然后将数据写入缓存中,删除缓存的时间远远小于更新缓存所用的时间。
缓存过期后请求将尝试从后端数据库获取数据,这是一个看似合理的流程。但是,在高并发场景下,有可能多个请求并发地从数据库获取数据,会对后端数据库造成极大的冲击,甚至导致“雪崩”。这就是高并发环境下缓存出现的三种问题,雪崩,击穿、穿透等问题。
此外,当某个缓存key被更新时,也可能被大量请求获取,这也会导致一致性问题。那么如何避免类似问题呢?可以使用类似“锁”的机制,在缓存更新或者过期的情况下,先尝试获取锁,当更新或者从数据库获取完成后再释放锁,其他请求只需要一定的等待时间即可直接从缓存中继续获取数据。
本地缓存会存什么类型的数据,如何进行刷新的
会存储Token令牌信息,用户信息的json字符串,角色信息,部门信息,权限信息。刷新根据每个用户登录之后根据不同用户ID查询并刷新对应的用户信息。
单token方案
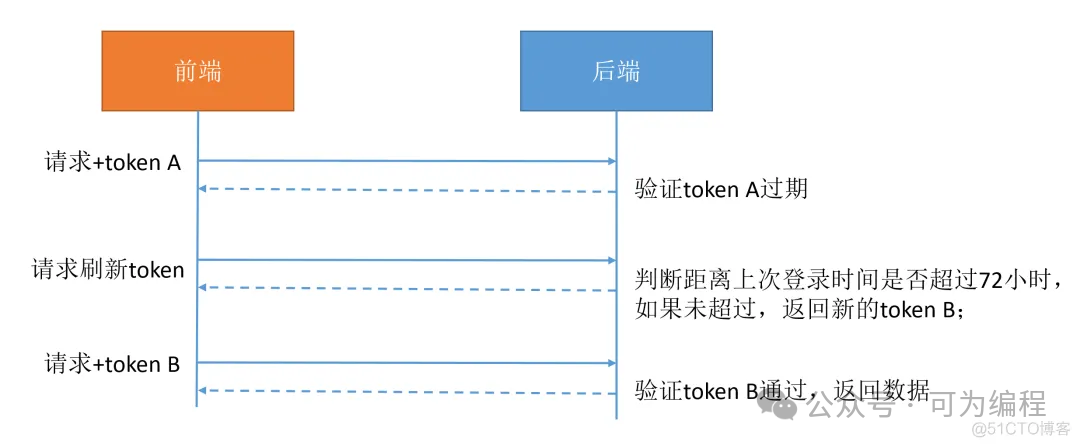
Token令牌会存储在redis中设置1小时的过期时间,时间到了会查询用户的登录状态和token是否过期,如果过期刷新获取新的token信息,并向后续命1小时。如果要实现每隔72小时必须强制重新登录,后端需要记录每次用户的登录时间;用户每次请求时,检查用户最后一次登录日期,如超过72小时,则拒绝刷新token的请求,请求失败,跳转到登录页面。
另外后端还可以记录刷新token的次数,比如最多刷新50次,如果达到50次,则不再允许刷新,需要用户重新授权。
上面介绍的单token方案原理比较简单。下面我们再看一个双token方案。
双token方案(OAuth2.0)
1、登录成功以后,后端返回 access_token 和 refresh_token,客户端缓存此两种token;
2、使用 access_token 请求接口资源,成功则调用成功;如果token超时,客户端携带 refresh_token 调用token刷新接口获取新的 access_token;
3、后端接受刷新token的请求后,检查 refresh_token 是否过期,通常refresh_token时长更长,一般设置为24小时,access_token设置为1小时。如果refresh_token也过期,拒绝刷新,客户端收到该状态后,跳转到登录页;如果未过期,生成新的 access_token 返回给客户端。
4、客户端携带新的 access_token 重新调用上面的资源接口。
5、客户端退出登录或修改密码后,注销旧的token,使 access_token 和 refresh_token 失效,同时清空客户端的 access_token 和 refresh_token。
缓存已经失效了怎么办?
