分布式认知-RAFT选举
原创

最近在学习Raft协议——一个用于管理日志一致性的协议,发现网上有关Raft选举逻辑描述不够全乎,特地咨询一些业界大佬,并将选举相关知识整理如下:
Raft协议概述
三种角色
Raft是一个用于管理日志一致性的协议。它将分布式一致性分解为多个子问题:Leader选举(Leader election)、日志复制(Log replication)、安全性(Safety)、日志压缩(Log compaction)等。同时,Raft算法使用了更强的假设来减少了需要考虑的状态,使之变的易于理解和实现。Raft将系统中的角色分为领导者(Leader)、跟从者(Follower)和候选者(Candidate):
- Leader:接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
- Follower:接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
- Candidate:Leader选举过程中的临时角色。
Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。Raft算法将时间分为一个个的任期(term),每一个term的开始都是Leader选举。在成功选举Leader之后,Leader会在整个term内管理整个集群。如果Leader选举失败,该term就会因为没有Leader而结束。
Term
Raft 算法将时间划分成为任意不同长度的任期(term)。任期用连续的数字进行表示。每一个任期的开始都是一次选举(election),一个或多个候选人会试图成为领导人。如果一个候选人赢得了选举,它就会在该任期的剩余时间担任领导人。在某些情况下,选票会被瓜分,有可能没有选出领导人,那么,将会开始另一个任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最多只有一个领导人。
RPC
Raft 算法中服务器节点之间通信使用远程过程调用(RPC),并且基本的一致性算法只需要两种类型的 RPC,为了在服务器之间传输快照增加了第三种 RPC。
【RPC有三种】:
- RequestVote RPC:候选人在选举期间发起。
- AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成。
InstallSnapshot RPC: 领导者使用该RPC来发送快照给太落后的追随者。
Leader选举
Raft选举逻辑是Raft算法中的一个关键组成部分,它负责在分布式系统中选举出一个领导者(Leader)来管理集群的日志复制和客户端请求。
选举过程
节点的角色:Leader,Candidate,Follower
Candidate:节点参与选举的中间状态。所有参与选举的节点,在没有选出Leader之前,所有节点都称为Candidate。当通过选举选出Leader后,其中一个node的角色会从Candidate转变为Leader,其它node的角色从candidate转变为Follower。
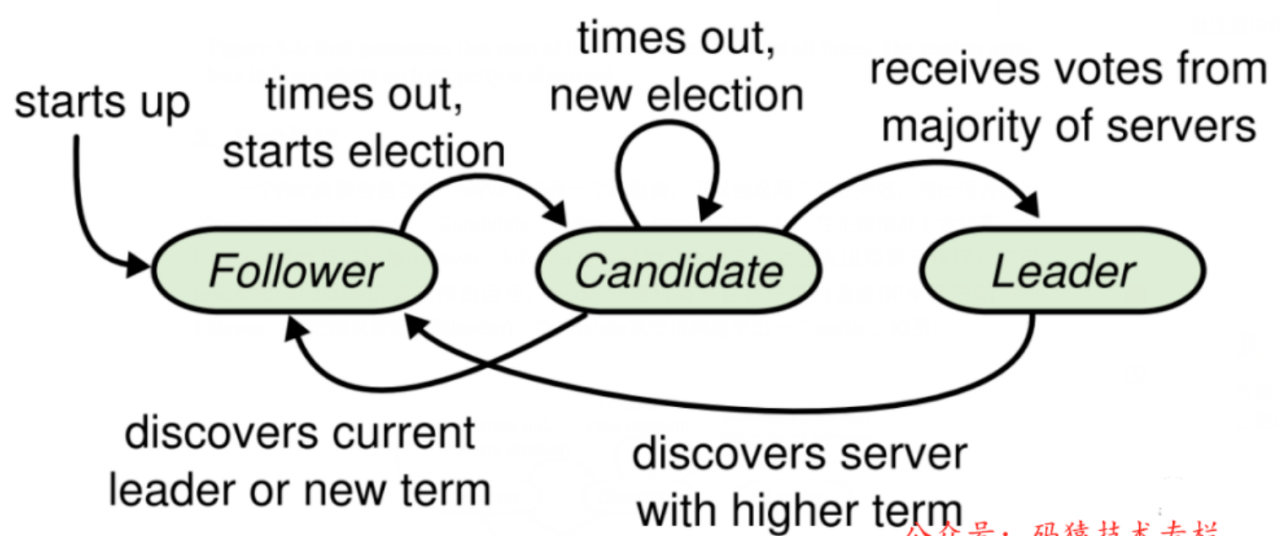
如图所示:所有的节点开始都处于follower的角色。如果Follower在超时时间没有收到Leader的hearbeat消息,就开始转入Candidate状态,开始发起选举。如果Candidate收到大多数节点的投票支持,就当选为Leader。如果选举超时或者没有得到大多数支持,特定的时间后重新发起选举。如果Candidate收到别的节点Leader的消息,就转为Follower状态。
发起选举的时机:
- 节点启动时,发起选举
- follower接收不到leader的心跳时发起选举
从发起选举者的操作:
- 增加节点自己的 current term ,切换到candidate状态
- 投自己一票
- 并行给其他节点发送 RequestVote RPCs等待其他节点的回复
再回到投票者的视角,投票者如何决定是否给一个选举请求投票,有以下约束:
- 在单个任期内,单个节点最多只能投一票
- 候选人知道的信息不能比自己的少(候选人的日志条目比自己新)。
- First-come-first-served 先来先得。

发起选举者根据选举的结果,可能出现三种情况:
- 情况1:收到majority的投票(含自己的一票),则赢得选举,成为leader
- 情况2:被告知别人已当选,那么自行切换到follower
- 情况3:一段时间内没有收到majority投票(选举超时),则保持candidate状态,增加自己的Term,重复选举过程。
第一种情况,赢得了选举之后,新的leader会立刻给所有节点发消息,广而告之,避免其余节点触发新的选举。
第二种情况,比如有三个节点A B C。A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的第一个约束,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成follower。
第三种情况,没有任何节点获得majority投票,比如右上角图这种情况:
总共有四个节点,Node C、Node D同时成为了candidate,进入了term 4,但Node A投了NodeD一票,NodeB投了Node C一票,这就出现了平票 split vote的情况。这个时候大家都在等,直到超时后重新发起选举。如果出现平票的情况,那么就延长了系统不可用的时间(没有leader是不能处理客户端写请求的),因此raft引入2个机制:
- randomized election timeouts来尽量避免平票情况。
- 节点的数目都是奇数,尽量保证majority的出现。
关键点总结
1、选举投票赢得了大多数的选票(也就是集群里n/2+1节点投票),成功选举为Leader
2、没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。
选举限制与保证
- 日志一致性:能被选举为领导者的节点必须包含所有已经提交的日志条目。这是为了确保数据的一致性和可靠性。
- 任期内的唯一性:Raft算法保证在给定的一个任期内最多只有一个领导者。这有助于简化系统的设计和实现。
与选举相关的两个重要机制
Prevote(预投票)机制
在Basic Raft算法中,当一个Follower与其他节点网络隔离,如下图所示:
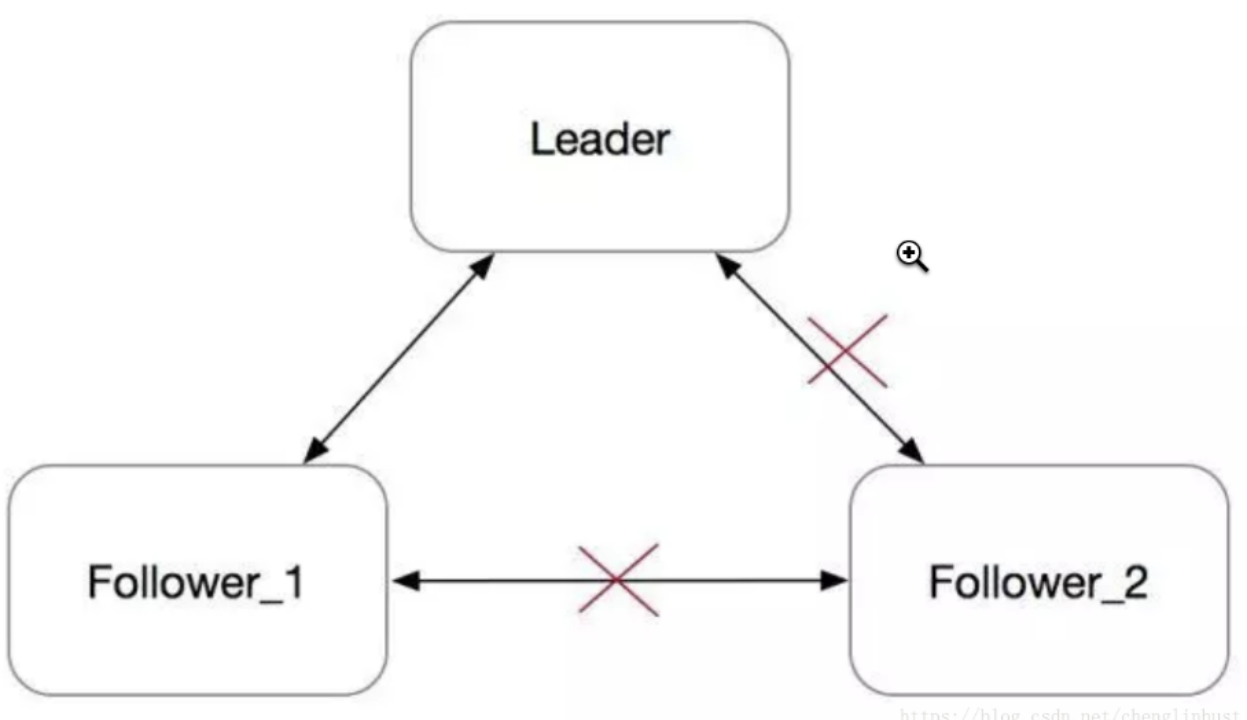
Follower_2在electionTimeout没收到心跳之后,会发起选举,并转为Candidate。每次发起选举时,会把Term加一。由于网络隔离,它既不会被选成Leader,也不会收到Leader的消息,而是会一直不断地发起选举。Term会不断增大。