1、服务熔断:当缓存服务器宕机或超时响应时,为了防⽌整个系统出现雪崩,暂时停⽌业务服务访问缓存系统。
2、服务降级:当出现⼤量缓存失效,⽽且处在⾼并发⾼负荷的情况下,在业务系统内部暂时舍弃对⼀些⾮核⼼的接⼝和数据的请求,⽽直接返回⼀个提前准备好的 fallback(退路)错误处理信息。
如果遇到慢查询SQL导致服务器CPU爆满或者时IO飙升,如何处理?
CPU爆满的情况主要分为两种,一种就是高并发请求导致MySQL连接数不足,需要增加CPU或者是mysql搭集群解决。另一种就是慢SQL查询导致的CPU爆满,此时首先做的是恢复业务。先连接上db,查出慢sql,kill掉,等待业务恢复。可以按照以下sql执行:
1.查看哪些表被锁:show OPEN TABLES where In_use > 0;
2.查询正在执行的SQL,发现大量SQL执行阻塞了几百秒:
select * from information_schema.processlist where db=‘ db_xxx ‘ and info is not null;
3.直接取出索引的进程ID,拼装成kill语句,取出来执行,干掉阻塞中的索引进程:
select concat(‘kill ‘, id,‘;‘) from information_schema.processlist where db=‘db_xxx ‘ and info is not null;从网上看到这样一段话,感觉分析的很到位。

找到慢SQL,之前文章有介绍如何处理慢SQL,处理完之后再上线。
JVM允许不断创建线程吗?由哪些命令进行限制?
JVM中可以生成的最大数量由JVM的堆内存大小、Thread的Stack内存大小、系统最大可创建的线程数量(Java线程的实现是基于底层系统的线程机制来实现的,Windows下_beginthreadex,Linux下pthread_create)三个方面影响。具体数量可以根据Java进程可以访问的最大内存(32位系统上一般2G)、堆内存、Thread的Stack内存来估算。
-Xms 最小堆内存
-Xmx 最大堆内存
-Xss 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M
操作系统限制 系统最大可开线程数
32位Linux系统可创建的最大pid数是32678,这个数值可以通过/proc/sys/kernel/pid_max来做修改(修改其值为10000:echo 10000 > /proc/sys/kernel/pid_max),但是在32系统下这个值只能改小,无法改大。
Windows可创建的线程数量比linux可能更少。
在64位Linux系统(CentOS 7.9)下,还有一个参数会限制线程数量:max user process(可通过ulimit –a查看,默认值127960,通过ulimit –u可以修改此值)
测试环境:
系统:Ubuntu 10.04 Linux Kernel 2.6 (32位)
内存:2G
JDK:1.7
测试结果:
不考虑系统限制
-Xms | -Xmx | -Xss | 结果 |
|---|---|---|---|
1024m | 1024m | 1024k | 1737 |
1024m | 1024m | 64k | 26077 |
512m | 512m | 64k | 31842 |
256m | 256m | 64k | 31842 |
在创建的线程数量达到31842个时,系统中无法创建任何线程。
由上面的测试结果可以看出增大堆内存(-Xms,-Xmx)会减少可创建的线程数量,增大线程栈内存(-Xss,32位系统中此参数值最小为60K)也会减少可创建的线程数量。
结合系统限制
线程数量31842的限制是是由系统可以生成的最大线程数量决定的:/proc/sys/kernel/threads-max,可其默认值是32080。修改其值为10000:echo 10000 > /proc/sys/kernel/threads-max,修改后的测试结果如下:
-Xms | -Xmx | -Xss | 结果 |
|---|---|---|---|
256m | 256m | 64k | 9761 |
这样的话,是不是意味着可以配置尽量多的线程?再做修改:echo 1000000 > /proc/sys/kernel/threads-max,修改后的测试结果如下:
-Xms | -Xmx | -Xss | 结果 |
|---|---|---|---|
256m | 256m | 64k | 32279 |
128m | 128m | 64k | 32279 |