一段时间之后,这个节点的Term会非常大。在网络恢复之后,这个节点会把它的Term传播到集群的其他节点,导致其他节点更新自己的term,变为Follower。然后触发重新选主,但这个旧的Follower_2节点由于其日志不是最新,并不会成为Leader。整个集群被这个网络隔离过的旧节点扰乱,显然需要避免的。
Prevote(预投票)是一个类似于两阶段提交的协议,第一阶段先征求其他节点是否同意选举,如果同意选举则发起真正的选举操作,否则降为Follower角色。这样就避免了网络分区节点重新加入集群,触发不必要的选举操作。
Prevote投票规则
日志更新性:在决定是否给予Prevote赞成票时,其他节点会检查Candidate节点的日志是否足够新。这通常通过比较Candidate节点的日志Term和Index来实现。只有日志更新或至少与自身日志一样新的Candidate节点才能获得赞成票。
避免重复投票:每个节点在一个任期内只能投一次票(无论是Prevote还是正式的选举投票)。这确保了选举过程的公平性和一致性。
Prevote处理流程
1、follower成员electionTimeout超时,且没有收到来自Leader的心跳消息时,它会转变为Candidate状态,并准备发起选举;
2、若配置Prevote机制,Candidate节点会首先向其他节点发送Prevote请求:是否赞同选举;
3、Candidate节点收集其他节点对Prevote请求的赞同或反对回复;
①若反对,则该节点保持Candidate状态并等待下一次electionTimeout超时,或者根据算法逻辑重置定时器并重新尝试。
②若大多数节点赞同,则Candidate节点将Term+1并广播给其他节点,尝试发起选举;
针对3.2里发起的选举,因为其他follower节点都记录还是在lease 没有过期,不会投票。此时发起选举的节点保持Candidate状态并等待下一次electionTimeout超时,或者根据算法逻辑重置定时器并重新尝试。
有关其他Follower节点发送Prevote请求处理:一般 是通过比较Candidate节点的日志Term和Index来判断 Candidate节点的日志是否足够新。只有日志更新或至少与自身日志一样新的Candidate节点才能获得赞成票。
Raft选举中的Prevote机制是一种有效的优化手段,它通过引入预投票阶段来减少不必要的选举和提高选举效率。这一机制不仅提高了分布式系统的稳定性,还保护了集群的历史数据不受网络分区或故障节点的影响。在实际应用中,许多基于Raft算法的分布式系统(如etcd和Consul)都采用了这一机制来确保系统的高可用性和一致性。
Lease租约机制
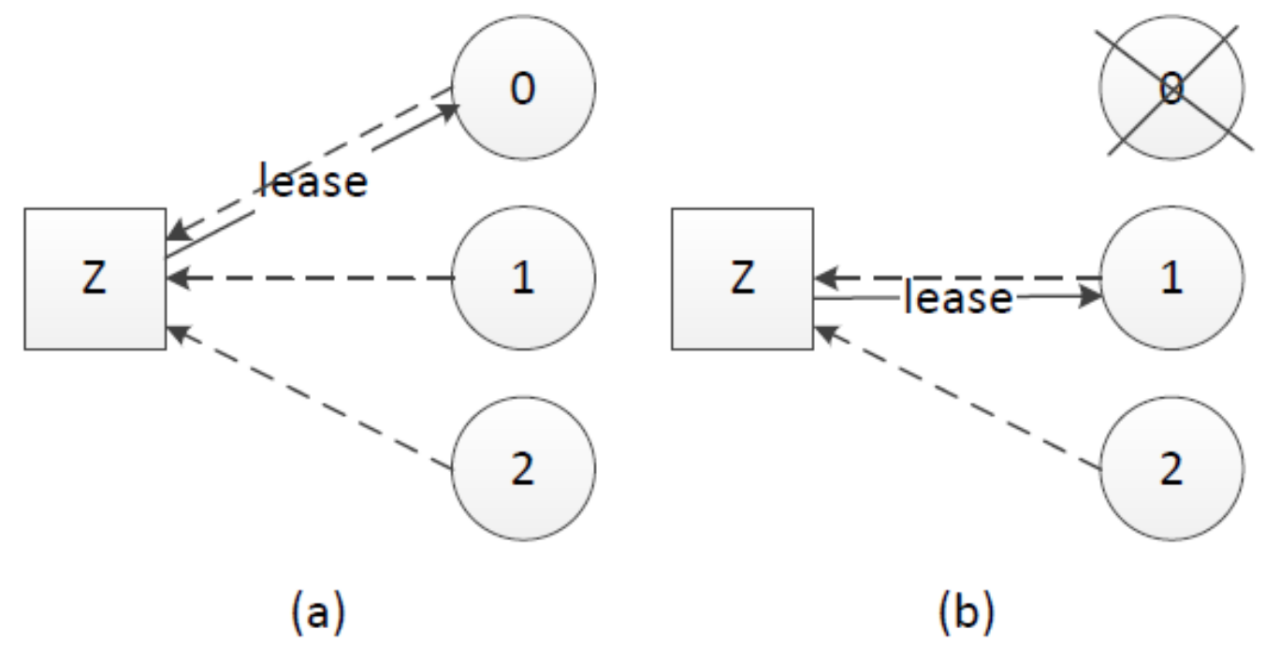
租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题。中心思想是每次租约时长内只有一个节点获得租约、到期后必须重新颁发租约。在实践应用中,zookeeper、ectd可用于租约颁发。
假设我们有租约颁发节点Z,节点0、1和2竞选leader,租约过程如下:
(a).节点0、1、2在Z上注册自己,Z根据一定的规则(例如先到先得)颁发租约给节点,该租约同时对应一个有效时长;这里假设节点0获得租约、成为leader
(b).leader宕机时,只有租约到期(timeout)后才重新发起选举,这里节点1获得租约、成为leader
选举后No-op操作
Leader在选举流程完成之后,需要提交一个空的日志记录(no-op操作)。只有当Noop操作成功返回后,Raft Group才能正常提供服务。
当Noop操作返回成功后,至少可以保证有多数个节点其上日志和leader保持同步。Follower上的日志条目多余的会清理,不足的日志会补齐。
如果不发送noop,可能会出现的问题:
- 数据丢失
- 数据不一致
在Leader选举完成之后,发一个空操作的目的:a)提交还未提交的日志。b)实现大多数副本的日志都以Leader为标准并同步对齐。
Transfer Leadership领导权转移
transfer leadership在实际一些应用中,需要考虑一些副本局部性放置,来降低网络的延迟和带宽占用。
Raft在transfer leadership的时候
1)先block当前leader的写入过程,然后排空target节点的复制队列,使得target节点日志达到最新状态
2)然后给target节点发送TimeoutNow请求,从而触发target节点立即选主。这个过程不能无限制的block当前leader的写入过程,否则会影响raft对外提供服务。需要为transfer leadership过程设置一个超时时间。超时之后如果发现term没有发生变化,说明target节点没有追上数据并选主成功,transfer就失败了。
leadership transfer 的流程如下:
- leader 停止接收新的请求;
- 通过 log replication 使 leader 和 transferee 的 log 相同,确保 transferee 能够赢得选举;
- leader 发送 TimeoutNow 给 transferee,transferee 会立即发起选举。leader 收到 transferee 的消息会 step down。
仍有几个问题需要处理:
- transferee 挂了: 当 leadership transfer 在 election timeout 时间内未完成,则终止并恢复接收客户端请求。
- transferee 有大概率成为下一个 leader,若失败,可以重新发起 leader transfer。
- check quorum 会使节点忽略 RequestVote,需要强制投票。
注意:braft里transfer leader,原主会停写等新主出现,如果transfer给一个日志比较落后的副本,会导致后者迟迟当选不了主,然后原leader发现transfer超时认为失败,然后恢复读写,这段时间就是不可用时间,所以是很粗暴的实现。
即:Raft 领导权转移 那一瞬间集群写性能会下降 甚至 那个时间窗口不可用。但理论上选举新主会快很多,通常由系统或管理员触发为了负载均衡、提高系统可用性或响应性等目的。
Raft选举与领导权转移不同点
触发条件:选举通常在集群启动或Leader失效时触发;而领导权转移则是由系统或管理员根据需要主动触发的。
目的:选举的目的是为了选出一个新的Leader以恢复集群的正常运作;而领导权转移的目的是为了优化集群的性能或响应性。
过程:选举过程中节点需要通过发送RequestVote RPC请求投票,并可能经历多轮选举;而领导权转移过程中,Leader会主动通知Transferee可以立即开始选举,且Transferee由于日志同步和特殊通知,通常能较快地成为新的Leader。