发现线程数量在达到32279以后,不再增长。查了一下,32位Linux系统可创建的最大pid数是32678,这个数值可以通过/proc/sys/kernel/pid_max来做修改(修改方法同threads-max),但是在32系统下这个值只能改小,无法更大。在threads-max一定的情况下,修改pid_max对应的测试结果如下:
pid_max | -Xms | -Xmx | -Xss | 结果 |
|---|---|---|---|---|
1000 | 128m | 128m | 64k | 582 |
10000 | 128m | 128m | 64k | 9507 |
在Windows上的情况应该类似,不过相比Linux,Windows上可创建的线程数量可能更少。基于线程模型的服务器总要受限于这个线程数量的限制。
linux CentOS7.9版本的/proc/sys/kernel/threads-max值为255921个线程。
kafka异步发送保证数据不丢失
1、生产者:
1.1 丢失原因:
- kafka生产端异步发送消息后,不管broker是否响应,立即返回,伪代码producer.send(msg),由于网络抖动,导致消息压根就没有发送到broker端,或者是broker突然下綫。
- kafka生产端发送消息超出大小限制,broker端接到以后没法进行存储;
1.2 解决方案:
1、生产者调用异步回调消息。伪代码如下: producer.send(msg,callback);
2、生产者增加消息确认机制,设置生产者参数:acks = all。partition的leader副本接收到消息,等待所有的follower副本都同步到了消息之后,才认为本次生产者发送消息成功了;
3、生产者设置重试次数。比如:retries>=3,增加重试次数以保证消息的不丢失;
4、定义本地消息日志表,定时任务扫描这个表自动补偿,做好监控告警。
5、后台提供一个补偿消息的工具,可以手工补偿。
2、Broker
2.1 丢失原因:
kafka broker集群接收到数据后会将数据进行持久化存储到磁盘,消息都是先写入到页缓存,然后由操作系统负责具体的刷盘任务或者使用fsync强制刷盘,如果此时Broker宕机,且选举一个落后leader副本很多的follower副本成为新的leader副本,那么落后的消息数据就会丢失。
2.2 解决方案:
1、同步刷盘(不太建议)。同步刷盘可以提高消息的可靠性,防止由于机器掉电等异常造成处于页缓存而没有及时写入磁盘的消息丢失。但是会严重影响性能。
2、利用partition的多副本机制(建议)
unclean.leader.election.enable=false:数据丢失太多的副本不能选举为leader副本,防止落后太多的消息数据而引起丢失;
replication.factor >= 3:消息分区的副本个数,这个值建议设为>=3;
min.insync.replicas >1:消息写入多少副本才算已提交,这个值必须大于1,这个是要求一个leader 至少感知到有至少一个 follower还跟自己保持联系;(replication.factor>min.insync.replicas 这样消息才能保存成功)
3、消费者
3.1 丢失原因:
1、消费者配置了offset自动提交参数。enable.auto.commit=true。
2、消息者收到了消息,进行了自动提交offset,kafka以为消费者已经消费了这个消息,但其实刚准备处理这个消息,还没处理完成,消费者自己挂了,此时这条消息就会丢失。
3、多线程消费消息,某个线程处理消息出现异常,还是会出现自动提交offset。
3.2 解决方案:
1、消费者关闭自动提交,采用手动提交offset。通过配置参数:enable.auto.commit=false,关闭自动提交offset,在完成业务逻辑以后手动提交offset,这样就不会丢失数据。
2、消费者多线程处理业务逻辑,等待所有线程处理完成以后,才手工提交offset。
3、消费者消费消息需要进行幂等处理,防止重复消费。
4、假如kafka挂了,如何保证高可用?
消息生产服务A 所有消息入库,然后通过 定时任务job 直接调用消息消费服务B。
算法-有序链表去除重复节点返回不包含节点数据的链
private static ListNode deleteDuplicates(ListNode head) {
if (head == null) {
return head;
}
ListNode cur = head;
while (cur.next != null) {
if (cur.val == cur.next.val) {
cur.next = cur.next.next;
} else {
cur = cur.next;
}
}
return head;
}腾讯云开发者