对系统的影响:选举过程中可能会有一段时间内没有Leader,对系统性能有一定影响;而领导权转移则可以在不中断服务的情况下进行,对系统的影响较小。
总的来说,Raft选举和领导权转移都是Raft共识算法中重要的机制,但它们在触发条件、目的、过程和对系统的影响等方面存在明显的不同。
成员变更
Raft成员发生变更时,处理逻辑是确保在变更过程中保持集群的一致性和可用性,同时避免出现双领导者(Leader)等异常情况。
基本概念
在Raft中,配置是指集群中节点的集合,配置(Configuration)决定了哪些节点参与领导者选举、日志复制等过程。
成员变更:成员变更是指在集群运行过程中改变运行一致性协议的节点,如增加、减少节点、节点替换等。
成员变更的风险
双领导者问题:在成员变更过程中,如果处理不当,可能会出现新旧两个配置同时存在多数派,进而可能选出两个领导者,破坏集群的安全性。
服务可用性影响:成员变更过程中需要保证服务的持续可用性,避免因变更导致服务中断。
成员变更的处理逻辑
两阶段成员变更(Joint Consensus)
这是Raft中处理成员变更的一种常用方法,它通过两个阶段来确保变更的安全性和一致性。
第一阶段:
Ø Leader在本地生成一个新的日志条目(Log Entry),其内容是旧成员配置(Cold)与新成员配置(Cnew)的并集(Cold ∪ Cnew),代表当前时刻新旧成员配置共存。
Ø 将这个日志条目写入本地日志,并复制到Cold ∪ Cnew中的所有副本。
Ø 在此之后,新的日志同步需要同时得到Cold和Cnew两个多数派的确认。
Ø 如果Cold和Cnew中的两个多数派都确认了Cold ∪ Cnew这条日志,则提交这条日志。
第二阶段:
Ø Leader生成一条新的日志条目,其内容是新的成员配置Cnew。
Ø 将这个日志条目写入本地日志,并复制到Follower上。
Ø Follower收到新成员配置Cnew后,将其写入日志,并从此刻起以该配置作为自己的成员配置。
Ø 如果Leader收到Cnew的多数派确认,则表示成员变更成功,后续的日志只需得到Cnew多数派确认即可。
这种易理解,但实现复杂度较高。
单步成员变更
虽然两阶段成员变更比较通用且容易理解,但实现起来相对复杂。为了简化操作流程,Raft还允许单步成员变更,但每次只允许增加或删除一个成员。
单步变更的限制
Ø 通过限制每次成员变更的数量(每次只增加一个或删除一个成员),可以避免Cold和Cnew形成两个不相交的多数派,从而简化变更流程。
Ø 如果需要变更多个成员,可以通过连续执行多次单步成员变更来实现。
单步变更的潜在问题
在单步变更过程中,如果发生领导者切换,可能会出现已提交的日志被覆盖的问题。
为了解决这个问题,Raft作者提出了在领导者上任后先提交一条no-op日志的修复方法,以确保在同步成员变更日志前,当前领导者已经提交了至少一条日志。
参考资料
https://cloud.tencent.com/developer/article/2168468 // RAFT算法详解
https://zhuanlan.zhihu.com/p/665730841 // RAFT学习笔记
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号